1.智能计算的转折点:从生成式AI迈向代理型AI
在全球半导体产业的演进历程中,2026年3月举办的英伟达(NVIDIA)GTC大会被视为一个分水岭,标志着计算范式从单纯的“内容生成”向“自主决策”的代理型AI(Agentic AI)实现决定性转变 。随着Vera Rubin平台的正式量产,AI基础设施的建设逻辑已经从传统的每季度性能增量演变为一场围绕“千兆瓦级AI工厂”(Gigawatt-scale AI Factories)展开的基础设施竞赛 。这一转变的背后,是算力需求从Zetta级向Yotta级的惊人跨越,全球AI算力在短短几年内实现了近100倍的增长 。

Vera Rubin架构不仅仅是Blackwell的继任者,它代表了半导体工程学的一次深刻革命。面对大语言模型(LLM)训练向100万亿参数规模迈进的挑战,传统的单体芯片(Monolithic)设计和电信号传输已触及物理极限 。为此,英伟达通过全面引入3D IC封装技术、硅光子共封装光学(CPO)以及HBM4内存体系,试图打破困扰行业多年的“存储墙”与“互连墙” 。这种系统级的深度整合,旨在为能够独立思考、推理并执行复杂任务的AI代理提供所需的推理吞吐量,同时将单个Token的推理成本降低至前代技术的十分之一 。
当前的资本支出竞赛(Capex Arms Race)已进入白热化阶段。亚马逊、谷歌和微软等超大规模云计算提供商(Hyperscalers)在2026年的资本支出计划均向2000亿美元大关迈进 。这些投入正被转化为对英伟达Vera Rubin平台的庞大预订订单,尽管美国司法部(DOJ)针对英伟达市场主导地位及其所谓“忠诚度惩罚”协议的调查仍在持续升级,但市场对先进制程算力的渴求依然压倒了监管隐忧 。
2.Vera Rubin平台:重塑算力底座的工程奇迹

Vera Rubin平台(R100)的量产,意味着英伟达在高性能计算(HPC)领域再次拉开了与竞争对手的距离。该平台的核心在于由全新Rubin GPU、Vera CPU以及第六代NVLink互连技术构成的集成化超级芯片 。
Rubin GPU的微架构创新与性能飞跃

Rubin GPU采用台积电(TSMC)先进的3nm级制程(N3P或N3)制造,其晶体管数量达到了惊人的3360亿个 。为了突破掩模版尺寸(Reticle Limit)限制,Rubin GPU采用了多芯片模块(MCM)设计,通过将四个或更多核心芯片(Dies)缝合在一起,使其在逻辑上表现为一个单一、强大的GPU实体 。
在计算精度方面,英伟达重点优化了NVFP4(4位浮点)性能,这是专门为混合专家模型(MoE)设计的计算格式 。相比于Blackwell架构,Rubin在推理工作负载上的性能提升高达5倍,而在训练任务上则实现了3.5倍的增幅 。这种性能提升很大程度上得益于新型自适应压缩技术,它取代了传统的结构化稀疏性,更有效地处理生成式AI中的稀疏矩阵运算 。
值得注意的是,为了确保在与AMD Instinct MI455X等对手的竞争中占据绝对优势,英伟达将Rubin GPU的额定功耗从最初设想的1.8 kW提升至2.3 kW 。这额外的500W功耗裕量被用于维持更高的持续加速频率,并支持更多的执行单元(Tensor Units)在高负载下同时运转,从而确保在千兆瓦级数据中心部署时能够提供可预测的吞吐量 。
Vera CPU:跨越Grace时代的自研算力

Vera CPU是Vera Rubin平台的另一大支柱,旨在完全取代基于ARM架构的Grace CPU。Vera CPU集成了88个定制的ARM架构“Olympus”核心,并支持同步多线程(SMT)技术 。该CPU通过1.8 TB/s的NVLink-C2C互连与两颗Rubin GPU配对,形成了Vera-Rubin超级芯片 。
为了应对复杂的AI代理任务,Vera CPU配备了1.5 TB的LPDDR5x内存,容量是Grace CPU的三倍 。这种巨大的内存池对于处理长上下文推理和大规模检索增强生成(RAG)至关重要。通过将互连从主板层级移动到硅片内部,英伟达成功解决了大模型推理过程中频繁发生的内存访问瓶颈 。
3. 3D IC封装技术突破:突破物理限制的基石
随着晶体管微缩进入亚纳米领域,封装技术已从“后台支持”转变为决定AI算力上限的“先锋力量” 。英伟达在GTC 2026上展示的3D IC封装突破,标志着半导体行业正式进入“封装优先”的时代 。
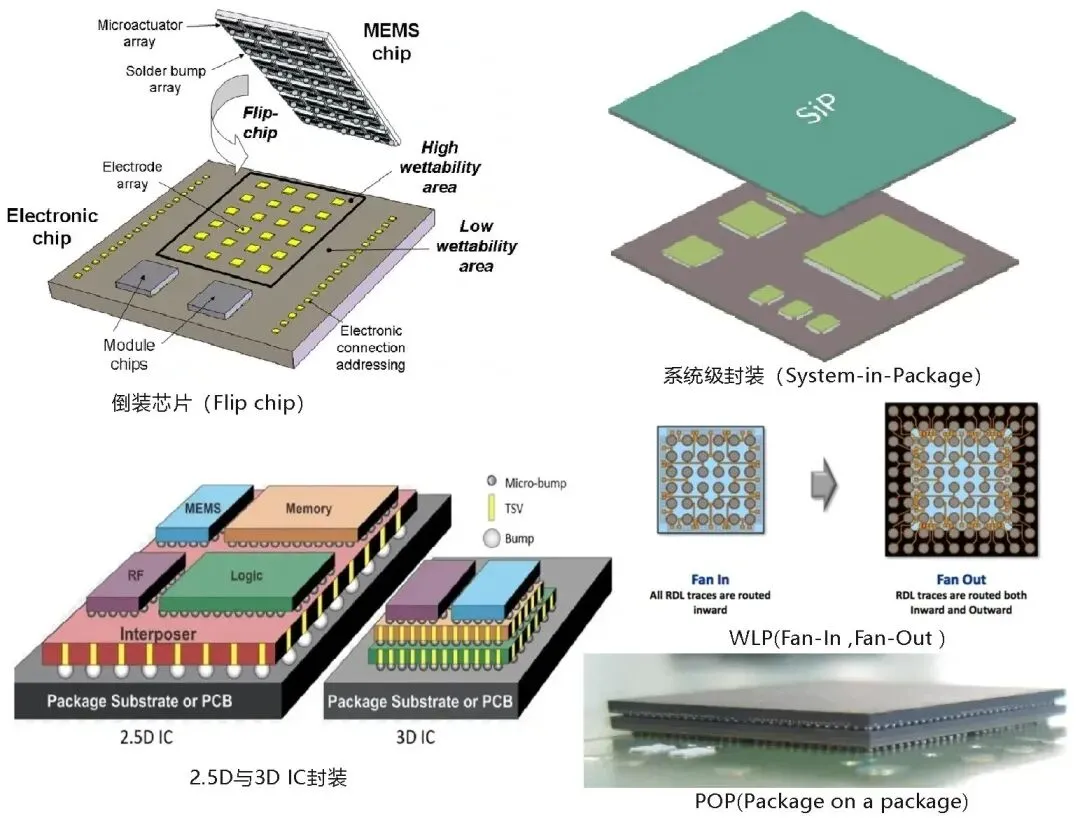
CoWoS-L的全面应用与演进
Rubin架构彻底告别了传统的CoWoS-S(单片硅中介层)封装,全面转向CoWoS-L(局部硅互连)技术 。CoWoS-S受限于光刻机的掩模尺寸,难以集成更多的内存堆栈,而CoWoS-L利用嵌入在有机层中的小型硅桥(LSI),允许封装尺寸达到标准芯片尺寸的6倍以上 。

这种技术演进使得英伟达能够在单个封装中集成多达12至16个HBM4内存堆栈,从而实现前所未有的显存容量和带宽 。此外,CoWoS-L通过重新分布层(RDL)和局部硅互连的结合,不仅提高了信号传输密度,还显著改善了大尺寸封装下的良率问题 。
SoIC-X与杂化键合的工业化
英伟达在Rubin超级芯片中采用了台积电的SoIC-X(集成芯片系统)技术,这是一种真正的3D堆叠方案 。与传统的微凸块(Micro-bumps)连接不同,SoIC-X利用“杂化键合”(Hybrid Bonding)实现铜对铜的直接连接,将互连间距缩小至6微米至9微米 。
这种无凸块连接在每平方毫米内可提供超过100万个互连点,极大地降低了电学阻抗和功耗 。通过这种方式,逻辑核心与I/O芯片可以实现垂直融合,从而将HBM内存与计算核心之间的距离缩短至微米级 。这一突破是打破“存储墙”的关键,使得Rubin能够以22.2 TB/s的速率访问内存,确保了其在处理100万亿参数模型时的高效运行 。
玻璃基板:散热与稳定性的最终方案
针对Rubin GPU超过2.3 kW的极端热负荷,英伟达开始在高性能计算平台中引入玻璃基板(Glass Substrates) 。相比于传统的有机材料,玻璃基板具有10倍的布线密度提升以及优越的平整度和热稳定性 。玻璃材料的引入有效防止了大面积系统级封装(SiP)在制造过程中的翘曲问题,并支持集成超过50个独立的芯粒(Chiplets) 。随着AI处理器向2000W以上功耗迈进,玻璃基板结合背面供电技术(Backside Power Delivery)正成为千兆瓦级AI工厂中不可或缺的技术支撑 。
4.硅光子商业化:光速互连时代的到来
在2026年的GTC大会上,英伟达首席执行官黄仁勋正式开启了“硅光子时代”,旨在通过光信号取代电信号,彻底解决超大规模集群中的数据传输瓶颈 。
共封装光学(CPO)的跨越
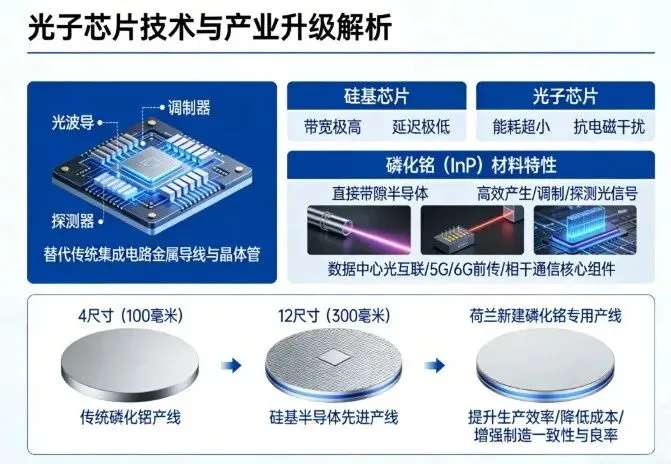
共封装光学(CPO)技术的核心在于将光学引擎直接集成到交换机ASIC或GPU的封装基板上,而不是像传统方式那样将其放置在外部的可插拔收发器(Transceivers)中 。这种集成方案将电信号转换为光信号的路径缩短了90%以上,从原来的十几英寸缩短到半英寸以内 。
通过消除笨重的外部数字信号处理器(DSP)重定时器,英伟达的CPO方案实现了高达5倍的能效提升和10倍的网络弹性 。这一技术突破不仅降低了光网络的能耗(光网络能耗通常占计算资源的10%),还极大地减少了大型GPU集群中的光纤连接复杂性 。
Quantum-X 与 Spectrum-X 光子交换机
英伟达推出了基于硅光子技术的Spectrum-X Ethernet Photonics和Quantum-X Photonics InfiniBand交换机 。Spectrum-X平台专为多租户超大规模AI云设计,每端口带宽达到1.6 Tbps,总吞吐量高达409.6 Tbps 。
而Quantum-X InfiniBand平台则采用了液冷设计,支持连接超过10,000个GPU的无阻塞二层肥树(Fat-tree)拓扑结构 。这些光子交换机的量产,使得构建拥有百万颗GPU的AI超级工厂成为可能,同时也显著降低了总拥有成本(TCO) 。
5.HBM4内存:打破存储瓶颈的最后一块拼图

Vera Rubin架构的性能飞跃离不开HBM4内存的鼎力支持。作为存储行业的新标杆,HBM4通过增加堆叠层数和位宽,实现了带宽的翻倍提升 。
供应商竞争与技术指标
三星电子(Samsung)和SK海力士(SK Hynix)是Rubin平台HBM4内存的主要竞争者 。SK海力士凭借其与英伟达长期的合作伙伴关系,已在2026年初进入最后的测试阶段,预计将供应今年约三分之二的HBM4需求 。与此同时,三星也在GTC 2026上展示了其通过验证的HBM4产品,该产品旨在为超大规模模型推理提供前所未有的位分配(Bit Allocation)效率 。

Rubin GPU配备的HBM4内存具有2048位的总线宽度,单个GPU的显存容量达到288GB,全速运转时带宽可达22.2 TB/s 。这种海量的显存资源使得甚至是最复杂的模型也能在单卡或单个机柜内完成内存驻留,极大地减少了模型并行带来的通信开销 。
内存层级结构的革新
除了HBM4,三星还展示了其针对AI工厂的其他存储创新,包括支持PCIe Gen6的PM1763固态硬盘以及SOCAMM2服务器内存模块 。这些技术共同构成了一个多层次的AI内存架构,能够持续支撑物理AI(Physical AI)和自动驾驶等高频数据交换场景 。
6.数据中心基础设施:迈向千兆瓦级算力工厂
Vera Rubin不仅仅是芯片的升级,它标志着数据中心设计从服务器集群向“算力工厂”的全面转型。随着AI工作负载的规模不断扩大,散热和供电已成为制约性能发挥的核心挑战 。

NVL72 与 NVL144 机柜系统
英伟达推出的Vera Rubin NVL72系统采用了全液冷机架配置,集成了72颗Rubin GPU和36颗Vera CPU 。该系统的NVFP4推理性能达到了3600 PFLOPS,总显存容量高达20.7 TB 。对于更高端的需求,NVL144机架则提供了翻倍的GPU密度,旨在应对需要极高性能且功耗敏感的顶级超算中心 。
为了配合这些算力怪兽,诸如Supermicro(超微)和AMAX等基础设施厂商已经推出了针对Vera Rubin优化的DCBBS(数据中心模块化解决方案),大幅缩短了从机房设计到算力上线的周期 。

存储与网络协同:DDN 与 Vast Data 的角色
在算力工厂中,存储不再是冷冰冰的数据归档,而是GPU的“血液循环系统”。DDN展示了其与英伟达合作开发的AI数据智能平台,通过优化存储路径,使GPU在大规模训练中的利用率达到99% 。
Vast Data则推出了专为代理型AI设计的推理上下文存储平台,通过直接运行在BlueField-4 DPU上的AI操作系统,消除了冗余的数据副本,将推理的首个Token生成时间(TFTT)缩短了40% 。这种软硬件一体化的协同,确保了Vera Rubin平台在处理实时多模态交互时能够提供极高的响应速度 。
8.供应链与全球竞争格局:英伟达的市场统治力
尽管英伟达在技术上处于领先地位,但其庞大的算力帝国依然面临供应链瓶颈和激烈的外部竞争 。
台积电封装产能的“独霸”
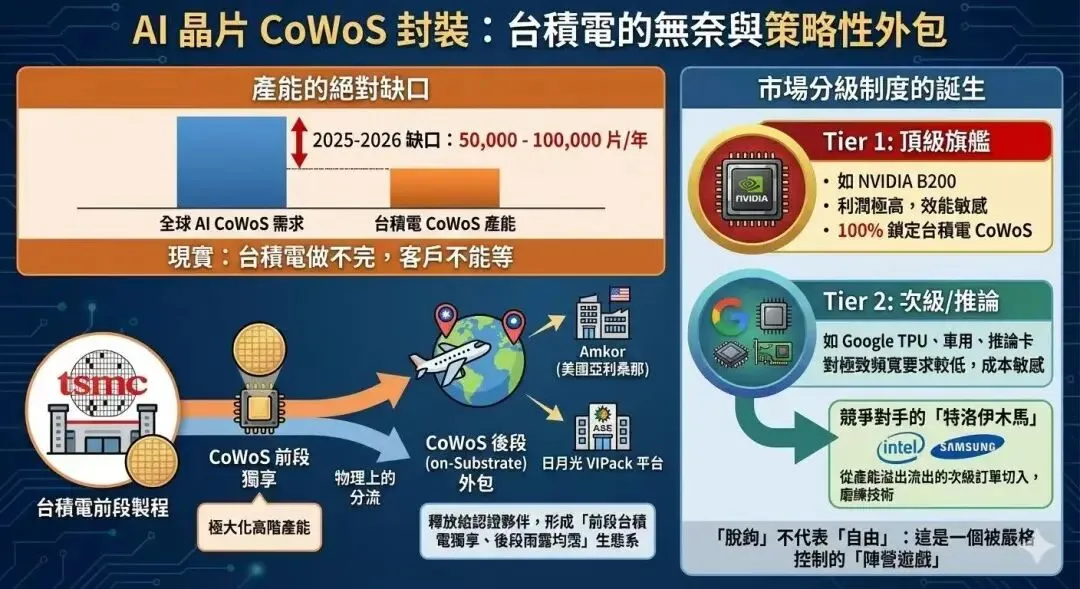
2026年,获取台积电CoWoS封装产能的能力已成为衡量一家半导体公司市场地位的关键指标。英伟达已经锁定了台积电2026年全球CoWoS产能的60%以上,约合51万片晶圆 。这种对稀缺产能的掌控,不仅确保了Rubin平台的稳定供应,也实际上为后来者设置了极高的行业壁垒 。
除了顶级台积电产能,英伟达还将非核心芯片(如Vera CPU和汽车级芯片)的封装外包给日月光(ASE)和安考(Amkor)等OSAT厂商 。这种多层次的供应链管理策略,使其能够在保持高性能芯片供应的同时,最大化整体出货量 。
台湾供应链的崛起:从光通信到基板
英伟达的成功带动了一批台湾中小企业的崛起。Poloniex作为硅光子产品的关键供应商,其利润率已从14%提升至18%以上 。博睿(Boruwei)的CPO相关模块出货量预计将在2027年从现在的1万台激增至30万台 。睿轩(Ruixuan)则通过其在越南的工厂负责光纤配线箱(Shuffle Boxes)的最后组装,这些价值6000至8000美元的组件正成为AI光子基础设施中重要的利润增长点 。
AMD 与 Intel 的防御性竞争
AMD正试图通过其Instinct MI400系列打破英伟达的垄断。MI455X采用了CDNA 5架构,宣称其HBM4内存容量比英伟达Rubin高出50%,并拥有更强的向外扩展(Scale-out)带宽 。然而,英伟达通过快速迭代和庞大的CUDA生态系统,依然在推理经济学和大规模集群稳定性方面保持着显著优势 。
Intel则更多地扮演了“潜在盟友”的角色。虽然Intel的Gaudi系列和Falcon Shores在算力市场占有一席之地,但其在玻璃基板和Foundry技术(如18A制程)上的突破,使其可能在2028年后的Feynman架构周期中成为英伟达的二号代工厂 。
9.未来路线图:迈向 Feynman 与 1.6nm 时代
GTC 2026的一个高潮是黄仁勋对2028年“Feynman”(费曼)架构的预热 。Feynman将是英伟达首款基于台积电1.6nm(A16)工艺的芯片 。
A16 工艺与背面供电(SPR)

Feynman架构将首次全面引入背面供电技术(SPR),这不仅可以提高10%的逻辑密度,还能将能耗降低15% 。背面供电技术将电源线从信号层下方移动到芯片背面,彻底解决了超高密度晶体管带来的布线拥塞和压降问题 。
硅光子的完全集成
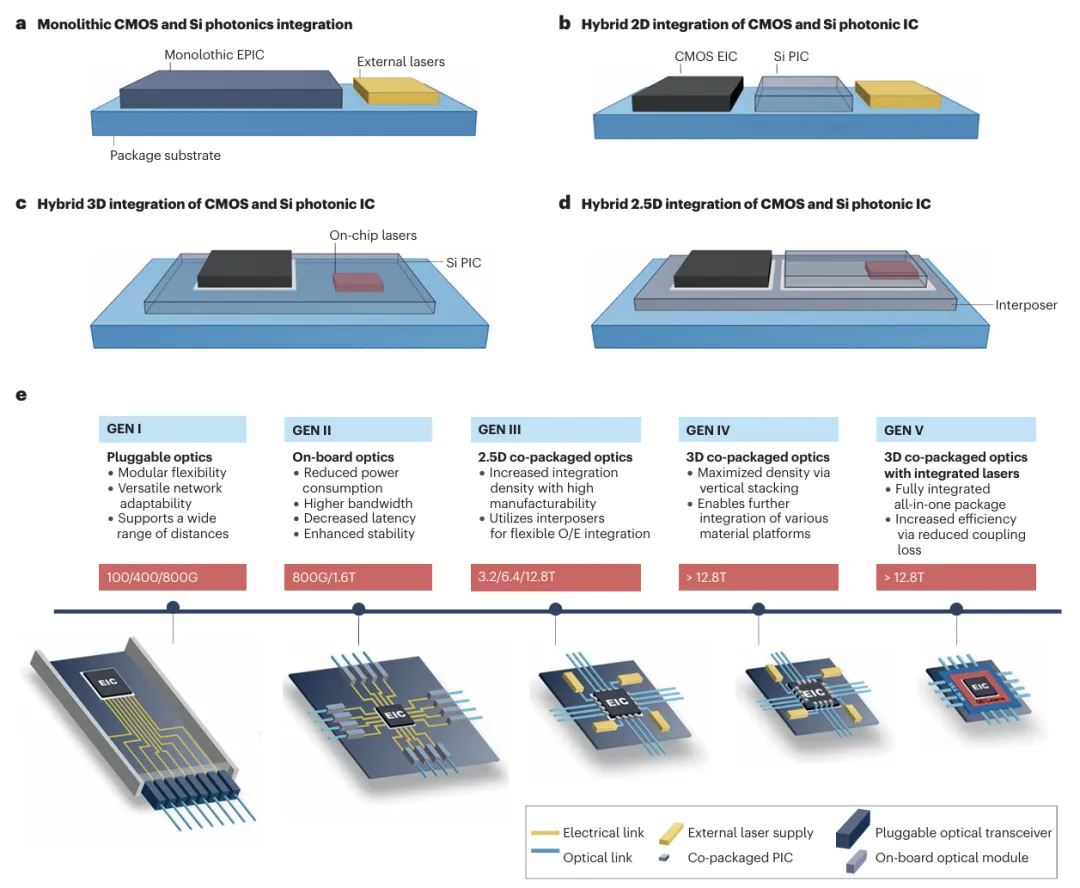
在Feynman时代,硅光子将进入第三阶段:光子引擎将直接集成在处理器封装(In-package)内部 。这意味着GPU核心与网络接口之间将实现真正的光速连接,带宽有望达到12.8 Tbps以上 。这种演进预示着,到2030年,计算和通信将不再是两个独立的领域,而是融合为一个高度统一的光学计算网络 。
10.结论:智能算力的主权与未来
英伟达GTC 2026不仅展示了Vera Rubin平台的技术细节,更揭示了未来十年全球智能算力的演进逻辑。通过在3D IC封装、硅光子商业化和自研CPU领域的全面突破,英伟达已经从一家“显卡公司”彻底转型为“AI主权基础设施的架构师” 。
对于专业观察者而言,Vera Rubin的量产意味着以下几点深远影响:
推理即商品:随着NVFP4和Rubin架构将推理成本降低90%,AI智能将像电力一样成为按需购买的公共事业 。
物理极限的超越:3D堆叠和玻璃基板技术使得单体芯片的物理尺寸不再是性能的限制,算力工厂的规模将由机柜的散热效率决定 。
光速文明的开启:硅光子CPO技术的落地,预示着未来百万GPU集群的通信效率将不再受限于铜线的物理阻抗 。
地缘政治的筹码:算力已成为一种地缘政治资源,英伟达通过对台积电产能和核心IP的掌控,建立了一套基于算力主权的全球护城河 。
Vera Rubin时代的开启,不仅仅是硬件参数的迭代,它是人类利用硅基智慧模拟并增强自然界推理能力的宏大实验。随着Feynman架构在1.6nm时代的远期召唤,英伟达正带领整个科技行业向着通用人工智能(AGI)的深蓝海域全力进发。

扫码进群,人脉资源一网打尽!