


导读:如果说大模型是AI时代的"大脑",那么AI Agent就是拥有"手脚"的完全体。2026年,AI Agent正从概念验证走向规模化落地,这场技术革命将如何重塑软件开发、产品设计和商业模式?本文深度解析AI Agent的技术架构、开发框架、应用场景与落地实践,为开发者和产品经理提供一份完整的行动指南。
目录
1. 为什么2026年是AI Agent的元年 2. AI Agent的本质:超越大模型的新范式 3. 技术架构深度拆解:六大核心模块 4. 记忆机制:让AI拥有"持续认知"能力 5. 规划与决策:从任务分解到自主执行 6. 工具调用:连接AI与现实世界的桥梁 7. 主流框架对决:LangGraph vs AutoGen vs CrewAI 8. Google ADK与OpenAI Agents SDK:巨头入局 9. Multi-Agent系统:团队协作的力量 10. 应用场景全景:100+实战案例 11. 企业级落地:从POC到规模化部署 12. 性能优化与成本控制 13. 2026十大发展趋势 14. 开发者与产品经理的行动指南
1. 为什么2026年是AI Agent的元年
1.1 从"数字玩具"到"生产力工具"的质变
2025-2026年,AI Agent正在经历一场深刻的范式转变。根据最新行业数据,企业级AI Agent的竞争核心已从单纯的模型能力,逐步转向平台生态与产业落地能力。
关键转折点:
• 技术成熟度:通过优化记忆机制与Context压缩算法,推动Agent实现数月甚至数年的长期自主性 • 商业价值验证:超过68%基于主流框架构建的AI应用采用了多工具组合的Agent架构 • 新职业诞生:"AI智能体运营工程师"成为2026年高价值新兴职业,融合大模型技术与业务场景
1.2 市场规模与生态爆发
? 2026年AI Agent市场格局:
- 开源框架:LangGraph、AutoGen、CrewAI三足鼎立
- 巨头入局:Google ADK、OpenAI Agents SDK相继发布
- 企业应用:从客服、营销扩展到研发、生产、财务等全业务流程为什么现在必须关注AI Agent?
• 大模型提供了强大的语言处理能力,而Agent在此基础上增加了环境感知、决策制定和任务执行的能力 • AI Agent能够自主规划、工具调用、记忆管理,实现从"对话"到"行动"的跃迁 • 2026年被称为"企业Agent上岗元年",多智能体将率先在数据基础完善、业务流程复杂的领域实现规模化部署
2. AI Agent的本质:超越大模型的新范式
2.1 核心定义
AI Agent(智能体)是一种能够感知环境、制定决策并采取行动以实现特定目标的AI系统,具备记忆、规划、采取行为、使用工具等基本能力。
公式化表达:
AI Agent = LLM(大脑)+ 规划技能 + 记忆 + 工具使用其中LLM扮演Agent的"大脑",提供推理、规划等能力;而Agent则是大模型的"手脚"和"工具集",赋予大模型感知环境和执行动作的能力。
2.2 AI Agent vs 大模型:五大核心区别
| 交互方式 | ||
| 数据处理 | ||
| 应用场景 | ||
| 自主性 | ||
| 持续性 |
典型案例对比:
大模型场景(Copilot模式):
用户:帮我写一个Python函数,计算斐波那契数列
AI:def fibonacci(n):
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)AI Agent场景(自主执行):
用户:分析公司Q1销售数据,找出增长最快的产品,并生成报告邮件给团队
AI Agent:
1. ? 连接数据库,查询Q1销售数据
2. ? 分析各产品增长率
3. ? 生成可视化图表
4. ✉️ 撰写报告邮件
5. ? 发送给团队成员2.3 从"信息入口"到"智能入口"的演进
技术变革路径:
• 过去:判别式AI → 嵌入式 → 信息入口 • 现在:生成式AI → 智能入口 → Agents
AI智能体将成为人与大模型交互的主要方式,从"配置模块、记忆模块、规划模块、执行模块"四个维度重构人机协作。
3. 技术架构深度拆解:六大核心模块
3.1 整体架构概览
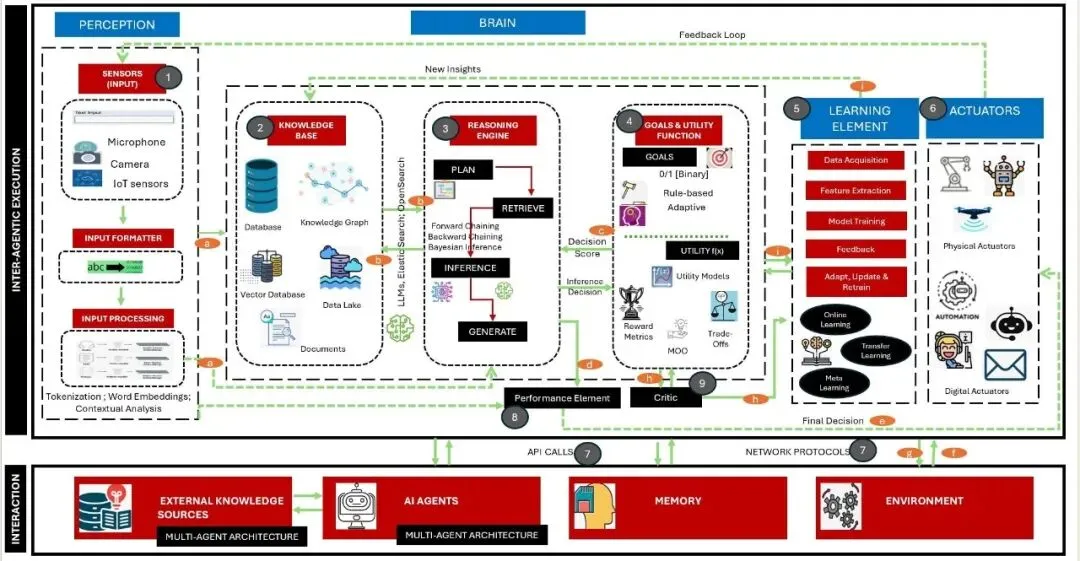
Agentic AI完整架构图展示了从感知到执行的完整闭环,包含:
1. 感知层(Perception):传感器、输入格式化、输入处理 2. 知识库(Knowledge Base):数据库、知识图谱、向量数据库、数据湖 3. 推理引擎(Reasoning Engine):计划、检索、推理、生成 4. 目标与效用函数(Goals & Utility Function):目标设定、决策评分 5. 学习元素(Learning Element):数据获取、特征提取、模型训练 6. 执行器(Actuators):物理执行器、数字执行器、自动化
3.2 六大核心模块详解
根据最新研究,AI Agent的技术架构已从早期的单一模型封装,演进为一套复杂的、模块化的系统。
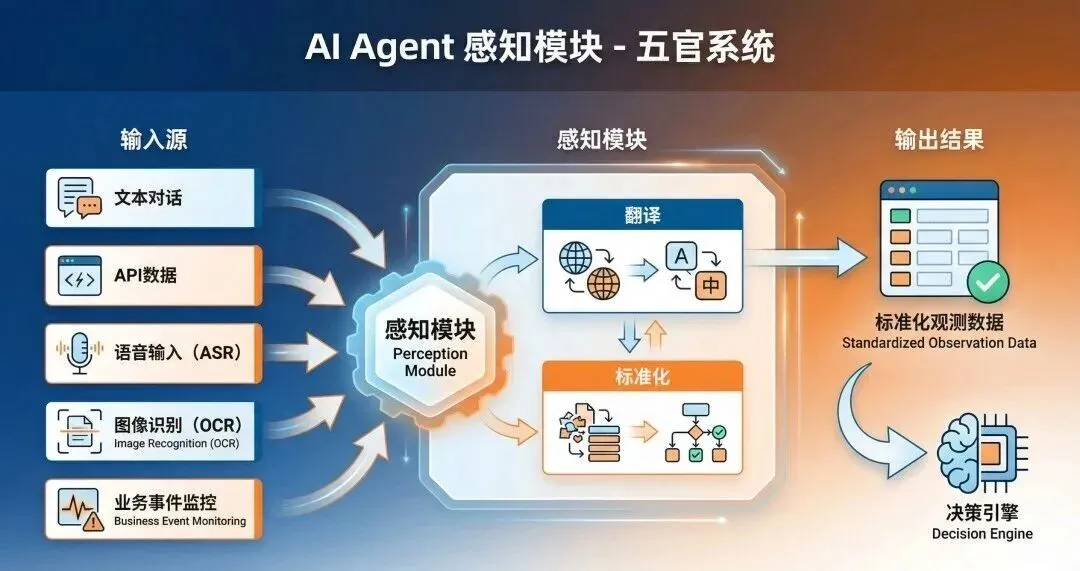
模块1:感知模块(Perception Module)
功能:多模态信息输入与处理
• 输入源: • 文本对话 • API数据 • 语音输入(ASR) • 图像识别(OCR) • 业务事件监控
处理流程:
原始输入 → 翻译 → 标准化 → 去噪与整理 → 高质量预处理 → 决策引擎技术要点:
• 多模态信息处理(Multimodal Information Processing) • 标准化观测数据(Standardized Observation Data) • 高质量预处理(High-Quality Preprocessing)
模块2:记忆模块(Memory Module)
分层记忆系统:
• 短期记忆:工作记忆,保存当前对话上下文 • 长期记忆: • 语义记忆:基础事实、世界知识 • 程序记忆:规则集、程序代码 • 情景记忆:历史事件流、经验
记忆操作:
• 记忆巩固(Consolidation) • 记忆索引(Indexing) • 记忆更新(Updating) • 记忆遗忘(Forgetting) • 记忆检索(Retrieval) • 记忆压缩(Compression)
模块3:规划模块(Planning Module)
核心能力:
• 任务分解:将复杂目标拆解为可执行的子任务 • 思维链(CoT):Chain of Thought推理 • 思维树(ToT):Tree of Thoughts探索多路径 • 自我反思:Self-critics评估执行效果 • 子目标分解:Subgoal decomposition
规划算法:
1. 理解任务目标
2. 检索相关知识与经验
3. 生成执行计划
4. 评估计划可行性
5. 动态调整与优化模块4:工具模块(Tools Module)
工具类型:
• Calendar():日历管理 • Search():网络搜索 • Calculator():数值计算 • CodeInterpreter():代码执行 • Image():图像处理 • Script():脚本运行 • API调用:外部服务集成
工具调用机制:
Agent思考 → 选择工具 → 构建参数 → 执行工具 → 观察结果 → 下一步决策模块5:执行模块(Action Module)
执行流程:
1. 将自然语言决策转化为计算机指令 2. 通过预定义的工具模式(Tool Schema)构建参数 3. 调用外部工具或API 4. 监控执行状态 5. 处理执行结果
执行特点:
• 自主性:无需人工干预 • 可观测性:实时追踪执行进度 • 容错性:异常处理与重试机制
模块6:反思模块(Reflection Module)
反思机制:
• Reflection:任务完成后全局回顾 • Self-critics:自我反思和批评 • Chain of thoughts:思维链追踪 • Subgoal decomposition:子目标评估
学习循环:
执行 → 观察结果 → 评估成功/失败 → 提炼经验 → 更新记忆 → 优化下次执行3.3 三层架构设计
从技术实现视角,智能体分为三层:
1. 交互层(Interaction Layer)
• 自然语言接口 • 多模态输入输出 • 用户反馈收集
2. 智能决策层(Intelligent Decision Layer)
• LLM推理引擎 • 规划与调度 • 记忆管理 • 工具选择
3. 系统连接层(System Connection Layer)
• API集成 • 数据库访问 • 外部工具调用 • 事件驱动架构
智能体执行引擎统一完成编排与调度,确保各层协同工作。
4. 记忆机制:让AI拥有"持续认知"能力
4.1 为什么记忆是Agent的核心
记忆的定义:Agent记忆(Agent Memory)是指AI Agent在执行任务过程中存储和管理信息的能力和机制。它类似于人类的记忆系统,使Agent能够记住过去的交互、经验和知识,并在未来的决策中使用。
记忆的重要性:
• 上下文保持:在多轮对话中保持一致性 • 经验积累:从历史任务中学习 • 个性化服务:记住用户偏好 • 长期目标追踪:跨会话任务管理
4.2 记忆系统的分类
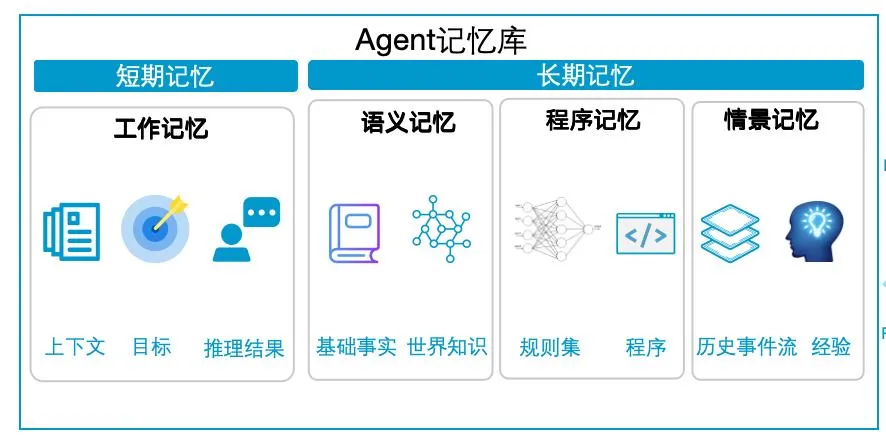
短期记忆(Short-term Memory)
工作记忆(Working Memory):
• 内容:上下文、当前目标、推理结果 • 特点:容量有限、快速访问、临时存储 • 实现:LLM的Context Window、KV Cache • 生命周期:单次会话内有效
应用场景:
用户:我想订一张去北京的机票
Agent:请问出发日期是?(记住:目的地=北京)
用户:下周一
Agent:好的,正在查询下周一到北京的航班...(保持上下文)长期记忆(Long-term Memory)
1. 语义记忆(Semantic Memory)
• 内容:基础事实、世界知识、概念关系 • 实现:知识图谱、向量数据库 • 示例:"北京是中国的首都"
2. 程序记忆(Procedural Memory)
• 内容:规则集、程序代码、操作流程 • 实现:LLM参数化知识、Agent代码 • 示例:"订机票的标准流程"
3. 情景记忆(Episodic Memory)
• 内容:历史事件流、个人经验、交互记录 • 实现:数据库、日志系统 • 示例:"用户上次订的是商务舱"
4.3 记忆管理操作
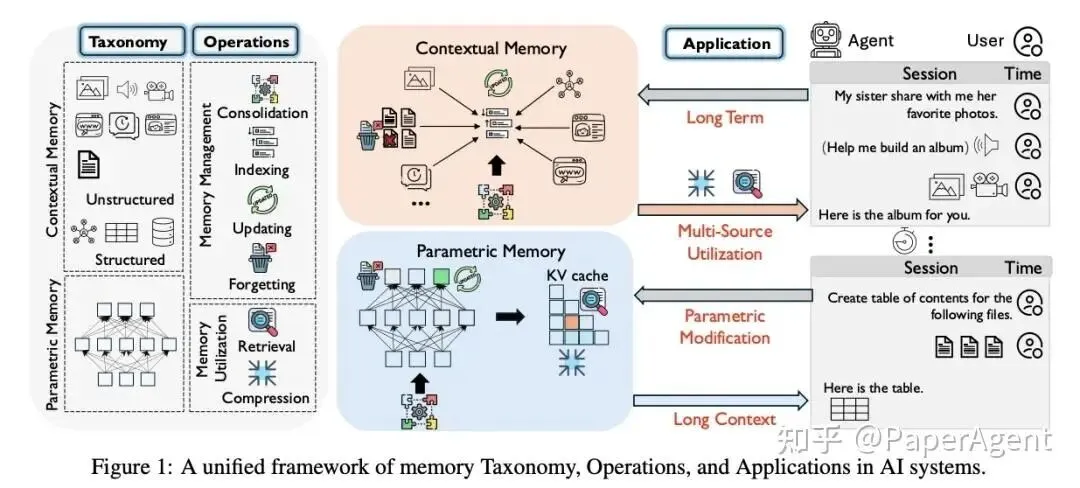
六大记忆操作:
1. 记忆巩固(Consolidation)
• 将短期记忆转化为长期记忆 • 从对话中提取结构化关键信息 • 示例:从"我喜欢川菜"提炼为"用户偏好:川菜"
2. 记忆索引(Indexing)
• 为记忆添加标签和元数据 • 建立快速检索机制 • 使用向量嵌入(Embedding)进行语义索引
3. 记忆更新(Updating)
• 修正过时的信息 • 合并冲突的记忆 • 示例:用户搬家后更新地址信息
4. 记忆遗忘(Forgetting)
• 删除无用或过期的记忆 • 保护隐私(GDPR合规) • 控制记忆容量
5. 记忆检索(Retrieval)
• 根据当前任务检索相关记忆 • 语义相似度匹配 • 多源记忆融合
6. 记忆压缩(Compression)
• 摘要长文本记忆 • Context压缩算法 • 保持关键信息不丢失
4.4 记忆实现技术
技术栈:
# 短期记忆:使用Redis
redis.set("session:user:context", json.dumps(context), ex=3600)
# 长期记忆:使用向量数据库(Pinecone/Weaviate)
vector_db.insert({
"user_id": "123",
"content": "喜欢川菜",
"embedding": embed("喜欢川菜"),
"timestamp": now()
})
# 语义检索
similar_memories = vector_db.search(
query=embed("推荐餐厅"),
filter={"user_id": "123"},
top_k=5
)最佳实践:
• 分层存储:热数据(Redis)+ 冷数据(数据库) • 异步提取:自动记忆提取模块异步运行 • 同步/异步结合: • 短期记忆:同步更新(保证实时性) • 长期记忆:异步写入(降低延迟)
4.5 记忆机制的2026年突破
2026年AI Agent在长期自主性方面将实现关键突破,核心体现在记忆机制的根本性改进:
技术突破方向:
• 优化记忆机制与Context压缩算法 • 推动Agent实现数月甚至数年的长期自主性 • 跨任务记忆保持与迁移学习
技术趋势:
• 记忆演化:记忆系统能够随着环境和任务的变化,动态调整认知过程与上下文理解能力 • 自我进化:Agent不仅"存",还要能在交互中不断更新、整合、纠错、抽象,并跨任务保持一致性
5. 规划与决策:从任务分解到自主执行
5.1 规划能力的核心作用
定义:AI智能体规划是指人工智能智能体确定一系列行动以实现特定目标的过程。它涉及决策、目标优先级排序和行动排序,通常会使用各种规划算法和框架。
规划能力使Agent能够:
• 将复杂目标分解为可执行的步骤序列 • 在不确定环境中做出明智的选择 • 动态调整计划以应对变化 • 多任务并行处理与资源分配
5.2 规划技术全景
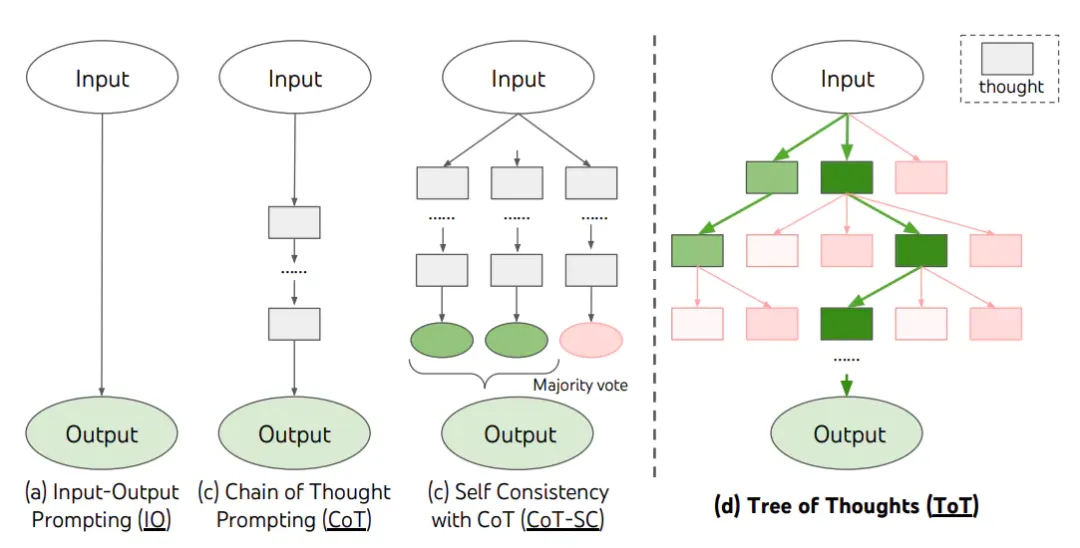
1. 基础 prompting 方法
(a) Input-Output Prompting (IO)
输入:问题
输出:答案• 最简单的直接问答 • 适用于简单任务
(b) Chain of Thought Prompting (CoT)
输入:问题
思考:步骤1 → 步骤2 → 步骤3
输出:答案• 引导模型逐步推理 • 显著提升复杂任务表现
(c) Self Consistency with CoT (CoT-SC)
生成多条推理链 → 多数投票 → 最终答案• 提高推理可靠性 • 代价:多次LLM调用
2. 高级规划方法
(d) Tree of Thoughts (ToT)
初始问题
/ | \
路径1 路径2 路径3
/ \ / \ / \
... ... ... ... ...
探索多路径 → 评估 → 选择最优ToT核心操作:
• Thought Generator:生成多个可能的下一步思考 • State Evaluator:评估每个状态的价值 • Search Algorithm:BFS/DFS/MCTS搜索策略
代码示例:
deftree_of_thoughts(problem, depth=3, breadth=5):
root = Thought(problem)
queue = [root]
for _ inrange(depth):
next_level = []
for node in queue:
# 生成多个可能的下一步
thoughts = llm.generate_thoughts(node, breadth)
# 评估每个思考
evaluated = [evaluate(t) for t in thoughts]
# 选择最优的
best = select_best(evaluated, top_k=2)
next_level.extend(best)
queue = next_level
return find_best_solution(queue)5.3 任务分解策略
10种基于大模型的Agent任务规划方式:
1. 顺序分解(Sequential Decomposition)
目标:写一份市场分析报告
子任务:
1. 收集市场数据
2. 分析竞争对手
3. 识别趋势
4. 撰写报告2. 并行分解(Parallel Decomposition)
目标:开发电商网站
子任务(并行):
- 前端开发
- 后端开发
- 数据库设计
- UI/UX设计3. 层次分解(Hierarchical Decomposition)
顶层目标
├─ 子目标1
│ ├─ 子任务1.1
│ └─ 子任务1.2
└─ 子目标2
├─ 子任务2.1
└─ 子任务2.24. 基于角色的分解(Role-based Decomposition)
项目:产品发布
角色分工:
- 产品经理:需求定义
- 设计师:UI设计
- 开发工程师:代码实现
- 测试工程师:质量保证5. 基于技能的分解(Skill-based Decomposition)
任务:数据分析
技能需求:
- 数据清洗(Pandas)
- 统计分析(统计学)
- 可视化(Matplotlib)
- 报告撰写(写作)5.4 决策机制
决策流程:
感知环境 → 检索记忆 → 生成选项 → 评估选项 → 选择行动 → 执行 → 观察结果决策算法:
1. 规则基础决策(Rule-based)
if condition1:
action = action1
elif condition2:
action = action2
else:
action = default_action2. 效用函数决策(Utility-based)
defchoose_action(actions, state):
best_action = None
max_utility = -infinity
for action in actions:
utility = calculate_utility(action, state)
if utility > max_utility:
max_utility = utility
best_action = action
return best_action3. LLM驱动决策
prompt = f"""
当前状态:{state}
可用行动:{actions}
历史经验:{memory}
请选择最优行动并说明理由:
"""
decision = llm.generate(prompt)5.5 自我反思与优化
ReAct模式(Reasoning + Acting):
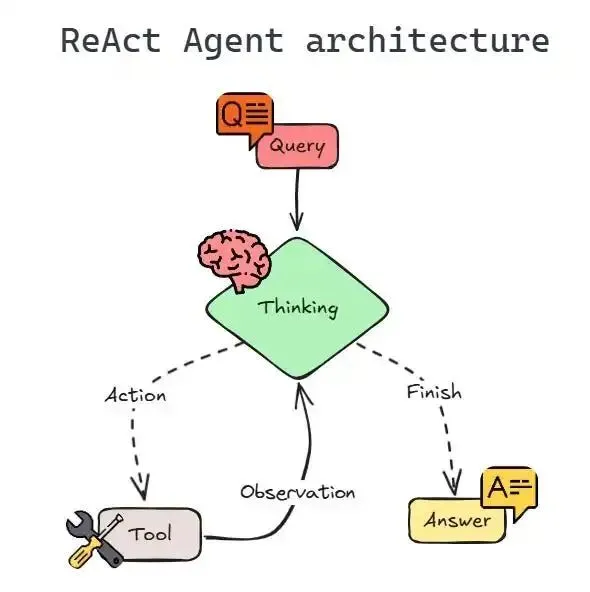
Thought: 我需要查询今天的天气
Action: search_weather(location="Beijing")
Observation: "晴天,25°C"
Thought: 好的,天气不错
Final Answer: 今天北京是晴天,25°CReflexion模式:
defreflexion_agent(task):
for attempt inrange(max_attempts):
# 执行任务
plan = generate_plan(task)
result = execute(plan)
# 评估结果
success, feedback = evaluate(result)
if success:
return result
# 反思并改进
reflection = reflect(plan, result, feedback)
update_strategy(reflection)
return"Failed after multiple attempts"自我批评(Self-Criticism):
初始方案:使用快速排序
自我批评:数据量小且近乎有序,插入排序可能更优
改进方案:改用插入排序5.6 自适应任务规划
动态调整机制:
classAdaptivePlanner:
def__init__(self):
self.plan = None
self.monitor = ExecutionMonitor()
defexecute_with_adaptation(self, goal):
self.plan = create_plan(goal)
whilenotself.plan.is_complete():
# 执行当前步骤
step = self.plan.current_step()
result = execute(step)
# 监控环境变化
changes = self.monitor.detect_changes()
if changes:
# 重新规划
self.plan = replan(self.plan, changes)
# 更新进度
self.plan.update(result)
returnself.plan.get_final_result()人机协作规划:
• Agent生成计划 → 人类审核 → 批准/拒绝/修改 • 形成协作式人机AI规划循环 • 关键决策点引入人工干预
6. 工具调用:连接AI与现实世界的桥梁
6.1 工具调用的核心价值
定义:工具调用(Function Calling)是让LLM能够使用外部工具的核心机制。它允许模型决定何时调用工具、调用哪个工具,以及传递什么参数。
为什么需要工具调用?
• 突破知识截止:访问实时数据(天气、股票、新闻) • 增强计算能力:执行复杂数学运算 • 扩展行动能力:调用API、操作数据库、发送邮件 • 提升准确性:使用专业工具而非依赖LLM猜测
简单地说:智能体通过工具调用将大语言模型的"思考"能力与外部系统、工具、API的"行动"能力结合,实现从需求理解到任务执行的闭环。
6.2 工具调用机制详解
核心循环:
1. 接收用户指令
2. 思考(是否需要工具?)
3. 选择工具
4. 构建参数
5. 调用工具
6. 观察结果
7. 继续思考或给出答案工具调用流程:
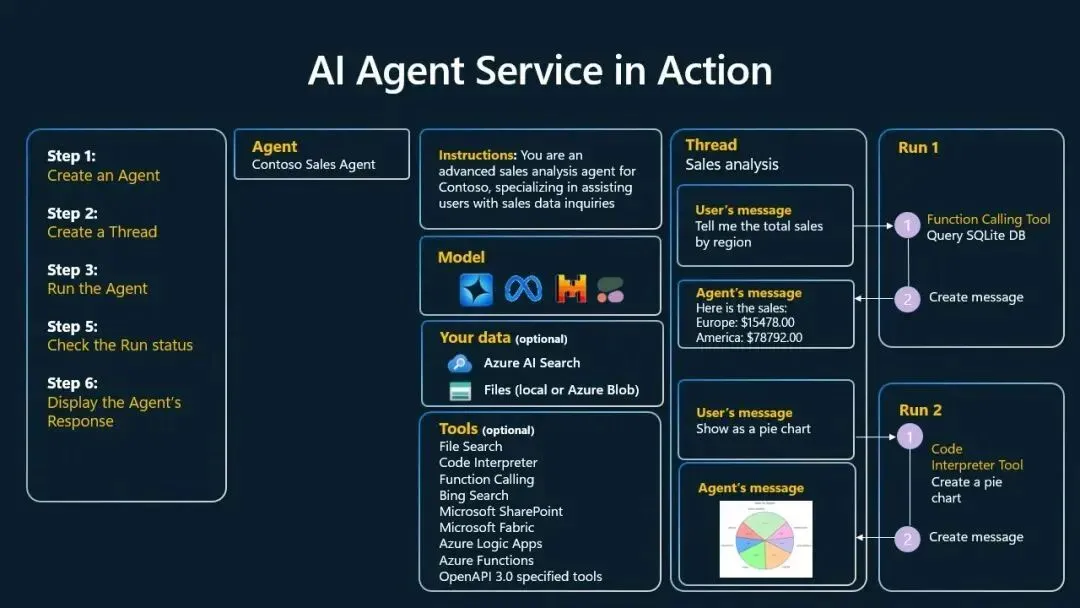
示例:销售数据分析Agent
Step 1: 创建Agent(Contoso Sales Agent)
Step 2: 创建对话线程
Step 3: 运行Agent
用户:告诉我各地区的总销售额
→ Agent思考:需要查询数据库
→ 工具调用:Query SQLite DB
→ 观察结果:Europe: $15478.00, America: $78792.00
→ Agent:生成回答
用户:用饼图显示
→ Agent思考:需要生成图表
→ 工具调用:Code Interpreter Tool
→ 执行代码:创建饼图
→ 观察结果:返回图表图片
→ Agent:显示图表6.3 OpenAI Function Calling
Function Calling机制:
Function Call机制是GPT模型的一种扩展能力,允许Agent调用预定义的工具(函数)。开发者通过提供函数的签名及其功能描述,让模型能够理解何时以及如何调用这些函数。
实现步骤:
1. 定义工具(Tool Schema)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
}
]2. LLM决定调用
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "北京今天天气如何?"}],
tools=tools
)
# LLM返回:
{
"tool_calls": [
{
"id": "call_123",
"function": {
"name": "get_weather",
"arguments": '{"location": "北京", "unit": "celsius"}'
}
}
]
}3. 执行工具并返回结果
# 执行天气查询
weather_data = query_weather_api("北京", "celsius")
# 将结果返回给LLM
second_response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "user", "content": "北京今天天气如何?"},
response.choices[0].message,
{
"role": "tool",
"tool_call_id": "call_123",
"content": json.dumps(weather_data)
}
]
)
# 最终答案
print(second_response.choices[0].message.content)
# "北京今天晴天,气温25°C,空气质量良好。"6.4 工具类型与应用场景
常见工具类型:
| 搜索引擎 | ||
| 计算器 | ||
| 时间工具 | ||
| API调用 | ||
| 代码解释器 | ||
| 数据库 | ||
| 文件操作 | ||
| 图像处理 |
工具为Agent带来的能力扩展:
核心智能(LLM)
↓
+ 搜索引擎 → 获取实时信息
+ 计算器 → 精确计算
+ 时间工具 → 日期处理
+ API调用 → 连接外部服务6.5 MCP(Model Context Protocol)与A2A(Agent-to-Agent)
MCP:单Agent调用工具
用户 → Travel Agent
↓
MCP/tool_call
↓
┌────┴────┬────────┐
↓ ↓ ↓
机票服务 酒店服务 天气服务
MCP Server MCP Server MCP Server
↓ ↓ ↓
机票信息 酒店信息 天气信息A2A:多Agent协作
用户 → Travel Agent
↓
A2A/发送任务
↓
┌────┴────┬────────┐
↓ ↓ ↓
机票Agent 酒店Agent 天气Agent
↓ ↓ ↓
└────┬────┴────────┘
↓
完整的行程计划对比:
• MCP:单个Agent通过标准协议调用外部工具 • A2A:多个Agent之间相互协作,每个Agent负责特定领域
6.6 工具调用的安全防护
安全挑战:
• 注入攻击:恶意用户尝试注入危险命令 • 权限滥用:Agent越权访问敏感数据 • 资源耗尽:无限循环调用工具
防护措施:
classSafeToolCaller:
def__init__(self):
self.allowed_tools = set(['search', 'calculator'])
self.rate_limiter = RateLimiter(max_calls=100, period=3600)
self.sanitizer = InputSanitizer()
asyncdefcall_tool(self, tool_name, params):
# 1. 权限检查
if tool_name notinself.allowed_tools:
raise PermissionError(f"Tool {tool_name} not allowed")
# 2. 速率限制
ifnotself.rate_limiter.allow():
raise RateLimitError("Too many requests")
# 3. 参数清洗
safe_params = self.sanitizer.sanitize(params)
# 4. 执行工具
try:
result = await execute_tool(tool_name, safe_params)
return result
except Exception as e:
logger.error(f"Tool execution failed: {e}")
raise最佳实践:
• 最小权限原则:只授予必要的工具访问权限 • 输入验证:严格校验所有输入参数 • 超时控制:防止无限循环 • 审计日志:记录所有工具调用 • 沙箱环境:隔离执行危险操作
6.7 工具调用性能优化
挑战:工具调用是Agent性能瓶颈之一
• 网络延迟 • 多次LLM调用成本 • 工具执行时间
优化策略:
1. 批量调用
# 低效:逐个调用
for item in items:
result = search(item)
# 高效:批量调用
results = batch_search(items)2. 并行执行
# 使用asyncio并行
tasks = [
search_flight(departure),
search_hotel(destination),
get_weather(destination)
]
results = await asyncio.gather(*tasks)3. 缓存机制
@cache(ttl=3600) # 缓存1小时
defget_weather(location):
return api_call(location)4. 懒加载
# 仅在需要时调用工具
if user_asks_about_weather:
weather = get_weather()7. 主流框架对决:LangGraph vs AutoGen vs CrewAI
7.1 三大框架定位对比
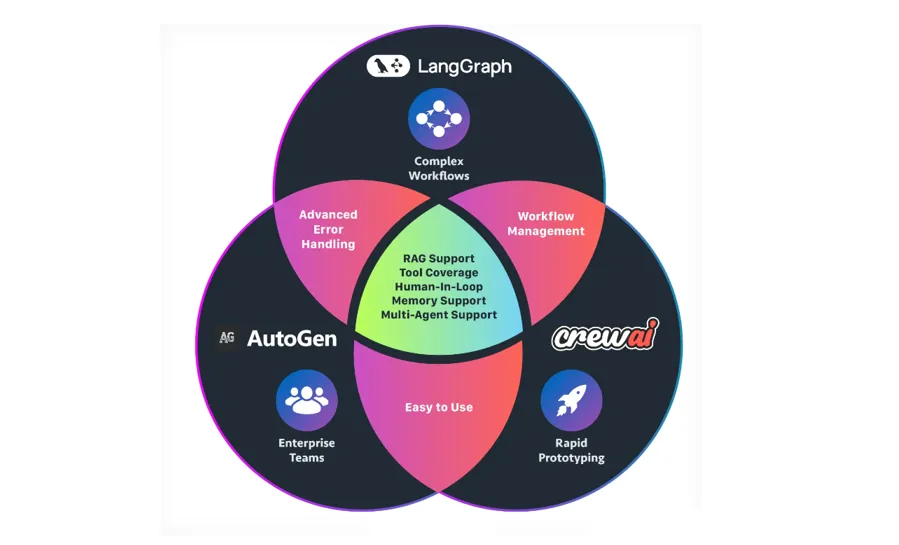
框架对比总览:
| 核心理念 | |||
| 适用场景 | |||
| 学习曲线 | |||
| 流程控制 | |||
| 多Agent支持 | |||
| 状态管理 | |||
| 企业采用 |
7.2 LangGraph:图结构工作流编排
核心特点:
• 基于图结构:将Agent执行流程框定为"流程图" • 确定性工作流:执行路径透明可控 • 状态持久化:支持检查点(Checkpointing) • 流式处理:实时输出结果 • HITL(Human-in-the-Loop):支持人工干预
适用场景:
• 复杂生产级应用 • 需要精确流程控制的场景 • 多步骤决策链
代码示例:
from langgraph.graph import StateGraph, END
# 定义状态
classAgentState(TypedDict):
messages: list
current_step: str
# 创建图
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("research", research_agent)
workflow.add_node("analyze", analyze_agent)
workflow.add_node("write", write_agent)
# 设置入口
workflow.set_entry_point("research")
# 添加边
workflow.add_edge("research", "analyze")
workflow.add_edge("analyze", "write")
workflow.add_edge("write", END)
# 编译
app = workflow.compile()
# 执行
result = app.invoke({"messages": ["研究AI趋势"]})优势:
• ✅ 流程可视化 • ✅ 易于调试 • ✅ 性能优化(已在大规模企业应用验证)
劣势:
• ❌ 学习成本高 • ❌ 灵活性相对较低
7.3 AutoGen:对话驱动的多Agent系统
核心特点:
• 对话为核心:Agent通过对话协作 • 代码生成与执行:侧重生成的代码并执行 • 跨语言支持:Python + .NET • 事件驱动:Actor模型 • 高度灵活:依赖LLM自主决策
适用场景:
• 软件开发(代码生成) • 复杂多智能体编码工作流 • 需要自然语言交互的场景
代码示例:
from autogen import ConversableAgent
# 创建Agent
coder = ConversableAgent(
name="Coder",
system_message="你是程序员,负责写代码"
)
reviewer = ConversableAgent(
name="Reviewer",
system_message="你是代码审查员"
)
# 发起对话
coder.initiate_chat(
reviewer,
message="请帮我写一个快速排序算法"
)优势:
• ✅ 代码生成能力强 • ✅ 对话自然流畅 • ✅ 微软生态支持
劣势:
• ❌ 随机性高(依赖LLM决策) • ❌ 流程不易控制
7.4 CrewAI:角色化Agent团队
核心特点:
• 角色驱动:每个Agent扮演特定角色 • 任务链设计:内置任务传递机制 • 模板化:提供可视化工作流模板 • 易用性:非技术人员也可快速上手 • 团队协作:强调Agent间的合作
适用场景:
• 内容创作 • 模拟复杂组织任务 • 快速原型设计
代码示例:
from crewai import Agent, Task, Crew
# 定义角色
researcher = Agent(
role='研究员',
goal='深入研究主题',
backstory='你是资深研究员',
verbose=True
)
writer = Agent(
role='作家',
goal='撰写高质量文章',
backstory='你是优秀作家'
)
# 定义任务
task1 = Task(
description='研究AI趋势',
agent=researcher
)
task2 = Task(
description='撰写报告',
agent=writer
)
# 创建团队
crew = Crew(
agents=[researcher, writer],
tasks=[task1, task2],
verbose=2
)
# 执行
result = crew.kickoff()优势:
• ✅ 直观易用 • ✅ 角色分工清晰 • ✅ 快速构建demo
劣势:
• ❌ 复杂场景控制力较弱 • ❌ 默认顺序执行
7.5 框架选择指南
根据场景选择:
软件开发 → AutoGen
• 代码生成和复杂多智能体编码工作流表现卓越
复杂工作流 → LangGraph
• 需要精确流程控制、状态管理
快速原型 → CrewAI
• 非技术人员友好、快速验证想法
新手入门 → OpenAI Swarm / CrewAI
• 操作简单,无需复杂设置
生产级应用 → LangGraph
• 已在大型企业验证
混合使用:
"大多数组织会组合使用多个框架"
8. Google ADK与OpenAI Agents SDK:巨头入局
8.1 Google Agent Development Kit (ADK)
发布时间:2025年
定位:灵活、模块化且模型无关的智能体开发套件
核心特性:
• 事件驱动架构:构建有状态AI Agent • 模块化设计:可插拔组件 • 优化Gemini:虽然模型无关,但针对Google生态优化 • 可视化界面:类似AutoGen Studio的工具 • 部署管理:内置部署和评估工具
架构组件:
ADK核心组件:
├── Agent(智能体)
│ └── 自包含执行单元
├── Tools(工具)
│ ├── 搜索工具
│ ├── MCP工具
│ └── 自定义工具
├── Memory(记忆)
│ ├── 短期记忆
│ └── 长期记忆
├── Orchestrator(编排器)
│ └── 任务调度
└── Evaluator(评估器)
└── 质量评估代码示例:
from google.adk import Agent
# 创建Agent
agent = Agent(
name="ResearchAgent",
model="gemini-pro",
tools=["search", "code_interpreter"],
memory=True
)
# 定义工作流
@agent.task
defresearch_topic(topic: str):
"""研究指定主题"""
results = agent.search(topic)
analysis = agent.analyze(results)
return analysis
# 执行
result = agent.run(research_topic("AI Agent趋势"))优势:
• ✅ Google生态整合(Gemini、Cloud) • ✅ 企业级特性(安全、合规) • ✅ 强大的工具链
劣势:
• ❌ 相对较新,社区较小 • ❌ 对Google生态依赖
8.2 OpenAI Agents SDK
发布时间:2025年3月
定位:轻量级、易用的多Agent工作流框架,是实验性Swarm的生产就绪升级版
核心特性:
• 极简抽象:很少的抽象层,易于理解 • Provider-agnostic:支持OpenAI Responses API及其他模型 • 内置追踪:Tracing功能 • Guardrails:安全防护 • 多Agent工作流:轻量级多Agent编排
代码示例:
from agents import Agent, Runner
# 创建Agent
agent = Agent(
name="Assistant",
instructions="你是有帮助的助手"
)
# 运行
result = Runner.run_sync(
agent,
"帮我写一首诗"
)
print(result.final_output)多Agent示例:
from agents import Agent, Runner
# 定义多个Agent
researcher = Agent(name="Researcher")
writer = Agent(name="Writer")
editor = Agent(name="Editor")
# 创建工作流
asyncdefworkflow(query: str):
research_result = await Runner.run(researcher, query)
draft = await Runner.run(writer, research_result)
final = await Runner.run(editor, draft)
return final
result = asyncio.run(workflow("AI发展趋势"))优势:
• ✅ 轻量级,学习成本低 • ✅ OpenAI官方支持 • ✅ 与OpenAI生态深度整合
劣势:
• ❌ 功能相对简单 • ❌ 主要面向Python开发者
8.3 巨头框架对比
| 背后公司 | |||
| 模型支持 | |||
| 抽象层级 | |||
| 可视化 | |||
| 企业特性 | |||
| 社区规模 |
选择建议:
• 使用Gemini → Google ADK • 使用OpenAI → OpenAI Agents SDK • 需要复杂工作流 → LangGraph • 快速原型 → OpenAI Agents SDK / CrewAI
9. Multi-Agent系统:团队协作的力量
9.1 什么是Multi-Agent System(MAS)
定义:Multi-Agent System(MAS)是由多个智能体组成的集合。这些Agent各自具备一定的智能和自主性,并处理各自擅长的领域,通过相互交互与协作来共同完成复杂任务。
核心概念:
• 多Agent协同:多个 specialized AI agents 共同工作 • 任务分发:将复杂问题分解给不同Agent • 协作机制:Agent间通信与协调
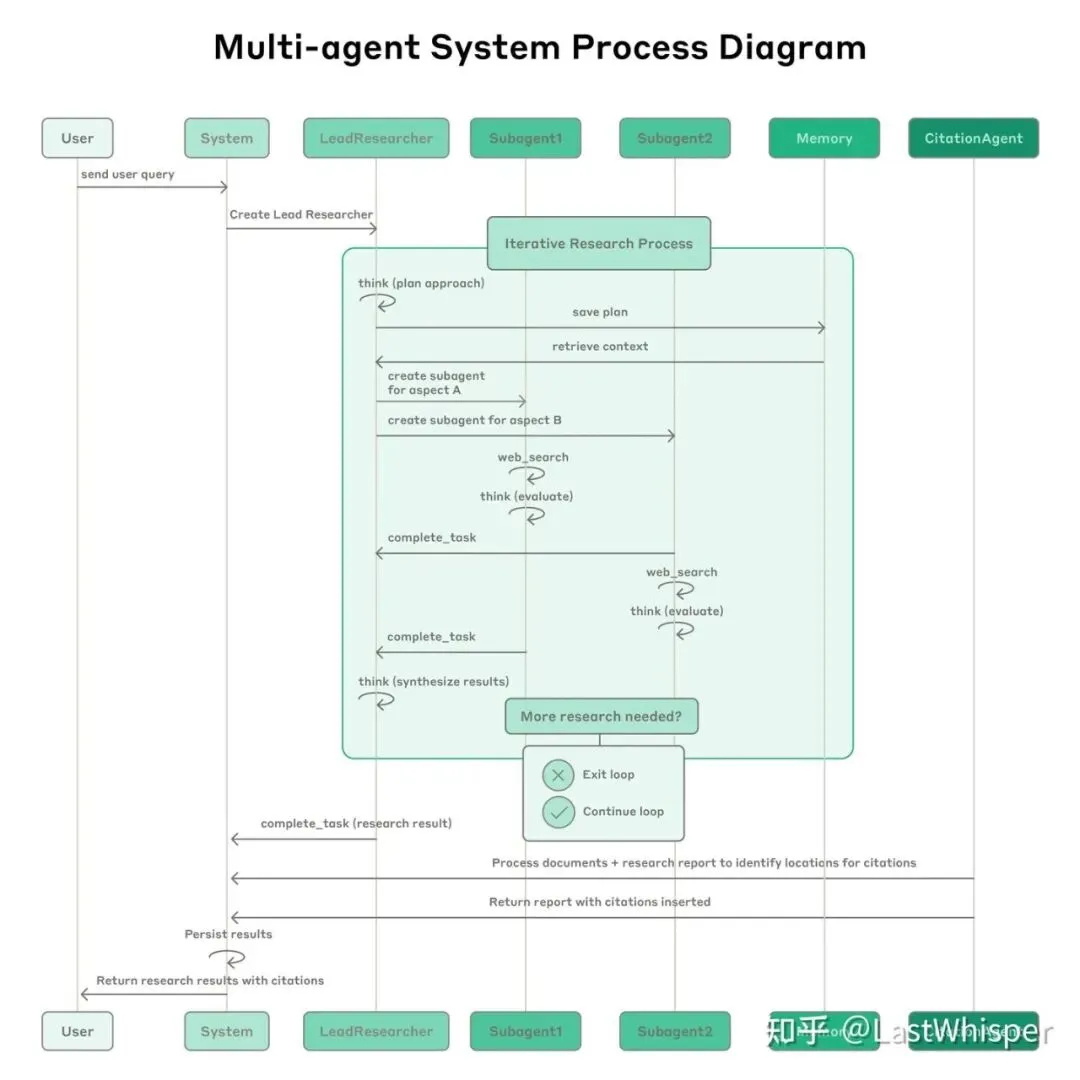
9.2 Multi-Agent架构模式
1. 集中式编排(Orchestrator Pattern)
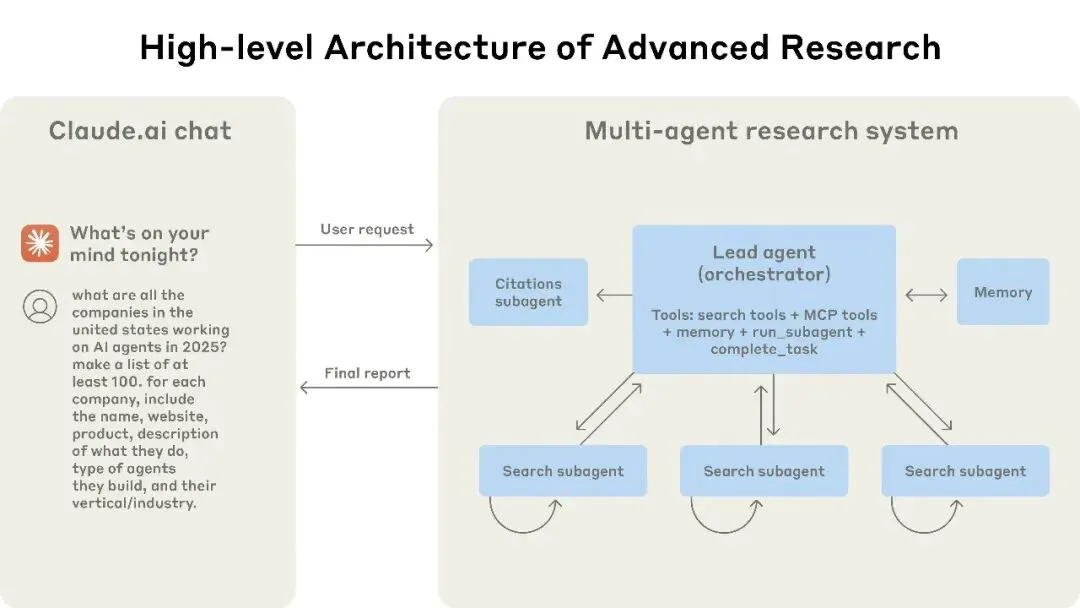
多Agent研究系统:
用户请求
↓
Lead Agent (Orchestrator)
├─ Citations Subagent
├─ Search Subagent 1
├─ Search Subagent 2
└─ Search Subagent 3
↓
最终报告工作流程:
1. Lead Agent接收任务
2. 分解为子任务
3. 分发给 specialized subagents
4. 收集结果
5. 整合输出2. 去中心化协作(Decentralized Collaboration)
Agent间直接通信:
Agent A ←→ Agent B
↓ ↓
Agent C ←→ Agent D优势:
• 更灵活 • 容错性强 • 扩展性好
3. 层次化结构(Hierarchical)
Manager Agent
/ | \
Team A Team B Team C
/ \ / \ / \
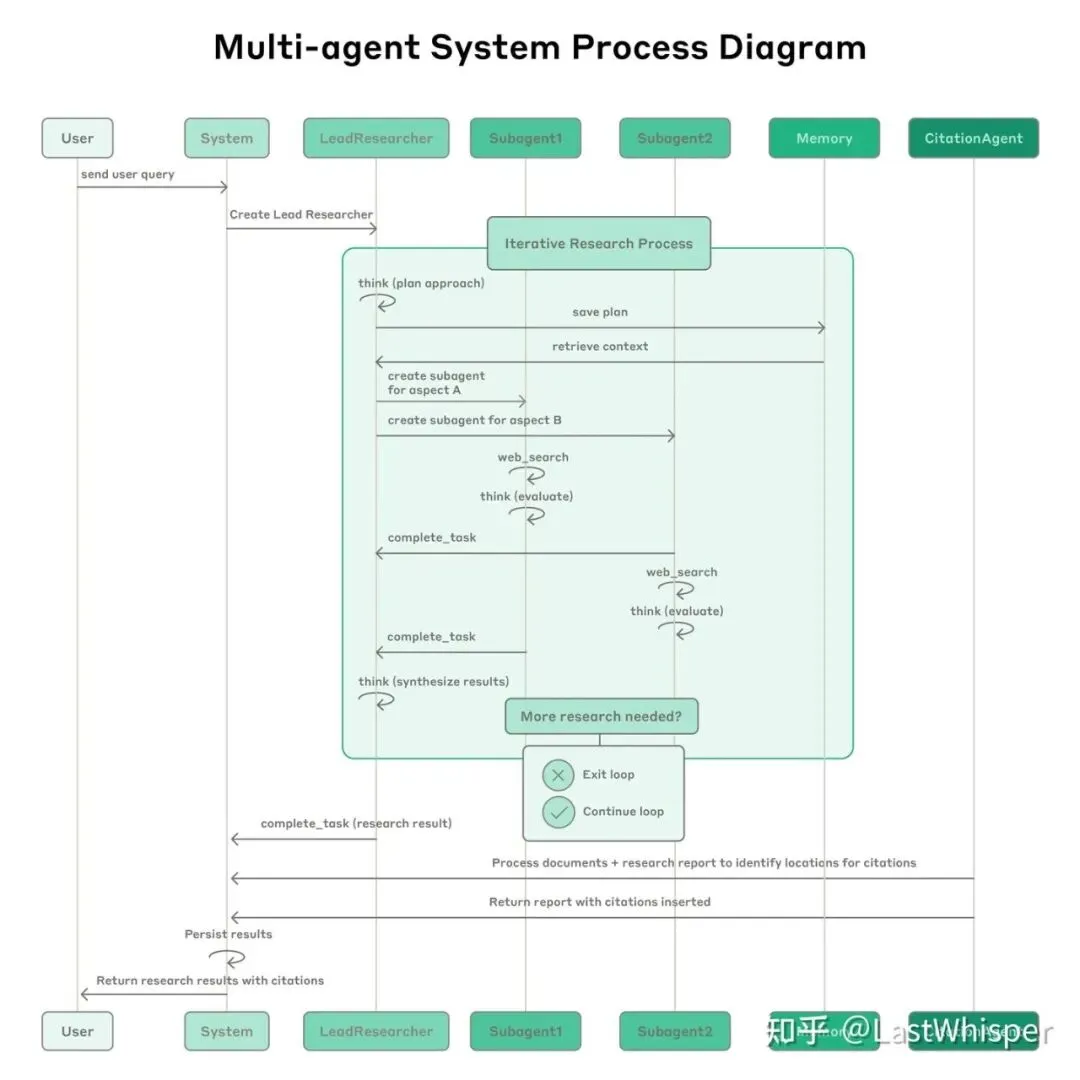
A1 A2 B1 B2 C1 C29.3 Multi-Agent协作流程
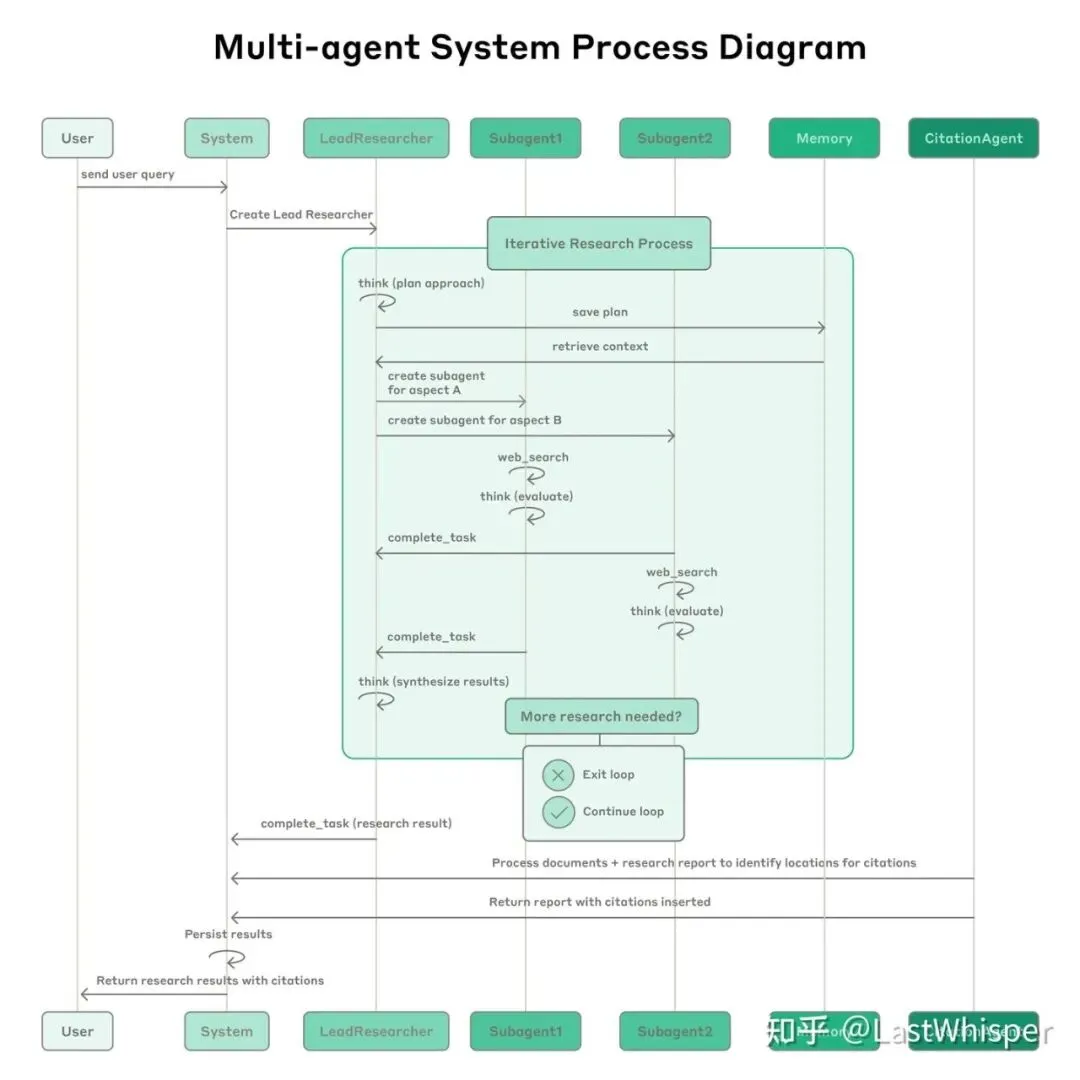
典型流程:
User → System → LeadResearcher
↓
创建Lead Researcher
↓
迭代研究过程:
1. think (plan approach)
2. save plan → Memory
3. retrieve context
4. create subagent for aspect A
5. create subagent for aspect B
6. web_search
7. think (evaluate)
8. complete_task
9. 更多研究需要?
- No → Exit loop
- Yes → Continue loop
↓
处理文档 + 插入引用
↓
返回最终报告9.4 多Agent通信协议
通信方式:
• 直接消息:Agent A → Agent B • 广播:Agent → All Agents • 发布-订阅:Pub/Sub模式 • 共享内存:Shared Memory
消息格式:
{
"from":"researcher_agent",
"to":"writer_agent",
"type":"task_assignment",
"content":{
"task":"撰写报告",
"data":{...},
"deadline":"2026-03-10"
},
"timestamp":"2026-03-07T10:00:00Z"
}9.5 Multi-Agent应用场景
1. 复杂研究任务
Lead Agent
├─ Data Collector Agent(数据收集)
├─ Analyst Agent(数据分析)
├─ Writer Agent(撰写报告)
└─ Reviewer Agent(质量审查)2. 软件开发
Product Manager Agent
├─ Architect Agent(架构设计)
├─ Developer Agent(编码)
├─ Tester Agent(测试)
└─ DevOps Agent(部署)3. 客户服务
Customer Service Orchestrator
├─ Greeting Agent(问候)
├─ Problem Diagnosis Agent(问题诊断)
├─ Solution Agent(解决方案)
└─ Escalation Agent(升级处理)9.6 Multi-Agent的优势与挑战
优势:
• ✅ 专业化:每个Agent专注特定领域 • ✅ 并发性:多任务并行处理 • ✅ 可扩展性:易于添加新Agent • ✅ 容错性:单点故障不影响整体 • ✅ 灵活性:动态调整团队结构
挑战:
• ❌ 协调复杂性:Agent间协调成本高 • ❌ 通信开销:消息传递延迟 • ❌ 一致性保证:分布式状态管理 • ❌ 调试困难:多Agent交互难以追踪
最佳实践:
1. 明确角色分工:每个Agent职责清晰 2. 定义通信协议:标准化消息格式 3. 引入Orchestrator:复杂任务需要协调者 4. 监控与日志:全面追踪Agent行为 5. 性能优化:减少不必要的通信
10. 应用场景全景:100+实战案例
10.1 客户服务
核心场景:
• 智能客服7×24小时响应:自动处理80%常见咨询 • 个性化推荐:基于用户历史行为精准推荐 • 投诉处理自动化:自动分类、升级、跟踪
落地案例:
某电商平台客服Agent:
- 日均处理咨询:50万+
- 人工介入率:从35%降至8%
- 用户满意度:提升23%
- 客服成本:降低60%10.2 销售与营销
核心场景:
• 线索评分与培育:自动评估线索质量,个性化跟进 • 内容生成与营销自动化:批量生成营销文案、邮件、社媒内容 • 销售预测:基于历史数据预测成交概率
落地案例:
某SaaS公司营销Agent:
- 邮件打开率:提升45%
- 线索转化率:提升2.3倍
- 内容生产效率:提升10倍
- A/B测试周期:从2周缩短至2天10.3 研发与生产
核心场景:
• 代码生成与审查:自动编写单元测试、代码审查建议 • 自动化测试:生成测试用例、执行回归测试 • 生产流程优化:实时监控、异常预警、自动调优
落地案例:
某科技公司研发Agent:
- 代码审查效率:提升5倍
- Bug发现率:提前30%
- 测试覆盖率:从65%提升至92%
- 发布周期:从2周缩短至3天10.4 财务与会计
核心场景:
• 发票处理:OCR识别+自动入账+异常检测 • 财务报表生成:自动汇总、分析、可视化 • 风险评估:实时监控现金流、预警风险
落地案例:
某制造企业财务Agent:
- 发票处理时间:从3天缩短至2小时
- 报表生成效率:提升8倍
- 风险预警准确率:95%+
- 合规审计成本:降低40%10.5 人力资源
核心场景:
• 简历筛选:自动匹配岗位需求,初筛候选人 • 员工培训:个性化学习路径推荐 • 绩效评估:多维度数据分析,生成评估报告
落地案例:
某互联网公司HR Agent:
- 简历筛选效率:提升15倍
- 候选人匹配度:提升35%
- 培训完成率:从58%提升至89%
- 员工满意度:提升28%10.6 医疗健康
核心场景:
• 临床决策支持:辅助诊断、治疗方案推荐 • 远程患者监测:实时分析健康数据,预警异常 • 药物研发:加速靶点发现、分子筛选
落地案例:
某医院临床辅助Agent:
- 诊断建议准确率:92%
- 预警响应时间:从小时级缩短至分钟级
- 医生工作效率:提升40%
- 患者等待时间:减少50%11. 企业级落地:从POC到规模化部署
11.1 落地路径
? POC验证(2-4周)
├─ 选择高价值、低风险场景
├─ 快速验证技术可行性
└─ 量化预期收益
? Pilot试点(1-3月)
├─ 小范围业务部门试用
├─ 收集反馈、迭代优化
└─ 建立运营指标体系
? 规模化部署(3-6月)
├─ 跨部门推广
├─ 建立Agent运营团队
└─ 持续优化与扩展11.2 关键成功因素
1. 业务流程梳理
• 识别可自动化的环节 • 明确人机协作边界 • 设计异常处理机制
2. 数据基础建设
• 确保数据质量与完整性 • 建立向量数据库支持语义检索 • 实现数据安全与隐私保护
3. 组织变革管理
• 培训员工适应新工作模式 • 建立Agent运营与监控体系 • 设计合理的绩效评估机制
11.3 案例研究
阿里云多智能体实践:
场景:电商大促智能运营
架构:
- 流量预测Agent
- 库存调度Agent
- 客服分流Agent
- 风控监控Agent
效果:
- 大促期间系统稳定性:99.99%
- 客服响应速度:提升3倍
- 库存周转率:提升25%
- 人力成本:节省40%51Talk教育应用:
场景:个性化英语教学
架构:
- 学情分析Agent
- 内容推荐Agent
- 互动练习Agent
- 进度跟踪Agent
效果:
- 学生学习时长:提升60%
- 知识点掌握率:提升35%
- 教师备课效率:提升5倍
- 用户续费率:提升22%哈啰出行场景:
场景:智能调度与客服
架构:
- 需求预测Agent
- 车辆调度Agent
- 异常处理Agent
- 用户服务Agent
效果:
- 车辆利用率:提升18%
- 用户等待时间:减少30%
- 客服工单量:降低45%
- 运营效率:提升2.1倍12. 性能优化与成本控制
12.1 性能优化
1. Prompt压缩
# 原始prompt(2000 tokens)
prompt = "你是一个专业的客服助手,请根据以下用户问题...[大量上下文]...请给出专业回答"
# 优化后(500 tokens)
prompt = compress_prompt(
original=prompt,
keep_keys=["用户问题", "关键上下文", "输出格式"],
max_tokens=500
)2. 缓存策略
# 语义缓存:相似问题直接返回历史答案
@semantic_cache(similarity_threshold=0.95)
defanswer_question(question: str):
return llm.generate(question)
# 结果:重复问题响应时间从3s降至50ms3. 智能路由
defroute_request(request):
if is_simple_query(request):
return small_model.generate(request) # 低成本
elif needs_reasoning(request):
return large_model.generate(request) # 高能力
else:
return medium_model.generate(request) # 平衡4. 批量处理
# 串行:10个请求 × 2s = 20s
for req in requests:
result = llm.generate(req)
# 并行:10个请求 × 2s = 2s(并发)
results = await asyncio.gather(
*[llm.generate(req) for req in requests]
)12.2 成本控制
1. 模型选择策略
? 成本对比(每1000 tokens):
- GPT-4o: $0.005
- GPT-4o-mini: $0.00015 ← 性价比首选
- Claude 3.5 Sonnet: $0.003
- 开源模型(本地部署): $0.0001
? 策略:
- 简单任务 → 小模型/开源模型
- 复杂推理 → 大模型
- 高频调用 → 本地部署+缓存2. Token优化
# 减少冗余输出
response = llm.generate(
prompt,
max_tokens=500, # 限制输出长度
stop=["\n\n"], # 提前终止
temperature=0# 减少随机性
)
# 结构化输出便于解析
response = llm.generate(
prompt + "\n请以JSON格式输出",
response_format={"type": "json_object"}
)3. 资源调度
# 动态扩缩容
classAgentPool:
def__init__(self, min_instances=2, max_instances=20):
self.pool = []
self.metrics = MetricsCollector()
defscale(self):
qps = self.metrics.get_qps()
if qps > 100andlen(self.pool) < self.max_instances:
self.add_instance() # 扩容
elif qps < 10andlen(self.pool) > self.min_instances:
self.remove_instance() # 缩容12.3 监控与评估
关键指标:
? 性能指标:
- 响应时间(P50/P95/P99)
- 任务完成率
- 工具调用成功率
- 记忆检索准确率
? 成本指标:
- Token消耗/请求
- 模型调用成本/任务
- 缓存命中率
- 资源利用率
⭐ 质量指标:
- 用户满意度(CSAT)
- 任务完成质量评分
- 人工干预率
- 错误率/重试率监控看板示例:
?️ Agent运营大屏:
┌─────────────────────────┐
│ ? 实时QPS: 1,245 │
│ ⏱️ 平均响应: 1.2s │
│ ✅ 任务成功率: 98.3% │
│ ? 今日成本: $127.50 │
│ ? 活跃用户: 3,421 │
└─────────────────────────┘13. 2026十大发展趋势
? 趋势1:长期自主性突破
• Agent能够持续运行数月甚至数年 • 跨任务记忆保持与迁移学习成为标配 • 自主目标设定与长期规划能力成熟
? 趋势2:多Agent协同普及
• 团队协作模式成为复杂任务首选 • Agent间通信协议标准化(A2A) • 动态组队与角色分配自动化
? 趋势3:企业级规模化部署
• 从试点项目转向核心业务流程 • Agent运营团队成为企业标配 • ROI可量化,投资回报周期缩短至6个月内
? 趋势4:协议标准化
• MCP(Model Context Protocol)成为工具调用标准 • A2A(Agent-to-Agent)协议统一多智能体通信 • 评估基准与测试框架行业共识
? 趋势5:成本优化
• 模型价格持续下降,同等能力成本降低10倍 • 本地小模型+云端大模型混合架构普及 • 缓存、压缩、路由等优化技术成熟
? 趋势6:人机协作深化
• Human-in-the-Loop成为关键场景标配 • 人工干预点智能化识别与触发 • 协作界面从"对话"进化为"协同工作台"
? 趋势7:生态系统演化
• Agent工具市场繁荣,即插即用组件丰富 • 低代码/无代码平台降低开发门槛 • 开源社区与商业产品协同发展
? 趋势8:治理框架建立
• 安全、合规、可解释性成为刚需 • Agent行为审计与追溯机制完善 • 行业监管政策逐步落地
? 趋势9:物理实体融合
• Agent+机器人实现"大脑+身体"结合 • 智能家居、智能制造、自动驾驶场景突破 • 多模态感知与执行能力大幅提升
? 趋势10:新职业诞生
• "AI智能体运营工程师"成为高价值岗位 • Agent提示工程师、记忆设计师等新角色涌现 • 人机协作培训师需求激增