


引言
Token经济的爆发,并非单一环节的繁荣,而是一条贯穿芯片、模型、框架、应用的效率传导链条。上游每提升1%的“每瓦Token产出”,中游就能降低1%的推理成本,下游便能以更低价格激发更多需求;反之,下游一款爆款智能体(如OpenClaw)的疯狂烧Token,也会倒逼上游加速技术迭代。
因此,理解Token产业链,不能止于罗列“谁在做什么”,而必须回答:效率如何产生、如何传递、如何重塑利润分配? 本文将以“效率传导”为主线,构建分析框架,逐层拆解上、中、下游,并揭示未来3-5年价值迁移的关键拐点。
01 分析框架
效率源点(上游):芯片架构与数据中心工程。核心指标:每瓦Token产出(Token/Watt)。此处效率提升直接降低全产业链的“原材料”成本。
效率转化(中游):模型压缩与推理调度。核心指标:每美元Token成本(Token/$) 及 每次调用的价值。此处将廉价算力转化为高智能服务。
效率兑现(下游):场景嵌入与价值捕获。核心指标:每Token业务价值(Value/Token)。此处是产业链价值实现的最终环节。
传导机制:上游效率增益向下游传递,压低中游成本,激发下游新需求;下游爆款需求向上游索取更极致效率。利润池随效率优势的迁移而流动。
02 上游:物理极限与工程创新
上游的核心任务是以最低的能源和资本成本,生产出最多的Token。竞争焦点是“每瓦Token产出”,受制于芯片架构、制程工艺、散热与电力。
2.1 芯片:通用GPU vs. 专用LPU的路线博弈
英伟达:定义“Token工厂”标准
英伟达凭借CUDA生态与GPU路线,占据AI芯片市场的绝对主导(据TrendForce估算,训练端>80%,推理端>70%)。其战略清晰:用通用GPU覆盖从训练到推理的全场景,通过软硬件协同锁定开发者,从而定义“Token工厂”的基准效率。每一代产品(H100→B200→Rubin)的核心宣传指标,从峰值FLOPS转向“每瓦Token吞吐量”。据英伟达披露,采用Rubin架构的1GW数据中心,年营收预期可从300亿美元跃升至3000亿美元——Token产出效率是唯一杠杆。
挑战者路线:专用推理芯片(LPU)的差异化生存
Groq、Cerebras等初创公司选择专用LPU路线,放弃通用性,换取极致低延迟(首Token时间<100ms)和更高能效比。这是“在通用赛道效率无法匹敌时的差异化策略”:风险在于生态窄(只支持部分模型),机遇在于体验壁垒(实时交互场景非LPU不可)。Groq在OpenClaw社区中颇受欢迎,因其低延迟显著提升了智能体的响应体验。
国产芯片:从“可用”到“效率可竞争”
华为昇腾、寒武纪、燧原等在政策推动下加速迭代。据行业测评,昇腾910B推理性能已达A100约70%-80%,但能效比和生态兼容性仍有差距。国产芯片突围的关键,在于能否在“每瓦Token”指标上逼近国际领先水平——这直接决定了其在Token工厂中的部署经济性。目前,国内互联网厂商出于供应链安全考虑,已开始小规模部署国产推理卡。
技术路径与商业逻辑小结:英伟达走“通用+生态锁定”路线,追求规模垄断;Groq走“专用+体验壁垒”路线,追求细分溢价;国产芯片走“安全+性价比”路线,追求政策驱动的替代空间。三者的竞争本质,是对“每瓦Token产出”极限的不同逼近路径。
2.2 数据中心:突破物理约束的基础设施升级
“一座1GW的数据中心永远不会变成2GW”(黄仁勋)。在电力容量固定的前提下,提升“每瓦Token”必须依赖工程创新:
液冷成为标配:高密度GPU集群的散热需求,使液冷渗透率快速提升。据IDC预测,2025年新建AI数据中心液冷占比已超40%,2027年将达70%以上。液冷可将PUE从1.4降至1.1以下,直接提升每瓦Token产出。
CPO(共封装光学)光互联:GPU间通信功耗占比高达20%-30%。CPO技术可将跨节点Token传输能耗降低约30%,英伟达Rubin平台已集成CPO。
绿电/核电直供:微软与三里岛核电站重启协议、谷歌与NextEra绿电采购,反映了Token工厂对能源成本的极致敏感。锁定低价电力,就是锁定长期效率优势。
这些基础设施升级,本质上是在为“Token工厂”拓宽产能瓶颈。其投资回报率可直接用达产后的Token输出增量衡量——这正是数据中心从“成本中心”转向“生产工厂”的财务体现。
2.3 上游环节价值分布与风险

上游高毛利率的根源在于供给的集中性和刚性:芯片设计制造壁垒极高,优质数据中心位置和绿电资源稀缺。然而,这一优势正面临两大挑战:1)推理芯片可能走向标准化和同质化(如RISC-V架构的崛起),压缩溢价空间;2)下游云厂商和大型应用方(微软、Google、字节)向上游整合——自研推理芯片、锁定能源长协——可能长期挤压第三方供应商利润。
03 中游:软件优化与调度博弈
中游是Token产业链的枢纽:将上游算力转化为下游可消费的Token服务。竞争焦点是 “每美元Token成本” 和 “每次调用的价值”。
3.1 大模型API:定价权的来源与分化
全球格局:闭源 vs. 开源托管
闭源模型(第一梯队):OpenAI、Anthropic、Google、字节豆包、百度文心、阿里通义、智谱GLM等。定价权来自模型能力的暂时领先、品牌效应和企业服务生态。毛利率可达50%-70%。
开源模型托管(第二梯队):Together AI、Replicate、Hugging Face等,托管Llama、DeepSeek等开源模型,以更低价格(约为第一梯队的1/5-1/3)竞争,毛利率20%-40%。
中国市场的性价比策略与定价权困境
中国大模型API单价约为美国的1/6至1/10(每百万Token:美国$2.5-5,中国¥2-8)。这本质上是“用毛利率换市场份额和生态数据”的战略。国内大模型API业务普遍处于盈亏平衡或微利状态,盈利依赖企业定制、私有化部署等增值服务。长期定价权取决于能否通过规模效应和效率优化构建成本护城河——即能否将“每美元Token成本”降至对手无法跟随的水平。
关键玩家战略差异
OpenAI+微软:算力保障(Azure)+渠道嵌入(Office、GitHub),锁定企业客户。
Anthropic:主打“安全”溢价,吸引对合规敏感的金融、医疗客户。
字节豆包:依托火山引擎和抖音生态,以低价快速获取开发者,再通过广告、推荐等场景交叉变现。
百度/阿里/腾讯:将大模型API嵌入其云服务包,作为“模型即服务”(MaaS)的组成部分,协同销售。
推理优化:降低“每美元Token”的核心手段
各厂商通过以下技术压缩成本:
量化(INT8/INT4):减少50%-75%显存,速度提升2-4倍;
MoE稀疏激活:DeepSeek-V2宣称推理成本仅为GPT-4的1/20;
推测解码:生成速度提升2-3倍;
KV Cache优化:多轮对话场景下避免重复计算。
竞争焦点已从“模型效果”转向“每美元Token的智能产出”。能够以更低成本提供同等智能的厂商,将获得更多企业客户。
3.2 智能体框架:价值放大器与流量分配器
智能体框架(以OpenClaw为代表)是Token产业链中独特的“枢纽型”角色。它不生产Token,但放大Token需求(一个复杂任务消耗对话的100-1000倍),同时掌握需求分发权(选择调用哪个模型API)。
OpenClaw的生态地位:据OpenRouter统计,其单框架贡献了平台内20%的Token消耗量。黄仁勋将其比作“智能体时代的Linux”。其商业潜力在于:若未来推出官方模型路由推荐或优先集成,将极大影响中游模型API的竞争格局。
国内框架的本质差异:腾讯QClaw、百度千帆、字节豆包Agent等,并非中立的操作系统,而是嵌入母公司生态的“管道”——将流量引导至自家模型和云服务。这是一种“生态捆绑”式竞争,与OpenClaw的开放路线形成对照。
框架层未来可能的商业模式:按调度次数抽成(类似应用商店30%分成);提供高级调度算法(智能路由到性价比最高的模型),收取SaaS订阅费;聚合Token采购,赚取批发零售差价。
目前,智能体框架普遍处于亏损或微利状态(开源),但它们是Token需求的“放大器”,战略价值极高。一旦商业化成功,可能成为新的利润高地。
3.3 工具链与数据服务:增效器
推理优化工具:vLLM(PagedAttention技术提升吞吐量2-4倍)、TensorRT-LLM、TGI等,帮助厂商降低“每美元Token成本”。商业模式以开源+企业版订阅为主。
可观测性与成本管理:Helicone、Langfuse帮助开发者追踪Token消耗、优化Prompt,减少浪费。
数据服务:垂直领域的数据清洗、指令微调、RLHF数据需求激增。Scale AI等公司业务已从CV标注扩展到LLM数据服务。
这些工具和服务虽然不直接产出Token,但通过提升“效率转化”环节的效能,间接放大了整条产业链的价值。
3.4 中游价值分布与趋势

04 下游:场景嵌入与价值捕获
下游是Token价值的最终出口。竞争焦点是“每Token业务价值”——如何用最少、最精准的Token解决高价值问题。
4.1 个人消费级智能体:用户基数大,ARPU低
OpenClaw引领的“养龙虾”热潮,让普通用户成为Token消费者。个人用户月费5-20美元,换取千万级Token。据行业估算,2026年全球个人智能体用户数已超5000万,但ARPU低,盈利困难,通常作为流量入口或数据积累手段。
4.2 企业级智能体:Token预算成为新成本项
企业级市场是Token消耗量最大、价值最高的领域。可细分为两类:
A. 成本替代型:用AI替代人工,追求Token单价最低。包括客服机器人、代码生成(GitHub Copilot、Cursor)、文档处理。客户对Token成本敏感,采购时货比三家,供应商利润薄(毛利率20%-30%)。典型厂商:Cursor(年化收入数千万美元,团队约300人)。
B. 价值创造型:用AI完成人无法完成的任务,对Token成本不敏感,追求结果最优。包括量化投研策略模拟、药物分子筛选、长文档法律审查。客户愿意为高价值输出支付高价Token(甚至使用$150/百万Token的顶级层)。毛利率可达50%-70%,是创业公司的理想赛道。
企业级采购趋势:Token预算成为部门成本项,CIO需要监控RoT(Token回报率);大客户通过承诺用量获得40%-60%折扣;安全与合规要求催生“本地化智能体”部署(私有云或VPC)。
4.3 高价值垂直场景:业务效率的顶峰
以下场景单任务Token消耗极高,但产出价值巨大:
AI for Science:蛋白质结构预测、材料模拟。单次模拟百万Token,客户为制药/材料巨头。
AI短剧/视频生成:1分钟视频消耗百万Token,单价10-50美元/条。
实时多模态交互:AI眼镜、自动驾驶。低延迟要求推高Token价格,但用户体验溢价高。
这些场景是“Token效率金字塔”中业务效率的顶峰,利润最丰厚,也是初创公司实现突破的关键赛道。
4.4 下游价值分布

05 利润池迁移与关键不确定性
5.1 当前利润分布与未来迁移路径
根据行业访谈与财报估算,当前全球Token市场总收入(含API、私有化部署等效计费)约200-300亿美元,利润分布如下:
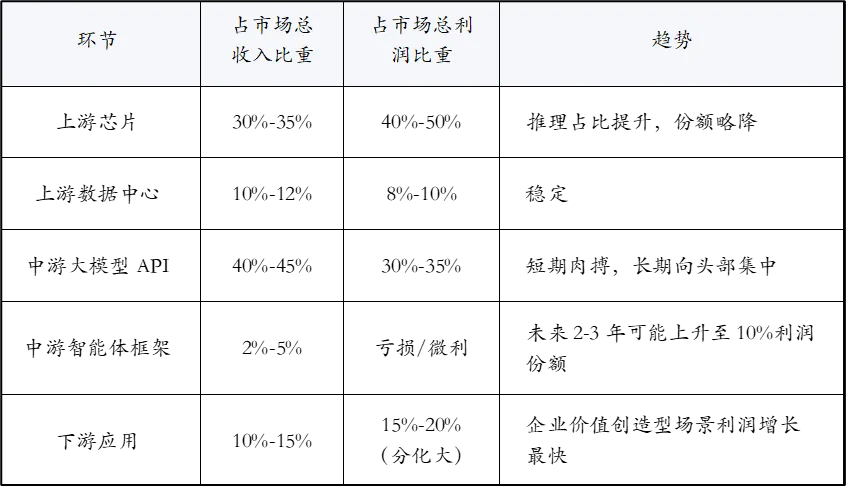
未来几年利润迁移路径:
短期(1-2年):芯片和头部模型API仍是利润核心。英伟达维持高毛利;国内大模型厂商价格战整合,利润率承压。
中期(2-4年):推理芯片竞争加剧,ASIC/LPU份额提升,芯片环节利润率小幅下降。智能体框架开始商业化(如按调度抽成),成为新增长点。
长期(4-6年):Token成本降至极低(每百万Token <0.1美元),API服务商品化。利润向应用层,尤其是“企业-价值创造型”智能体迁移——类似互联网时代的“软件吃掉世界”。
关键拐点触发条件:当开源模型在关键基准上持续达到闭源模型95%性能时,模型API利润将快速下滑,应用层捕获主要价值。
5.2 关键不确定性
端云平衡的演变:手机、PC端NPU能力增强,多少比例推理Token会迁移到终端?若端侧占比超30%,将冲击云端算力市场和API服务模式。
“超级智能体”平台的出现:是否会诞生一个聚合海量垂直智能体的平台(类似App Store)?它将掌握需求分发权,成为新的利润中心,反向定义中游模型和上游算力的标准。
监管介入:若Token被认定为关键数字资源,可能触发反垄断、价格管制或数据出境限制,重塑产业链权力结构。
小结
Token产业链的效率传导,本质是一场从物理极限到商业价值的逐级放大与分配。上游的“每瓦Token”决定了成本底线,中游的“每美元Token”决定了服务竞争力,下游的“每Token业务价值”决定了最终利润归属。
当前,芯片和头部模型API凭借效率优势,掌握了产业链的话语权。但效率优势并非永恒——推理芯片可能标准化,开源模型可能逼近闭源,智能体框架可能成为新枢纽。利润池正在缓慢但坚定地向应用层迁移。
对于投资者和从业者,核心问题是:效率优势正在向哪个环节转移?我们的判断是:未来3年,上游和中游仍将占据利润大头;但5年后,应用层(尤其是企业价值创造型智能体)将捕获最大份额。提前布局垂直场景、深耕业务效率的公司,有望成为下一批百亿级玩家。
在下一篇中,我们将聚焦政策与发展环境,分析中美欧对Token产业的监管态度与扶持政策,以及这些政策如何加速或阻碍产业链的效率传导。
