【行业研究】构建“数据-模型-应用-价值”的高质量数据集建设闭环生态
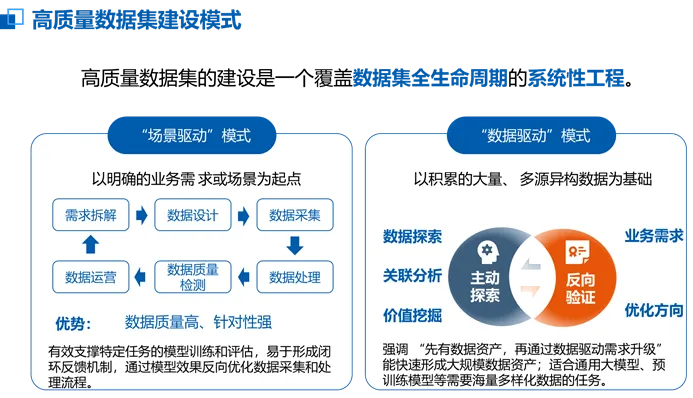
大家好,我是专注于数据要素价值化最后一公里服务的未小智。4月29日下午,第九届数字中国峰会“高质量数据集和数据标注主题交流活动”在福州举办。国家数据局局长刘烈宏出席并对 “推进行业高质量数据集建设”六大行动作出系统阐述,提出:通过“场景牵引数据、数据驱动模型、模型赋能应用、应用创造价值”,打造“数据—模型—应用—价值”的闭环生态,推动形成一批更好满足人工智能就绪度要求,有效提升模型、智能体、智能终端等应用效能的高质量数据集,赋能人工智能与实体经济深度融合。数智创新研习社,结合参与高质量数据集咨询与建设过程中积累的认知与感悟,对高质量数据集建设现状与进程进行了梳理和总结,得出以下结论,仅供行业高质量数据集建设参考使用。行业高质量数据集建设已进入规模化、体系化发展阶段,其核心在于构建“场景牵引数据、数据驱动模型、模型赋能应用、应用创造价值”的闭环生态。该生态以真实业务痛点为起点,通过高质量数据集支撑垂直领域大模型与智能体训练,实现从技术能力到经济价值的转化,并反哺数据持续优化,形成可持续迭代的“数据飞轮”。按照国家数据局统计口径,全国已建成高质量数据集超过11.6万个,总体量超过960PB,日均Token调用量突破140万亿,标志着数据供给与应用进入高速增长期。钢铁、化工、医疗、农业等多个行业成效显著,验证了“数据-模型-应用-价值”路径的可行性。- 场景为锚:所有有效案例均从具体高价值场景出发,如河钢集团聚焦转炉炼钢“黑箱”控制难题。
- 数据筑基:通过系统性汇聚、治理与标注,将原始数据转化为满足AI就绪度要求的高质量数据集。
- 模型跃迁:基于高质量数据训练的行业大模型与专用智能体,在诊断准确率、生产效率等关键指标上实现突破。
- 价值可测:应用落地带来可量化的经济效益,如成本降低12%、效率提升80%、事故率下降40%等。
- 循环自驱:应用反馈持续优化模型与数据,推动生态向更高水平演进。
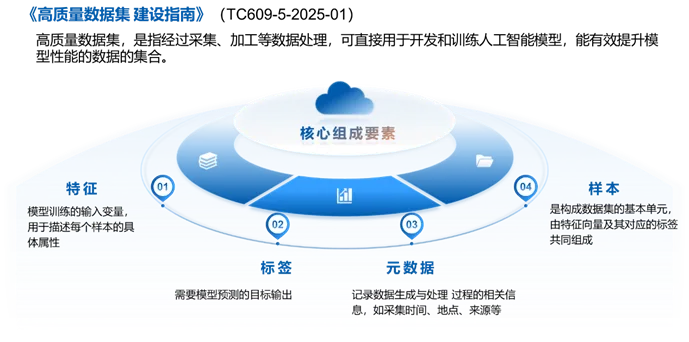
“数据-模型-应用-价值”路径的正向循环不仅提升了人工智能系统的实际效能,更成为推动人工智能与实体经济深度融合的关键引擎。当前,我国行业高质量数据集建设已进入规模化、体系化发展的新阶段,成为推动人工智能与实体经济深度融合的关键基础设施。其发展态势呈现出“规模快速扩张、技术持续演进、政策系统引导”的显著特征。行业高质量数据集是指经过采集、加工等数据处理,可直接用于开发和训练人工智能模型,并能有效提升模型、智能体、智能终端等应用效能的行业数据集合。核心在于从“大数据”向“精炼数据”转变,遵循“先算法,后数据”的路径,即根据AI应用场景需求定向构建数据,而非简单堆砌原始数据。这类数据集被赋予了高知识密度、高技术含量、高价值应用的“三高”特征,是实现“人工智能+”行动的核心载体。根据国家数据局统计数据显示,截至2026年一季度,全国已建成高质量数据集超过11.6万个,总体量超过960PB,相当于中国国家图书馆数字资源总量的336倍左右。数据集的应用活跃度大幅提升,日均Token调用量在2026年3月已突破140万亿,较2025年底增长40%以上。目前,高质量数据集建设主要聚焦于数字化基础好、痛点明确、数据价值密度高的行业,形成了清晰的先行梯队:- 重点推进行业:钢铁、石化化工、有色金属、建材、工业母机、汽车、医疗装备、电力装备、船舶、航空航天、家居、医药、生物制造、电子元器件、消费电子、新型显示、软件、信息通信、网络安全等。
- 共性特征行业:装备制造、电子信息制造、新能源、生物医药、能源与电力、低空经济、新材料等。
- 区域试点:国家先进制造业集群所在区域、中小企业数字化转型城市试点等成为重点推进区域。
高质量数据集的建设正经历深刻的技术范式升级,主要体现在以下四个方面:- 数据模态多元化:从单一结构化数据转向文本、图像、时序数据兼备的多模态体系,覆盖操作手册、图纸、参数等全类型知识。
- 加工方式智能化:由人工标注为主转向“模型预标注+人工校验”模式,引入极端场景数据合成技术补齐长尾数据。
- 流通机制标准化:统一格式、接口、质量评估标准,打破数据孤岛,实现跨企业高效互通。
- 共享模式开源化:依托国家级AI开源社区建设工业数据开源专区,形成行业公共数据资源池。
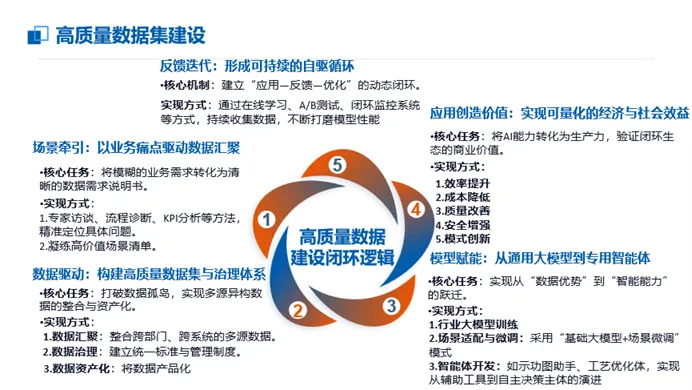
“数据—模型—应用—价值”闭环生态是推动人工智能与实体经济深度融合的核心范式。该生态并非线性流程,而是一个以真实业务场景为起点、以价值创造为目标、以反馈迭代为动力的正向循环系统。其成功运行依赖于四个关键环节的紧密耦合与协同演进。闭环生态的逻辑起点是识别高价值、可量化的业务场景。这些场景通常源于企业生产运营中的“黑箱”难题或效率瓶颈,具有明确的优化目标和效益预期。核心任务:将模糊的业务需求转化为清晰的数据需求说明书。- 通过专家访谈、流程诊断、KPI分析等方法,精准定位具体问题。
- 凝练高价值场景清单,例如《“模数共振”行动》要求每行业凝练不少于30个高价值场景。
典型案例:河钢集团聚焦转炉冶炼过程难以实时监控的“黑箱”问题,通过安装视觉与温度传感器采集炉内数据,为后续数据治理明确了方向。在场景牵引下,原始数据被系统性地汇聚、清洗、标注与治理,转化为满足AI就绪度要求的高质量数据集,成为模型训练的基石。核心任务:打破数据孤岛,实现多源异构数据的整合与资产化。- 数据资产化:将数据产品化,支持API调用与订阅服务。
基于高质量数据集,通过预训练、微调等技术路径,开发出能够解决特定领域复杂问题的垂直领域大模型或专用智能体。核心任务:实现从“数据优势”到“智能能力”的跃迁。- 行业大模型训练:如中国石油利用2.2TB关键时序数据,训练出覆盖主流炼化装置的时序大模型。
- 场景适配与微调:采用“基础大模型+场景微调”模式。钢铁冶金全流程机器视觉数据集支持单场景微调无需从零采集数据,落地效率提升27倍。
- 智能体开发:卡奥斯开发38个石化行业智能体,如示功图助手、工艺优化体,实现从辅助工具到自主决策主体的演进。
模型能力被嵌入到具体的业务流程中,形成智能应用,直接产生可衡量的降本增效成果。核心任务:将AI能力转化为生产力,验证闭环生态的商业价值。应用产生的用户行为日志、预测偏差和新场景需求,被重新收集并用于优化数据集和模型,从而启动新一轮的迭代升级,使整个生态具备自我进化的能力。- 实现方式:通过在线学习、A/B测试、闭环监控系统等方式,持续收集数据,不断打磨模型性能。
推动行业高质量数据集建设,需构建“政策引导、技术突破、模式创新、生态协同”四位一体的实施路径。国家层面已形成多层次政策体系,明确行动目标与制度框架,为高质量数据集建设提供方向指引和资源保障。- 制定专项行动方案:国家数据局发布《关于推进行业高质量数据集建设行动的实施方案(征求意见稿)》,提出到2028年底建成一批覆盖重点领域的行业高质量数据集,并探索词元交易等新型商业模式。
- 推进跨部门协同落地:工业和信息化部与国家数据局联合实施2026年“模数共振”行动,目标是到2026年底基本形成“数据-模型-场景应用”良性互促循环。
- 支持地方先行先试:北京市对数据首登记、首入表企业给予奖励;贵州省设立专项资金,每年安排不超过500万元对训练使用量、数据质量排名前10的市场主体进行激励。
技术创新是破解数据采集、标注、治理等瓶颈的核心动力,重点聚焦智能化处理与安全流通两大方向。- 推广人机协同标注模式:发展“模型预标注+人工校准”、“人工标注+模型检验”等人机协同机制,提升标注效率并降低人力成本。
- 突破极端场景数据合成技术:利用生成式AI创建少样本、零样本下的异常缺陷数据(如设备破损、漏油),补足真实采集难以覆盖的长尾事件。
- 强化隐私保护与可信流通:深化联邦学习、区块链确权、隐私计算等技术应用,实现数据“可用不可见”,破解企业“不愿共享、不敢共享”的难题。
- 构建多模态数据治理工具链:研发支持文本、图像、时序、点云等多源异构数据一体化处理的技术平台,提升数据加工自动化水平。
推动数据要素价值转化,需打破传统“数据包销售”模式,向服务化、资产化跃迁。- 初级阶段:以基础数据包交付、定制化开发为主,满足特定项目需求。
- 中级阶段:发展订阅租赁、API调用、词元(Token)交易等模式,实现按需付费、弹性使用。
- 高级阶段:探索数据信贷、数据资产作价入股、数据保险、资产证券化等金融化路径,释放数据资本属性。
- 鼓励政府率先采购:推动政府部门、国有企业开展数据采购实践,培育市场需求,带动产业生态发展。
高质量数据集建设非单一主体可完成,必须通过机制设计促进多方参与、共建共享。- 创建“模数共振”空间:打造具备跨主体数据可信贯通、模型协同训练能力的软硬件基础设施,支持产业链上下游联合攻关。
- 组建创新联合体:引导算力、模型、数据、应用企业组建“模数共振”创新联合体,整合资源,协同解决共性问题。
- 做强开源社区:依托国家级AI开源社区建设工业数据开源专区,推动形成行业公共数据资源池,降低中小企业使用门槛。
- 培育专业服务商:扶持数据咨询、治理、标注等第三方服务机构发展,壮大产业生态,提升专业化服务能力。
尽管行业高质量数据集建设已取得显著进展,但在迈向规模化、可持续发展的过程中,仍面临一系列深层次的结构性挑战。这些问题横跨标准体系、技术能力、供给机制、商业逻辑与制度环境,亟需系统性应对策略予以破解。- 标准与规范缺失:行业缺乏统一的数据标准与质量评估体系,导致不同主体间数据难以互通互认,重复建设严重,资源浪费突出。数据格式不一、采集误差引发分布偏差、颗粒度参差等问题普遍存在。
- 技术能力薄弱:数据加工自动化水平低,尤其在医疗、建筑等专业领域,高度依赖人工密集型标注,成本高昂且效率低下。多源异构数据采集难度大,缺乏成熟接口与工具链;长尾事件数据稀缺,真实场景难以覆盖。
- 数据供给与协同难题:中小企业自身数据储备不足、治理能力有限,难以独立完成高质量数据集构建。工业企业普遍坚守“数据不出域”安全底线,影响数据可持续供给。可供给数据的企业数量偏少、规模偏小,制约工业AI深度落地。
- 商业模式与价值变现困境:数据成本与价值回报失衡,企业通过数据治理产生利润仍是待解难题。市场回报机制不明,缺乏专门针对行业专识数据集的投资或补贴政策。数据流通慢、责任界定不清,抑制供需双方积极性。
- 生态与制度障碍:存在“不愿共享、不敢共享、不会共享”的行业痛点。跨部门、行业和地区数据标准不统一,互操作性缺失,资源整合困难。数据权属、合规等制度建设滞后,影响高效流通利用。
为有效应对上述挑战,需从制度设计、技术创新、生态培育等维度综合施策,形成协同推进格局,可逐步打通高质量数据集建设的堵点卡点,为“数据—模型—应用—价值”闭环生态的健康运行提供坚实支撑。未名未央管理咨询旗下专注数据要素价值变现的实战研习平台,汇聚了来自中国科学院、北京大学等顶尖机构的专家团队,已成功服务多个地方数据集团与行业龙头,助力其实现数据资产的价值跃迁。我们提供的“高质量数据集诊断与建设全周期咨询服务”,正是为了系统化梳理数据资源和探查数据应用场景,并交付《高质量数据集建设可行性诊断报告》与《行业高质量数据集建设方案》,帮助您从“自查”走向“专业诊断”,从而做出精准的决策。