


吞吐量(Throughput, tokens/s): 每秒生成的Token数。吞吐量直接决定了系统的产出效率——在批量内容生成、数据标注等场景中,吞吐量的差异意味着同样的任务量,完成时间可能相差数倍。
延迟(Latency): 从请求发出到获得完整响应的时间。在实时交互场景(智能客服、AI辅助写作、实时对话)中,延迟是用户体验的直接决定因素。研究表明,当AI回复延迟超过3秒时,用户满意度会显著下降;超过5秒时,部分用户会直接放弃等待。
稳定性(Consistency): 性能表现在时间维度上的一致性。一个服务商可能在某一时刻跑出极高的吞吐量,但如果这个数据无法持续——时快时慢、峰谷差距大——对于需要7x24小时稳定运行的生产环境来说,其实际价值大打折扣。
单次快照:2026年3月31日22:00
近7日均值:2026年3月25日06:00至4月1日06:00
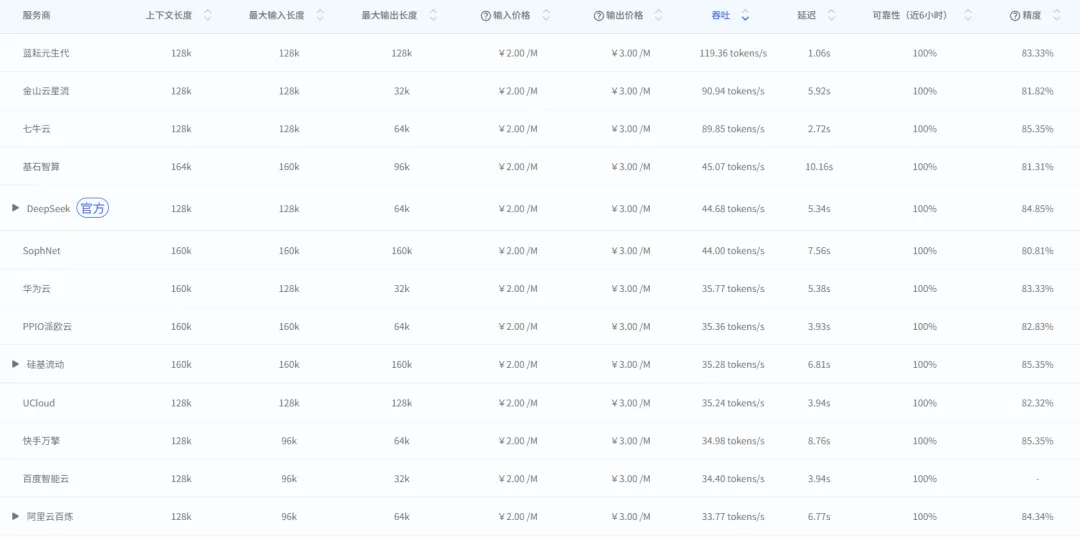
延迟维度:蓝耘1.14秒,比第二名快近3倍。 AI Ping收录的20+服务商中,蓝耘的延迟是唯一低于2秒的。第二低延迟为火山方舟的3.40秒,蓝耘比其快约3倍。与延迟最高的基石智算(9.52秒)相比,差距超过8倍——而两者的Token标准定价完全一致。对于智能客服、AI辅助写作、实时对话等交互式应用,这个差距直接决定了用户体验。1秒响应与5秒响应、10秒响应,是完全不同量级的产品体验。 吞吐量维度:蓝耘85.47 tokens/s,单次快照排名第三。 在单次测试中,金山云星流以116.43 tokens/s排名第一,七牛云89.69 tokens/s排第二,蓝耘85.47 tokens/s位列第三。但这只是某一时刻的快照——真实的生产能力,还需要看持续表现。 最大输出长度:蓝耘128k,位居前列。 在6家非DeepSeek官方的服务商中,蓝耘的128k最大输出长度仅次于硅基流动的160k,远超金山云星流和火山方舟的32k。对于需要生成长文档、完整代码文件或翻译长篇内容的场景,这个参数至关重要。
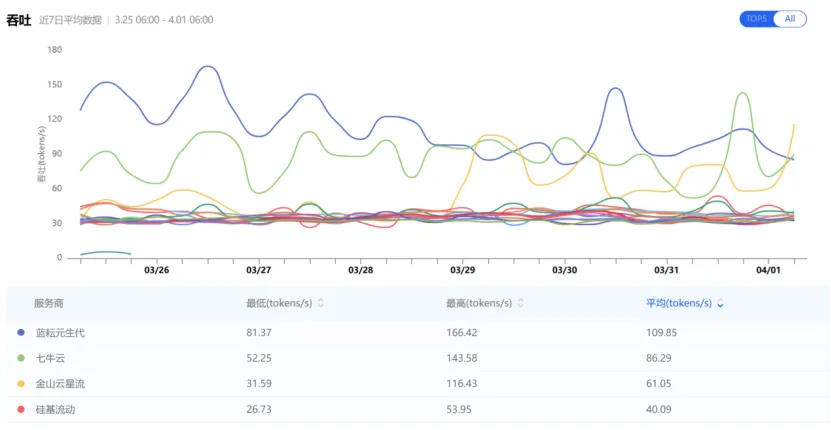
7日平均吞吐量排名与单次快照完全不同。 金山云星流在单次快照中以116.43 tokens/s排名第一,但7日平均仅61.05 tokens/s,跌至第三。蓝耘在单次快照中排第三(85.47 tokens/s),但7日平均以109.85 tokens/s反超所有对手,稳居第一。 蓝耘的"下限"高于多数平台的"平均值"。 蓝耘近7日最低值为81.37 tokens/s,这个数字高于金山云星流的7日平均值(61.05 tokens/s),也高于硅基流动的7日最高值(53.95 tokens/s)。换句话说,蓝耘表现最差的时刻,依然优于很多平台的正常水平。 金山云星流的波动幅度提示可能存在资源调度问题。 其7日最低值(31.59 tokens/s)仅为最高值(116.43 tokens/s)的27%,峰谷差达到3.7倍。这种剧烈波动意味着企业实际使用中可能遇到"有时很快、有时很慢"的体验——对需要稳定产出的生产环境是一个隐患。 对企业而言,"持续稳定的高性能"远比"偶尔的峰值"更有价值。 生产环境需要的是可预期、可依赖的服务质量,而不是开盲盒。
延迟最低(1.14s)——适合所有对实时性有要求的交互式应用
7日平均吞吐量最高(109.85 tokens/s)——适合大规模批量处理任务
7日性能下限最高(81.37 tokens/s)——适合对稳定性要求严格的生产环境
最大输出长度128k——适合长文本生成场景
资源不超卖。 第三方转租模式下,供应商可能将同一块GPU的算力超额分配给多个客户,导致高峰时段性能下降。自有集群可以精确控制资源分配,确保每个推理请求获得充足的计算资源。
调度链路更短。 从API网关到GPU执行,中间不经过第三方中转,减少了网络跳转和协议转换带来的额外延迟。这是蓝耘延迟能做到1.14秒的基础条件之一。
运维响应更快。 硬件故障时,自有运维团队可以直接介入处理,而非等待上游供应商响应。这也是蓝耘能维持高可靠性的重要因素。
请求调度策略: 基于优先级的动态批处理(Dynamic Batching)机制,根据请求的输入长度和预估输出长度自动组批,在保证延迟SLA的前提下最大化GPU利用率.
KV Cache管理: 采用分页式KV Cache管理(PagedAttention),有效减少显存碎片,使单卡可同时服务更多并发请求.
推理框架: 基于Vllm/SGLang自研优化.
共享API层: 适合业务初期或流量波动较大的场景,按实际调用量付费,无需预留资源
专属资源池: 适合业务量稳定且对性能有严格要求的场景,独享GPU资源,不受其他租户影响
平滑迁移路径: 企业可以从共享API起步,业务增长后无缝迁移至专属资源池,API接口保持不变,无需改造业务代码
场景 | 核心需求 | 蓝耘的适配性 |
智能客服/在线对话 | 低延迟(<2s) | 延迟1.14s,20+服务商中最低 |
实时内容生成(AI写作辅助) | 低延迟 + 中高吞吐 | 延迟1.14s + 7日均值109.85 tokens/s |
批量内容生成/数据标注 | 高吞吐量 + 稳定性 | 7日均值吞吐量第一,下限81.37 tokens/s |
长文档处理(报告/翻译/代码) | 大输出长度 + 高吞吐 | 最大输出128k |
高峰期弹性场景(电商大促) | 弹性扩容 + 低延迟 | 自有集群支持共享→专属平滑迁移 |
通用推理: DeepSeek-V3.2、Qwen3-235B等
对话与生成: GLM-5、GLM-4.7、MiniMax-M2.5等
输入:¥2.00 / 百万Token
输出:¥3.00 / 百万Token
新用户申请可赠500万免费Token体验额度,可完成业务适配测试
批量推理5折、缓存命中价格降低80%以上
年度框架协议客户可获得定制化报价
注册与兼容性测试(1-3天): 在 lanyun.net 注册账号,使用500万免费Token进行业务适配测试。API接口兼容OpenAI格式,大多数现有代码只需修改base_url和API Key即可接入 压力测试(3-5天): 用真实业务流量进行为期一周的并行测试,重点观察高峰时段的延迟和吞吐量表现。建议同时测试2-3家服务商进行横向对比 生产部署: 根据测试结果确认方案,签署服务协议后正式上线 按需升级: 业务量增长后,可随时从共享API迁移至专属GPU资源池,API接口不变,业务代码无需改造
指标 | 蓝耘实测数据 | 行业对比 |
延迟 | 1.14s | 20+服务商中最低,比第二名快近3倍 |
7日平均吞吐量 | 109.85 tokens/s | 持续监测排名第一 |
7日最低吞吐量 | 81.37 tokens/s | 高于多数平台的平均值 |
可靠性 | 100% | 测试期间零故障 |
最大输出长度 | 128k | 位居行业前列 |






蓝耘科技集团股份有限公司成立于2004年,是国家高新技术企业、国家级专精特新“小巨人”企业,专注于构建面向人工智能时代的算力基础设施与全栈服务能力。公司以自主研发的 “元生代MetaGen” 智能算力操作系统(AIDC-OS)为核心技术生态,深度融合多元异构算力底座与算力调度平台、AI模型训推平台、MaaS服务平台、AI数据生成平台等全栈自研产品矩阵,打造 “算力工厂 + 数据工厂 + 模型工厂” 三位一体的赋能体系,为千行百业提供从底层算力支撑到AI应用落地的全栈式赋能。
元生代MetaGen智能算力操作系统(AIDC-OS)是蓝耘技术生态的底层架构与核心引擎,通过整合高性能GPU算力调度、容器化资源管理、混合云架构协同等能力,构建智能化、弹性化的算力操作系统。其核心价值在于打通算力、数据、模型AI三大核心生产要素的协同闭环,实现从基础设施到行业场景的全链路技术赋能








