


第一章 计算物理学的范式转移:从电子到光子的底层逻辑
1.1 硅基半导体的物理极限界定与算力危机
在全球人工智能(AI)模型参数量呈指数级增长的背景下,基于传统硅基互补金属氧化物半导体(CMOS)工艺的电子计算架构正面临严峻的物理极限。摩尔定律的放缓与登纳德缩放定律(Dennard Scaling)的失效,导致算力增长的边际成本急剧上升。数据表明,至2030年,全球AI工作负载产生的数据中心算力需求将激增至156吉瓦(GW),其能耗规模构成了不可持续的物理与经济屏障。电子计算的核心瓶颈不仅在于晶体管尺寸逼近原子极限,更在于冯·诺依曼架构下的“内存墙”与“功耗墙”效应。在深度学习训练和推理任务中,频繁的数据搬运导致严重的电阻-电容(RC)延迟,系统绝大部分的能量并未消耗在算术逻辑单元(ALU)的计算上,而是消耗在数据从高带宽内存(HBM)到处理器的物理位移过程中。
1.2 玻色子与费米子的物理特性解析及光计算的理论优势
光计算(Optical Computing或Photonic Computing)的物理基础在于利用光子(Photon)替代电子作为信息载体与运算单元。从量子统计物理学的角度来看,电子作为费米子,带有电荷且具有静止质量。电子在半导体晶格中传输时,不可避免地会与硅原子和金属原子发生声子散射,这种散射不仅极大地限制了电子的漂移速度,还会导致晶格振动并产生大量焦耳热。这种固有的物理特性决定了电子芯片在提升时钟频率时必然伴随非线性的热耗散激增,进而需要庞大的液冷或风冷系统来维持芯片稳定性。
相反,光子作为玻色子,静止质量为零且不带电荷,能够在介电介质中以光速传输而几乎不产生热耗散。更为关键的是,光子不遵循泡利不相容原理,不同波长、偏振态和空间模式的光波可以在同一介质中独立传播而互不干扰。这种特性为光计算提供了天然的多维并行处理能力,使得系统能够利用波分复用(WDM)、空分复用(SDM)和模式复用(MDM)技术,在不提升物理时钟频率的前提下,实现算力的指数级增长。
下表系统性地对比了电子计算与光计算在核心物理维度的差异:
物理特性维度 | 电子计算 (Electronic Computing) | 光计算 (Photonic Computing) |
基础信息载体 | 电子(费米子,带负电荷,具静止质量) | 光子(玻色子,无电荷,无静止质量) |
极限传输速度 | 较低(受限于RC延迟、寄生电容与电子迁移率) | 极高(介质中的光速,无RC延迟限制) |
热耗散机制 | 高(电子与晶格散射引发强烈热耗散) | 极低(光子在透明介质中传输几乎无热效应) |
信道并行度 | 极低(基于时间序列的电脉冲,单线单信号) | 极高(支持波长、偏振、相位、空间模式复用) |
环境抗干扰性 | 易受电磁干扰 (EMI) 影响,密集线路存在串扰 | 完全免疫电磁干扰,光束空间交叉无串扰 |
计算能效比 | 随频率提升呈非线性衰减(受制于晶体管开关功耗) | 极高(乘加运算通常为被动干涉或衍射物理过程) |
1.3 光电混合计算架构的必然性与分工机制
尽管光子在数据传输和线性代数运算中表现出绝对优势,但当前的产业共识并非利用光子完全替代电子,而是走向“光电混合计算”(Hybrid Compute)范式。这一选择的物理根源在于光子之间缺乏直接的强相互作用,导致实现全光非线性逻辑控制异常困难且成本高昂。在光电混合架构中,系统遵循明确的功能分工:复杂的控制流、高精度的存储调用以及非线性激活由电子电路(如CMOS控制器)负责;而消耗系统绝大部分算力的线性代数任务(如张量矩阵乘法、卷积网络特征提取、快速傅里叶变换)则自然映射到光域中执行。这种架构最大限度地发挥了光波干涉和衍射的并行吞吐优势,同时绕过了全光数字计算机在逻辑门联级(Cascadability)和扇出(Fan-out)能力上的物理限制。
第二章 集成光子神经网络(IPNNs)的核心硬件架构
集成光子神经网络(Integrated Photonic Neural Networks, IPNNs)是目前解决传统计算三重瓶颈(带宽不足、功耗过高、数据搬移缓慢)的核心硬件路径。通过将光学元件密集集成于芯片之上,IPNN能够将人工智能的推理过程转化为以光速进行、低功耗的物理传播过程。
2.1 光突触的设计原理与权重存储机制
在人工神经网络中,突触负责存储和施加网络权重。在光域内,光突触主要通过调制光信号的相位或振幅来实现矩阵-向量乘法(MVM)。目前主流的光突触元器件包括微环谐振器(MRR)和马赫-曾德尔干涉仪(MZI)。微环谐振器利用光的谐振特性,对特定波长具有极强的敏感性,因而在面积占用和能效方面极具优势,尤其适用于波分复用(WDM)架构中的权重加载。然而,MRR对温度波动极为敏感,需要精密的反馈控制系统维持其谐振状态。相比之下,马赫-曾德尔干涉仪通过热光或电光效应调节干涉臂之间的相位差来改变输出光强。由MZI组成的网格(MZI Meshes)被广泛应用于相干光网络中,能够通过奇异值分解(SVD)精确地映射任意酉矩阵,为光神经网络提供了极高的数学严谨性与计算精度。
为解决MRR和MZI在维持权重时产生的静态功耗问题,学术界与工业界正在引入非易失性相变材料(Phase-Change Materials, PCMs)。硫族化物合金(如Ge2Sb2Te5或Ge2Sb2Se4Te1)能够在晶态与非晶态之间快速切换,两种状态具有截然不同的折射率与吸收系数。将PCM集成在光波导上,可以在不消耗任何静态电能的情况下持久保持设定的光学权重,这对于构建极低功耗的大规模并行光计算阵列具有决定性意义。
2.2 光神经元与光忆阻器的功能实现
神经网络的表达能力依赖于神经元的非线性激活函数。在光计算中,由于光子呈现玻色子特性,线性叠加是其基本行为。要实现光神经元,必须引入非线性光学效应。传统的混合方案是通过光电探测器将光信号转化为电信号,在电域中执行非线性激活(如ReLU或Sigmoid函数),然后再调制回光信号,但这种OEO转换会严重削弱光计算的速度与能效优势。因此,当前的前沿研究高度聚焦于全光非线性激活方案,利用半导体光放大器(SOA)的增益饱和效应,或者二维材料(如石墨烯、过渡金属硫化物)在强光场下的非线性吸收和折射率变化,直接在光域完成激活操作,从而确保系统的端到端超低延迟。
除了光神经元,光忆阻器(Photonic Memristors)也是构建复杂动态网络的关键组件。光忆阻器根据其物理记忆弛豫时间的长短,可分为非易失性与易失性两类。非易失性光忆阻器主要用于深度学习架构中的长期权重固化;而易失性光忆阻器则由于其具有类似生物突触的短期记忆特性,被广泛应用于处理快速时序信号的储池计算(Reservoir Computing)和脉冲神经网络(SNN)中。
2.3 IPNN的四种主流拓扑架构
依据信号的传播与干涉方式,集成光子神经网络衍生出四种极具代表性的硬件架构,各自适配不同的人工智能工作负载。相干光网络(Coherent Networks)以MZI网格为核心,通过精确的相位控制实现矩阵相乘,其严格的数学同构性使其非常适合执行多层感知机(MLP)并支持片上训练。并行化光网络(Parallelized IPNNs)则深度利用波长或空间多路复用技术,在极小的硬件足迹内实现超高吞吐量的卷积运算,是计算机视觉预训练的理想选择。集成衍射网络(Integrated Diffractive Networks)摒弃了传统的波导路由,通过在自由空间或平板波导中设计多层相位掩膜,使光波在自然衍射中完成特征提取,提供极限的超低延迟推理能力。最后,储池计算(Reservoir Computing)利用光学微腔或延迟光纤环构建复杂的动态非线性节点网络,极大地降低了训练复杂度,在光纤通信信号恢复与时间序列预测中展现出巨大的商业潜力。
第三章 核心非线性光学材料的物理演进与优劣势评估
硅基光子学(Silicon Photonics)凭借庞大的CMOS代工基础设施,成功推动了光互连(Optical Interconnects)的商业化。然而,标准硅材料存在间接带隙,无法作为高效的有源发光器件,且其中心对称的晶格结构导致其二阶非线性光学系数(Pockels效应)近乎为零,三阶非线性效应也相对较弱。为满足光计算对超高速调制与极低能耗非线性的苛刻要求,产业界正加速向异质集成(Heterogeneous Integration)方向演变。
3.1 非线性光学材料的基准对比
下表综合梳理了目前光计算领域主流与前沿光学材料的物理性能与产业化状态:
材料平台 | 核心物理优势与光学性能 | 在光计算系统中的核心功能定位 | 产业化挑战与良率瓶颈 |
薄膜铌酸锂 (TFLN) | 高二阶非线性 ( | 执行极高带宽的电光调制,构建低功耗光学张量核心,支持光学量子计算 | 晶圆尺寸受限,干法刻蚀难度极高导致侧壁粗糙度难以控制,缺乏标准化PDK |
钛酸钡 (BTO) | 极化率和电光系数显著优于铌酸锂,相变温度高达700°C,热稳定性优异 | 提供超高密度的片上集成电光器件,减小调制器体积与驱动电压 | 与硅晶圆的晶格失配问题导致外延生长缺陷,大尺寸异质集成良率偏低 |
富硅氮化硅 (USRN) | 三阶非线性折射率比化学计量氮化硅高100倍,有效抑制通信波段的双光子吸收 | 实现完全无双光子吸收的全光信号处理、光参量放大及光逻辑门 | 薄膜应力引发的机械脆弱性,高非线性伴随的热光效应干扰,难以与有源光源单片集成 |
二维材料 (2D Materials) | 原子级厚度,强激子极化子耦合,光电特性高度可调,支持超快宽带响应 | 贴附于波导表面实现紧凑型全光非线性激活函数,构建饱和吸收体与调制器 | 大面积均匀转移技术缺乏,晶圆级缺陷控制困难,器件性能重复性与一致性极差 |
硫族化物玻璃 (Chalcogenide) | 覆盖宽泛的红外透明窗口,具备光致折射率可调性,高非线性折射率 | 用于非易失性光突触权重存储,实现零静态功耗计算,中红外超连续谱生成 | 材料热导率低导致热串扰,光致暗化效应影响长期可靠性,刻蚀与后道工艺兼容性差 |
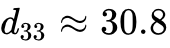
3.2 商业化焦点的转移:薄膜铌酸锂与钛酸钡
在众多新兴材料中,薄膜铌酸锂(TFLN)已处于商业化的前沿阵地。传统体块铌酸锂由于波导折射率对比度低,导致光场约束能力差、器件体积庞大且驱动电压极高。TFLN技术通过将数百纳米厚的铌酸锂薄膜键合在绝缘层(二氧化硅)上,形成高折射率差的波导结构,大幅增强了光场与射频电场的重叠积分。这一物理结构的改变,使得TFLN调制器的半波电压-长度积(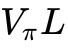 )显著降低,从而在极低的功耗下实现超过100 GHz的超高带宽。为解决TFLN难以刻蚀的问题,离子束刻蚀(Ion Beam Etching)等先进修膜技术的引入有效降低了波导侧壁粗糙度,使得TFLN芯片在数据中心相干光通信与光计算微环阵列中实现了量产。
)显著降低,从而在极低的功耗下实现超过100 GHz的超高带宽。为解决TFLN难以刻蚀的问题,离子束刻蚀(Ion Beam Etching)等先进修膜技术的引入有效降低了波导侧壁粗糙度,使得TFLN芯片在数据中心相干光通信与光计算微环阵列中实现了量产。
与此同时,钛酸钡(BTO)因其更为惊人的电光系数,被视为硅光子集成的下一代候选者。BTO能够在更短的物理长度下实现等效的相位调制,这对于极其看重硅片面积(Real Estate)的集成光计算芯片而言具有巨大的吸引力。此外,BTO的高相变温度()使其在复杂的制造热工艺中表现出极佳的稳定性,从而能够通过外延工艺直接或间接地集成到标准硅光子晶圆上。
第四章 系统级工程瓶颈与突破性解决方案
尽管底层物理机制与材料科学描绘了光计算的宏伟蓝图,但在系统级工程实现中,光计算必须跨越衍射极限、光电转换损耗以及模拟噪声累积这三大硬核技术瓶颈。2025至2026年间的学术突破与工业实践,为这些瓶颈提供了结构性的解决路径。
4.1 突破阿贝衍射极限:纳米光子学与空间结构工程
光学系统面临的物理定律限制在于阿贝衍射极限(Abbe's Diffraction Limit),即光波在自由空间或传统介质中无法被聚焦到小于其半波长(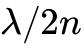 )的尺度。对于通信常用的1310 nm或1550 nm频段,这意味着传统光学元器件的物理尺寸在微米级别,比当前几纳米的电子晶体管大了近三个数量级,从根本上制约了光计算芯片的算力密度上限。
)的尺度。对于通信常用的1310 nm或1550 nm频段,这意味着传统光学元器件的物理尺寸在微米级别,比当前几纳米的电子晶体管大了近三个数量级,从根本上制约了光计算芯片的算力密度上限。
为打破这一空间屏障,研究人员深度整合了纳米光子学(Nanophotonics)与超构表面(Metasurfaces)技术。通过设计特定的亚波长纳米天线阵列,利用表面等离激元共振或米氏谐振(Mie resonances),光场可以在深亚波长尺度内被强烈局域化。例如,利用二硒化钼(MoSe2)构建的亚波长光栅,能够成功将红外光限制在仅40纳米厚的介质层中,实现了高度的空间压缩。此外,自动化逆向设计框架(Inverse Design)结合深度神经网络(DNN)与贝叶斯优化,能够精准剪裁非局部超构表面的光学传递函数(OTF)。研究人员据此在1250-1350 nm波段制造出基于硅空心砖结构的超构器件,在数值孔径达到0.4的条件下,直接在光域完成二维高阶微分与高通滤波计算。这种在深亚波长维度操作空间频率的技术,彻底颠覆了传统透镜系统的尺寸限制。
4.2 消除OEO转换能耗陷阱:单片光电计算转换器
光电混合计算网络在层与层之间通常需要进行非线性激活或信号重塑。传统流程依赖于完整的光-电-光(OEO)转换:通过光电探测器(PD)将光子转化为微弱电流,利用跨阻放大器(TIA)进行电压放大并进行数字逻辑处理,最后再驱动电光调制器(EOM)将信号重新印刻到光载波上。这一过程不仅引入了巨大的RC延迟,而且消耗了系统总能耗的30%以上,直接抵消了光计算在传输过程中的能效红利。
解决这一痛点的最新方案是采用无TIA的单片集成硅光子OEO转换器。研究表明,通过在纳米尺度上实现光电探测器与微环调制器(MRM)的极端电容缩放(Capacitive scaling),可以构建负载电阻型(Load-resistor type)和电流注入型(Current-injection type)的紧凑OEO器件。这种单片器件在极低的光偏置功率下即可提供大于1的射频OEO增益,并展现出高度可重构的非线性传递函数。其眼图测试证实,在无需传统跨阻放大的情况下,该结构能够在极低延迟下实现子皮焦耳每比特(sub-pJ/bit)的高速非线性激活。这使得光学神经网络能够在芯片内实现高效的信号再生与非线性映射,避免了向主板级数字域的昂贵数据往返。
4.3 抑制模拟噪声与级联误差累积的控制策略
光计算本质上属于模拟计算体系。在包含成百上千个微环或马赫-曾德尔干涉仪的庞大光子网络中,半导体制造过程中的几何尺寸偏差、热串扰波动以及本征的光学衰减,均会不可避免地引入相位与振幅噪声。这些微小的误差在多层网络结构中会发生不可控的级联放大(Cascaded Error Accumulation),导致光信噪比(OSNR)急剧恶化,使得最终的推理结果严重偏离精确值。这是阻碍光计算大规模商用最核心的算法阻碍。
应对级联误差的控制方法在近年取得了多维度的进展:
第一,在数据编码协议层面,Lightmatter公司针对模拟计算开发了自适应块浮点(Adaptive Block Floating-Point, ABFP)格式。该算法将权重矩阵划分为若干数据块,每个块基于绝对值最大的元素提取一个共享指数(Shared Exponent)。在数模转换(DAC/ADC)阶段,硬件会根据该指数动态施加物理级的模拟增益控制(Analog Gain Control),对微弱的低阶位信号进行物理放大,并在数字后处理阶段将增益除尽。这一物理与算法融合的策略,有效抑制了量化截断引发的噪声,使得仅具备低位数模转换能力的光网络依然能输出逼近32位浮点(FP32)的高保真结果。
第二,在系统建模层面,利用引入了传播不确定性的高斯过程模型(NIGP)以及级联学习(Cascaded Learning)架构,对光纤放大器(EDFA)增益、光纤衰减和非线性串扰进行精准拟合。此方法使得多跨段长距离光学传输中的OSNR预测误差降低至0.12 dB以内,大幅优化了路由调度时的信噪比裕度。
第三,全数字光神经网络(ADONN)架构被提出,该架构尝试在计算核心的光学输入端保持数字二进制脉冲,传输与乘加运算在全光域执行。仿真与物理验证表明,在高噪声环境(OSNR为20 dB)下,该架构能够实现$3 \times 10^{-4}$的均方根误差(RMSE),等效于11位的数字计算精度,极大地缓解了对超高精度数模转换硬件的依赖。
第五章 2025-2026年全球光计算性能基准与标杆产品评估
在理论突破的支撑下,全球光计算产业在2025至2026年间迎来了原型机向商用部署跨越的爆发期。以下选取中美两地及欧洲的三个标杆性产品与研究成果,进行深度的量化基准测试(Benchmarks)分析。
5.1 SIOM:基于孤子微梳的超高并行度光计算芯片
2025年中期,中国科学院上海光学精密机械研究所(SIOM)在《eLight》期刊上发表了全球首款超高并行度光计算集成芯片的成果,标志着光计算在复用维度上的工程突破。
技术与架构机制:该芯片摒弃了传统光计算平台依赖单一工作波长的路径,创造性地引入了孤子微梳(Soliton Microcomb)光源技术。孤子微梳能够在极宽的频带内(超过40 nm)稳定生成100多个等间距、相位锁定的独立波长通道。结合新研制的超高并行光计算架构,系统利用这100多个独立波长将多路数据流同时注入光子处理网络进行特征提取与矩阵运算。 性能基准评估:在50 GHz的光学时钟频率驱动下,该芯片实现了2560 TOPS(每秒2560万亿次运算)的理论峰值算力。这种基于物理维度的扩展机制意味着,系统可以在不增加芯片物理尺寸、不提升基础时钟频率(避免热量崩盘)的情况下,将吞吐量提升两个数量级。其超低延迟和无与伦比的计算密度,为自动驾驶、无人机蜂群的具身智能(Embodied Intelligence)以及通信节点的高频量化交易提供了极具竞争力的底层硬件平台。
5.2 Lightmatter:逼近FP32精度的全集成3D光子处理器
总部位于北美的光计算独角兽Lightmatter在2025年的《Nature》主刊上详细披露了其全栈式光子处理器的架构细节,打破了业界对光计算“仅能处理简单线性任务”的刻板印象。
技术与架构机制:该系统采用了极端复杂的3D混合封装技术,在单一封装内集成了6个独立芯片。系统整体包含高达500亿个电子晶体管和100万个光学元器件。垂直排列的光学张量核心直接与高速数字控制裸片相连。为了应对外部环境与内部热量对光学干涉相位的扰动,系统配置了海量的混合信号控制电路,实时、动态地稳定所有100万个光子元件的工作状态。在数据精度上,系统全面部署了上文提及的ABFP16自适应块浮点计算格式。
性能基准评估:该处理器达到了65.5 TFLOPS的吞吐率,而电功耗仅为78 W,光功耗更低至1.6 W。最为突破性的是,该芯片可以直接运行主流AI框架(如PyTorch构建的BERT变压器模型、ResNet卷积网络以及Atari深度强化学习算法),且在不需要进行特定量化感知训练或权重微调的条件下,“开箱即用”地输出逼近标准FP32数字处理器的极高精度结果。
5.3 Q.ANT NPU 2:全面部署于HPC环境的商用协处理器
德国初创公司Q.ANT于2026年发布的NPU 2(第二代原生处理单元)是业界首款实现规模化生产并部署于国家级超级计算中心的全光协处理器。
技术与架构机制:NPU 2的核心采用了其专有的薄膜铌酸锂(TFLN)光子集成电路。与当前Nvidia GPU高度依赖内部HBM(高带宽内存)不同,Q.ANT的架构彻底剥离了片上存储的高昂功耗。该处理器通过标准的PCIe总线以协处理器(Co-processor)形式接入X86服务器,模型权重与输入数据驻留在主机的外置DDR内存中。数据被调取后,以极高效率的I/O通道送入光核心,完成纯光域的矩阵向量乘法,完全排除了片内晶体管逻辑开关导致的热耗散。
性能基准评估:在德国莱布尼茨超级计算中心(LRZ)和于利希超级计算中心(JSC)的实际生产负载(涵盖药物发现、材料科学模拟等真实非线性物理仿真任务)测试中,NPU 2表现出惊人的能效比。单个NPU设备的稳态运行功耗仅为30 W,远低于高端Nvidia加速器的700-1000 W。基准测试表明,其矩阵乘法吞吐量相比传统电子架构高出50倍,在ResNet-18视觉模型的推理速度是其自身第一代架构的25倍,整体能效相比上一代提升了6倍。
下表综合对比了三种代表性光计算架构在2026年的关键指标:
企业/机构 | 核心技术路径 | 并行/精度控制策略 | 基准算力指标 | 目标应用场景与部署状态 |
SIOM (中科院) | 孤子微梳多波长复用架构 | 100+ 波长同时处理 | 2560 TOPS (50 GHz时钟) | 具身智能、高频计算验证期 (2025发表) |
Lightmatter | 硅光异质3D封装 | ABFP16自适应浮点与模拟增益 | 65.5 TFLOPS (78 W电功耗) | 云端大模型、通用AI框架、预商用就绪 |
Q.ANT | TFLN纯光域张量核心 | PCIe协处理与片外DRAM调度 | 50x矩阵吞吐提升 (30 W功耗) | HPC非线性科学计算、物理仿真、已量产部署 |
第六章 数据中心架构的光学重构:从计算到互联
2026年的计算产业已经形成了一个明确的共识:算力扩张的痛点不仅在于处理器内核,更在于处理器之间的数据搬移网络。随着大语言模型(LLMs)训练和推理规模的激增,集群内部的东西向(East-West)通信流量呈爆炸式增长,促使数据中心架构发生物理层面的演化,主要体现在纵向扩展(Scale-up)、横向扩展(Scale-out)及跨中心扩展(Scale-across)三个维度。
6.1 共封装光学(CPO)与网络拓扑革命
在Scale-up和Scale-out场景下,维持GPU和AI加速器集群中上万个节点的高带宽和极低延迟是关键。传统的铜缆电气互连在速率达到800G乃至1.6T时,遭遇了不可逾越的趋肤效应(Skin Effect)与信噪比衰减问题,导致需要消耗极大的功率进行重定时和信号均衡。
**共封装光学(Co-Packaged Optics, CPO)**成为重塑AI工厂的决定性技术。CPO技术打破了将光模块插在交换机前面板(Pluggable Optics)的传统形态,转而将高密度光电收发器与核心计算ASIC(如GPU或交换机芯片)直接封装在同一个多芯片模块(MCM)基板上。这种深度的3D异质封装将电子信号在印刷电路板(PCB)上的传输距离从数十厘米缩短至几毫米,彻底消除了沉重的SerDes(串行器/解串器)功耗负担。基准数据显示,从传统的可插拔模块过渡到CPO架构,单比特数据传输功耗从约15 pJ/bit 断崖式下降至5 pJ/bit,并拥有向亚皮焦耳级别演进的清晰路径。行业巨头(如Nvidia的Spectrum-X、Broadcom与Coherent的深度合作)在OFC 2026上展出了海量的1.6T和3.2T CPO引擎,宣告了大规模光连接时代的全面降临。
6.2 光路交换(OCS)与无损确定性网络
在更大规模的AI算力集群中,传统的电层分组交换(Packet Switching)网络面临着严重的性能损耗。每个数据包经过交换节点时,都需要经历复杂且高功耗的“光-电-光(OEO)”转换,并在电域内进行解包、排队缓冲、路由计算后再重新封装为光信号。这一过程不仅极度耗电,且不可避免地引入了微秒至毫秒级的排队抖动(Jitter)和长尾延迟(Tail-latency),这在要求集合通信绝对同步的分布式AI训练中是致命的。
**光路交换(Optical Circuit Switching, OCS)**技术通过微机电系统(MEMS)反射镜阵列或其他空间光调制手段,直接在物理光层面上建立端到端的数据传输通道。在光路维持期间,数据流如同行驶在专用的高铁轨道上,无需在中间节点进行任何基于包的OEO转换或电缓存。这使得端到端的延迟无限趋近于光在光纤中的物理传输时间,实现了网络行为的极度确定性和零丢包率。在结合RDMA(远程直接内存访问)协议后,这种无损网络最大化了GPU在训练千亿参数模型时的同步计算效率。
第七章 光子集成电路制造、良率管理与代工生态
由于光计算和硅光子学涉及复杂的微观物理结构以及多种材料体系的结合,从实验室原型迈向数百万颗的批量生产,晶圆级制造与良率控制成为产业链中最艰难的挑战。
7.1 异质集成的工艺复杂性与封装挑战
与电子芯片在单一硅衬底上完成所有逻辑门雕刻不同,光子集成电路(PIC)往往是异质化(Heterogeneous)的。例如,需要将III-V族材料(如磷化铟InP,用于发光激光器)、铌酸锂(用于高速调制)以及锗(用于探测器)精准结合在硅波导基板上。晶圆键合(Wafer Bonding)、微转移打印(Micro-transfer Printing)和外延生长工艺在此过程中会引入热膨胀系数失配应力及晶格缺陷。
更为严峻的是光芯片的封装环节。一个完好的光子裸片需要以亚微米级的容差对准连接外部光纤阵列,并与控制电路进行共封装,同时需实现严密的气密性以防止湿度导致激光器退化。在光计算产业中,封装测试环节占据了PIC总制造成本的50%至70%,这一比例远高于传统电子芯片的后道封装成本。
7.2 良率提升策略:计算光刻与自动化逆向设计(PRISM)
在PIC的制造过程中,“良率(Yield)”是决定商业利润的生命线。光波导对侧壁粗糙度和尺寸偏差极其敏感,纳米级的制造容差漂移就会导致相位的严重偏移,致使MZI干涉仪无法完全消光,从而引起系统级的串扰与性能崩溃。
为弥合设计仿真与实际流片性能之间的巨大鸿沟,2026年的EDA(电子设计自动化)工具链引入了革命性的光学逆向光刻与优化流程。例如,**PRISM(光子感知神经逆向光刻)**框架利用基于物理学原理的可微制造模型与贝叶斯优化,自动合成紧凑的掩模校准图案。PRISM不仅仅局限于对几何形状的完美复制,更是通过光学传递函数的物理评估来进行“面向性能的掩模修正”。这种高度光学感知的自动化工作流大幅减少了流片迭代周期,使光子代工企业能够像制造硅基CMOS逻辑门一样,输出性能可预测且良率极高的高密度不规则光子器件。
7.3 全球晶圆代工厂(Foundry)的产能博弈
为了满足日益膨胀的市场需求,全球半导体代工厂正在疯狂扩充其光子工艺产能。台积电(TSMC)大力推进其COUPE(紧凑型通用光子引擎)异质集成封装平台,深度绑定Nvidia和Broadcom等大客户的下一代CPO路线图;GlobalFoundries则通过收购新加坡先进微铸造公司(AMF),进一步巩固其在全球硅光子代工市场的霸主地位。此外,Tower Semiconductor斥资6.5亿美元用于将其硅光子产线提升三倍,全面拥抱量产化的薄膜铌酸锂及异质激光器集成生态。这些数十亿美元的资本支出与产能竞赛,彻底扫清了光计算硬件从研发步入工业量产的规模化障碍。
第八章 深度研究结论与战略前瞻
结合对2026年最新技术突破、物理模型、材料学进展及商业生态的详尽分析,本研究得出以下几点核心结论:
光电计算范式的历史性跨越已然完成。光计算已彻底跨越了以实验室理论验证和被动元器件演示为主的早期阶段,以Lightmatter(通用AI架构)和Q.ANT(针对HPC非线性方程的专用架构)为代表的系统级光子芯片,已经成功部署在真实的数据中心和超算网络中。这证明了在不改动现有高层算法软件栈的基础上,通过底层物理升维(以光速执行巨量模拟运算),能够将系统级推理能耗降低数十倍,吞吐量提升至50倍以上。
硬件体系从“同质化微缩”转向“异质化创新”。在传统电子摩尔定律碰壁的情况下,光计算产业没有走上单纯追求缩小线宽的老路,而是转向了材料维度的全面突破。薄膜铌酸锂(TFLN)与钛酸钡(BTO)等高Pockels系数材料的晶圆级成功制备,结合无跨阻放大器(TIA)的单片光电转换器的量产,打通了全光网络中致命的OEO能效瓶颈和非线性激活阻碍,使得大规模深层光网络的训练和稳定推理在物理上成为可能。
双线并行的光学重构:光互联与光处理共同推进。未来五年内,AI数据中心的底层硬件将在两个方向被光子学深度重构。其一是网络结构的全面“光化”,共封装光学(CPO)与光路交换(OCS)将彻底取代短距电缆互连与电子分组交换,为十万卡级别的GPU集群铺设无损、超低延迟的确定性高速公路;其二是运算核心的光化,光学张量核心将越来越多地以加速卡(Co-processor)的形式介入那些被内存带宽和高并发矩阵乘法所掣肘的大模型推理任务。
在此背景下,全球算力竞争的底层核心要素正在从单纯的晶体管密度,转向光学材料的异质集成良率、高并行度光芯片架构设计以及深亚波长纳米光子学工程。光计算凭借零热耗散和天然的高度并行物理优势,为打破日益严峻的能源危机和算力增长极限提供了最为客观且符合物理学定律的战略路径。