


第一章 概述:发布背景与核心定位
2026年4月16日深夜,Anthropic 正式发布了其最新旗舰大语言模型 Claude Opus 4.7。这是对 Opus 4.6 的直接升级,官方将其定位为**"目前能力最强的通用可用模型"**(The most capable general-purpose model available today)。

1.1 核心升级方向
Opus 4.7 重点强化了以下五大能力维度:
能力维度 | 升级内容 | 提升幅度 |
|---|---|---|
编程能力 | 软件工程任务表现大幅提升 | 生产任务解决量提升3倍 |
视觉能力 | 支持375万像素图片输入 | 分辨率提升3倍以上 |
Agent能力 | 长程任务一致性增强 | 自我验证机制 |
指令遵循 | 逐字级精准执行 | 字面化程度提升 |
记忆能力 | 长时段任务间保持记忆 | 跨会话连续性增强 |
1.2 定价策略
令人惊喜的是,Opus 4.7 的定价与 Opus 4.6 保持一致:
定价项 | 价格 |
|---|---|
输入token | $5 / 百万token |
输出token | $25 / 百万token |
1.3 可用平台
Opus 4.7 已在以下平台同步上线:
✅ Anthropic API & Claude 产品
✅ Amazon Bedrock
✅ Google Cloud Vertex AI
✅ Microsoft Foundry
第二章 核心升级深度解析
2.1 编程能力:三倍跃升的奥秘
软件工程能力是 Opus 4.7 最耀眼的升级方向。在多项权威编程基准测试中,Opus 4.7 实现了质的飞跃。
2.1.1 基准测试表现
基准测试 | Opus 4.7 | Opus 4.6 | 竞品对比 |
|---|---|---|---|
SWE-bench Pro | 64.3% | 53.4% | GPT-5.4: 57.7% |
SWE-bench Verified | 87.6% | 80.8% | — |
Terminal-Bench 2.0 | 69.4% | — | — |
OSWorld-Verified | 78.0% | — | — |
CursorBench | 70% | 58% | +12pp |
Rakuten-SWE-Bench | 3x | 1x | — |
2.1.2 关键特性:规划阶段自我捕获错误
Opus 4.7 在开始执行前会主动检查逻辑错误,而非执行到一半才发现问题——这大幅降低了长链路任务的失败率。
# Opus 4.7 的自我验证机制示意def opus_47_self_verification(): """ 1. 理解用户需求后,先制定验证计划 2. 执行过程中持续对照验证标准 3. 输出前进行最终一致性检查 """ plan = understand_and_plan() verification_criteria = design_verification(plan) result = execute_with_monitoring( plan, verification_criteria ) return final_self_check(result)2.1.3 企业级验证
Hex评价 Opus 4.7 为"测试过最强的模型":
"它能正确报告数据缺失,而不再编造看起来合理的回答。"
Notion的工具调用准确率和规划能力提升超过 10%,更难得的是,它是**第一个通过隐式需求测试(implicit-need tests)**的模型。
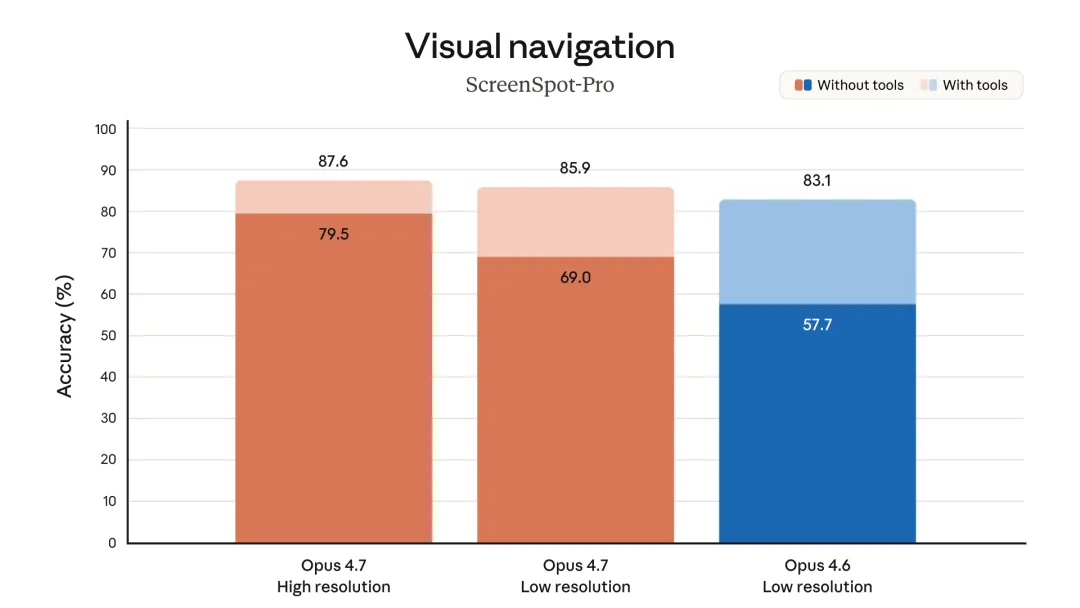
2.2 视觉能力:分辨率翻三倍
2.2.1 核心参数提升
指标 | Opus 4.7 | Opus 4.6 | 提升 |
|---|---|---|---|
最大图像分辨率(长边) | 2576px | ~860px | 3倍+ |
像素量 | ~375万像素 | ~74万像素 | 5倍 |
XBOW 视觉准确率 | 98.5% | 54.5% | +44pp |
CharXiv 推理 | 82.1% | 69.1% | +13pp |
2.2.2 应用场景拓展
计算机控制Agent:可以读取密集截图
复杂图表:数据提取更准确
像素级精度:需要精确视觉判断的工作
审美品味:更具品味和创造力的界面、幻灯片生成
2.3 Agent 与记忆能力增强
2.3.1 长程任务一致性
Opus 4.7 在长时间运行的任务中具备更高的一致性,能够:
更稳定地处理复杂、耗时的任务
在执行过程中更严格地遵循用户指令
输出结果前对自身产出进行自我验证
2.3.2 记忆机制
# 多步骤任务的记忆保持class Opus47Memory: """Opus 4.7 的增强记忆机制""" def __init__(self): self.context_window = "200K+" # 长上下文窗口 self.cross_session_memory = True # 跨会话记忆 self.long_term_anchors = [] # 长期任务锚点 def maintain_memory(self, task, step): """长时段任务间保持记忆连贯性""" if self.is_long_running_task(task): self.update_anchors(step) self.maintain_coherence()第三章 基准测试深度分析:与竞品的全面对比
3.1 编程能力横向对比
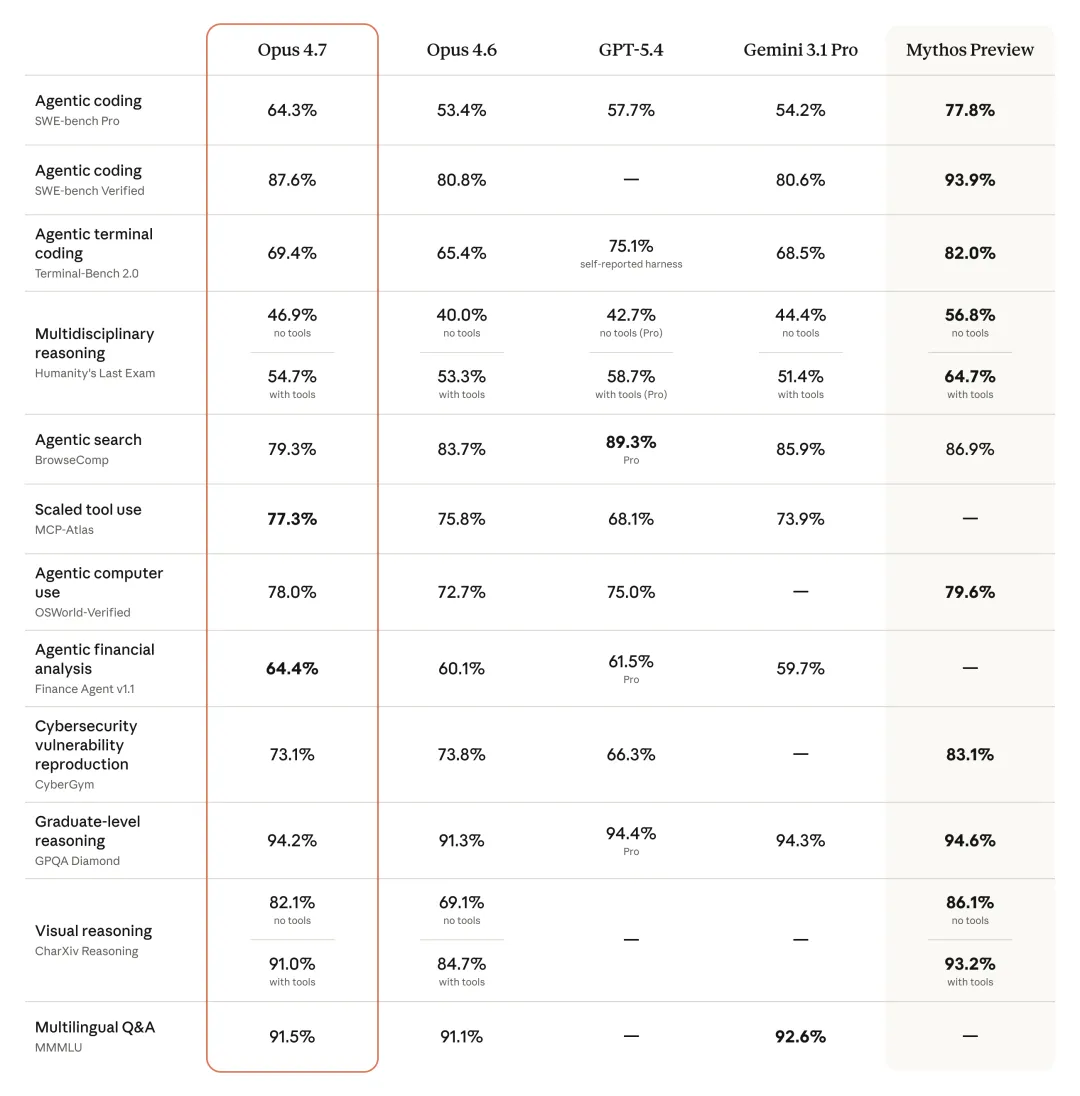
基准测试 | Opus 4.7 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|
SWE-bench Pro | 64.3% | 57.7% | 54.2% |
MCP-Atlas | 77.3% | — | — |
93项编码基准 | +13% | — | — |
3.2 长上下文检索能力
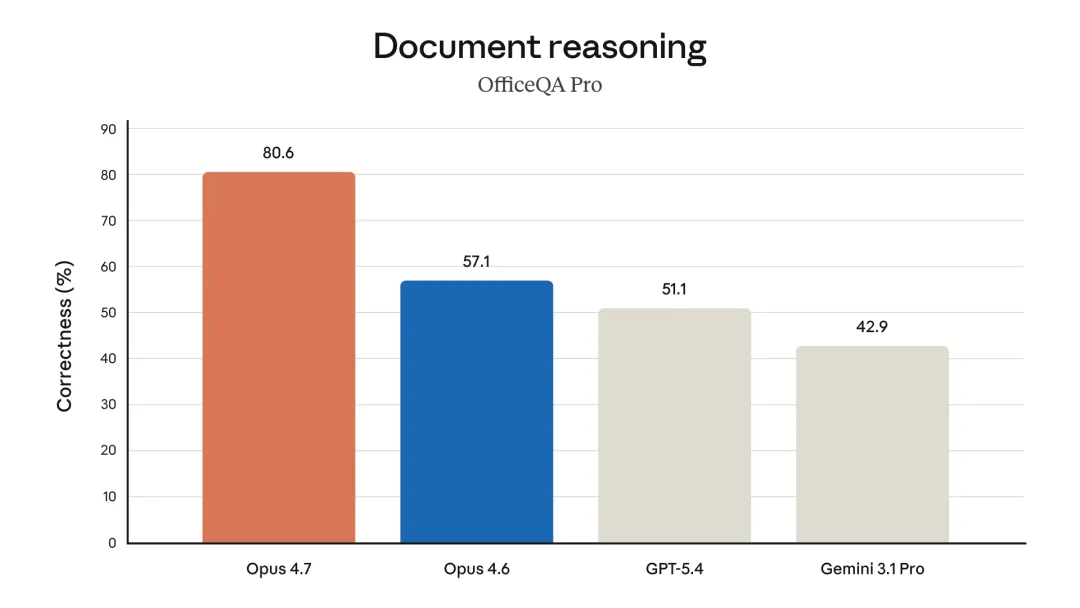
在 OfficeQA Pro评测中(要求解析近9万页美国财政部历史文件,涵盖近100年公报、2600万个数字):
模型 | 得分 |
|---|---|
Claude Opus 4.7 | 80.6% |
GPT-5.4 | 51.1% |
Gemini 3.1 Pro | 42.9% |
数据来源: Anthropic 官方评测及 Databricks 联合评测
3.3 各维度能力雷达图
编程能力 ▲ /|\ / | \/ | \/ | \/ | \/ | \/ | \────────┼───────→ 视觉能力\ | /\ | /\ | /\ | /\ | / \ | / ▼综合能力第四章 Project Glasswing 安全机制
4.1 差异化削弱策略
Opus 4.7 是 Anthropic "Project Glasswing(玻璃翼)"计划下首个应用新型网络安全防护的模型。
4.1.1 核心安全措施
安全措施 | 说明 |
|---|---|
差异化削弱 | Opus 4.7 的网络攻防能力被刻意弱化,不及 Claude Mythos Preview |
自动检测拦截 | 内置违禁用途检测和拦截机制 |
高风险请求拦截 | 可自动检测并拦截高风险网络安全请求 |
Cyber Verification Program | 安全专业人士可申请加入用于合法安全研究 |
4.1.2 与 Mythos Preview 的关系
特性 | Opus 4.7 | Claude Mythos Preview |
|---|---|---|
定位 | 通用旗舰模型 | 前沿安全模型 |
访问权限 | 全面开放 | 仅限部分企业客户 |
网络安全能力 | 已削弱 | 完整保留 |
安全防护 | 已部署 | 额外企业级防护 |
4.2 Anthropic 官方声明
"我们在发布 Opus 4.7 的同时部署了安全防护措施,可自动检测并拦截违禁或高风险的网络安全请求。这些实际部署经验将助力我们实现最终目标,即广泛发布 Mythos 级别的模型。"
第五章 API 与开发者工具
5.1 定价详情
模型 | 输入价格 | 输出价格 | 上下文窗口 |
|---|---|---|---|
Claude Opus 4.7 | $5/M tok | $25/M tok | 200K+ |
Claude Sonnet 4 | $3/M tok | $15/M tok | 200K+ |
Claude Haiku 4 | $0.25/M tok | $1.25/M tok | 200K+ |
5.2 API 调用示例
from anthropic import Anthropicclient = Anthropic()# 使用 Opus 4.7 进行编程任务message = client.messages.create( model="claude-opus-4.7-20250416", max_tokens=4096, messages=[ { "role": "user", "content": "帮我实现一个高性能的排序算法,需要支持自定义比较函数" } ])print(message.content)5.3 Claude Code 史诗级升级
Claude Code 同步完成重大升级,新增功能:
Agent Teams:多Agent协作
增强的长程任务处理:处理复杂耗时任务
改进的自我验证:输出前自动检查
第六章 企业应用场景
6.1 企业案例
企业 | 应用场景 | 评价 |
|---|---|---|
Hex | 数据分析 | "测试过最强的模型",能正确报告数据缺失 |
Notion | 工具调用与规划 | 准确率提升10%+,首个通过隐式需求测试的模型 |
Cursor | IDE编程辅助 | CursorBench 70%(提升12pp) |
6.2 金融领域应用
Finance Agent 评估得分:0.813(Opus 4.6: 0.767),提升 6%
6.3 渗透测试与安全研究
XBOW 渗透测试基准:从 54.5% 飙升至 98.5%
第七章 争议与反思:用户反馈的"负升级"问题
7.1 社区反馈
尽管 Opus 4.7 在多项基准测试中表现优异,但也引发了部分用户的质疑:
"最强AI也跌落神坛?Claude Opus 4.7 被指负升级:国内外都在喷"
7.1.1 主要争议点
争议项 | 说明 |
|---|---|
长上下文下降 | MRCR v2 下降46个百分点 |
指令遵循过于字面化 | 用户的 prompt 可能需要重新调整 |
写作风格变化 | 部分用户反馈创意写作能力下降 |
7.2 技术解读
7.2.1 能力权衡(Trade-off)
Anthropic 在 Opus 4.7 的开发中进行了有意的能力权衡:
强化:编程、Agent、视觉、精确指令执行
弱化:部分创意写作、长上下文边缘场景
7.2.2 可能的优化建议
# 针对 Opus 4.7 优化的 Prompt 策略opus_47_optimized_prompt = """# 任务[清晰描述任务目标和期望输出格式]# 约束条件[明确列出必须满足的条件]# 验证标准[定义如何验证结果是否正确]# 上下文(如果需要)[提供必要的背景信息]"""第八章 未来展望
8.1 与 Mythos Preview 的演进关系
┌─────────────────────────────────────────────────────────┐│ Anthropic 模型路线图 │├─────────────────────────────────────────────────────────┤│ ││ Opus 4.7 ──────┐ ││ (已发布) │ Glasswing 安全机制验证 ││ │ ││ Mythos Preview ├────► 积累经验 ──────► 广泛发布 ││ (企业限供) │ ││ │ ││ 差异化削弱 ────┘ 逐步释放 ──────────► 完整能力 ││ │└─────────────────────────────────────────────────────────┘8.2 对 AI 工程师的6个警示信号
AI 已能"自主交付数月资深工程量"—— 不是辅助,是接管
"次强模型"就能按住所有公开竞品—— 前沿能力已远超你感知
你的 Prompt 库可能一夜失效—— "指令跟随"从宽容变成较真
"AI 可信委派"时代正式开始—— 人机协作形态在质变
Anthropic 开始"差异化削弱"模型—— AI 安全可控性成为核心议题
知识截止日期前移到2026年1月—— 模型时效性管理更加重要
8.3 开发者应对策略
策略 | 具体措施 |
|---|---|
版本锁定 | 在生产环境明确指定模型版本 |
多模型冗余 | 关键业务部署多模型并行策略 |
Prompt 适配 | 根据新特性调整 prompt 策略 |
质量监控 | 建立输出质量监控体系 |
C. 技术术语表
术语 | 说明 |
|---|---|
SWE-bench | 软件工程基准测试,评估模型解决真实GitHub Issue的能力 |
Terminal-Bench | 终端编程环境基准,评估AI在命令行场景的自主解决能力 |
OSWorld | 计算机操作基准,评估AI操控操作系统界面的能力 |
XBOW | 渗透测试基准,评估AI在网络安全任务中的表现 |
CharXiv | 学术论文视觉理解基准 |
Project Glasswing | Anthropic的网络安全防护项目 |
差异化削弱 | 刻意降低模型特定能力以控制风险 |