


第一章 结论速览与核心决策
v3核心观点变化
v2报告偏重模型选型对比;v3基于用户反馈,全面转向工程方案。核心变化:(1)ASR准确率不是"选对模型"就能解决的,需要系统性的工程闭环;(2)双工对话的关键不在模型而在工程——语义判停、噪声过滤、协议选型;(3)弱网问题的解决靠Opus/QUIC工程调优,不靠模型。
1.1 核心技术决策速览
| 系统架构 | |||
| ASR准确率 | |||
| 端点检测 | |||
| 打断处理 | |||
| 传输协议 | |||
| 弱网策略 | |||
| 网络切换 | |||
| 对话框架 |
1.2 关键指标
~640ms
优化后端到端延迟
200-600ms
语义端点节省
86%
AIH打断精度
20-50%
热词CER改善
1.3 P0行动清单
- 部署语义端点检测
: 替代固定超时,节省200-600ms首音延迟 - 实现会话级Context Graph热词
: 订单+位置→动态热词表,热词CER改善20-50% - 搭建跨模型热词挖掘管线
: 5%流量采样→外部强ASR→自动发现长尾热词 - 接入LiveKit AIH
: 过滤51%噪声误打断,提升对话自然度 - 客户端切换WebRTC
: 弱网下延迟从200-500ms降至50-100ms - Opus FEC自适应
: 根据丢包率动态调整FEC/码率/帧大小
1.4 技术路线图
Phase 1 (月1-6)Pipeline优化+热词+AIH
Phase 2 (月6-12)LLM纠错闭环+QUIC评估
Phase 3 (月12-18)多模态挖掘+Hybrid试点
第二章 研究方法
2.1 研究范围
第三章 架构范式与TTS技术概要
3.1 Pipeline vs E2E vs Hybrid
三种架构对比
| 架构 | |||
| 中间文本 | |||
| SOP可控性 | |||
| 热词支持 | |||
| 延迟(优化后) | |||
| 中文成熟度 | |||
| 合规审计 | |||
| 工具调用 |
架构决策
2026年:Pipeline是唯一正确选择。原因:(1)企业客服需要SOP控制(话术合规、流程管控);(2)热词纠偏只在Pipeline中有效;(3)合规要求文本可存可审;(4)E2E S2S在中文场景无可用方案(Gate评估见第十一章)。
E2E S2S Gate-Based评估 (2026.03)
| 未通过 | |||
| 未通过 | |||
| 通过 | |||
| 接近 | |||
| 未通过 | |||
| 部分 | |||
| 未通过 | |||
| 未通过 |
8个Gate中仅G3通过,G4接近。结论:2026年E2E S2S不可用于企业级客服,2027年H2可能在受限场景(确认/取消)试点。
3.2 TTS技术概要
公司有自研TTS,本节仅提供前沿技术方向参考,不做选型建议。
TTS架构演进
| CosyVoice 3 RL | |||
| Spark-TTS | |||
流式TTS关键指标
流式合成策略
Chunk-based streaming: LLM输出→按标点/固定长度分chunk→每chunk独立合成→流式播放。关键参数: chunk大小(字符数)影响延迟和自然度的trade-off。小chunk(10字)延迟低但韵律差,大chunk(50字)韵律好但延迟高。推荐: 首chunk 10-15字(快速响应),后续chunk 30-50字(提升韵律)。
打断回滚
用户打断时: (1)立即停止音频播放; (2)清空TTS缓冲队列; (3)取消待合成的chunk; (4)记录已播放位置(char_index); (5)LLM上下文标注"说到哪里被打断"。
第四章 ASR准确率工程——从热词到LLM纠错闭环
4.1 准确率提升全景框架
方案延迟-效果矩阵
| Context Graph | ||||
| 上下文热词预加载 | ||||
| 跨模型热词提取 | ||||
4.2 跨模型热词提取
核心思路
采样5-10%流量,同时送给自研ASR和外部最强ASR(如Seed-ASR API/阿里灵积等)。对比两者输出,提取外部ASR识别正确但自研ASR识别错误的专名词,自动添加到自研ASR的热词表中。
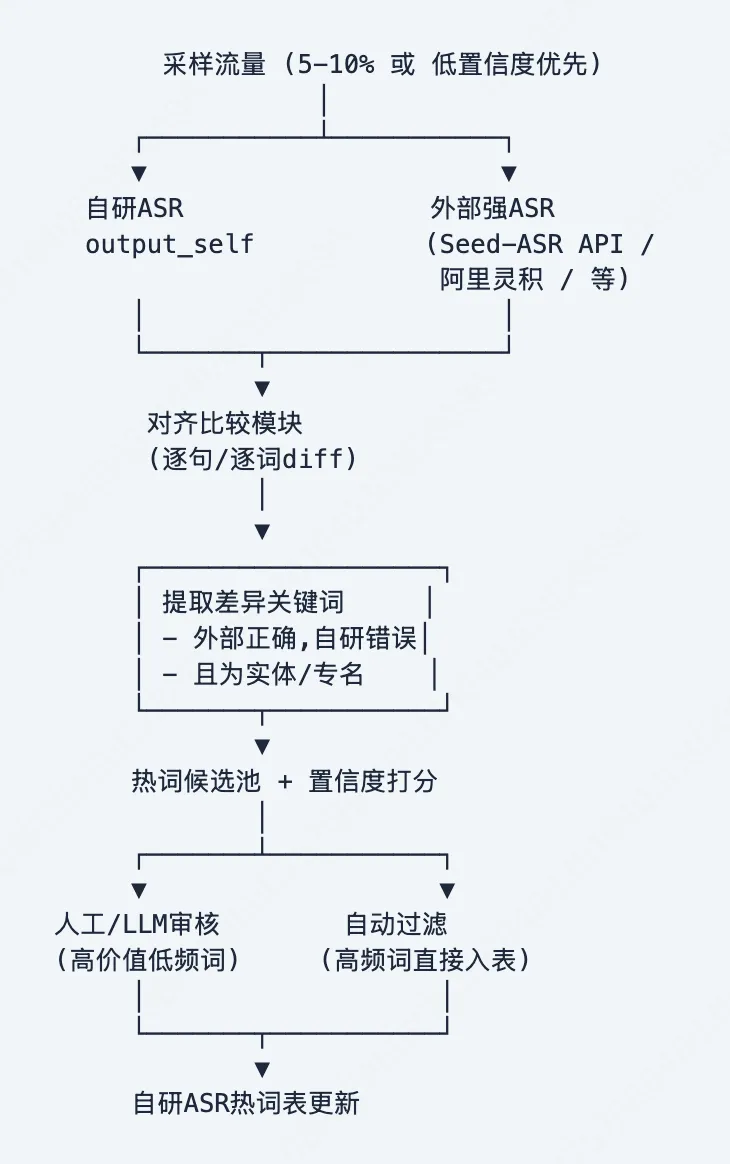
工程实现要点
# 跨模型热词提取伪代码def extract_hotword_candidates(self_output, ext_output, ner_model): # 1. 文本对齐(编辑距离) alignment = align_texts(self_output, ext_output) # 2. 提取差异片段(外部正确,自研错误) diffs = [seg for seg in alignment if seg.type == 'substitution' and seg.ext_correct] # 3. NER过滤:只保留实体/专名 candidates = [] for diff in diffs: entities = ner_model.extract(diff.ext_text) for ent in entities: if ent.type in ['POI', 'PRODUCT', 'ADDRESS', 'PERSON']: candidates.append({ 'word': ent.text, 'type': ent.type, 'freq': count_in_corpus(ent.text), 'self_error': diff.self_text, # 自研ASR错误识别成了什么 }) # 4. 去重 + 按频率排序 return dedupe_and_rank(candidates)采样策略
| 置信度采样 | |||
热词更新周期
4.3 LLM后处理纠错管线
学术背景
| HyPoradise | ||
| GenSEC | ||
| ASR-EC | 首个中文ASR纠错基准 | |
| Pinyin-GEC | ||
| Full-text EC | ||
| Confidence EC |
分层纠错管线设计
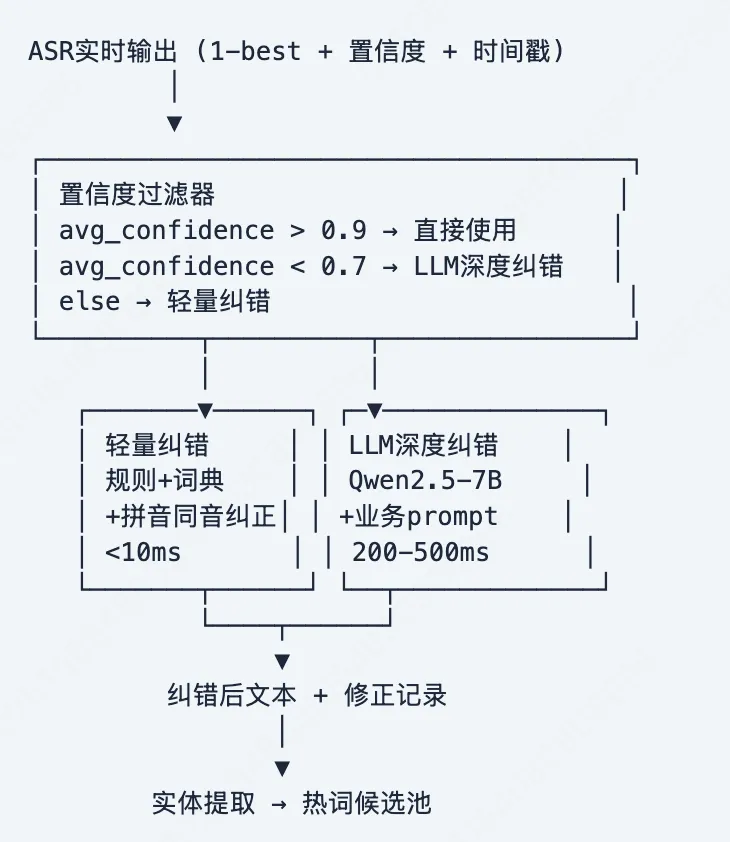
中文ASR纠错prompt示例
你是一个中文ASR纠错专家。以下是语音识别输出,可能包含同音字错误。业务上下文:用户咨询{业务线},位于{城市}热词参考:{hotword_list}ASR原始输出:"{asr_output}"请修正其中明显错误(特别是专名/同音字),不确定的保持原样。输出JSON:{"corrected": "修正后", "changes": [{"from": "原", "to": "正", "reason": ""}]}三层纠错效果对比
| 第一层(实时) | ||||
| 第二层(近线) | ||||
| 第三层(离线) |
关键洞察(来自ASR-EC基准)
纯文本prompting在中文ASR纠错上效果差(因同音字多,单纯文本上下文不够)。解决方案:(1)加入拼音信息(Pinyin-GEC方案);(2)加入音频(多模态方案,效果最好但延迟高);(3)加入业务上下文(热词表+订单信息)。
4.4 N-best重排序与置信度驱动
N-best LLM重排序
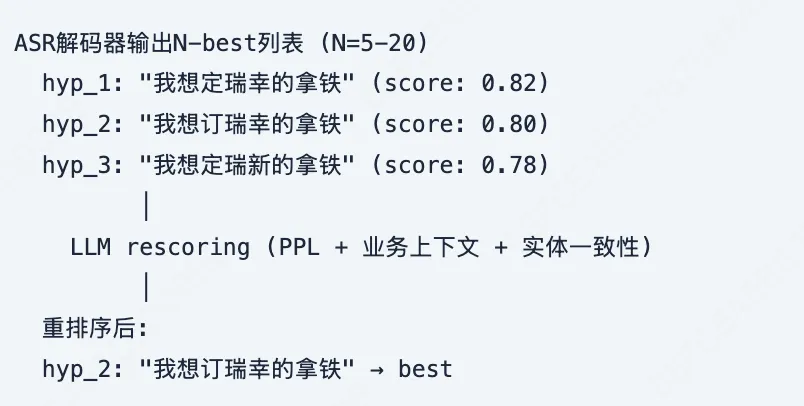
受限解码(Ma et al., arXiv 2409.09554):基于N-best列表约束LLM的输出范围,避免LLM"幻觉"生成ASR根本没听到的词。跨ASR系统泛化性好。
置信度驱动的处理策略
4.5 上下文检索增强
会话级动态热词构建

热词来源优先级
| 当前订单 | ||||
| 跨模型挖掘 | ||||
4.6 持续学习闭环
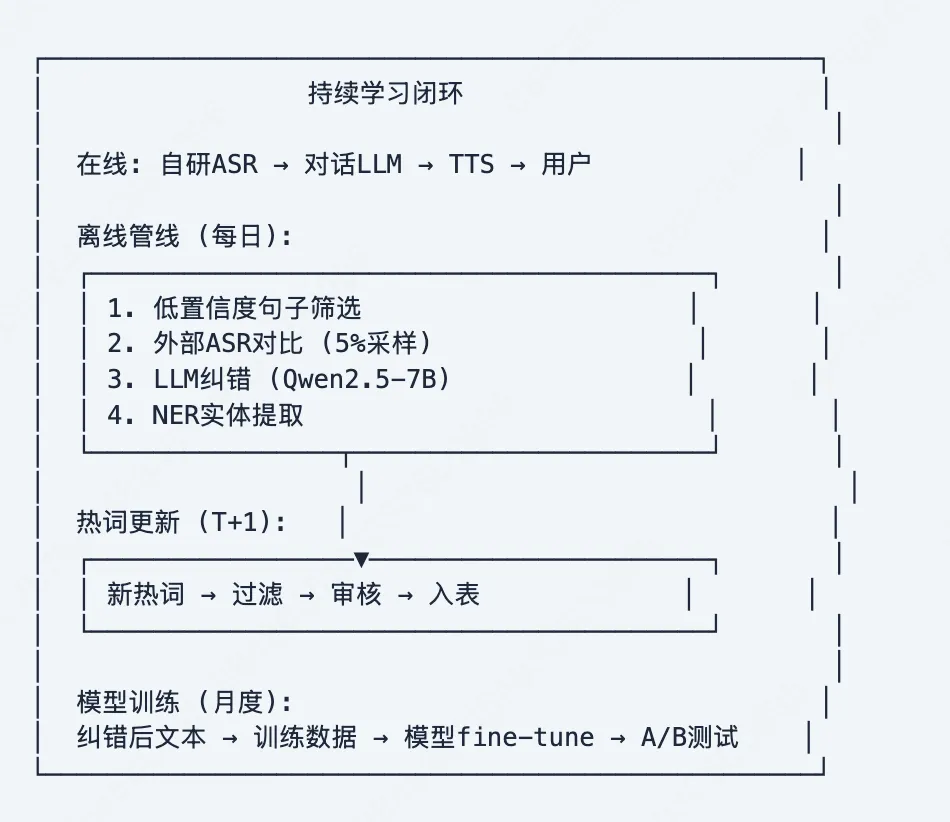
关键度量
实施路径
Phase 1 (月1-3)Context Graph + 会话热词
Phase 2 (月3-6)跨模型热词挖掘
Phase 3 (月6-12)LLM纠错闭环 + 多模态挖掘
第五章 热词纠偏算法与工程实践
5.1 Context Graph算法原理
数据结构
Context Graph基于字符级前缀树(Trie) + Aho-Corasick失败链接。在CTC/RNN-T解码的beam search过程中,每个假设额外携带一个Context Graph的遍历状态。
热词: ["星巴克", "星巴克臻选", "瑞幸咖啡", "肯德基"]前缀树: root (s0) / | \ 星(s1) 瑞(s6) 肯(s10) | | | 巴(s2) 幸(s7) 德(s11) | | | 克(s3) 咖(s8) 基(s12) ✓ | ✓ | 臻(s4) 啡(s9) ✓ | 选(s5) ✓Aho-Corasick失败链接: s6("瑞")的失败链接 → s0(root) s4("星巴克臻")的失败链接 → s0(root)Beam Search加分机制
CTC beam search with Context Graph:for each time step t: for each beam hypothesis h: # 正常CTC得分 base_score = ctc_score(h, t) # Context Graph加分 cg_state = h.context_state # 当前在Trie的位置 char = h.last_char if can_advance(cg_state, char): new_state = advance(cg_state, char) if is_final(new_state): # 完成一个热词!给额外加分 bonus = hotword_boost * len(matched_word) h.score += bonus else: # 部分匹配,给小加分鼓励继续匹配 h.score += partial_boost else: # 不匹配,通过失败链接回退 h.context_state = fail_link(cg_state)典型参数: hotword_boost = 2.0-5.0 (完整匹配加分) partial_boost = 0.5-1.0 (部分匹配加分) 热词长度加权: 越长的热词匹配越难,加分越高性能特征
5.2 CPPN / Deep Biasing
CPPN (Contextualized Phoneme Prediction Network)
CPPN在RNN-T的Predictor层注入热词信息。与Context Graph不同,CPPN在模型内部影响预测,而非仅在解码阶段加分。
Contextual Adapter (Jain+, ICASSP 2020)
在编码器后增加注意力层,对热词embedding做cross-attention。思路类似CPPN但位置不同(编码器后vs Predictor)。
5.3 LLM Biasing
GLCLAP + GRPO (arXiv 2512.21828)
最新的LLM Biasing方案,将热词纠偏建模为LLM生成任务:
- GLCLAP
: 结合音频和热词列表,让LLM同时"听"和"看"来纠正 - GRPO
: Group Relative Policy Optimization, 用RL优化纠错效果 - 热词规模
: 支持100K+热词(远超Context Graph的10K) - 延迟
: 100-500ms(LLM推理,不适合实时first-pass) - 适用
: 作为second-pass或离线纠错
各方案使用时机
| Context Graph | |||
5.4 百万级POI热词工程
大规模POI热词挑战
三层热词架构
Layer 1: 全局热词表 (~10K, Shallow Fusion) - 高频POI/商品名/地址 - 月度更新 - 所有通话共享Layer 2: 城市/区域热词表 (~5K, 选择性加载) - 本城市POI - 按用户IP/手机号归属地选择 - 每日更新Layer 3: 会话级Context Graph (~500, 动态构建) - 当前订单POI + 商品名 + 地址 - 近30天历史订单 - 区域附近POI - 每通电话独立构建, <10ms第六章 双工对话系统——Turn-Taking与全双工工程
6.1 Pipeline语音对话系统架构
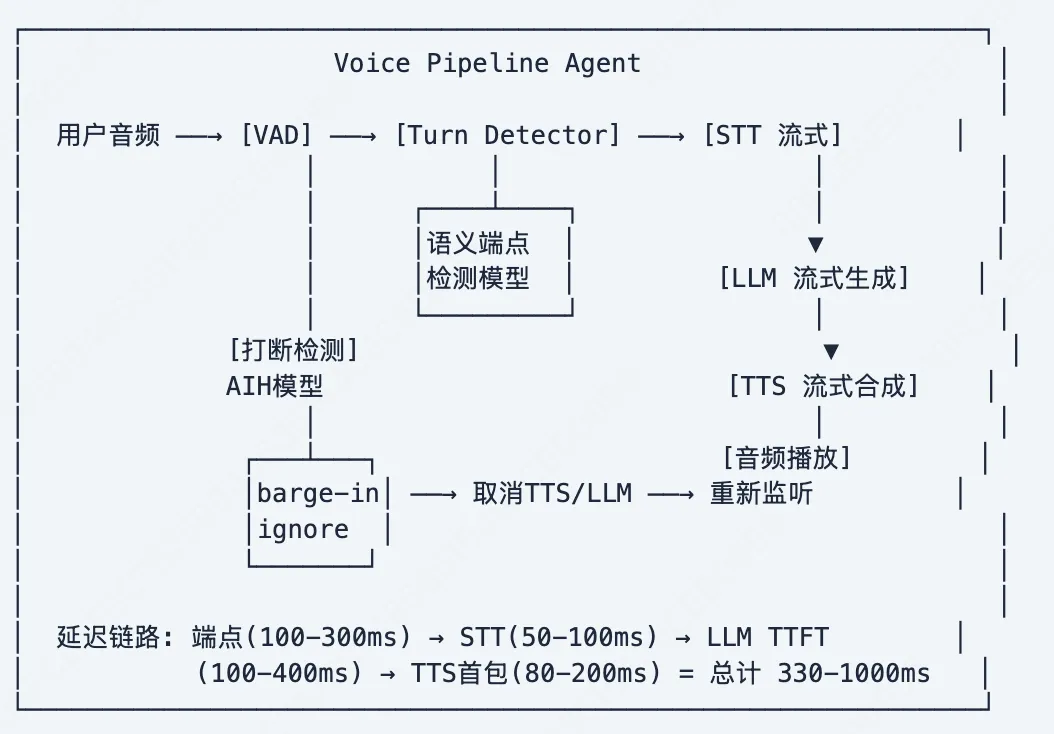
各组件延迟要求
| VAD | |||
| Turn Detector | |||
| STT | |||
| LLM | |||
| TTS | |||
| AIH |
6.2 语义端点检测——提前判停
为什么端点检测是最高ROI的优化
端点检测在延迟预算中占比最大(200-800ms)。从固定超时(800ms)优化到语义检测(200ms)可节省600ms。这比优化任何模型推理速度的收益都大。
五级端点检测体系
| L4 | 语义端点模型 | 100-200ms | 高 | 高 |
语义端点检测原理
输入特征融合: 声学: 能量包络(下降→可能结束), 语调(下降→陈述句结束), 语速变化 语言: ASR partial transcript, 句法完整度, 语义完整度 对话: 对话轮次, 期望回复类型, 历史turn时长 │ ▼ 端点预测模型 (Transformer) 输出: P(end_of_turn) ∈ [0, 1] │ if P > threshold (0.7-0.85): → 触发 STT final → 开始 LLM 生成 else: → 继续监听提前判停策略 (Predictive Endpointing)
时间线: t=0 t=500ms t=800ms t=1000ms t=1200ms |---------|----------|----------|----------| 用户开始 "我想查" "我的订单" 静音开始 传统判停 Predictive Endpointing: t=800ms: partial="我想查我的订单" 语义端点: P(end)=0.85 > 0.7 → 立即开始LLM预生成(推测执行) → 节省: ~400ms t=1200ms: VAD确认停说 → 如果预生成匹配 → 直接播放(已ready) → 如果不匹配(用户又说了"的快递") → 取消,重新生成6.3 噪声误打断识别与过滤
误打断来源分析
LiveKit AIH (Adaptive Interruption Handling)
LiveKit AIH性能指标
Precision:86%| Recall:100%| 推理延迟:≤30ms| 中位音频需求:216ms| VAD误打断过滤:51%| 比VAD更快检测真打断:64%
AIH训练与部署
- 训练数据
: 数百小时人类自然对话(含打断、回馈、噪声标注) - 数据增强
: 添加各种环境噪声模拟真实场景 - 多语言
: 训练覆盖多语言,无需针对中文重训(学习对话动态而非语言内容) - 部署
: LiveKit Cloud GPU推理,或Agent v1.5+ / TypeScript v1.2+ - 配置
: 默认 interruption.mode: "adaptive",可回退到"vad"
自建方案(如不使用LiveKit Cloud)
class InterruptionClassifier: def __init__(self): self.vad = SileroVAD() self.audio_encoder = Wav2Vec2Small() # 预训练音频编码器 self.head = nn.Sequential( nn.Linear(768, 256), nn.ReLU(), nn.Dropout(0.3), nn.Linear(256, 3), # barge_in, backchannel, noise ) def classify(self, audio_200ms): if not self.vad.is_speech(audio_200ms): return 'noise' features = self.audio_encoder(audio_200ms) return ['barge_in', 'backchannel', 'noise'][self.head(features).argmax()]# 训练数据需求: 1000+小时对话(含打断标注) + 噪声增强# 开发周期: 2-3个月# 建议: 直接用LiveKit AIH, 自建ROI不高6.4 打断处理与TTS回滚
打断处理流程
Agent正在播放TTS: "您的快递已经发出,预计明天下午到达,快递员..." ↑ 用户: "等等,我要改地址"打断处理 (<100ms完成):1. 立即停止TTS音频播放2. 清空TTS待播放缓冲3. 取消LLM正在生成的token4. 记录: 已播放到 char_index=16 ("预计明天下")5. 切换回监听模式LLM上下文更新: system: "你之前说了'您的快递已经发出,预计明天下', 被用户打断。用户说: '等等,我要改地址'。 请处理用户的新请求,不要重复已说过的内容。"SOP场景的打断控制
allow_interruptions=False | ||
interruption.mode="adaptive" |
6.5 回复延迟极致优化
优化策略矩阵
| 语义端点检测 | |||
| Pipeline全流式 | |||
| 首句简短承接 | |||
| 模型co-location | |||
首句简短承接策略
传统方式: 用户: "我的快递怎么还没到?" LLM生成全部回复后TTS: "让我帮您查询一下物流状态。您的包裹..." → 总延迟: 400-800ms优化方式 (首句承接 + 后续详细): 用户: "我的快递怎么还没到?" LLM第一句: "好的," → 立即TTS播放 (感知延迟~300ms) 用户听"好的"的同时,LLM继续生成详细回复 → TTS跟上 prompt: "当用户提问时,先用简短承接语(如'好的'、'我帮您看看') 回应(不超过4字),然后给出详细回答。"热门回复预缓存
外呼场景高频回复预缓存: "好的/可以/行" → 预生成TTS: "太好了,那我帮您确认一下..." "不要/不需要" → 预生成TTS: "好的,那您有其他需要吗?" "什么意思" → 预生成TTS: "我再详细说一下..." "转人工" → 预生成TTS: "好的,正在为您转接..." 命中率: 外呼50-70%, 客服30-40% 延迟节省: LLM TTFT + TTS首包 ≈ 200-500ms6.6 通信协议深度对比
四种协议全面对比
| 传输层 | ||||
| 设计用途 | ||||
| 丢包处理 | ||||
| 弱网5%丢包 | 200-500ms | 200-500ms | ||
| 内置音频栈 | ||||
| 连接迁移 | ||||
| 编解码协商 | ||||
| SFU支持 | ||||
| 浏览器支持 |
WebRTC vs WebSocket: 为什么WebSocket不适合语音AI
来源: LiveKit Blog "Why WebRTC beats WebSockets for realtime voice AI"
WebSocket的三大问题
- 队头阻塞
: TCP丢一个包→后续所有音频包排队等待重传→200ms+播放卡顿。WebRTC用UDP: 丢了就丢(人耳对20ms缺失不敏感)。 - 拥塞控制不适配
: TCP为bulk transfer设计(填满→拥塞→退避)。恢复需多个RTT。WebRTC的GCC基于单向延迟变化预检测,平滑降码率。 - 缺少音频处理栈
: WebRTC内置AEC+AGC+NS+Jitter Buffer。WebSocket: 全需自建, "这是多年的工程工作量"。
WebSocket仍然适合: ASR文本结果传输(非音频)、控制信令、批量转写上传、Demo/原型。
QUIC对语音AI的潜力
| 连接迁移 | ||
| 0-RTT恢复 | ||
预测: 2027年LiveKit/Pipecat可能原生支持QUIC。App端可先行用QUIC做控制通道+备用音频通道。
推荐混合协议架构
客户端 ←── WebRTC ──→ LiveKit SFU ←── 内部gRPC ──→ Agent Server │ ┌─────┴─────┐ gRPC Streaming WebSocket/SSE │ │ ASR/TTS Server LLM Server 为什么这样: - 客户端↔SFU: WebRTC (弱网resilient, 内置音频栈) - SFU↔Agent: 内部网络, gRPC足够 - Agent↔ASR/TTS: gRPC streaming (双向流, 强类型) - Agent↔LLM: WebSocket/SSE (LLM API标准)
6.7 对话状态机与SOP控制
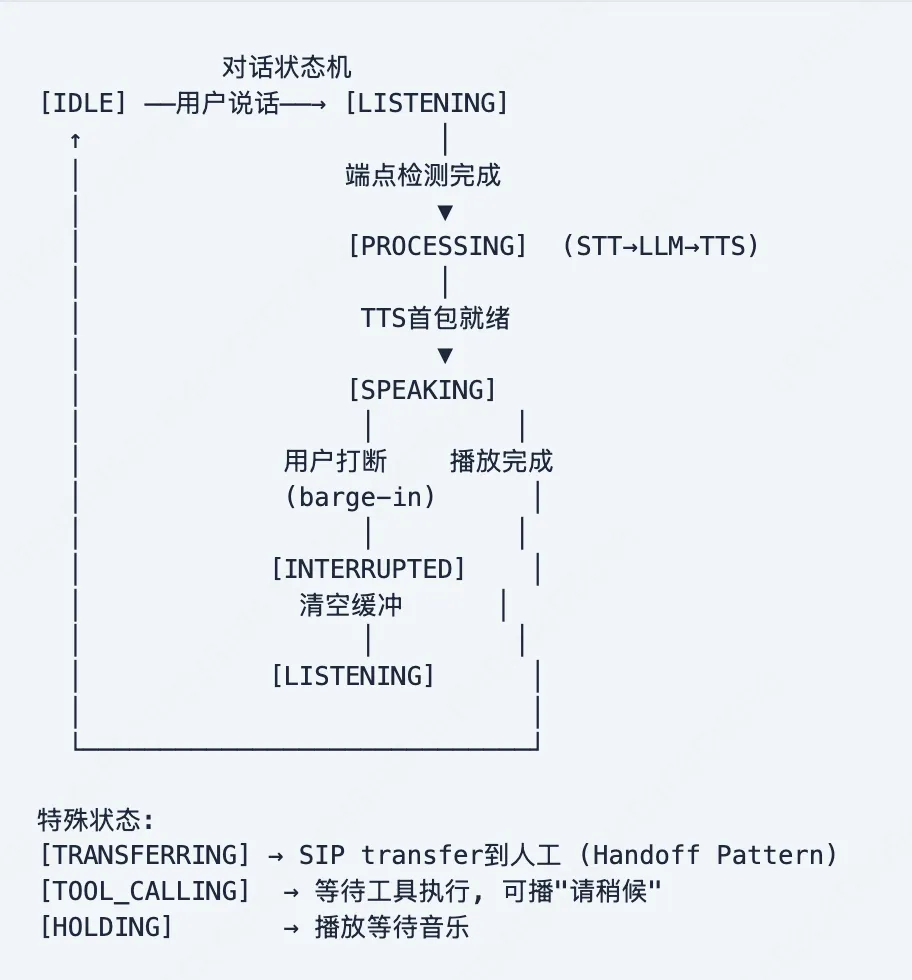
Handoff Pattern (替代IVR菜单)
来源: LiveKit Blog "The Handoff Pattern for Voice Agents That Replaces IVR Menus"
轻量Triage Agent自然语言识别意图→路由到专业Agent或人工 上下文传递: 意图+实体+历史转写+情绪状态→无缝切换 支持: AI→AI、AI→人工、人工→AI 双向Handoff 关键: 转接时播放承接语避免沉默("正在为您转接...")
平台选型建议
推荐: 使用LiveKit Agents作为框架,自研ASR/TTS通过Plugin接口接入。
第七章 端到端延迟工程
7.1 全链路延迟模型

延迟预算总表
| 端点检测 ★ | 200-800ms | 100ms | 700ms | 语义端点(ROI最高) |
各场景延迟预算分配
| 外呼营销 | ||||
| 外勤语音 | ||||
| 智能客服 | ||||
7.2 Pipeline并行化
串行 Pipeline (传统): 端点 ──→ STT final ──→ LLM ──→ TTS ──→ 播放 800ms 200ms 400ms 300ms 总计: ~1700ms流式 Pipeline (推荐): 端点(语义200ms) → STT partial已在流式输出 → LLM开始生成(不等STT final) → TTS流式合成(不等LLM完成) → 播放(不等TTS完成) 有效延迟 ≈ max(各阶段) + 少量overlap 总计: ~500-700ms推测执行 (激进): STT partial → 语义端点(100ms) → 推测LLM开始 → 推测TTS → STT final确认 → 验证推测 → 命中: 已在播放, 有效延迟~300ms → 未命中: 取消重来7.3 延迟优化实施优先级
第八章 弱网语音工程
8.1 Opus编解码弱网详解
Opus三种模式
| SILK | |||||
Opus FEC工作机制 (RFC 6716 §2.1.7)
Opus In-band FEC: 帧N的包 = [帧N主数据(正常码率)] + [帧N-1的FEC副本(~60-70%码率)] → 带宽增加约30-40% 丢包恢复: 包序列: [P1] [P2] [❌P3丢失] [P4] [P5] │ P4包含P3的FEC副本 → 从P4提取P3近似音频 恢复质量约原始70-80% 限制: 只能恢复相邻单帧丢包。连续丢包需RED(RFC 2198)补充。API配置: opus_encoder_ctl(enc, OPUS_SET_INBAND_FEC(1)); opus_encoder_ctl(enc, OPUS_SET_PACKET_LOSS_PERC(10)); // 预期10%丢包帧大小对延迟和弱网的影响
| 10ms | 100 | 10ms | 低 | 中 | 正常网络推荐 |
| 20ms | 50 | 20ms | 中 | 高 | 弱网推荐 |
自适应Opus配置策略
def adapt_opus(loss_rate): if loss_rate < 0.02: # 正常 set_bitrate(32000); set_fec(False); set_frame(10) elif loss_rate < 0.05: # 轻度弱网 set_bitrate(24000); set_fec(True, 5); set_frame(10) elif loss_rate < 0.10: # 中度弱网 set_bitrate(16000); set_fec(True, 10); set_frame(20) elif loss_rate < 0.20: # 严重弱网 set_bitrate(12000); set_fec(True, 20); set_frame(20) else: # 极端弱网 set_bitrate(8000); set_fec(True, 20); set_frame(20) enable_dtx() # 静音时不发包节省带宽丢包率对MOS的影响
8.2 QUIC连接迁移与0-RTT
WiFi→4G切换对比
WebRTC处理WiFi→4G切换: t=0s: WiFi正常, IP=192.168.1.100 t=0.1s: WiFi断开 t=0.3s: 4G上线, IP=10.0.0.50 t=0.5s: ICE检测连接丢失 t=0.8s: ICE gather新候选 t=1.2s: ICE connectivity check t=1.5s: DTLS重协商 t=1.8s: 恢复音频 → 总断连: 1-3秒 (明显音频中断)QUIC处理WiFi→4G切换: t=0s: WiFi正常, Connection ID=ABC123 t=0.1s: WiFi断开 t=0.3s: 4G上线, IP变了 t=0.35s: QUIC: IP变了但Connection ID不变 t=0.4s: PATH_CHALLENGE/RESPONSE t=0.5s: 恢复数据 (无需重新握手) → 总断连: ~200ms (用户几乎无感)电梯场景: 0-RTT恢复
WebRTC: 出电梯→Full ICE restart→DTLS握手→恢复 = 2-5秒QUIC: 出电梯→发送0-RTT包(使用之前TLS密钥)→立即恢复 = 50-100ms2026年可行的混合方案
Web端: WebRTC (浏览器原生)App端: WebRTC(主链路) + QUIC(控制通道+备用) - 正常: WebRTC传输音频 - WiFi切换: QUIC保持控制通道(零断连) - WebRTC ICE restart完成后切回 - 效果: 控制通道零断连, 音频断连从1-3s降到~200ms8.3 分场景弱网策略矩阵
| 家庭WiFi | ||||
| 商场WiFi | ||||
| 电梯 | ||||
| WiFi→4G | ||||
| 弱4G | ||||
| 地铁/高铁 |
MOS质量监控 (E-model ITU-T G.107)
R = 93.4 - Id(延迟损伤) - Ie_eff(编解码+丢包损伤) + A(用户期望补偿)MOS = 1 + 0.035R + R(R-60)(100-R) × 7 × 10^(-6)示例: 正常WiFi: R = 93.4 - 0 - 5 + 10 = 98.4 → MOS ≈ 4.5 5%丢包+Opus FEC: R = 93.4 - 0 - 12 + 10 = 91.4 → MOS ≈ 4.4 10%丢包+Opus FEC: R = 93.4 - 0 - 25 + 10 = 78.4 → MOS ≈ 3.8 弱网+200ms延迟: R = 93.4 - 4 - 20 + 10 = 79.4 → MOS ≈ 3.9实时监控指标: 丢包率(RTCP RR) > 5% → 开启高FEC RTT(RTCP) > 200ms → 切换就近节点 MOS估算 < 3.5 → 通知用户/降级第九章 场景落地方案
9.1 智能客服(呼入)
场景特点
| 延迟 | ||
| 准确率 | ||
| 打断 | ||
| SOP | ||
| 转人工 | ||
| 弱网 | ||
| 多轮 |
客服对话流程

关键配置
9.2 智能外呼
场景特点
| 延迟 | ||
| SOP控制 | ||
| 打断 | ||
| 并发 | ||
| 挂断检测 |
外呼延迟优化策略
| 热门回复预缓存 | |||
| 首句承接语 | |||
9.3 AI面试
场景特点
| 延迟 | ||
| 准确率 | ||
| 长文本 | ||
| 打断 | ||
| 记录 | ||
| 多人 |
面试场景特殊处理
- 长静默处理
: 候选人思考时间可能>5s,不应误判为说完。解决:面试模式下将silence timeout提高到5-8s - 追问策略
: 候选人回答不充分时自动追问,需语义完整度判断 - 评分维度
: 内容质量、表达能力、逻辑性、专业度 → 离线LLM多维评分 - 公平性
: 相同问题相同评分标准,LLM prompt需严格控制
9.4 外勤/司机语音交互
场景特点
| 环境噪声 | ||
| 网络 | ||
| 交互模式 | ||
| 免提/蓝牙 | ||
| 方言 |
外勤场景弱网策略
外勤App语音交互: 默认配置: - Opus: 12kbps, SILK模式, FEC ON(10%), 20ms帧 - 传输: WebRTC + ICE restart - DTX: 启用(用户听回复时不发送) 地铁/隧道: - 检测断连 → 暂停语音 → 显示文字提示 - 出隧道 → ICE restart → 语音"信号恢复" - 对话状态保持在服务端,不丢失 高速移动: - 基站切换频繁 → 启用NACK+高FEC - 码率自适应: 根据带宽估计动态调整 2027+ 考虑: - 双链路(WiFi+4G同时保持) - QUIC连接迁移(基站切换~0s断连)9.5 场景对比矩阵
第十章 辅助技术与合规
10.1 说话人分离(Speaker Diarization)
| 在线分离(TS-VAD) |
典型场景应用: 客服/外呼场景为双人对话(Agent+用户),天然知道Agent侧音频,只需分离用户侧是否有多人说话(如旁边人插话)。AI面试场景需要面试官+候选人的完整分离。
10.2 语种识别与多语言
10.3 情绪识别
检测用户情绪(愤怒/焦急/不满)对客服场景有重要价值:
- 实时检测
: 音频特征(音高升高+语速加快+音量增大) → 简单分类器 → 30ms内出结果 - 应用
: 检测到愤怒→优先转人工;检测到焦急→加快回复速度;检测到不满→调整话术更安抚 - GenSEC挑战
: Yang+ 2024 (arXiv 2409.09785) 定义了post-ASR情感分析标准任务
10.4 合规与安全
录音告知合规
内容安全
LLM输出安全管线: LLM生成文本 → 内容安全过滤 → TTS合成 过滤规则: 1. 关键词黑名单 (政治/暴力/色情) 2. 意图偏离检测 (是否偏离SOP主题) 3. 承诺检测 (是否做了不当承诺) 4. 个人信息泄露检测 (是否泄露其他用户信息) 触发后: - 轻微偏离 → 自动修正,继续对话 - 严重违规 → 立即转人工第十一章 前瞻分析
11.1 E2E Speech-to-Speech:Gate-Based评估
E2E S2S不是"时间问题",而是"条件问题"
v2报告预测"2028年E2E可用",但这不是一个时间预测问题,而是一组技术条件是否满足的问题。以下列出8个必须全部通过的技术门控。
8个技术Gate (2026年3月评估)
| 未通过 | ||||
| 未通过 | ||||
| 通过 | ||||
| 接近 | ||||
| 未通过 | ||||
| 部分 | ||||
| 未通过 | ||||
| 未通过 |
结论: 8个Gate中仅G3通过,G4/G6接近。最核心的G5(SOP可控)和G7(合规审计)不是训练更多数据就能解决的,需要架构层面的创新。保守预测: 2027年H2可能在受限场景(确认/取消)试点E2E, 2028+才可能在非SOP场景部分使用。
Hybrid过渡方案 (2027+)
Hybrid方案: Pipeline为主 + E2E辅助
阶段1 (2027H1): Pipeline + E2E Turn Detection - 用E2E模型做端点检测(替代VAD) - Pipeline其余流程不变 - 低风险, 收益: 端点检测精度提升
阶段2 (2027H2): Pipeline + E2E简单场景 - 简单确认场景(是/否/好的/取消)走E2E - 复杂场景仍走Pipeline - 中风险, 收益: 确认场景延迟降至~300ms
阶段3 (2028+): 按Gate通过情况逐步扩展 - G5通过 → 允许E2E处理更多场景 - G7通过 → 允许E2E处理合规相关场景 - G8通过 → 允许E2E处理热词相关场景
11.2 多模态语音Agent
Qwen3.5多模态 (2026+)
- 原生多模态Agent
: 文本+语音+图像+视频统一处理 - 对话场景价值
: 用户发送图片(如损坏的商品)→ Agent同时"看到"图片和"听到"描述 → 更准确的判断 - 技术难点
: 多模态推理延迟高(>1s),不适合实时first-pass,但适合离线理解和纠错
Speech-LLM发展方向
11.3 2026-2028技术趋势
| QUIC/WebTransport成熟 | |||
| LLM推理成本下降10x | |||
| 端侧LLM(手机/端侧) | |||
| 多模态Agent标准化 | |||
| 语音克隆法规 | |||
| E2E S2S中文可用 |
11.4 团队技术影响力方向
高价值技术贡献方向
以下方向兼具业务价值和技术前沿性,适合中小规模语音工程团队建设影响力。
| 跨模型热词挖掘系统 | ||||
| 语义端点检测(中文) | ||||
| 百万级POI热词工程 | ||||