领取方式1
如需报告原文,请点击上方卡片关注本公众号,后台回复关键词“260436”,即可获取报告下载链接。
领取方式2
扫码加入星球,星球内精选行业报告无限量下载。
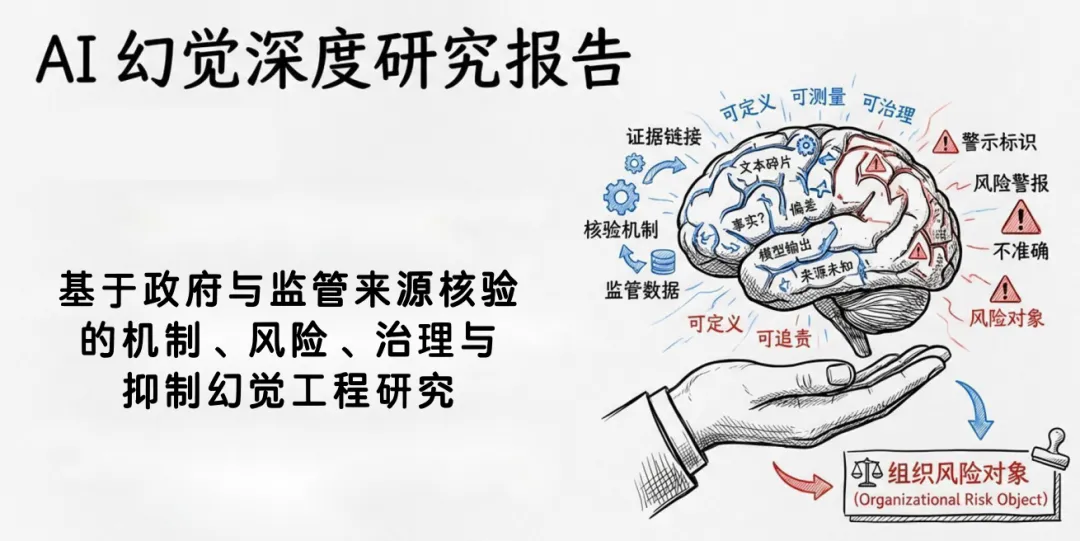
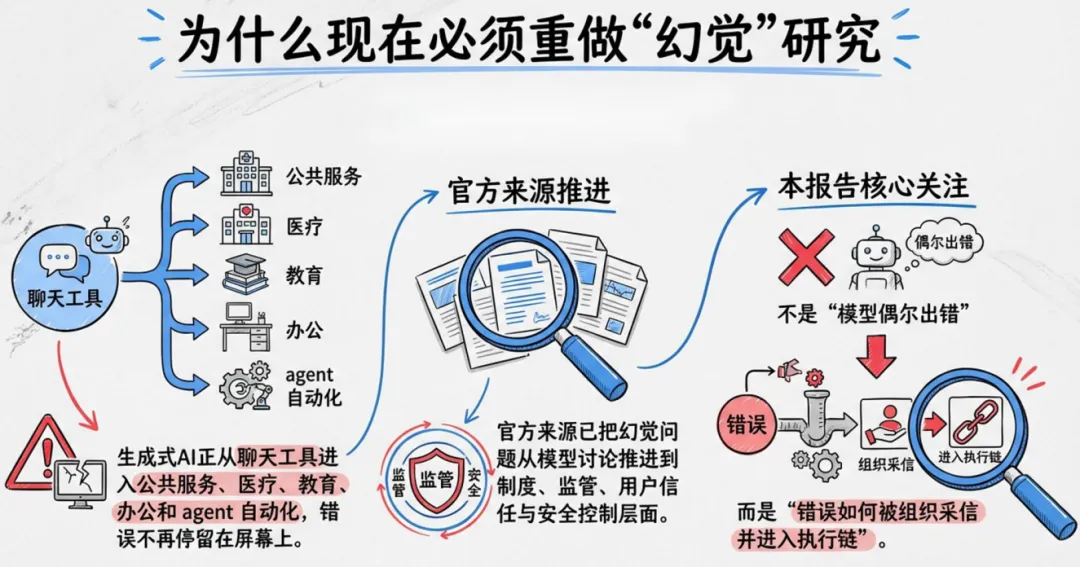
当 AI 进入政务、医疗、法律、办公自动化,幻觉早已不是 “偶尔说错话”,而是会被采信、会被执行、会造成真实损失的系统性风险。清华大学清新研究团队发布 75 页《AI 幻觉深度研究报告》,基于 NIST、FDA、英国政府等官方权威框架,首次把幻觉从模型问题升级为组织治理问题,给出可定义、可测量、可治理的完整方案。
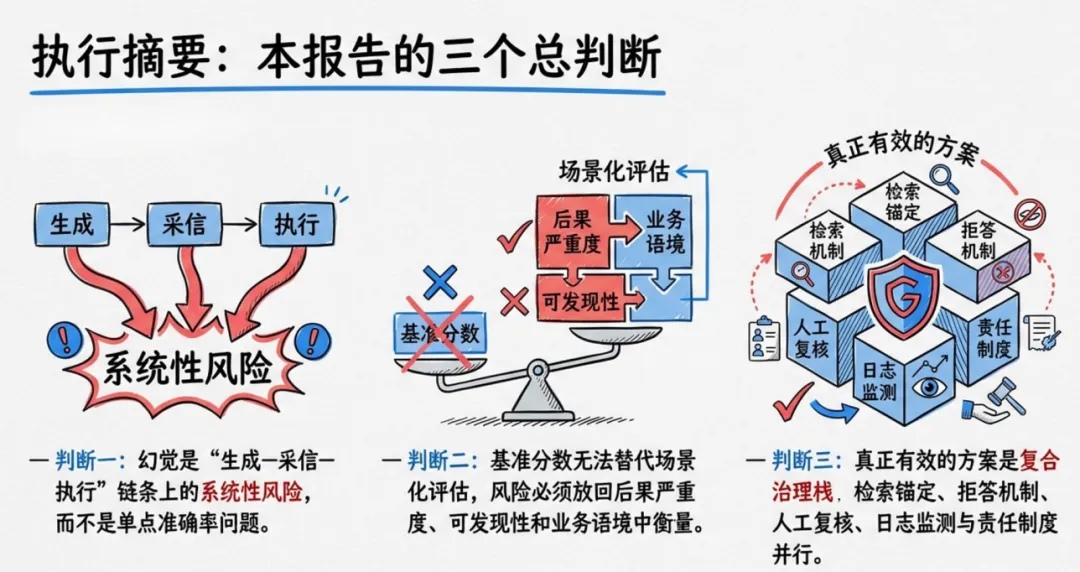
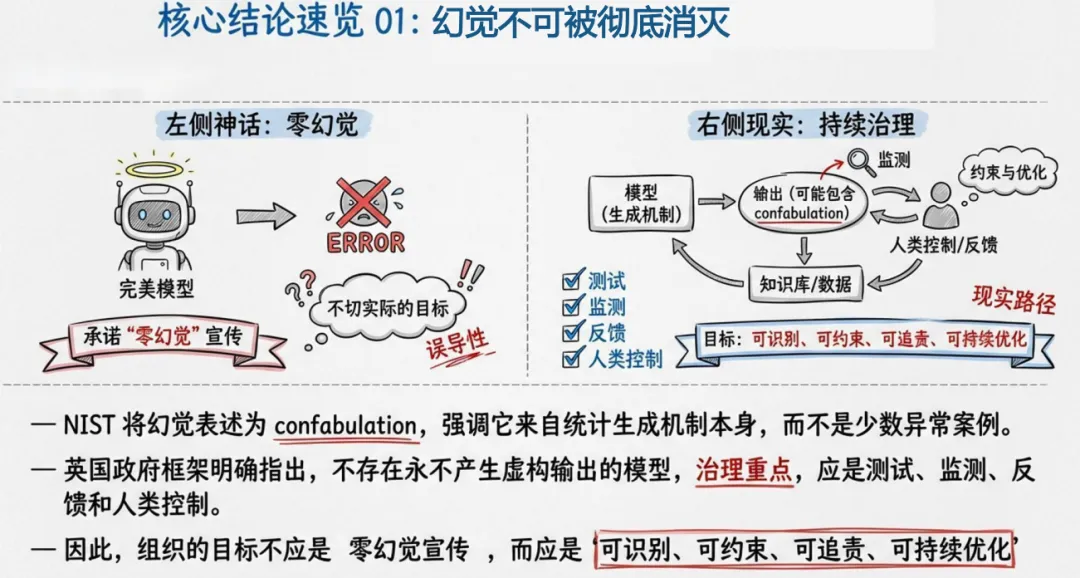
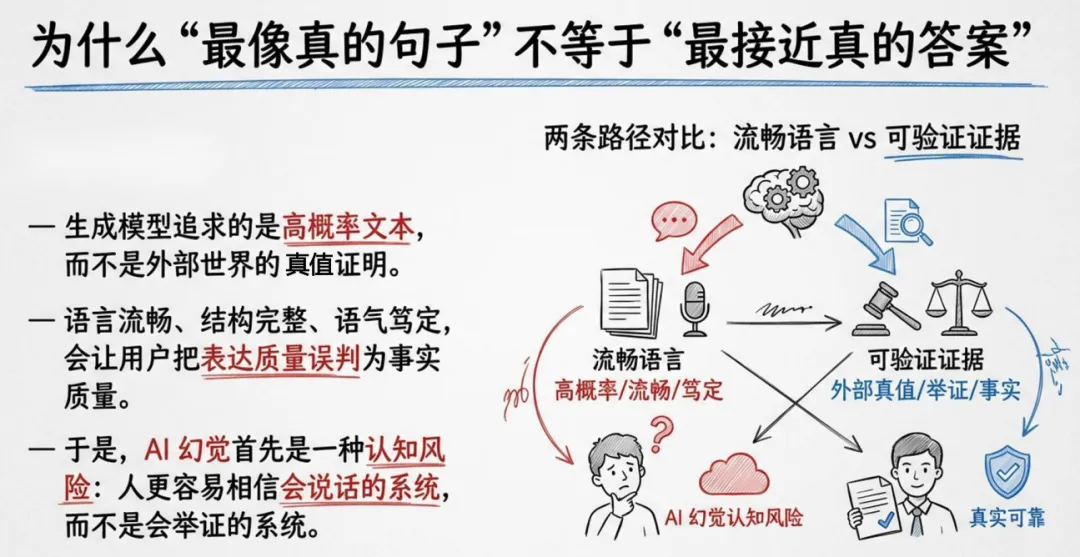
报告核心判断一:幻觉是 “生成 — 采信 — 执行” 链条上的系统性风险,而非单点准确率问题。哪怕实验室准确率 98%,一旦进入真实业务,模糊提问、权威界面、用户过度信任都会放大风险。核心判断二:基准分数无法替代场景化评估,同样错误在娱乐问答无关紧要,在医疗、政务则可能致命,必须结合严重度、可发现性、业务语境判断。核心判断三:不存在零幻觉模型,有效治理一定是检索锚定、拒答机制、人工复核、日志监测、责任制度的复合方案。
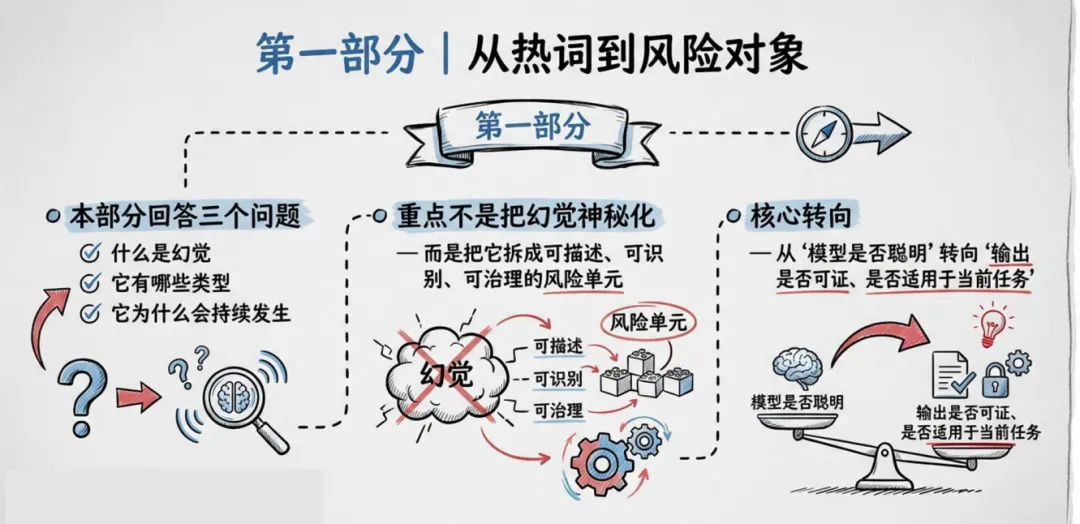
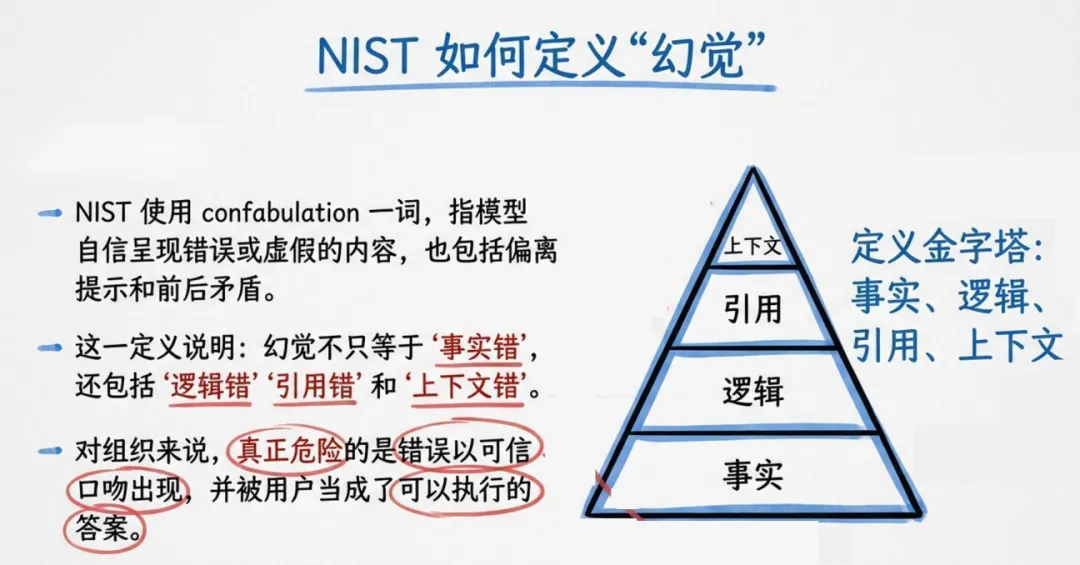
报告将幻觉分为六大类:事实性幻觉编造数据事件,引用性幻觉伪造文献法条,语境性幻觉答非所问,逻辑性幻觉空转推理,行动性幻觉调错工具流程,遗漏性幻觉漏掉关键信息。五大根因清晰可循:统计生成机制天生追求流畅而非真实,专业知识边界容易断层,提示不充分会强迫 AI 乱答,组织追求速度完整感抬高误信率,检索生成错配让 RAG 也无法彻底杜绝幻觉。
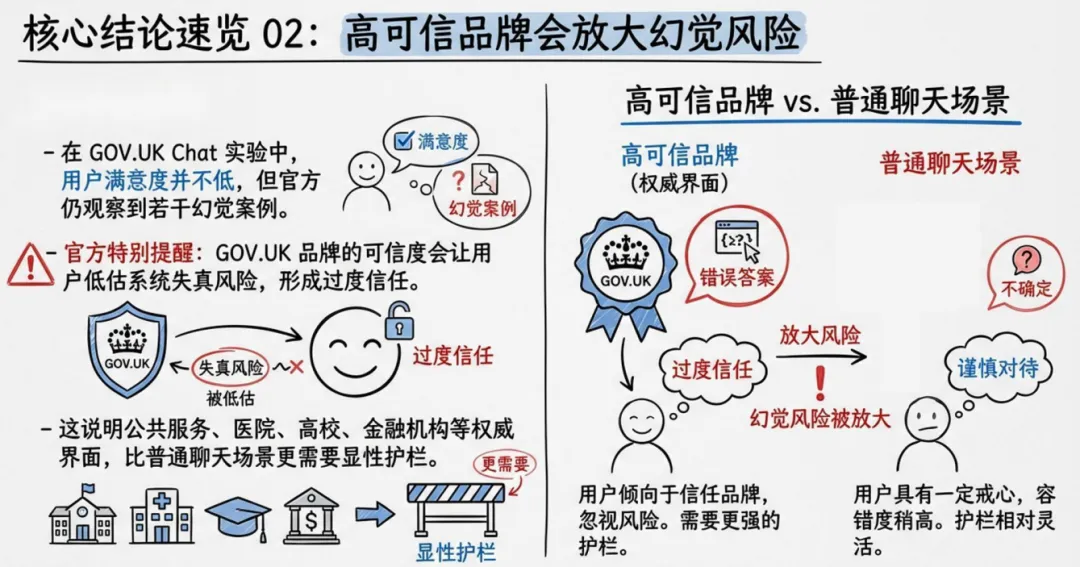
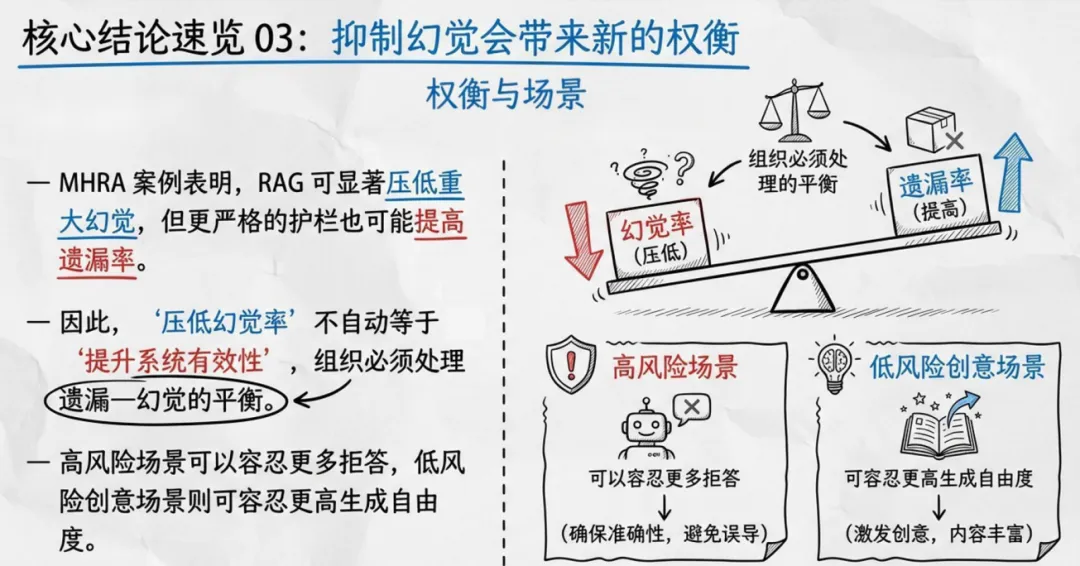
真实世界案例敲响警钟:GOV.UK Chat 因官方品牌放大幻觉风险,用户越满意越容易轻信;美国联邦机构 AI 用例一年增长 9 倍,治理滞后让试验风险变运营风险;MHRA 临床测试证明,RAG 能压低重大幻觉,但会抬高遗漏率,形成 “遗漏 — 幻觉跷跷板”;医疗、法律、学术场景中,引用幻觉会污染知识链条,网络安全场景下幻觉会演变为提示注入与系统边界失守。
报告原创五大概念,帮组织精准识别风险:概率真相陷阱是把流畅当真实,引用幻影链是伪造来源制造可信假象,低置信高伤害区是让 AI 处理高风险任务,遗漏 — 幻觉跷跷板是安全与信息完整的平衡难题,责任折返门是无效复核导致的责任悬空。最终提出抑幻觉六层栈:任务分级、知识锚定、生成约束、验证校正、上线监控、责任治理,从能不能回答一直覆盖到出了错谁负责。
幻觉无法消灭,但可治理。未来组织的真正竞争力,不是让 AI 无所不知,而是让 AI 知道何时停下、何时拒答、何时交给人类。