【行业观察】Hermes Agent冲榜Open Claw,自进化是“聪明Token”经济学?
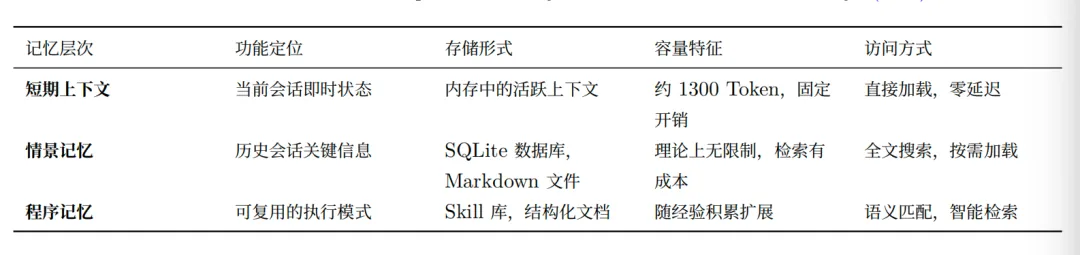
前段时间Hermes冲上榜单,在两个月内狂揽35k+ GitHub星标,这是由Nous Research于2026年2月发布的Agent,其与Open Claw的核心差异化正是Token效率。Open Claw是"网关"架构(hub-and-spoke),而Hermes采用"同心增长式架构"(concentric growth),强调持久记忆与自我进化,大白话说就是“长脑子了”。两者的关键差异在于架构逻辑,即Open Claw 是集中管控,适合团队协作,而Hermes Agent 是个人成长,适合长期陪伴。Hermes的缓存感知记忆架构冻结系统提示快照在会话初始化,因此重复模型调用使用缓存上下文窗口,防止学习循环膨胀token账单。早在今年3月的中关村论坛中,小米MiMo大模型负责人罗福莉就直接指出AI Agent时代的成本悖论:当大模型从"聊天"转向"干活",Token消耗量呈现10倍甚至100倍的爆发式增长,而现有的技术架构和商业模式难以支撑这种增长。这也与她后来4月6日在X上的呼吁完美契合,她将Anthropic封禁第三方Agent框架与MiMo推出的Token Plan并置分析,系统阐述了她对Agent算力分配与定价逻辑的深层思考,即Agent时代不属于烧掉最多算力的人,而属于用得最聪明的人。她认为未来一年AGI进程最关键的词,是"自进化"。而Hermes正是"用得更聪明"的典范,通过自我生成的Skills和高效的记忆管理,将token消耗集中在真正创造价值的地方。在Token效率为王上,它的出现与市场需求产生了微妙的共振。当前AI行业存在一个根本性的经济矛盾,训练成本持续飙升,推理成本断崖式下跌。根据斯坦福2025年AI指数,每百万token的推理成本在过去两年内下降了惊人的99%,从GPT-3时代的60美元降至2026年初的0.06美元。驱动这一降幅的是三股力量的相乘效应:硬件效率每年提升2~3倍,算法效率每年提升2~3倍,系统优化每年再提升2~4倍。三者相乘,Token成本每年下降5~10倍。然而,训练最先进的LLM已成为人类历史上最昂贵的资本密集型活动之一。Anthropic CEO Dario Amodei曾透露,2024年中期模型训练成本已达1亿美元,而训练中的模型成本接近10亿美元,预计2025年可能出现耗资百亿美元的训练项目。这对开源模型构成了致命威胁。你需要持续投入九位数人民币级别的训练成本(单次完整训练的折旧加电费),却无法通过模型本身直接收费回收。当你的权重文件免费挂在Hugging Face上,现金流回收路径只剩下一条,云上推理。但开源权重意味着客户可以自行采购GPU部署,根本不需要回到你的云平台。你越成功,你的商业模式就越失败。在此基础上,规模效应是失效。最典型的就是之前猝死的Sora,用户量越多,其毛利率越低,甚至赔本。但传统云计算的商业模式建立在规模效应之上,即随着客户数量增长,固定成本被摊薄,边际成本递减。Token经济学颠覆了这一逻辑。另一点是规模效应直接面临的冲突就是闭源和开源之争,比如DeepSeek曾披露其推理系统的理论成本利润率高达545%,但这建立在极致的算力优化和闭源模型的基础之上。对于开源模型提供者而言,规模效应带来的保障并不存在,客户可以"带走"你的技术成果,在任何有云算力的地方部署。事实上,Qwen系列模型在Hugging Face下载量突破6亿次,成为全球仅次于Llama的开源力量。但技术成功的另一面是商业困境:当模型能力差距缩小,用户通过多模型比较的需求自然下降;当开源权重让客户可以自建AI infra,云厂商的推理收入被直接侵蚀。在Agentic时代,是否面临定价权丧失的问题?《金融时报》的报道用一句话带过了核心事实:"MaaS(模型即服务)目前占比很小,且因竞争激烈而低毛利"。随后迅速跳转到agentic AI带来token消费爆发的乐观叙事。但这句轻描淡写的背后,是一个被掩盖的残酷现实,即国内大模型API的价格战已经将单token毛利打到接近成本线。DeepSeek、字节豆包、百度文心一言的轮番降价,让MaaS变成了"赔本赚吆喝"的生意。豆包大模型1.6在2025年6月的价格降至0.8元/百万tokens(输入),成本比上一代下降63%。而agentic应用即便消耗再多的token,乘以一个趋近于零的单位毛利,结果依然是零。更严峻的是,新一代推理模型(如DeepSeek R1)消耗的计算量是传统推理的150倍,模糊了训练与推理的边界。当模型在内部进行大量隐式推演(用户看到一个token,模型内部可能已生产上百个),单个可见token的成本被思考过程成倍放大。在 ChatGPT 时代,月度订阅(如 ChatGPT Plus 的 20 美元/月)是主流商业模式,其假设是用户的 Token消耗相对均匀,订阅收入能够覆盖服务成本。然而,Agent 时代的到来彻底颠覆了这一假设:同一用户在不同场景下的Token 消耗可能相差百倍,固定订阅价格无法反映这种差异,导致严重的交叉补贴和效率扭曲。MaaS(模型即服务)模式的必然性在于其按需付费的定价机制,能够更准确地反映Token消耗的实际成本和价值。用户为实际使用的Token付费,服务提供商根据Token类型(输入/输出、模型能力等级)差异化定价,实现成本与收益的精准匹配。这一模式对Agent经济尤为重要,即企业客户可以根据业务需求灵活调整 Token 使用量,避免为闲置能力付费;服务提供商则可以根据成本结构优化定价,实现可持续的盈利。MaaS模式的成功不仅取决于定价机制,更取决于Token效率的持续提升,如果单位Token的成本不能有效降低,按需付费可能导致客户的使用成本过高,抑制需求增长。罗福莉提出的核心解决方案,是“更省Token的 Agent框架”与“更强大和高效的模型” 的协同进化(co-evolution)。不是孤立地优化框架或模型,而是将两者作为相互反馈的系统,实现整体效率的持续提升。在框架层面,“更省Token” 意味着多个维度的优化:上下文压缩技术(只保留关键信息)、工具调用优化(减少低价值调用)、推理路径规划(避免无效探索)、长期记忆机制(避免重复计算)等。似乎新出的Hermes Agent 的自进化机制,正是这一方向的典型代表,它通过自动技能生成和持续优化,将任务执行的经验转化为效率提升。在模型层面,“更高效” 意味着针对 Agent 场景的能力优化,更强的工具调用准确性(减少试错)、更好的长链路规划能力(避免失速)、更高的指令遵循精度(减少误解)等。协同进化的关键在于反馈闭环,框架的实际运行数据反馈至模型训练,优化模型能力;模型能力的提升又拓展框架的设计空间,实现更高层次的效率优化。这一闭环的建立,需要打破传统的“模型训练-框架开发-应用部署”的线性流程,构建一体化的持续优化体系。自我改进学习闭环:失败→反思→自动生成技能→持续优化。Hermes Agent的核心差异化特征在于内置的自我改进学习闭环,这一机制使Agent能够从每一次任务执行中学习,自动生成和优化可复用的技能,实现持续的效率提升。根据技术文档,Hermes Agent的学习闭环遵循“观察-规划-执行-学习”(Observe-Plan-Act-Learn)的循环 (ai.cc) ,在完成任务后自动分析执行过程,提取成功经验,生成结构化的技能文档,并在后续任务中调用和优化这些技能。这一机制的技术实现依赖于多个关键组件。技能文档(Skill Documents)是核心数据结构,每个技能以Markdown格式存储,包含任务描述、执行步骤、代码示例和优化记录。与传统Agent框架的静态提示工程不同,Hermes的技能文档是动态生成和持续更新的,反映了Agent的实际执行经验。反思模块(Reflection Module)负责分析任务执行的成败,识别关键决策点和优化机会。这一模块基于DSPy(Declarative Self-improving Python)框架实现,能够自动构建优化提示,引导模型生成更高质量的技能。技能库(Skill Library)是持久化的技能存储,支持跨会话、跨任务的技能复用。Agent 在执行新任务时,首先检索相关技能,加载至上下文,避免从零开始的重复探索。自我改进学习闭环的Token效率优势在于经验驱动的计算复用。传统Agent框架在每次执行任务时都进行完整的推理和探索,而Hermes通过技能复用,将大量计算转化为一次性的技能生成成本,后续调用仅需加载和执行预优化的技能,显著降低Token消耗。根据社区测试,经过充分训练的Hermes Agent在执行熟悉任务时,Token消耗可比初始运行降低50% 以上,这一效率提升随着技能库的丰富而持续累积。Hermes Agent 的另一个核心特性是持久化身份与记忆系统,这一系统支持跨会话的知识积累和技能复用,是实现长期效率提升的基础。根据技术文档,Hermes 的记忆架构分为三个层次:短期上下文(Short-term Context)、情景记忆(Episodic Memory)和程序记忆(Procedural Memory)(ai.cc) 。短期上下文维护当前会话的即时状态,包括用户输入、Agent响应和中间结果。这一层次的容量有限(约1300Token),但访问速度极快,支持实时交互。情景记忆存储历史会话的关键信息,以结构化格式(如 MEMORY.md 和 USER.md文件)持久化保存。Agent 可以通过session_search工具检索过往会话,获取相关经验的摘要 (Blake Crosley) 。这一层次的容量理论上无限制,但检索和摘要需要额外的Token成本。程序记忆即技能库,存储经过抽象和优化的执行模式,是Agent“知道如何做”的核心知识。持久化记忆的Token效率优势在于上下文压缩和知识外化。传统Agent框架将所有历史信息保留在上下文中,导致线性膨胀;Hermes通过将经验外化至持久化存储,只在需要时检索相关信息,大幅压缩活跃上下文的规模。更深层地看,程序记忆(技能)的形成是对情景记忆的进一步抽象,将具体的执行序列转化为可参数化的模式,实现更高层次的知识复用。这种“记忆分层”的设计,与人类认知系统的结构高度相似,可能是实现高效Agent架构的普适原则。Hermes Agent的“自进化”机制,为Token经济学提供了关键的技术基础:技能自动化生成对人工调优成本的替代。在传统Agent开发模式中,任务规划和工具调优依赖人工专家的知识投入,开发者需要理解业务场景、设计执行策略、编写提示模板、调优模型参数。这一模式的人力成本高昂,且难以规模化,每个新任务领域都需要相应的专家投入,成为 Agent应用扩展的瓶颈。Hermes的自我进化机制从根本上改变了这一成本结构。技能生成从人工任务转化为自动化过程。Agent通过执行-反思-抽象的循环,自动提取可复用的执行模式。这一自动化的直接效果是边际人力成本趋近于零:新增任务领域的技能生成无需额外专家投入,Agent 自身的学习能力足以应对。更深层的效应是知识积累的复利效应,技能库的持续丰富提升Agent处理新任务的能力,形成正向循环。从Token经济学的视角,这一成本结构的转变具有革命性意义。传统模式的Token成本包括计算成本(推理和工具调用的算力消耗)和人力成本(开发和调优的专家投入),两者都随任务量增长;Hermes模式的Token成本主要限于计算成本,且计算成本本身随技能积累而下降。这意味着,在Agent规模化部署的场景中,Hermes模式可以实现单位Token总成本的持续下降,而传统模式的成本结构相对刚性。Hermes的自我进化机制,还实现了从试错学习到预测性执行的范式转移,这是Token效率提升的另一关键维度。传统Agent框架采用试错学习模式。面对新任务,Agent通过探索-反馈-调整的循环逐步逼近正确解。这一模式的优点在于通用性,无需预训练即可处理任意任务;代价在于效率,探索过程中的大量尝试产生冗余的Token消耗。Hermes Agent与OpenClaw的核心差异,首先体现在记忆架构的设计哲学上。OpenClaw采用静态提示工程模式,即开发者预定义工具描述、任务规划和执行策略,以提示模板的形式嵌入Agent上下文。这一模式的优点在于可控性和可解释性,开发者精确知道Agent将如何响应各类输入,便于调试和优化。然而,其缺点同样显著,比如提示模板的容量有限,无法涵盖所有可能场景;静态定义无法适应动态变化的任务需求;每次执行都从头开始推理,缺乏经验积累。Hermes的动态技能库进化模式,意味着技能不是预定义的提示模板,而是从实际执行中自动生成的可复用程序;技能库不是静态的配置文件,而是持续更新的知识资产。这一模式的技术优势在于:容量无限制,技能库可以随经验积累无限扩展;适应性,新场景自动触发新技能生成,无需人工干预;效率,技能复用避免重复推理,显著降低 Token 消耗。从Token经济学的视角看,两种记忆架构的差异具有深远的商业含义。OpenClaw 模式的 Token成本与任务复杂度线性相关,更复杂的任务需要更长的提示和更多的推理步骤;Hermes模式的Token成本与技能库丰富度负相关,随着经验积累,熟悉任务的执行效率持续提升。这意味着,在Agent规模化部署的场景中,Hermes模式具有显著的长期成本优势,可能从根本上改变Token经济的成本结构。上下文压缩是Hermes最核心的效率机制。通过将经验外化至技能库,Hermes将活跃上下文的规模控制在必要最小,通常仅加载与当前任务直接相关的技能文档,而非完整的历史记录和工具描述。根据技术文档,Hermes的固定记忆开销约1300Token (Blake Crosley) ,而OpenClaw的完整提示模板可能超过10000Token,这一数量级差异在长会话中累积为显著的成本优势。计算结果复用是另一关键机制。Hermes的技能文档不仅包含执行步骤,还封装了经过验证的中间结果和优化参数。在执行相似任务时,Agent可以直接调用这些预计算结果,避免重复的推理和验证。这一机制在批量处理、周期性任务等场景中尤为有效,首次执行生成技能,后续执行近乎“零成本” 复用。OpenClaw强调即时可用,开发者通过简单的配置即可启动Agent,快速验证想法。这一模式的优点在于低门槛和快速迭代,但代价是深度定制的能力受限,复杂的任务规划、个性化的工具集成、长期的性能优化都需要深入框架内部。而Hermes则采用渐进式能力构建模式,初始配置同样简单(一键安装脚本支持 Linux/macOS/WSL (ai.cc) ),但框架的设计鼓励持续的技能积累和优化。开发者可以从简单任务开始,让Agent自动学习和生成技能;随着技能库的丰富,逐步挑战更复杂的任务。这一模式的优点在于长期回报,投入的时间转化为可复用的技能资产,Agent能力随使用持续提升;代价是初期学习曲线较陡,需要理解技能生成和管理的机制。从Token经济学的视角,两种开发者体验模式对应不同的成本结构。OpenClaw的“即时可用”意味着每次任务都支付完整的推理成本,长期总成本与任务量线性相关;Hermes的“渐进式构建”意味着初期投入较高的学习和优化成本,但边际成本随技能积累持续下降,长期总成本可能显著低于线性增长。对于高频、长期的Agent应用场景,Hermes的模式更具经济可行性。Hermes的GitHub Star数在短时间内持续攀升,已超过35k;OpenRouter上的Token使用量从3月下旬开始明显加速,单日使用量连续刷新新高,全球日排名一度进入前列 。在Productivity、Personal Agents、Coding Agents等多个榜单中同时靠前,这对于一个上线不到两个月的Agent框架而言并不常见。罗福莉的文章在开发者圈子引发共鸣,正是因为它把许多用户长期使用中感受到的问题,以及行业不断攀升的token成本压力,摆在了面上。有意思的是Hermes的自我进化机制,为这些问题提供了技术解决方案,吸引了大量寻求长期效率优化的开发者。如果说OpenClaw 代表了“生态优先”的第一代Agent框架,通过丰富的工具集成和活跃的社区建设快速获取用户;Hermes则代表了“效率优先”的第二代框架,通过技术创新解决第一代的核心痛点,以长期价值吸引高质量用户。几乎与效率优先的行业趋势高度一致,预示着AI Agent竞争焦点的根本性变化。最后一句总结,说人话就是,在干活大军里,未来则是谁节省Token谁是赢家。