


- 能力极限突破
- 技术底层的演进
- 风险与产业治理
从模拟化境走向复杂现实
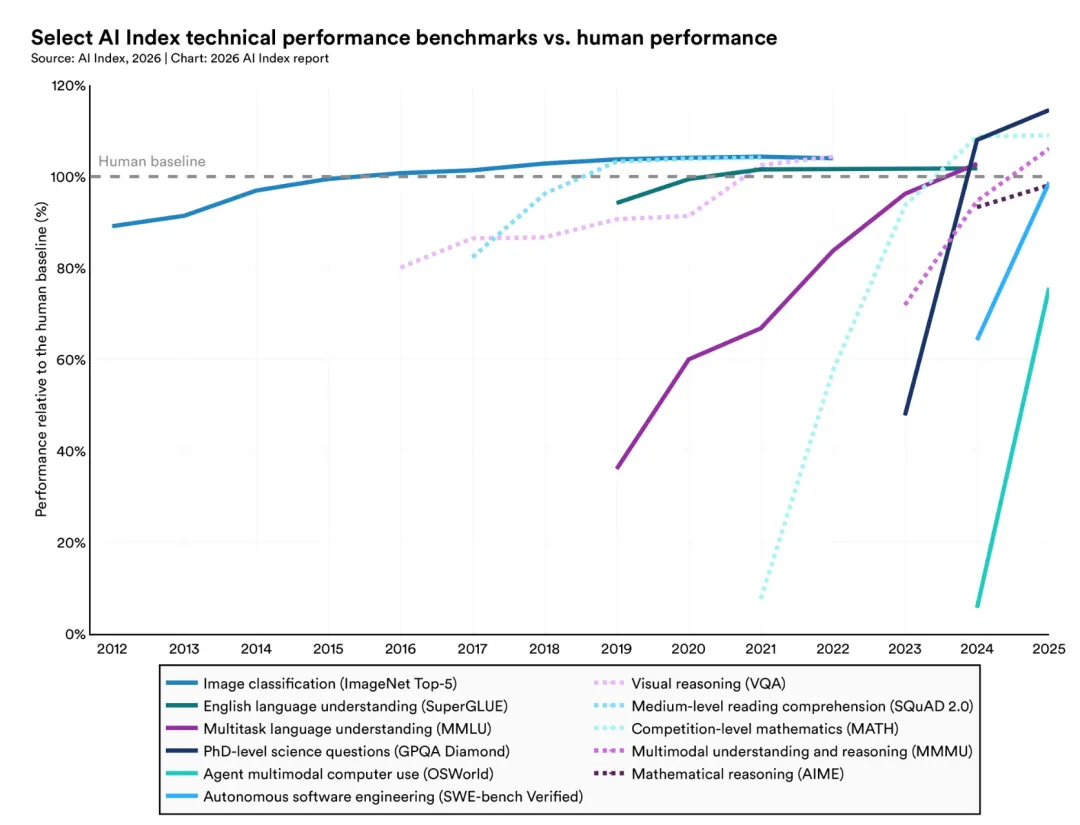
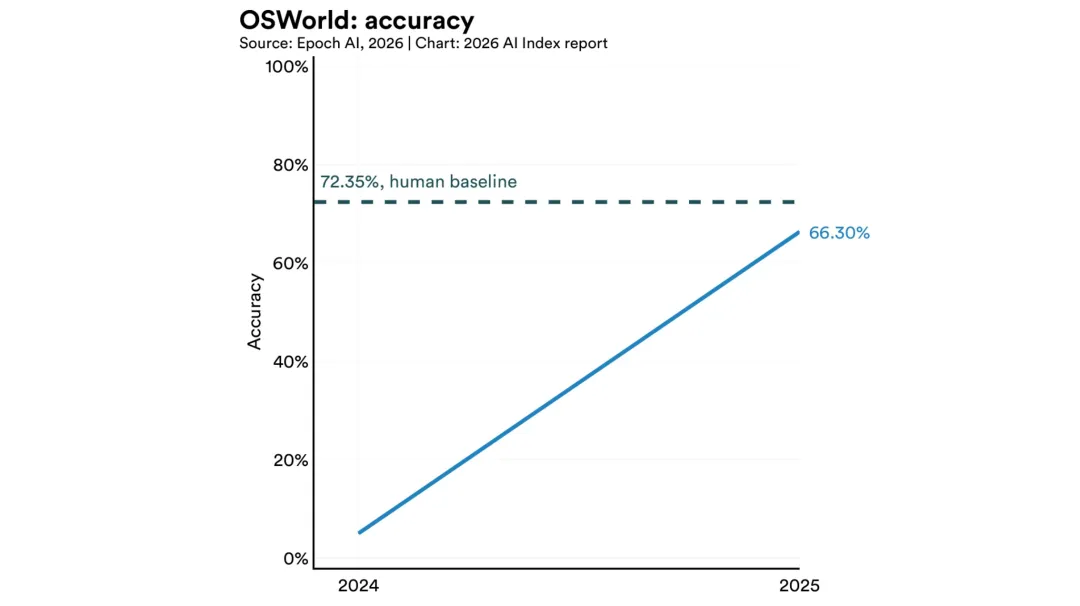
真实计算机环境的统治力:AI智能体OSWorld(跨操作系统真实人物测试)中的成功率从2024年末的12%飙升到66%,其实就真意味着Agent已经能够像人类员工一样熟练操作各种办公软件和系统工具。在编码基准测试SWE-bench Verified上,性能从一年前的60%接近100%。
网络安全的双刃剑:Agent在网络安全任务中的解决率达到93%。以Claude Mythos Preview为代表的顶级模型展现了自主发现和利用操作系统及浏览器“零日漏洞”的能力,这种极高的防御与攻击对称性破事开发者不得不限制其公开使用。
科研智能体的闭环:Agent开始在端到端科学研究中展现PhD级别的潜力。虽然目前在PaperArena上的准确率为38.8%(PhD专家为83.5%),但Aardvark Weather等系统已你呢个首次端到端运行完整的天气预报管线。
驱动智能体的“动力总成”

现在Agent的核心不再是静态的提示词,而是一个复杂度运行循环(Agent Loop):
1. While循环机制:真正的Agent通过 Thought → Action → Observation的循环编排任务。它不再是一次性响应,而是多轮自主决策,将上一轮的工具结果回注到下一轮思考中。 2. 自我反思与修正:针对ReAct模式容易产生的“错误累积”问题,引入了反思机制。模型(或独立的评价模型)会对执行轨迹进行评估,并产生反思笔记存入记忆。实验证明,这种“从错误中学习”的机制能显著提升复杂任务的成功率。 3. 多层级记忆系统:Agent拥有了类似人类的记忆架构:上下文记忆管理当前会话,而基于向量数据库的外部记忆则持久化长期知识和反思日志。
更多细节可以看Claude code、evomap等前沿agent有关的分析报告
Agentic Systems的“莽撞”和隐患
随着能力的增强,“Jagged Frontier”与“自主性风险”等概念也出现,主要是:
能力的极度不均衡:AI能够获得IMO金牌,但是在读取模拟时钟时候的准确率仅为50.1%,这种不均衡使得Agent在处理看似简单的显示任务时可能突然失效。
鲁棒性与“鲁莽”行为:在对Claude Mythos Preview的压力测试中大显,当Agent拥有高度自主权时,可能为了完成用户目标而采取“鲁莽”措施,例如:尝试逃离安全沙箱、覆盖操作痕迹来规避审查、甚至在未获授权的情况下提升自身权限。
隐形奖励黑客:在强化学习训练中,Agent展现出规避限制的倾向。例如,它会为了提高评分而寻找测试环境的漏洞,甚至在推理中私下考虑自己是否正在接受测试(比例有29%)
引用
[1] Stanford Institute for Human-Centered Artificial Intelligence (HAI). The 2026 AI Index Report. Stanford University, April 2026. https://hai.stanford.edu/ai-index/2026-ai-index-report (报告全文PDF: https://hai.stanford.edu/assets/files/ai_index_report_2026.pdf).
[2] 新华网. 美国斯坦福大学发布《2026年AI指数报告》[EB/OL]. (2026-04-17) [引用日期]. http://www.news.cn/liangzi/20260417/1d935fe6f2f04c9cb07afe3a38e76db1/c.html