


1 引言
1.1 背景
超以太网联盟(UEC)是一项行业合作计划,汇聚了超大规模数据中心运营商、系统供应商、芯片提供商等众多贡献者,其使命在于增强以太网以适应人工智能与高性能计算(HPC)的应用需求。
各贡献方旨在涵盖规范的所有关键方面,包括软件 API、网络协议、硬件兼容性与可扩展性、网络运维、合规性及可扩展性。为践行 UEC 的使命,本文档规定了用于以太网络的新协议,以及对现有以太网协议的可选增强方案,从而提升人工智能与 HPC 应用的性能、功能和互操作性。
超以太网(UE)规范涵盖与 AI 和 HPC 工作负载相关的广泛软件与硬件内容:从 UE 合规设备所支持的 API,到传输层、链路层和物理层提供的服务,以及管理、互操作性、基准测试和合规要求。
UE 不要求也不强制对网络层或以太网物理层及链路层进行任何修改。例如,UE 合规实现可使用本规范发布时市场上常见的以太网交换机。然而,UE 提供了可选的网络层、以太网物理层和链路层特性,以实现对高要求应用的更优性能。随着时间推移和经验积累,部分可选特性有可能逐渐成为常态乃至强制要求。UE 合规实现须满足本规范中的所有强制性要求。
1.1.1 UEC 组织架构
UE 架构涵盖经典 ISO/OSI 网络模型的四个较低层次,以及向上层提供服务并暴露相关 API 的软件服务。四个层次中的每一层均由一个 UEC 工作组负责(如图 1-1 中的行所示),各工作组从可扩展性、能力、性能和互操作性角度定义所需架构,并制定严格要求与描述规范。UEC 管理工作组负责以太网 Fabric 及端点管理,UE 管理架构包含管理协议、传输机制和数据模型。UEC 合规工作组与技术咨询委员会(TAC)合作,定义合规性与互操作性要求。UEC 管理工作组以及调试与性能工作组与上述所有工作组均有交互。
此外,UEC 正在现有网络服务的基础上为相关应用与工作负载增加存储服务。图 1-1 中以列形式呈现的工作组是在初始行工作组之后成立的,其对 UE 规范及其他独立文档的贡献计划在未来版本中发布。
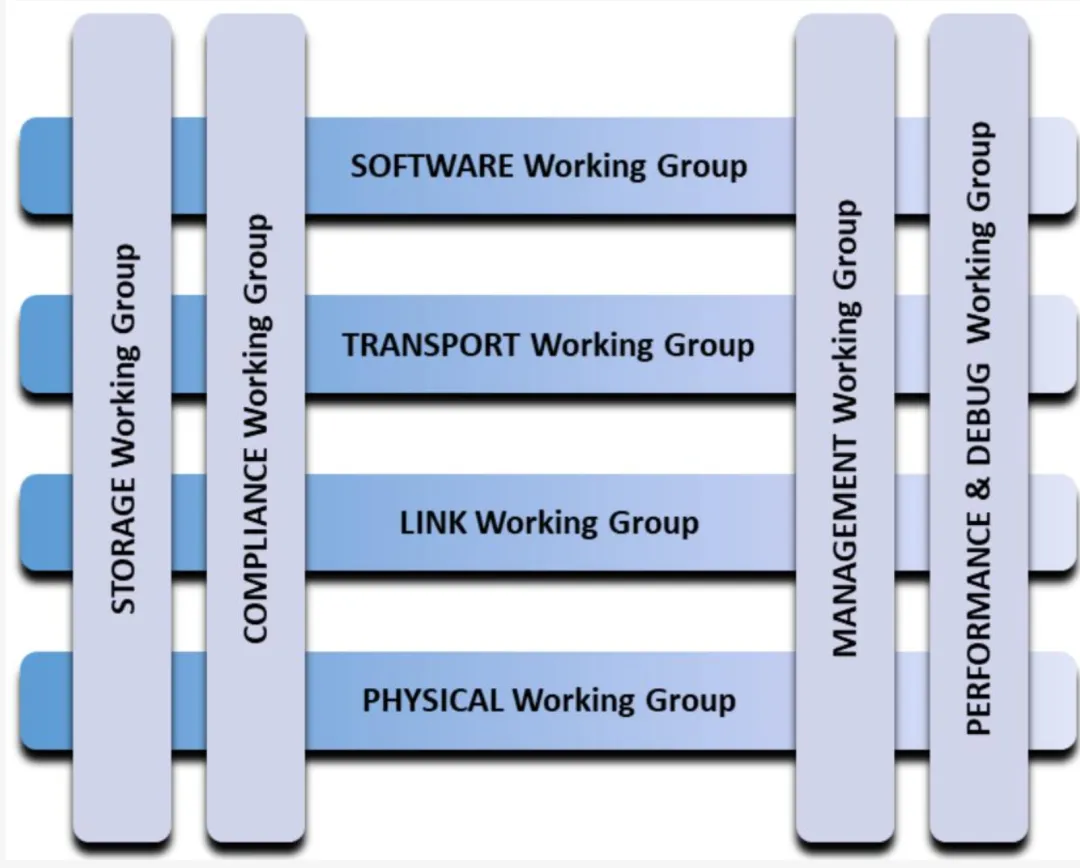
图 1-1 - 工作组组织架构
UE 以 Linux 基金会联合开发基金会(JDF)旗下国际标准开发组织(SDO)的形式注册成立。UE 规范公开发布,可供公众免费下载。未来版本一经制定并批准,同样将公开发布。UEC 成员有意将其工作成果提交至相关标准组织和/或开源社区,以推动广泛采纳,并积极参与以太网、互联网协议(IP)、软件及 API 开发领域的主流行业标准化工作。潜在相关 SDO 包括但不限于 IEEE、IETF、OCP、OFA、SONiC/SAI 以及各存储和管理领域 SDO。
1.1.2 UE 传输配置文件
UET 规定了三种配置文件:AI Base、AI Full 和 HPC。AI Base 配置文件旨在以最低成本满足当前及未来 AI 应用对高性能的需求。AI Full 配置文件在此基础上增加了额外特性(如可延迟发送、精确匹配以及对原子原语的支持)。HPC 配置文件面向高性能计算应用,具备 AI Full 配置文件的全部特性,但不包含可延迟发送功能。
每种配置文件列出了所提供的服务以及合规产品在传输层所需的特定功能。配置文件本身在第 3.3 节定义。端点处硬件接口的详细内容超出 UE 规范的范围。向上层提供的软件 API 经过规范化,以实现与上层软件的互操作性。其目标是使不同供应商支持同一配置文件的设备,按本规范所述展现互操作性和功能一致性。
配置文件可包含可选实现的特性。若实现了可选特性,则必须遵循已定义的规范方可声明合规。
1.2 UE 规范约定
UE 规范在规范性语言、信息性说明、术语、单位、数值和图示格式方面采用以下约定。
1.2.1 规范性、信息性与实现性陈述
规范性语言采用 IETF BCP14 定义的术语进行标识。本文档中的关键词"MUST"(必须)、"MUST NOT"(禁止)、"REQUIRED"(要求)、"SHALL"(应当)、"SHALL NOT"(不应当)、"SHOULD"(建议)、"SHOULD NOT"(不建议)、"RECOMMENDED"(推荐)、"NOT RECOMMENDED"(不推荐)、"MAY"(可以)和"OPTIONAL"(可选),当且仅当以全大写形式出现时,按照 IETF BCP 14 [4]、IETF RFC 2119 [1] 和 IETF RFC 8174 [2] 的规定加以解释。
所有未明确标注为信息性注释的文本均为规范性内容。节标题中的 [informative](信息性)标注适用于该节的全部内容,包括所有子节。图示和表格除非在标题中标注为信息性,否则均视为规范性内容。
信息性文本采用以下格式标注:
信息性文本:
信息性文本包含于此区域。
规范中偶尔会包含面向实现者的注释,旨在阐明规范意图并为实现者提供指导。此类注释采用以下格式标注:
实现注意事项:
实现注意事项文本包含于此区域。
1.2.2 术语
1.2.2.1 缩略语
1.2.2.2 术语定义
1.2.3 格式约定
图示用于定义协议头和协议序列交换。这些图示的约定如下所示。凡图示与文字描述存在无意冲突之处,均以文字描述为准。
1.2.3.1 头格式图
图 1-2 是规范其他章节所示完整头栈的示例。这些完整头栈并未显示每层各头的所有细节,而是标识出解析头及找到栈中下一层所需的重要字段。头栈的各层显示于左侧,并以颜色加以区分。
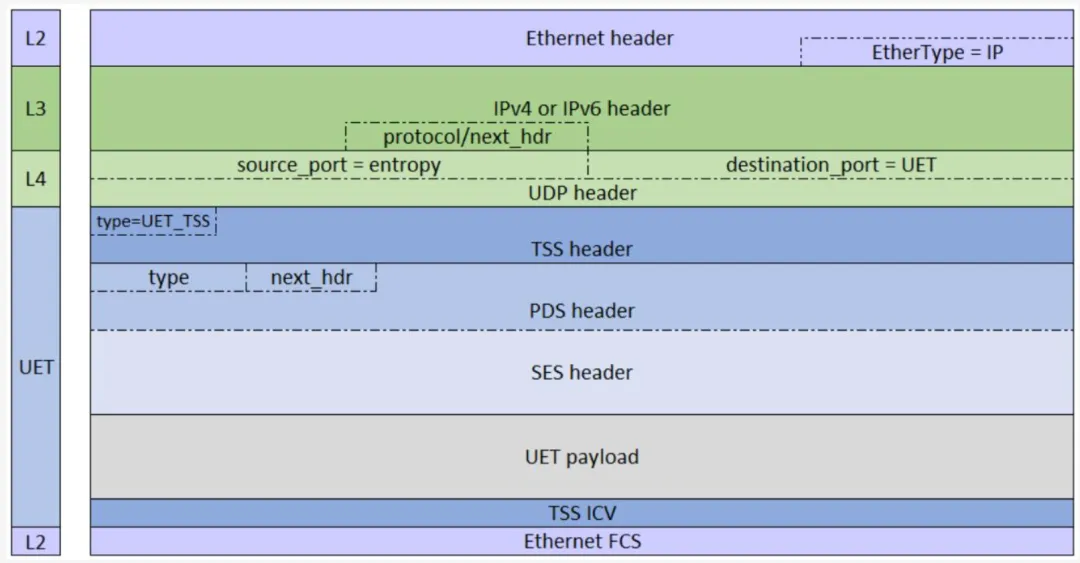
图 1-2 - 完整头格式示例
图 1-3 是规范其他部分所用单个详细头图示的示例。字节标注于顶部和左侧。字节的最低有效位(LSB)为左侧第一位,最高有效位(MSB)位于右侧。头字段标注于顶部字节标签下方和左侧字节偏移标签的右侧。头字段宽度基于实际位数。保留字段在接收时应忽略,发送时置零。每个单独头均为独立图示,显示从字节偏移零开始的头。接收包中头的实际偏移量取决于前序头的具体格式,单独图示中未显示前序头。
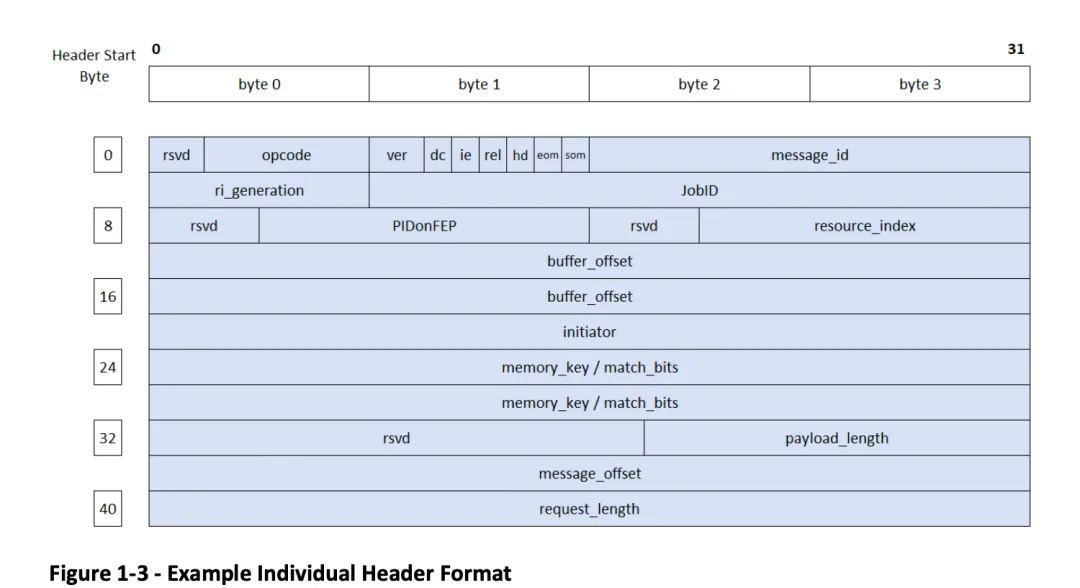
图 1-3 - 单个头格式示例
头字段的描述在详细头图示之后以表格形式给出。
1.2.3.2 序列图
图 1-4 展示了本规范所用序列图的示例。序列图用于说明两个实体之间以及实体内各功能层之间特定信息交换的时序。序列图被分解为包并传递至 PDS 层。一些重要的 UET 头字段显示于表示线上传输包的箭头上方。信息交换过程中发生的动作和事件以虚线箭头和说明文字加以突出显示。
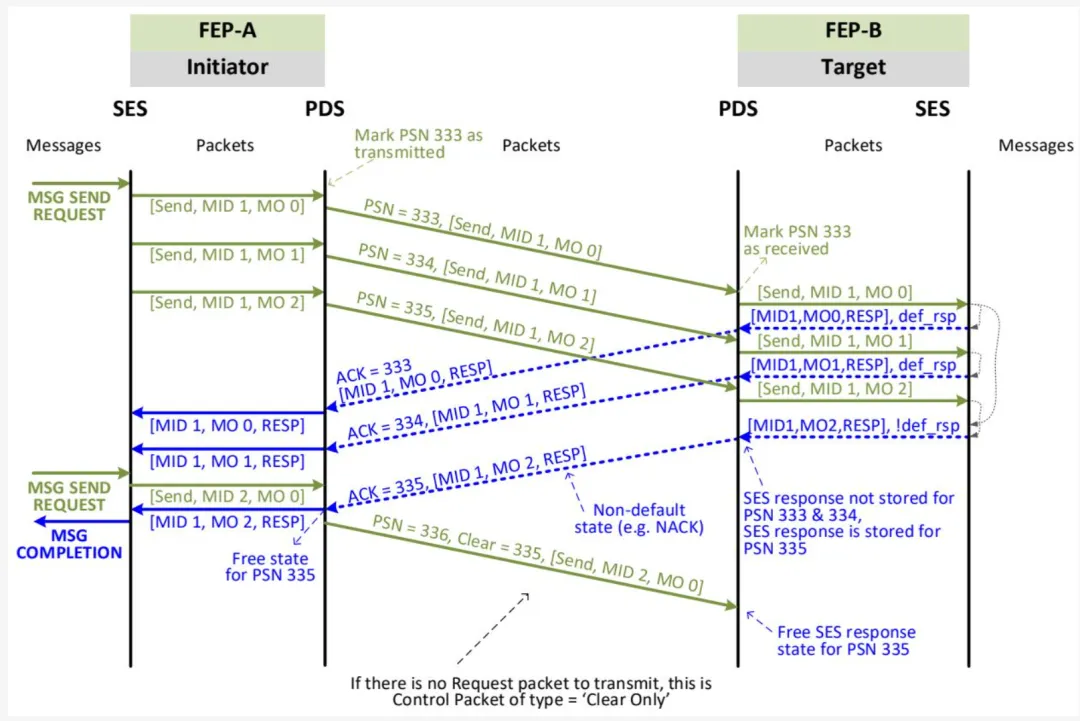
图 1-4 - 序列图示例
1.2.4 参考文献
UE 规范同时包含规范性参考文献和信息性参考文献。规范性参考文献是确保 UE 组件间互操作性的必要依据。信息性参考文献旨在提供补充背景知识,帮助进一步理解 UE 运行环境。UE 规范的每一章节均可提供规范性和信息性参考文献列表。
以下规范性参考文献用于本引言部分:
[1] IETF RFC 2119,"Key words for use in RFCs to Indicate Requirement Levels,"1997。[在线]。可访问:https://www.rfc-editor.org/rfc/rfc2119。 [2] IETF RFC 8174,"Ambiguity of Uppercase vs Lowercase in RFC 2119 Key Words,"2017。[在线]。可访问:https://www.rfc-editor.org/rfc/rfc8174。
[3] IETF RFC 2474,"Definition of the Differentiated Services Field (DS Field) in the IPv4 and IPv6 Headers,"1998。[在线]。可访问:https://datatracker.ietf.org/doc/html/rfc2474。 [在线]。可访问:https://datatracker.ietf.org/doc/bcp14/。
1.3 系统视图与命名约定
AI 和 HPC 领域正以极快的速度演进,AI 模型的变化速度更甚。这催生了对能够针对各类 AI 和 HPC 工作负载进行水平和垂直扩展的精细化系统的需求。水平扩展指增加更多端点和/或 Fabric 交换机;垂直扩展指通过增加更多处理能力、内存和/或存储来扩展端点。
算法和模型的演进速度超过了硬件(主要体现在内存、存储和网络方面)的发展速度。最优系统在计算、网络(即 Fabric)和相关数据(即模型参数和训练数据)三者之间取得平衡。UE 规范明确面向网络技术,并隐含涵盖其他要素。
UE 规范面向分布式工作负载,无论是 AI 还是 HPC,并自然地继承了并行计算的部分命名约定。图 1-5 提供了并行计算组件的系统概览,本标准后续规范性章节将详述各组件的协议与运行方式。
UE 规定在集群内运行,集群包括通过 Fabric 互连的节点。端口实现 IEEE Std 802.3 定义的单一介质访问控制(MAC),并可选地包含 UET 配置文件所要求的任何 UE 特定扩展。链路连接两个端口。Fabric 接口(FI)是提供一个或多个端口并向一个或多个操作系统实例(OSI)暴露一个或多个 Fabric 端点(FEP)的物理实体。Fabric 地址(FA)为 IPv4 或 IPv6 地址,FEP 是分配了单一 FA 的逻辑可寻址实体。UE 传输协议(可选地包含安全上下文)终止于 FEP。具体而言,FEP 只能被单一 OSI 使用,一个节点可拥有一个或多个 FEP。每个 OSI 可使用一个或多个 FI 及一个或多个 FEP 连接至 Fabric。
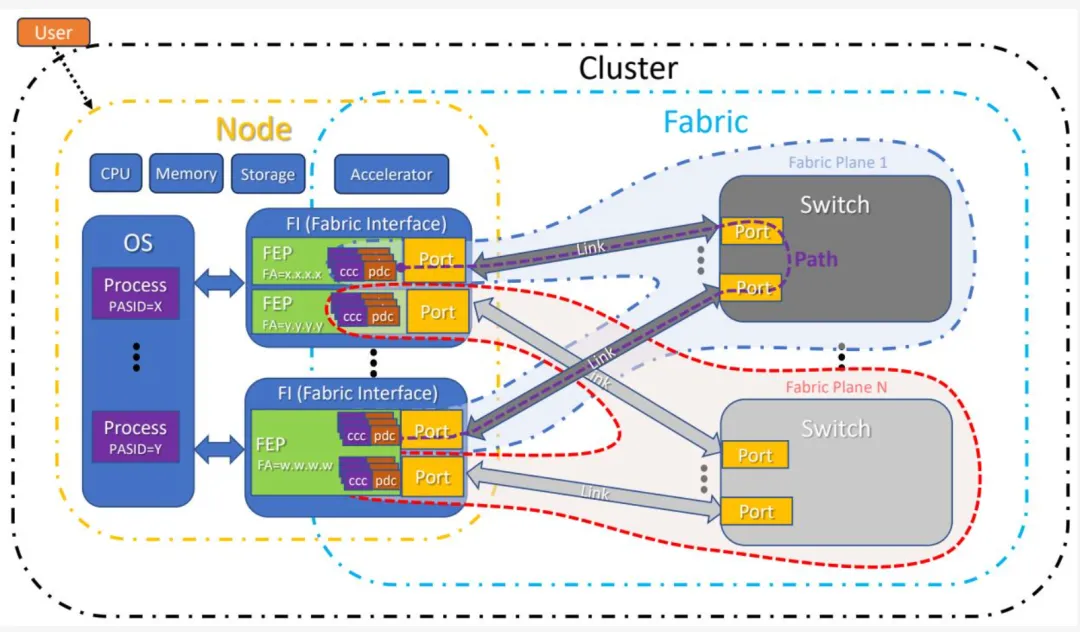
图 1-5 - 系统概览
节点是具有一个或多个 FEP 的计算设备。集群是通过 Fabric 连接的此类节点集合(注意图 1-5 中的简化示意图仅供说明,仅显示集群中的单个节点。典型 UE 部署可包含数十万个节点)。加速器是为高效执行特定功能而设计的计算模块或设备。CPU 是用于执行任意计算的通用处理器。CPU 和加速器连接有内存,FEP 通过虚拟寻址访问该内存。节点可拥有本地存储,并包含一个或多个 CPU 和/或一个或多个加速器。
用户是对集群节点具有访问权限的实体,可执行进程。进程是在 OSI 上由特定用户执行的程序实例,在内存中具有私有虚拟地址空间(VAS)。进程由在其所运行 OSI 内唯一的进程 ID(PID)标识。进程地址空间 ID(PASID)是每个 OSI 内虚拟地址空间的唯一标识符。
集群可以两种根本不同且可能共存的方式运行:
以并行作业模型运行(如 MPI/*CCL 或 SHMEM)。 以客户端/服务器模型运行,客户端连接到服务器(如存储或函数即服务(FaaS))。
每个包携带一个标识符,指明其所参与的模型。并行作业执行以"运行至完成"模型为特征,而客户端/服务器执行通常无限期运行服务器,为无限数量的客户端提供服务(通常具有复杂的可靠性和可用性保证)。
两个 FEP 需具备 IP 层连通性方可通信。UE 网络支持多端口 FEP,但要求任何 FEP 只关联一个 FA(即 IP 地址)。与 FEP 关联的 FA 用作从该 FEP 发送的所有包的源地址,或发往该 FEP 的所有包的目标地址。
FEP 可拥有多个端口(如图 1-6 中的场景 A)。UE 不规定这些端口的使用方式。多端口配置有多种可能,包括:成员终止于同一交换机的链路聚合(LAG)(如图 1-6 中的场景 D)、成员终止于不同交换机的多交换机 LAG(如图 1-6 中的场景 E),或通过多端口或主备配置实现到 FEP 单一地址的 IP 层多路径连接。Fabric 接口上支持多端口的其他场景是可能的,且取决于具体实现(如图 1-6 中的场景 B、C 和 F)。图 1-6 中的场景 F 展示了 Fabric 接口卡上的嵌入式交换机。
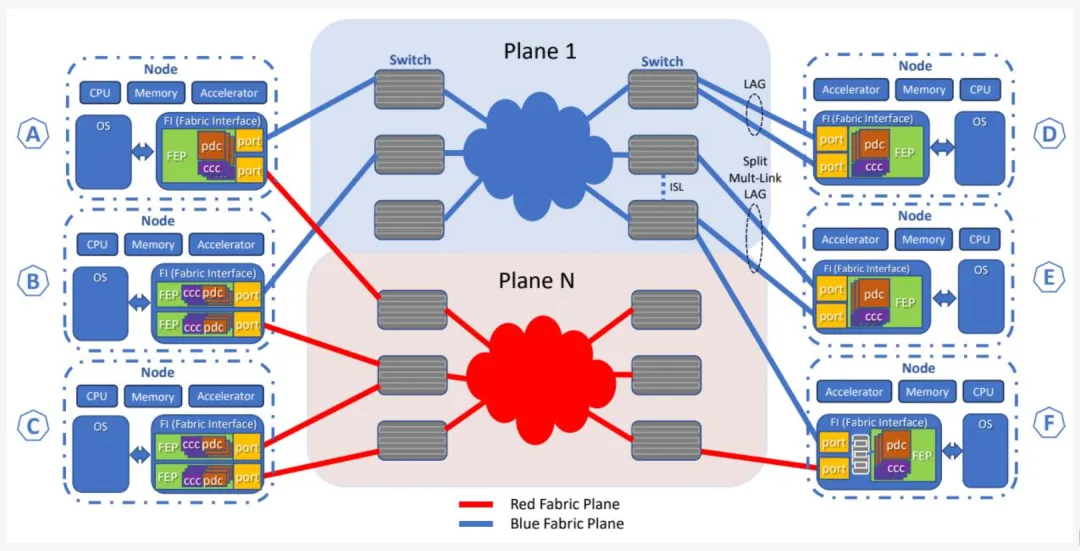
图 1-6 - 多平面网络与多端口 FEP
在多端口 FEP 架构中,UET 拥塞管理子层为每个包选择熵值。UET 不规定多端口主机的任何特定端口选择方法,该方法可因实现而异。
信息性文本:
在多端口配置中,网络应提供一种机制,允许 FEP 检测目标 IP 地址(如对端 FEP 的 FA)在任意给定平面上是否不可达,并在不可达时避免在该平面上使用该目标。可能的实现方法包括使用 IP 路由协议或 ICMP 不可达消息向 FEP 通告不可达性。然而,UET 不规定任何特定技术。未来可能在 UET 中定义用于确定可达性的机制。
两种计算模型在寻址方面有所区分:并行作业模型和客户端/服务器模型。单个 FEP 可设计为支持两种或仅一种计算模型的流量类型。两种模式可在单个 FEP 上同时运行。图 1-7 和图 1-8 是集群内两种不同计算模型的概览。
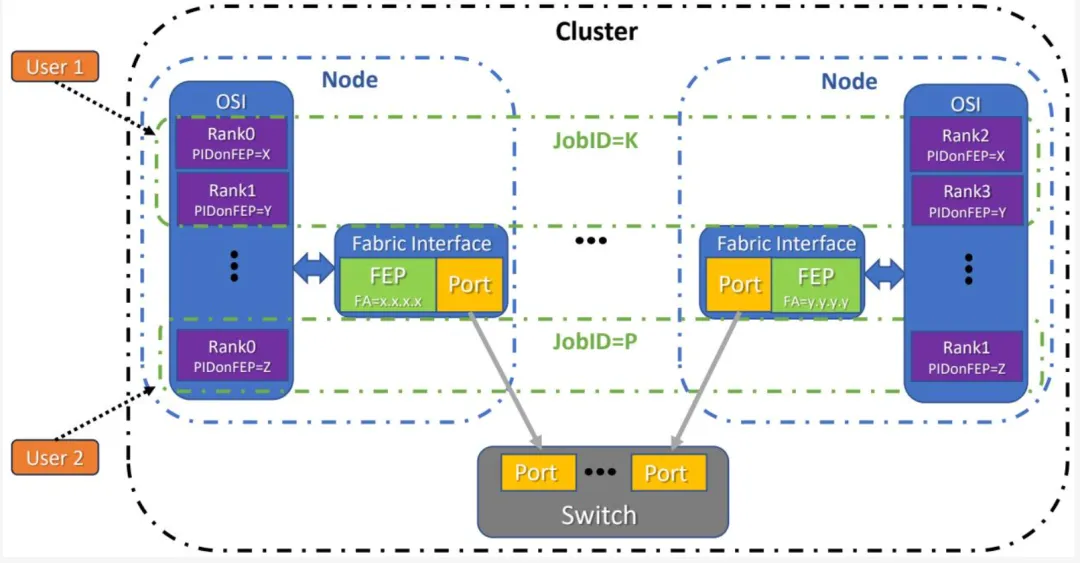
图 1-7 - 并行作业模型
并行作业是在集群上运行和通信、属于同一用户的进程集合。作业通常集体启动,并由集群内的 JobID 唯一标识。JobID 用于寻址和授权目的。作业由一个或多个 rank 组成,rank 是协作计算特定工作负载的进程。一个作业可在每个 OSI 上派生多个 rank,一个 OSI 可承载多个作业的 rank。若作业全局包含 R 个进程/rank,则以 RankID 从 0 到 R-1 编号。在并行作业模型中,本地 PIDonFEP 寻址范围从 0 到 P-1,其中 P 个进程与一个 FEP 关联于给定作业。若每个 FEP 关联相同数量的进程,每个端点可轻松计算特定 RankID 的 PIDonFEP。以一个例子说明:假设一个作业在 N 个节点上运行 R 个 rank,每个节点有 F 个 FEP。RankID 范围为 0 到 R-1,每节点 rank 数为 R/N,每 FEP 的 rank 数为 R/N/F。此时,P 为 R/N/F,PIDonFEP 范围为 0 到 P-1,即 0 到 R/N/F-1。
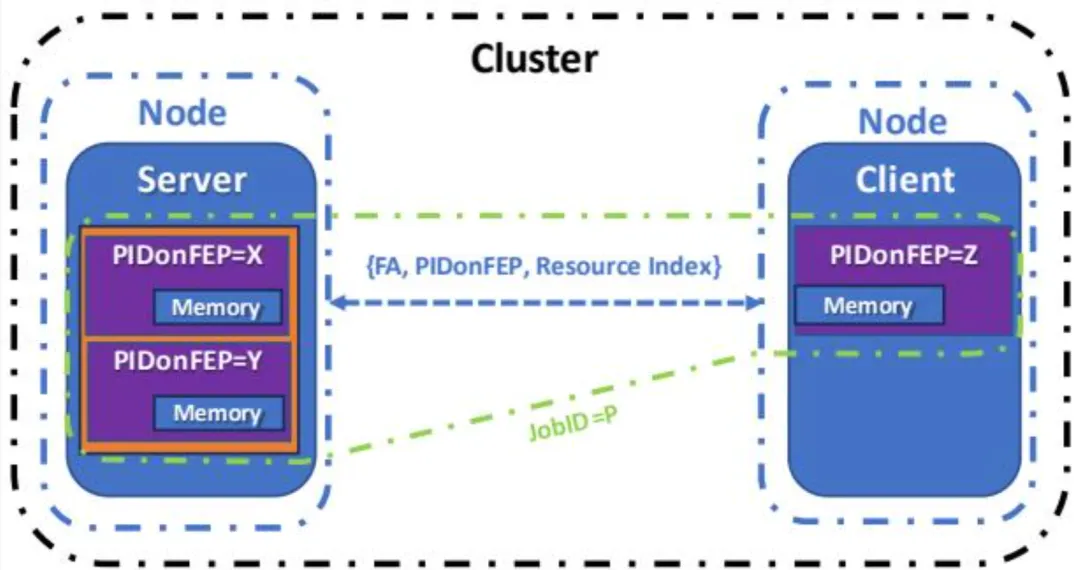
客户端/服务器关系是分布式架构的关键组成部分。服务器是节点上为一个或多个客户端提供服务的软件实体。客户端和服务器通过 FEP 通信。服务器 PIDonFEP 标识特定 FEP 上可用的服务,资源索引标识该服务内的资源。同一 FEP 可被多个服务器(在单一 OSI 上)使用,单一服务器可通过 FEP 上的多个 PIDonFEP 提供服务。客户端/服务器 JobID 在概念上等同于"N 对 1"连接,用于客户端对服务器的授权,
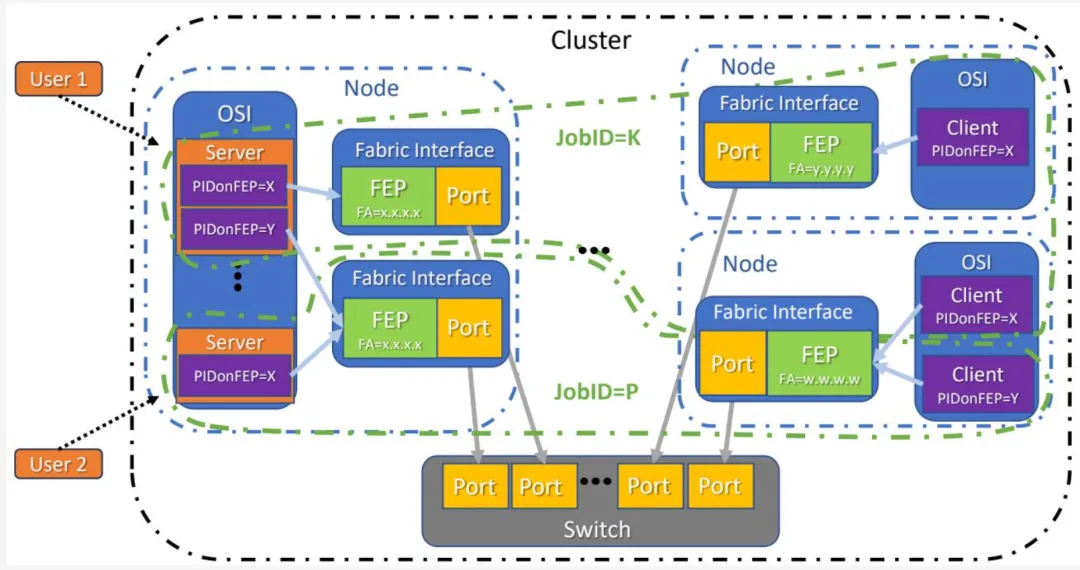
图 1-8 - 客户端/服务器作业模型
但它可能是短暂的,仅在流量活跃期间存在。服务器 PIDonFEP 与资源索引的组合在概念上等同于 TCP/UDP 端口。
UET 服务器可为特定服务使用众所周知的服务器 PIDonFEP 值和一组资源索引,UET 客户端可使用预配置的静态服务器 FA 或各种发现机制(如 DNS 或 hosts 文件)将服务器主机名或别名解析为 FA,从而与服务器建立通信。此外,UET 客户端和服务器可选择使用非 UET 发现方法,如先建立 TCP/IP 连接,再交换 UET 能力、地址和标识符。
UE 同时支持相对和绝对端点寻址模式(见图 1-9)。相对寻址模式在并行作业模型中提供连续寻址,确保对最大进程数量的可扩展性。绝对寻址用于客户端/服务器模型。
在相对寻址模式中,UET 定义目标地址的四个互补部分:
标识 FEP 的 FA。 在集群中唯一标识作业的 JobID。 范围从 0 到 P-1 的 PIDonFEP。 标识目标进程内服务、库或其他实体(如 MPI 与 *CCL)的资源索引(RI)。
当包到达目标 FEP 时,目标 PASID 可根据 JobID 与 PIDonFEP 的组合确定。
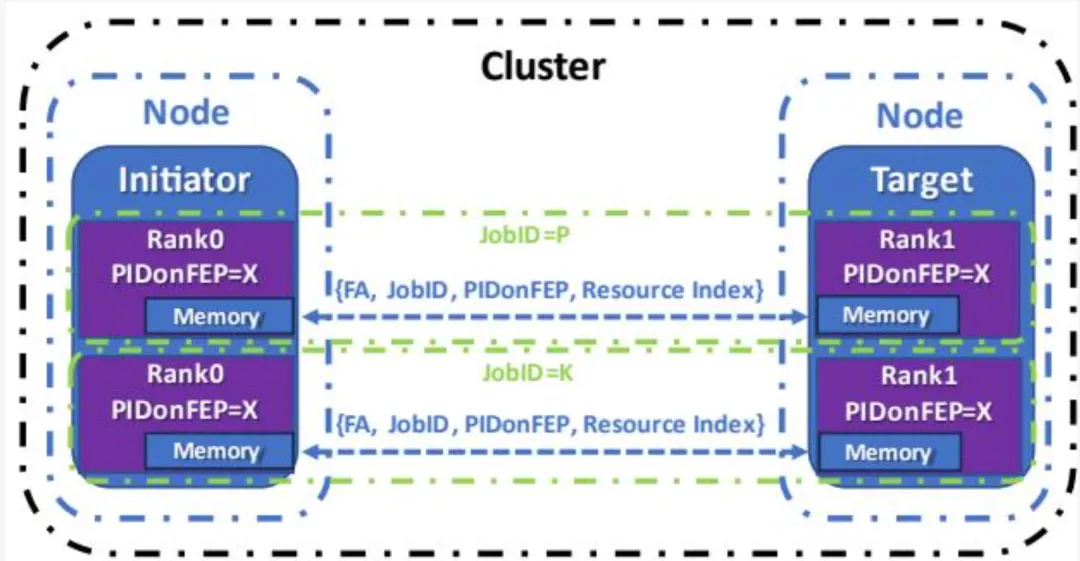
相对寻址
绝对寻址 图 1-9 - 寻址模式
信息性文本:
假设某个作业, 数量级在数万级,P 在数百级。
在绝对寻址模式中,UE 定义地址的三个互补部分:
标识 FEP 的 FA。 标识与目标 FEP 关联的某个 OSI PID 的 PIDonFEP。 标识目标进程内服务或其他实体的资源索引(RI)。
RI 用于寻址服务器中的特定子程序或函数(如运行 FaaS 或 RPC 服务)。当包到达目标 FEP 时,目标 PASID 根据 PIDonFEP 确定。JobID 不参与寻址,但用于授权。
消息代表 UE 网络中的单个通信事务。图 1-10 展示了消息通信交付背后的主要概念。事务由进程调用 UET libfabric 提供者创建,后者继而调用语义层。语义子层创建各类消息以完成事务。消息及其关联缓冲区在源 FEP 按内存地址的空间顺序被分割为有序包集合。包被发送并可能以乱序方式沿路径在网络中路由。消息最初可能涉及如 UET 语义规范所述的汇聚协议步骤。
此类消息的源端称为发起方,目标端称为目标。每个包有一个源 FEP 和一个目标 FEP。路径是两个 FEP 之间链路(节点和/或交换机之间的跳数)的有序集合。源 FEP 和目标 FEP 之间的路径是两个 FEP 通信所经过的有序链路集合。在不考虑 Fabric 中包丢失的情况下,沿同一路径发送的相同流量类别(TC)的包始终以发送顺序在目标 FEP 接收。当包在两个 FEP 之间沿多条路径路由时,不同路径之间不保证到达顺序。UET 期望交换机在无路由变化的情况下,将来自同一 PDC、具有相同熵值和流量类别的两个包沿同一路径传递。UE 传输协议(UET)定义了 FEP 间通信的协议、包格式和 FEP 策略。FEP 可设计为支持并行、客户端/服务器或两种流量类型。
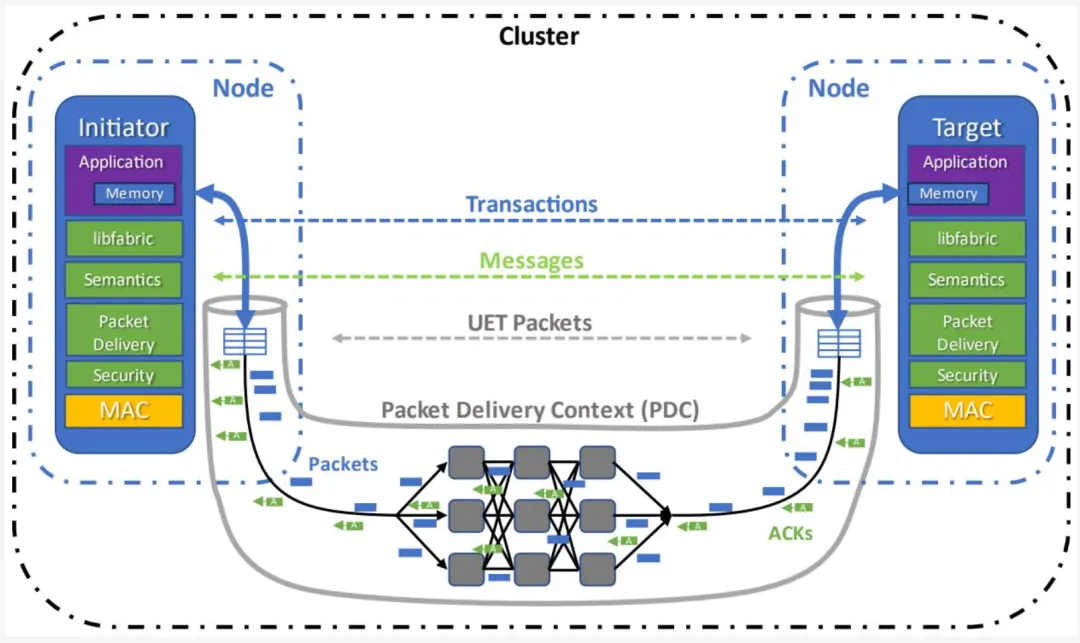
图 1-10 - 传输数据交付与包传递上下文
包传递上下文(PDC)是由传输层在两个 FEP 之间定义的单向逻辑且通常是瞬态的实体,存在于发起方 FEP 和目标 FEP,用于控制包的成功传输。包传递子层(PDS)创建并使用 PDC,以提供所要求的顺序性和可靠性交付模式。可靠性通过确认包(即 ACK 和 NACK)实现,目标向源发送 ACK/NACK 以指示端到端接收成功。拥塞管理子层(CMS)控制源在任意给定时刻可向目标发送的字节数。包窗口是一个 CCC 上可未确认的最大未确认字节数。同一作业的多个进程可共享单个 PDC,单个进程可使用多个 PDC 与另一进程通信。两个 FEP 之间可存在一个或多个 PDC,每个包标识其所关联的 PDC。
1.3.1 工作负载 [信息性]
本小节中的信息为背景材料,代表了 UE 规范 v1.0 发布时工作负载的技术现状。UE 主要面向以下四类工作负载:
AI 训练(AIT) AI 推理(AII) 高性能计算(HPC) 客户端/服务器(如存储流量)
1.3.1.1 AI 训练工作负载
AI 训练工作负载最初以"3D 并行"为特征,若有需要,通信模式可表示为三维环面。第一个维度是数据并行(DP),其中单个小批次中的样本通过多个模型副本处理,梯度或权重通过 allreduce 操作同步。
第二个维度是流水线并行(PP),其中每个流水线阶段是模型的一组层,前向方向的激活值和后向方向的误差在不同加速器上的相邻层之间通过点对点通信传输,形成流水线。
第三个维度是算子并行(OP),取决于层的类型。对于大语言模型(LLM),主要的层操作是矩阵乘法,因此层实现可同样以 allreduce 操作表达的并行矩阵乘法。"专家混合"模型通常使用与 3D 并行中算子并行类似的专家并行(EP),将 个模型捆绑在一起(典型 到 256),并在它们之间执行 alltoall(v) 操作。alltoall(v) 操作并非总是均衡的。AI 推理并行与此非常相似,区别在于不考虑数据并行,且通常使用非常小的批次,因此作业规模和传输消息通常更小。
后来增加了序列并行和上下文并行等额外的并行维度,可能导致更高维度的通信结构。
作为工作负载示例(约 2023 年),著名的 GPT-3 模型在 96 个 Transformer 层中有 1750 亿个参数。以 FP16 格式存储这些参数需要 350 GiB,这需要 2023 年可用的多块顶级加速器(未计及存储的激活值或训练过程中的其他临时值或副本)。在此场景中,若沿流水线有 6 个加速器、算子并行维度有 4 个,则每 4 个加速器负责 16 个 GPT 解码层。在 2023 年可用的加速器上,这大约需要 160 毫秒的计算时间。每层沿每个维度(流水线和算子)的通信量为 50 MiB。
假设目标服务水平目标(SLO)为 200 毫秒,则 40 毫秒用于流水线通信和环形 allreduce(数据发送两次)。每个加速器现在需要为 allreduce 发送 50 MiB × 16 × 2 次,并沿流水线维度发送一次。因此,需要在 40 毫秒内通信 1.7 GiB,要求 41 GiB/s 的带宽。若要降低延迟,可扩展算子维度并减少通信时间。对于 10 毫秒的服务水平目标,大约需要 150–200 GiB/s 的吞吐量。
AI 采用 3D 并行方案,但除权重外,每个加速器通常还存储权重的"黄金副本"以及其层的所有激活输出,直到在反向传播时应用梯度为止。总体而言,AI 训练工作负载需要极高(且廉价)的带宽,对延迟的敏感度较低至中等。典型消息大小为兆字节或更大量级。
1.3.1.2 AI 推理工作负载
AI 推理工作负载遵循 3D 并行方案,但不提供数据并行,因为每个输入样本是一个用户请求。推理可进行批处理,但通常仅用于提高加速器效率。AI 推理工作负载有时具有严格的服务水平目标要求,以满足交互式使用模式。此时批次更小,导致更小的激活值(流水线消息)和操作(allreduce),这些通常保持在千字节量级。
以 GPT-3 上的生成式 AI 推理为例。此时仅输入一个 token,而非完整序列(GPT-3 为 2048)。因此,一切都按序列长度缩小。在实践中,生成式推理系统通常使用束搜索以提高质量。以束宽为 4 计,总体缩小因子为 512。遗憾的是,权重内存保持不变,导致相同的分布(OP=4,PP=6)。现在计算量可小至 1 毫秒,每个加速器发送约 3.3 MB 数据。在 1.2 毫秒的服务水平目标下,归约操作在 0.2 毫秒内完成,带宽需求为 16 GB/s——但 allreduce 的大小约为 100 KB。若这些操作分布于多个平面,消息大小将在个位数千字节量级。随着分布式 KV 缓存的引入,带宽需求进一步增长!推理通常比训练需要更低的延迟。
1.3.1.3 HPC 工作负载
HPC 工作负载分为两类:(1) 低深度(LD),高度并行;(2) 高深度(HD),具有长依赖链。HD 工作负载通常具有细长的有向无环图(DAG),导致对延迟敏感的执行。许多强扩展问题具有这种形态。
以天气预报为例。在此情况下,计算必须在规定时间内完成。算法在模拟期间进行多次迭代,时间步长与分辨率成反比。更精确的高分辨率模型导致更小的时间步长。在实践中,此类模型具有很高的通信开销(25–50%),大多数消息较小(单包,2.5 kB),且呈周期性模式。
许多其他工作负载为 LD,因此对延迟不那么敏感。大多数可调整本地域大小以适应给定系统的弱扩展工作负载属于此类。其中一些工作负载可能需要高带宽(如 AI 训练)或高消息速率(如图算法)。
1.3.1.4 客户端/服务器(如存储流量)
存储流量将数据从存储服务器传输至端点,是客户端/服务器通信的典型示例。通信栈通常将较大请求分割为多个较小消息(如数 MiB 乃至数 KiB)。这些大小在一定程度上可根据传输协议进行调整。数据访问模式和大小取决于用户,系统管理员鲜少能加以控制。因此,随机 incast 事件(如许多客户同时访问同一存储服务器)会定期发生。
1.4 软件
1.4.1 AI 和 HPC API 接口
UE 设计为支持 libfabric v2.0 API,并与 libfabric 社区合作,使端点能够与 AI 框架和 HPC 工作负载交互。部分 UE 可选特性需要网络设备(如交换机)支持,以实现包裁剪等高级能力。为此,网络操作系统(NOS)需要扩展以支持 UE 特性。
UE 目前不处理跨管理域的交互。
1.4.2 Fabric 端点软件栈
图 1-11 展示了在 FEP 上运行的软件栈。
UE 设计为支持现有 AI 训练(AIT)和 AI 推理(AII)框架。TensorFlow、PyTorch、JAX 等框架预期可无缝运行于 UE 软件栈之上。换言之,UE 的目标之一是使依赖这些框架的应用程序无需修改即可迁移至 UE 驱动的节点上。框架通常利用硬件相关的供应商专有 *CCL 库,而 UE 合规的 *CCL 库虽未直接规范,但不要求修改应用程序。
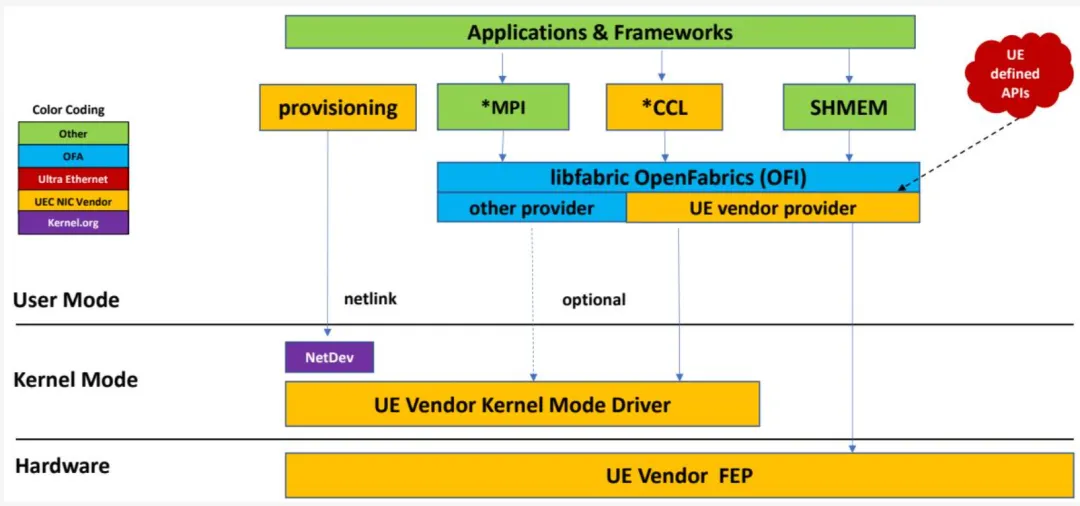
图 1-11 - UE 软件端点栈
1.4.3 交换机软件栈
图 1-12 展示了支持 UE 特性的交换机软件栈示例。UE 运行于现有以太网交换机之上,但通过在交换机中支持可选 UE 特性可获得额外能力。UE 环境中的交换机预期运行各种网络操作系统(如 SONiC、FBOSS、Junos OS、IOS 等)。交换机芯片中的可选 UE 功能可通过交换机访问。交换机的转发范式及其关联网络操作系统(NOS)无需任何更改。基于 IP 的转发可保持不变;然而,UE 定义了可选特性(如包裁剪)。
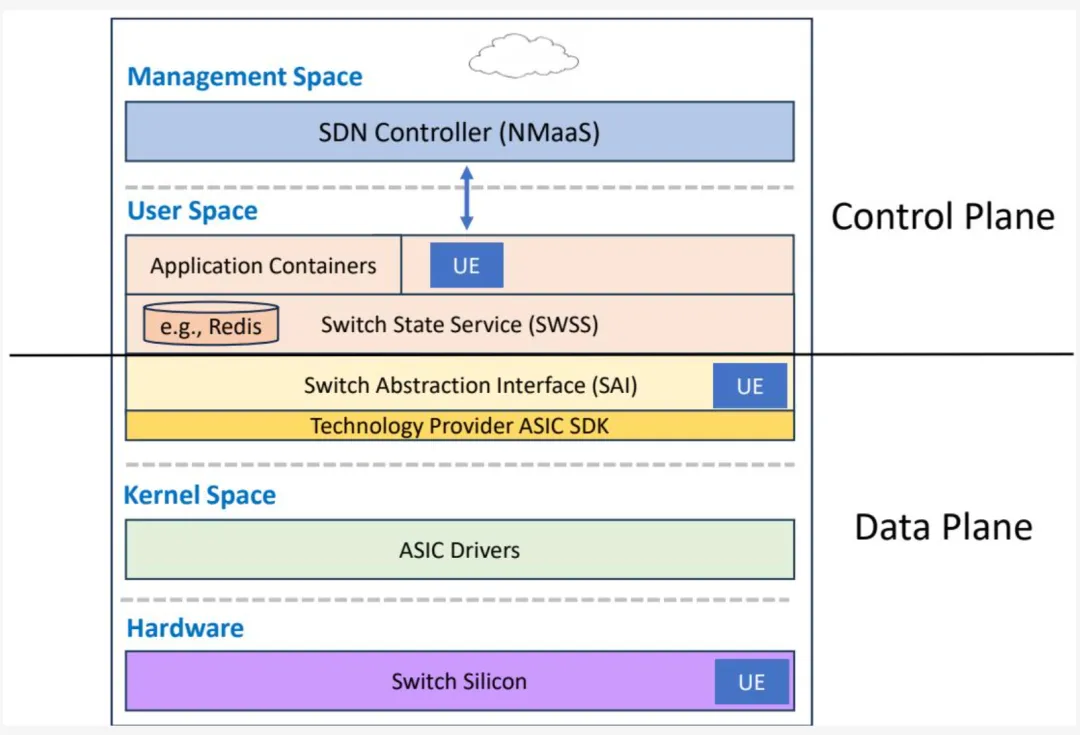
图 1-12 - 交换机模块分层
1.4.4 网络操作系统(NOS)接口
NOS 在交换机上为配置和控制提供基本服务。部分 NOS 组件可能需要更新以支持 UE 特性。以下是一些示例:
用于 LLDP 的 UE 组织特定 TLV。 包裁剪。
图 1-12 展示了各交换机模块的分层。交换机抽象接口(SAI)以上的层称为 NOS 控制平面,以下的功能称为 NOS 数据平面。
控制平面软件通过抽象 API 与数据平面功能交互。一个示例接口是在开放计算项目(OCP)中开发的交换机抽象接口(SAI)。SAI 在供应商提供的软件开发套件之上提供抽象层,帮助 NOS 通过单一一致的 API 集与硬件编程交互。参见以下参考资料:
https://www.opencompute.org/wiki/Networking https://www.opencompute.org/wiki/Networking/SAI
SDN 控制器可能是 UE 实现的组成部分,但超出 UE 规范的范围。
1.5 网络
1.5.1 AI 和 HPC 网络分类
UE 区分三种网络类型,如图 1-13 所示:
前端网络 后端横向扩展网络 纵向扩展网络
1.5.1.1 前端网络
前端网络是数据中心内将所有计算节点连接至外部世界(如其他数据中心或互联网上的终端用户)的运营网络。这使得前端网络成为数据中心最重要的组成部分之一。前端传输的任何可用性损失都会直接影响客户并产生相关成本。由于前端网络连接客户和远程数据中心,它可能需要支持各种传输协议(如 TCP/IP、UDP/IP 和 QUIC),这些协议可在具有毫秒级延迟的长距离链路上运行。此外,计算节点的多租户使用很常见,可能需要网络覆盖以支持虚拟机迁移和网络虚拟化。
从根本上说,前端网络承载两类流量:"南北向"(NS)流量(往返于外部世界,如其他数据中心和客户)和"东西向"(EW)流量(来自同一数据中心内的网络端点)。每类流量具有根本不同的特征。例如,EW 流量通常比 NS 流量带宽更高,且包的"价值"更低(即可以以比 NS 流量更低的代价丢弃和重传)。此外,EW 流量通常有更严格的延迟要求(微秒级)和更高的带宽需求(如数十 Gbit/s),因为它通常连接各种服务(如微服务的深调用链、无服务器函数或存储访问)。NS 流量通常面向客户,瓶颈通常出现在数据中心之外,这些特性可能将延迟限制在个位数毫秒、带宽限制在数十 Mbit/s。
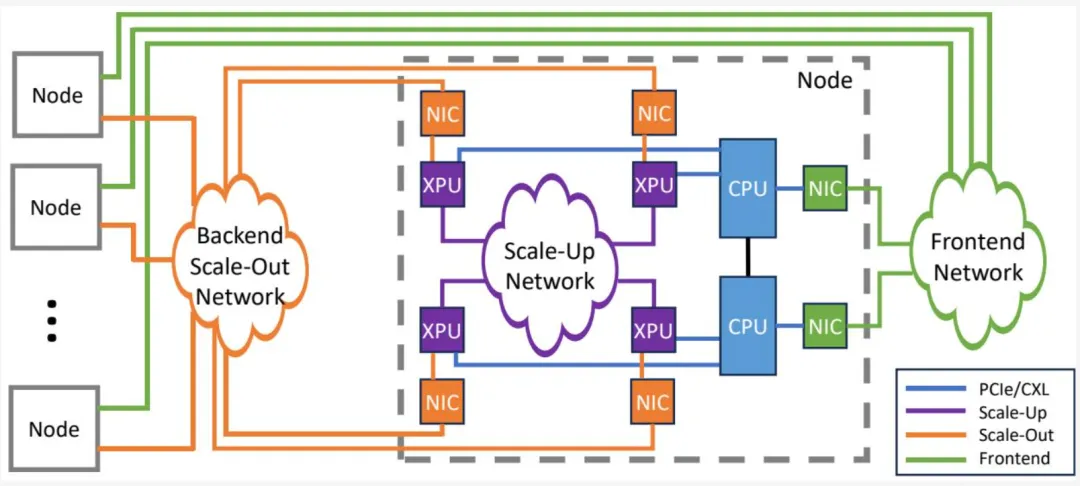
图 1-13 - 网络类型
处理这两类流量并提供高可用性使前端网络相当复杂。交换机和 NIC 需要支持过滤、策略管理、封装和安全等复杂功能。
1.5.1.2 后端横向扩展网络
后端网络通常是相对于前端网络范围有限的专用高性能网络,通常部署于一个"集群"范围内(如一组机架行)。它有时也称为"横向扩展"网络。后端横向扩展网络通常形成其自己的第 3 层子网,通常不直接连接至前端网络。前端网络和后端网络之间的通信通常通过同时具有两个网络接口的计算节点进行。
后端横向扩展网络服务于非常特殊的目的。例如,HPC 后端横向扩展网络通过消息传递接口(MPI)实现通信,而深度学习后端横向扩展网络传输训练流量。面向 AI 的后端横向扩展网络可能包括针对大数据量集合操作的交换机支持等专用优化,而面向 HPC 的后端横向扩展网络可能仅对小型集合操作进行延迟优化。
拥有两个网络可能增加整体系统成本(即两个网络而非一个——独立的前端和后端网络)。然而,两个网络提供了清晰的流量分离(无干扰)和设计分离(允许不同的架构和技术部署)。在一些经典 HPC 系统中,后端横向扩展网络为计算节点提供所有连接和网络服务,但这是通过在 HPC 传输(如 portals、IPoIB)之上改造传统传输协议(如 TCP/IP)并接受其隐含的权衡来实现的。
1.5.1.3 纵向扩展网络
纵向扩展网络通常是高度专用的短距离互连,通常仅有单层交换机,甚至没有交换机。
传统的纵向扩展网络支持 I/O 一致性,而并非所有类型的互连都具备这一能力。用于连接加速器(如称为 GPU、FPGA 或专用 SoC 的 XPU)的现代示例包括 AMD 的 XGMI、NVIDIA 的 NVLINK、Intel 的 Xe Link、交换式 PCIe Express 和 CXL 系统。这些网络的能力通常包括以最低可用延迟(目标低于微秒,适用于小规模或程序化内存访问)的内存语义(类似于大数据块传输的 RDMA)。UE 主要聚焦于后端横向扩展网络,但 UE 技术的概念和部分内容可能适用于纵向扩展网络。
在典型的 2024 年数据中心环境中,三种网络类型以不同特征相区分,如表 1-1 所总结。
表 1-1 - 按网络类型区分的典型特征(约 2024 年)
信息性文本:
本规范聚焦于后端横向扩展网络。UEC 将考虑对前端和纵向扩展网络的机会性支持。其意图是,在权衡取舍时,支持前端或纵向扩展网络的目标不应影响后端横向扩展部署的性能,也不应影响本规范的交付进度。
1.5.2 UE 传输(UET)目标
UET 聚焦于支持 HPC 和 AI(AIT 和 AII)的工作负载与用例。UET 主要面向 RDMA 服务,旨在为 AI 和 HPC 工作负载中的 RDMA 传输提供最优化的现代高性能传输服务。表 1-2 总结了总体特征。三种用例(专用 AI 训练集群、云 AI/HPC 和大规模 HPC)涵盖了将单一应用的全系统规模充分利用的组织,以及用单节点应用填充机器相当比例的组织——以及两者之间的全谱系。UET 的目标是以单一传输协议服务于这些用例的全部范围。
表 1-2 - UET 部署模型特征
UET 的另一个目标是提供对加速器友好的接口,包括定义将集成端点所需硬件复杂度降至最低的规范,以及定义使加速器和其他处理器能够在硬件中完成更多工作的软件方案。例如,UET 可允许加速器拥有"快速路径",并将其他功能(如管理和复杂错误处理)转移至独立处理器(如主机 CPU)。端点内部面向加速器的硬件实现和接口细节超出本规范的范围。
UET 在利用多路径和网络遥测辅助改进拥塞控制的尽力而为网络上提供卓越性能的同时,也被设计为可在无损网络上运行。对于尽力而为网络,UET 汲取了以太网、TCP/IP 以及为各种应用(含云)部署的大规模网络成功经验的两个基本教训:传输协议应提供丢失恢复,以及许多大规模无损 Fabric 在运营中难以避免触发队头阻塞和拥塞扩散。遵循这些原则,UE 传输建立在分布式路由算法以及基于端点的可靠性和拥塞控制这一经过验证的路径之上。
1.5.3 网络 Fabric
网络 Fabric 由以太网交换机及下述相关要素组成。
1.5.3.1 要素
UE 交换 Fabric 包含三个常见功能平面:控制平面、数据平面和管理平面,如图 1-14 所示,描述如下。
1.5.3.1.1 控制平面
控制平面负责运行关键功能,如路由协议,以维护 Fabric 交换机之间的通信。该层由 SONiC、FBOSS 等网络操作系统(NOS)管理。控制平面通过 SAI 等标准 API 或供应商特定 API 与交换机数据平面交互。
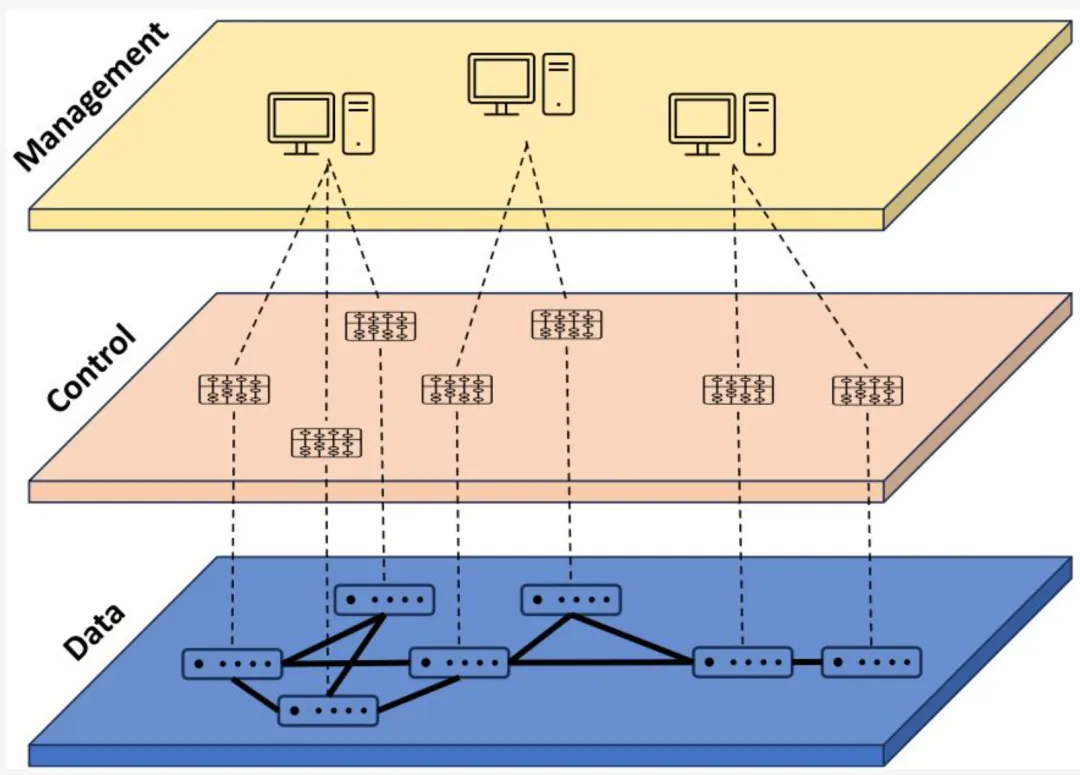
图 1-14 - 网络功能的分层视图
1.5.3.1.2 数据平面
数据平面又称转发平面,负责在网络中转发包。该层跨越 UE 端点(即 FEP)和网络交换机。需要说明的是,数据平面不控制或管理 UET FEP。该层包含交换机硬件的较低层抽象,负责根据控制平面提供的转发信息转发包。
1.5.3.1.3 管理平面
管理平面负责确保交换 Fabric 的运行、可靠性和安全性。管理系统及其关联协议执行软件升级、监控和其他管理活动。管理平面通过 Netconf、gNMI、SNMP 等标准接口与控制平面交互。管理平面所操作的被管对象由 YANG 等标准化数据模型定义,并由 OpenConfig 等供应商中立软件支持(参见:https://openconfig.net)。
信息性文本:
传统上,端点管理与 Fabric 管理是分开的。UE 遵循业界和组织已习惯的传统分离方式。UEC 管理工作组负责确保 UE 合规设备的完整功能、性能和互操作性。
1.5.3.2 UE 交换机在物理网络中的运行
UE 合规交换机在两类物理网络中运行:
UE 数据平面网络:通过 UE 交换机将 FEP 相互连接的网络,承载各类工作负载的应用流量,并针对 UE 规范进行优化。 交换机管理网络:每台交换机至少提供一个专用以太网端口,用于连接 SDN 控制器、Fabric 管理器、遥测收集器、SNMP 服务器等负责管理基础设施的非 Fabric 端点。该网络对延迟不敏感,带宽需求通常较低。
1.5.3.3 拓扑
拓扑是 AI 和 HPC Fabric 的关键组成部分,通过确定网络直径和对分带宽来设定性能边界。部署时需考虑能耗和线缆成本等物理因素,以实现最优的系统成本。
本规范中的拥塞管理以 Clos 网络为目标,但不排除其他拓扑。然而,本规范不为折叠 Clos 网络(即胖树)以外的拓扑设置任何优化或性能目标。本规范中的拥塞管理已在胖树网络拓扑上进行仿真验证。
1.5.3.4 网络约束
UE Fabric 被约束为使用基于 IPv4/IPv6 的第 3 层转发。使用隧道(如 VXLAN)的 UE Fabric 目前未被规范,留给实现者自行决定。多租户可在 FEP 层面通过加密租户应用数据、特定的 JobID 分配来实现,也可利用现有的隧道机制。
UE 不要求对网络层进行修改,可使用现有路由协议。UE 交换机使用等价多路径(ECMP)路由进行负载均衡,熵值由 UET 拥塞管理子层(CMS)管理。拥塞管理算法的设计预期 Fabric 交换机不修改熵值,且具有相同熵值的任意两个包在 UE Fabric 中经过相同路径。CMS 期望 UE 交换机按照 IETF RFC 3168 的规定支持显式拥塞通知(ECN),但附加约束为在出队发送时(而非入队时)对拥塞包进行标记。包裁剪(见第 4.1 节)是拥塞通知的额外机制,利用多个差分服务代码点(DSCP)来标识可被裁剪和已被裁剪的包,并确保将其映射到适当的流量类别以进行加速转发。
流量类别体现为端点和交换机内用于包差异化传输的机制与资源(如队列、缓冲区、调度器)。流量类别相互区分且可相互间设置优先级。接收包的属性和头字段用于将包映射至流量类别。UE 主要依赖 IP 头中的 DSCP 字段来识别接收包的流量类别。
信息性文本:
流量类别在多个层面进行规定。UE 将 libfabric 层指定的流量类别映射至 Fabric 中的流量类别。例如,UET 建议为请求和 ACK/NACK 设置独立的流量类别。UET 选择宽泛的流量类别定义,以兼容通过 DSCP 标识的包实现差异化转发的各种排队资源和转发机制实现。DSCP 可标识 64 种不同的差分服务,其中 16 种可供本地定义和使用。实现方式提供了多种将 DSCP 标识的包映射至端点链路和交换机层流量类别的配置手段。目前 UE 尚未标准化或定义执行此映射的方法。在某些情况下,多个 DSCP 值可映射至同一流量类别(见 CMS 第 3.6.4.7 节中的 UET DSCP 映射表)。UE 特性依赖于端点和 Fabric 中流量类别的一致配置和使用。UE 推荐一致的映射方式,网络运营者负责保证此一致性。
图 1-15 展示了应用程序请求的流量类别到端点和交换机链路层可用流量类别的映射关系。虚线框内的项目是 UE 运营者在 UE 解决方案栈不同层次可用的配置值。应用程序可使用 fi_domain() 库 API 指定所需的 libfabric 流量类别;若未指定,UE libfabric 映射第 2.2 节提供了请求使用的默认 DSCP 值。CMS 规范在第 3.6.4.7 节提供了 DSCP 至流量类别的映射表,描述了不同 DSCP 值类别如何在链路层映射至流量类别。
libfabric 层提供的消息请求 DSCP 值被传递并归类为 DSCP_TRIMMABLE 或 DSCP_NO_TRIM。UET 协议包含为生成的 ACK、NACK 和控制包使用的 DSCP 值,归类为 DSCP_CONTROL。UET 协议还可将重传数据包标记为 DSCP_TRIMMABLE_RETX。所有这些 DSCP 类别均映射至链路层流量类别 TC_high 和 TC_low,两者之间具有高低优先级关系。
执行包裁剪的交换机(图 1-15 中以剪刀图标表示)将 DSCP 值更改为 DSCP_TRIMMED 或 DSCP_TRIMMED_LASTHOP,取决于其在 Fabric 拓扑中的位置。裁剪包的 DSCP 值可映射至第三个流量类别(TC_med,若可用),否则使用 TC_high。交换机内 DSCP 值至流量类别映射的管理操作目前为供应商特定或尚未规范。
UET 的拥塞管理子层设计时预期对 PDC 使用至少两个流量类别以实现高性能。网络运营者负责分配和配置 UET 所使用的流量类别。UET 包类型至流量类别的映射取决于网络是尽力而为还是无损。详见 CMS 第 3.6.4.7 节。
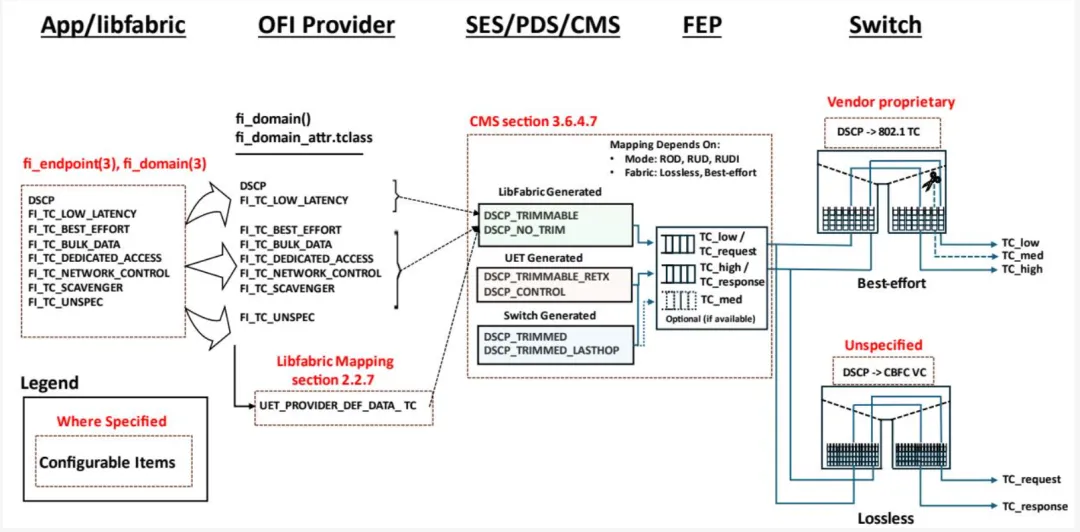
图 1-15 - 流量类别映射
1.6 UE 规范概览:各层
UE 规范跨越从软件到物理层的多个层次。图 1-16 按层次展示了 UE 规范的必需和可选组件,以下各节对每个层次进行概述。
图 1-16 - 按层次划分的 UE 规范
1.6.1 软件层
UE 软件规范在第 2 节提供,包含至 libfabric API 的映射。
libfabric 映射:UE 合规实现支持开放 Fabric 接口——libfabric API(https://ofiwg.github.io/libfabric/)。Libfabric v2.0 是 UE 合规端点的基线 API。Libfabric 是定义并检验 UE API 合规性的北向 API。UE 规范预期与 libfabric 社区保持对齐。选择 libfabric 是因为它支持基于 RDMA 的 Fabric 上的多种工作负载,并已被众多构建硬件和软件以满足规范的供应商所实现。多家供应商已成功创建产品,在支持基于 MPI 的 HPC 应用的同时,也允许 PGAS、SHMEM 和其他编程模型。与此同时,供应商已创建支持 PyTorch、TensorFlow 或 ONNX 等流行 AI 框架的库。所有这些供应商产品均被证明可轻松高效地映射于 libfabric 之上。UEC 与 libfabric 社区合作,在适当且必要时扩展 libfabric API,以支持新的 UE 特性。
1.6.2 传输层
UE 传输层规范在第 3 节提供。UE 传输协议旨在满足 HPC 和 AI 工作负载的网络需求。为满足工作负载的独特需求并实现产品优化,定义了不同的配置文件。预计 AI 和 HPC 工作负载的网络需求将日益重叠。UE 传输协议支持广泛的实现方式,其组成部分包括包传递可靠性模式、拥塞管理和安全。
语义子层(SES):SES 子层通过 libfabric 映射集成到广泛部署的 AI 框架和 HPC 库中,进行消息处理。
包传递子层(PDS):应用需求决定了适当 UET 包传递服务的选择。不同应用针对消息传递的各种可靠性和包顺序约束进行优化。通过 UET 分层模型及其关联库,应用可选择最适合其需求的传输协议功能。PDS 子层定义了具有多种操作模式的协议,提供可靠、不可靠、有序和无序包传递服务的所有组合。
拥塞管理子层(CMS):端到端拥塞管理对于实现高网络效率、减少包丢失、在保持竞争流公平性的同时最小化延迟至关重要。流量类别用于将具有不同特征和网络需求的流量流分开。为维护公平性并保证低延迟控制环路,UE 拥塞管理被设计为对同一流量类别中的所有流量使用。流量类别配置是网络运营者的责任。高网络效率和低延迟通过允许 UET 拥塞管理在拥塞信号到达时跨 Fabric 进行多路径包喷射、避免热点来实现。在 UET 下,具有无序流的 PDC 可同时使用所有到达目标的路径,实现更均衡的网络路径利用。端点与交换机之间路径的协调选择(受实时拥塞管理引导)避免了链路负载不均衡,这种细粒度的负载均衡改善了网络利用率并降低了尾延迟。
传输安全子层(TSS):AI 训练和推理通常在需要作业隔离的托管网络中进行。此外,AI 模型越来越敏感,并成为宝贵的商业资产。认识到这一点,UE 传输将网络安全设计融入其中,可对 AI 训练或推理作业中计算端点之间发送的所有网络流量进行加密和认证。随着作业规模的增大,有必要支持加密而不使主机和网络接口中的会话状态膨胀。为此,UET 引入了新的密钥管理机制,允许参与作业的大量计算节点之间高效共享密钥。它被设计为可在 AI 训练和推理所需的高速度和大规模下高效实现。在大型以太网络上托管的 HPC 作业具有类似特征,需要可比较的安全机制。注意,TSS 是可选特性。
1.6.3 网络层
可选的 UE 网络层特性规范在第 4 节提供。UE 不要求对网络层进行任何修改,但 UET 拥塞管理期望按照 IETF RFC 3168 的规定支持显式拥塞通知(ECN),附加约束为在出队发送时(而非入队时)对拥塞包进行标记。
包裁剪:Fabric 内的拥塞不可避免。随着 Fabric 速率的提高和有限交换机芯片缓冲的压力加大,拥塞信号愈加频繁,这些信号中的信息对于确定纠正措施愈加重要。UE 定义了包裁剪特性,允许交换机截断拥塞包、修改截断包的 DSCP 字段,并将截断包作为拥塞信号向目标转发。包裁剪比单独的 ECN 位提供了显著更多的拥塞信息。包裁剪对交换机为可选实现,对 FEP 接收裁剪包为强制要求。
1.6.4 链路层
可选的 UE 链路层规范在第 5 节提供。UE 规范在链路层增加了几个可选特性,并认识到推出支持这些特性的产品可能需要更长时间。部分工作负载可能受益于这些特性,而大规模实验可能是证明这一点的最佳方式。此外,IEEE 802 等其他 SDO 可能对更改部分特性感兴趣。
图 1-17 展示了 UE 链路层规范相对于 IEEE 802 链路层架构的关注领域。UE 对链路层的可选建议涉及阴影区域。所有特性对 UE 合规均为可选。
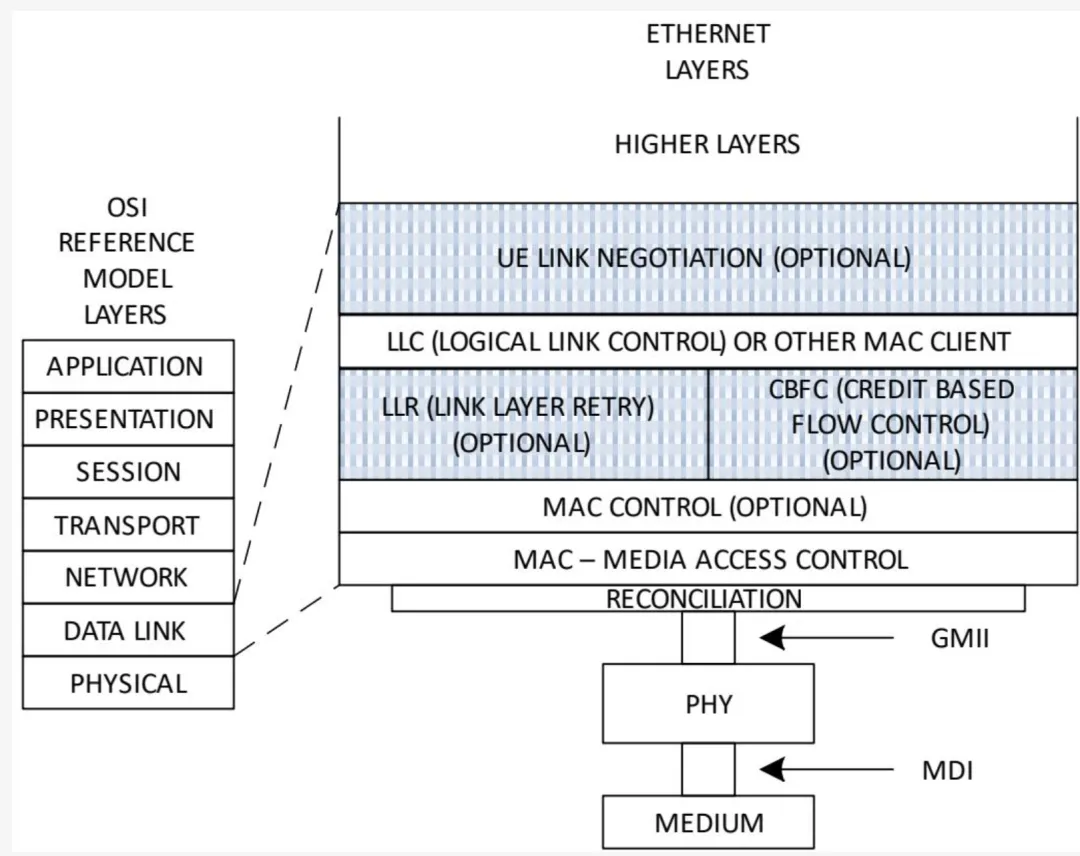
图 1-17 - UE 链路层规范关注领域
链路层重传(LLR):随着速率和规模的增大,以及加速器网络中常见的极端带宽密度,仅依赖端到端重传来处理包丢弃对延迟敏感型工作负载的负担日益加重。链路层的本地错误处理在横向扩展 HPC 网络(如超算系统)中已被证明有价值。UE 规范为以太网提供了这一能力。
基于信用的流量控制(CBFC):传统以太网络不使用基于信用的链路,而这在 Fabric 技术中很常见。然而,部分近期推出的产品已支持该功能,并对部分工作负载有可选的改进效果。CBFC 是 UE 链路层的可选特性。
1.6.5 物理层
UE 物理层规范在第 6 节提供。UE 规定使用 IEEE Std 802.3 定义的每通道 100G 信令的物理层。
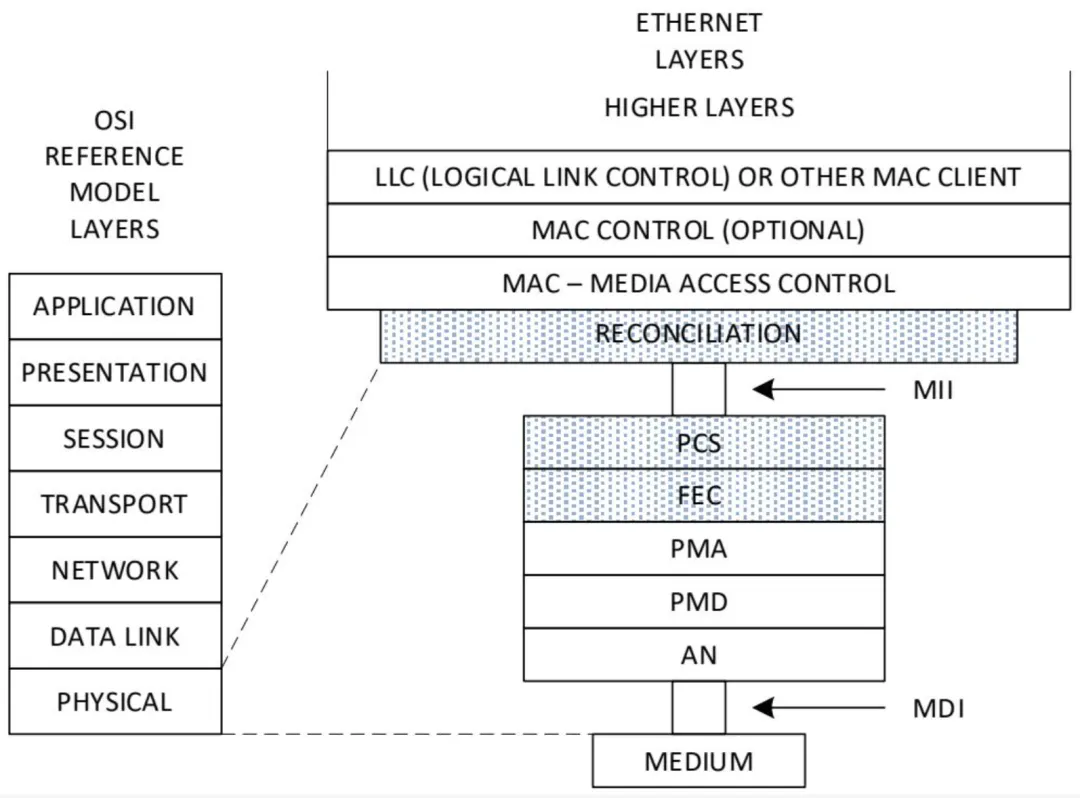
图 1-18 展示了 UE 物理层规范相对于 IEEE 802.3 PHY 架构的关注领域。UEC 对物理层的可选建议涉及阴影区域。 图 1-18 - UE 物理层规范关注领域
IEEE 802.3 每通道 100G 信令:UE 物理层章节列出了在 UE 范围内的 IEEE 802.3 规范。
信道质量假设:加速器节点比标准端点或 TOR 交换机更为复杂。在发布时,假设 IEEE 标准已足够,但鼓励 UE 产品构建更鲁棒的信道。
FEC 统计用于链路质量预测:UE 网络被假定由多条受前向纠错(FEC)保护的高性能链路组成,物理层错误导致的数据丢失极为罕见。然而,在大规模网络中,可能存在少数链路的错误率高于网络其余部分。对于大规模并行应用,FEC 统计对链路质量预测具有重要意义,有助于改善网络性能或对其端点提供服务。