


如需报告请联系客服或扫码获取更多报告
一、背景和意义概述
1.1 背景
在科技竞争日益激烈的国际大背景下,以构建自主可控的 AI 芯片及其软件生态战略为指引,我国 AI 芯片近些年在技术创新与市场拓展方面均收获颇丰。以华为昇腾、寒武纪、地平线、沐曦、燧原科技、海光信息、壁仞科技、摩尔线程及天数智芯等为代表的一批本土企业,已成功推出一系列具有市场竞争力的 AI 芯片产品,在国内市场形成了多厂商、多技术路线并行的活跃竞争格局。
随着国产 AI 芯片在算力、能效比等硬件指标上的突破,用户关注点已从“有没有”转向“好不好”——即软件生态的成熟度、兼容性与易用性。这里的“好不好”,其核心指向的已不再仅仅是芯片的理论峰值性能,而是其背后支撑的软件生态是否成熟、完善与开放。
一个成熟的软件生态,是决定芯片价值能否充分释放的关键。它体现在很多方面,包括基础软件栈的完备性与稳定性、算子库的丰富度与高性能实现、编译工具链的智能化与高效性、以及对 PyTorch 等业界主流 AI 框架的无缝兼容与深度适配能力、开发社区的活跃度等。对于广大的 AI 开发者和企业用户而言,一个完善的软件生态意味着其现有的 AI 应用、算法模型与开发工作流,能够以极低的迁移成本、甚至实现“无感”地部署到新的国产硬件平台上,从而避免大规模的代码重构和漫长的适配调试周期。因此,软件生态的构建水平,不仅是衡量国产 AI 芯片核心竞争力的关键标尺,更直接决定了其商业化落地的广度、深度以及最终能否赢得用户信任与市场份额。
1.2 目的和意义
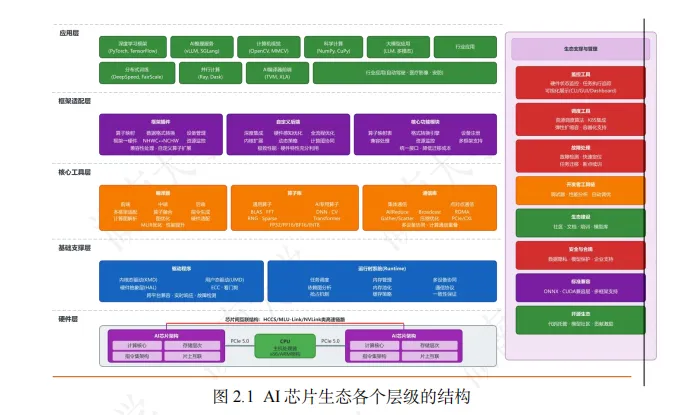
本白皮书的核心目的在于系统性地梳理和评估国产 AI 芯片软件生态的发展现状,为产业界、学术界及政府部门提供一份客观的技术参考与决策依据。AI 芯片软件生态主要由"四层架构"组成,包括基础支撑层、核心工具层、框架适配层与管理监控层,各模块通过"技术依赖-功能协同"形成闭环,共同作用于 AI 模型的训练与推理过程。然而,不同厂商在生态建设上呈现出显著差异:例如,华为昇腾通过自研软件栈,构建出一套完整的自主软件生态体系;摩尔线程通过高度对标NVIDIA CUDA 生态,实现了极高的兼容性。
二、AI 芯片软件生态核心组成与功能解析
AI 芯片软件生态是衔接硬件算力与上层应用的 “技术枢纽”,其本质是通过分层设计实现 “硬件能力抽象化、算力调用标准化、开发流程便捷化”。参考CPU(如飞腾)、AMD、英伟达等成熟软件生态的 “底层支撑 - 核心优化 - 上层适配 - 运维保障” 逻辑,AI 芯片软件生态可划分为基础支撑层、核心工具层、框架适配层与管理监控层四大模块。各模块通过 “技术依赖 - 功能协同” 形成闭环,共同作用于 AI 模型的训练与推理过程。
为了方便有一定 GPU 编程经验的读者理解,以下使用 NVIDIA 生态为例进行类比讲解一个任务在 GPU 上的处理流程。当用户在 PyTorch 中指定 NVIDIA GPU开始执行任务,流程从框架适配层开始:框架把高层算子映射到 cuDNN/cuBLAS等实现,并做必要的数据格式转换。接着进入核心工具层,编译器将计算图编译成PTX 或机器指令,并在需要时调用 NCCL 完成多卡通信。生成的指令再交由基础支撑层执行:CUDA Runtime 和 CUDA Driver 合作负责调度与显存管理,CUDA Driver 将上层指令翻译成可在 GPU 上运行的底层操作,并通过 GPU 的 ECC 硬件、Watchdog(超时检测)等机制保证稳定性。整个执行过程中,管理监控层通过nvidia-smi/NVML 监控状态,Kubernetes 分配 GPU 资源,驱动在异常时进行隔离与恢复。四层协同完成了从模型代码到 GPU 指令的转换与可靠执行。而对于 GPU编程经验较少、对 AI 芯片与 CPU 区别理解较少的读者,可以阅读“附录一 AI 芯片硬件基础:理解软件生态所‘指挥’的对象”进行了解。
2.1 基础支撑层:硬件算力的“翻译与调度中枢”
基础支撑层是 AI 芯片软件生态的“地基”,负责把底层硬件算力翻译为上层可用的形式,并对资源进行底层调度。它主要包括芯片驱动、底层库和系统运行时等组件,相当于 AI 芯片的操作系统。
在这一层,软件通过抽象硬件复杂性,让上层开发者无需直接处理寄存器、DMA 等细节。例如,摩尔线程的 MUSA SDK 提供了底层编译器和运行时库,屏蔽了 GPU 硬件细节,开发者可以像使用 CUDA 那样调用 GPU 加速计算。又如,华为昇腾提供的 CANN (Compute Architecture for Neural Networks) 就包含基础支撑层部分,这一部分封装了昇腾 AI 处理器的指令集和算子,实现对硬件的抽象和使能,并已全面开源以方便开发者直接调度底层资源。
2.2 核心工具层:算力释放的“性能优化引擎”
核心工具层是 AI 芯片软件生态的“性能核心”,汇集各种让算力真正高效发挥的优化工具链。主要涵盖模型编译器、算子库、性能分析和调优工具等,它们相当于为芯片配备的“引擎和涡轮增压器”。这一层的首要组成是 AI 编译器/执行引擎:它负责将上层训练好的模型转换为适配芯片的高效执行方案,包括计算图优化、算子融合和指令调度[1]。
2.3 框架适配层:开发者友好的 “应用接口桥梁”
框架适配层是 AI 芯片软件生态与开发者之间的“最后一公里”,核心任务是让开发者在 不改变主流开发习惯 的前提下,把模型顺畅迁移到国产算力之上。其基本思路是:一方面,通过对 PyTorch、TensorFlow 等国际主流框架进行插件式适配或后端扩展,让这些框架可以直接在昇腾、寒武纪、摩尔线程等国产芯片上运行;另一方面,通过发展 PaddlePaddle、计图(Jittor)等国产深度学习框架和推理软件栈,从软件侧原生支持多家国产加速硬件,形成“国产软硬协同”的一体化方案。在这一层,生态建设的评价标准不仅要关注“能不能跑”,还要关注“迁移成本多高、性能损耗多大、开发体验是否一致”。
2.4 管理监控层:系统稳定的“运维保障屏障”
管理监控层是 AI 芯片软件生态中负责系统运行维护和资源管控的模块,充当整个平台稳定性的“保障屏障”。随着 AI 训练集群规模日益扩大、任务愈发繁杂,如何监控硬件状态并调度资源变得至关重要。
成熟的算力生态往往配套完善的监控和调度系统:例如,NVIDIA 提供了DCGM (数据中心 GPU 管理) 工具套件用于监控集群中 GPU 的利用率、温度、功耗等指标,并可以通过 Prometheus 等开源平台导出这些指标以实现集中监控[6]。在国产生态中,类似的运维能力也在构建中。如沐曦公司为其“曦云”系列 GPU 开发了 mx-smi 监控工具,可实时查询每块 GPU 的版本、温度、利用率、功耗等信息,并支持启停 GPU、固件升级等操作,功能上类似于 NVIDIA 的 nvidia-smi [7]。
三、国产 AI 芯片软件生态资源现状
3.1 国产 AI 芯片分类及代表性厂商
结合技术路线与核心应用场景,国产 AI 芯片当前已呈现出多元化的技术路径,大体可以按照主要承载的计算负载分为三类:一类是聚焦神经网络等智能算法的专用加速芯片,一类是同时服务于科学计算与智能计算的通用计算型芯片,一类是兼顾图形渲染与 AI 计算的图形计算型芯片。
其中,专用 AI 加速芯片以 NPU(神经网络处理器)及面向云端训练/推理的数据专用架构(DSA)芯片为代表。此类芯片普遍摒弃传统图形流水线与大规模双精度单元,围绕矩阵运算、张量计算等神经网络核心算子进行深度硬件优化,从而在 AI 核心任务上实现更高的算力密度与能效比。代表厂商包括华为昇腾与寒武纪:前者依托“鲲鹏+昇腾”体系打造覆盖“云、边、端”的全场景 AI 基础设施,后者则通过思元 MLU 系列芯片构建云端推训一体及边缘推理产品矩阵,在大模型训练、推理及行业化落地方面积累了较强的技术与市场基础。同时,以燧原科技等为代表的云端 AI 训练/推理加速芯片厂商,同样属于该类,其采用针对 AI 工作负载深度定制的专用架构,在大型模型训练和高并发推理场景下追求极致的性价比与能效表现。
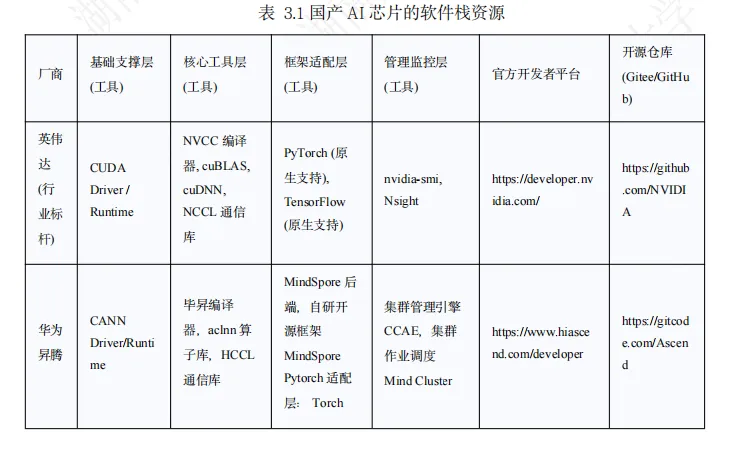
3.2 国产 AI 芯片软件生态各环节资源汇总与完善度对比
本节在第二章“四层架构”(基础支撑层、核心工具层、框架适配层、管理监控层)的基础上,对国产 AI 芯片的软件栈资源进行梳理和评价。
3.3 国产 AI 芯片软件社区活跃度对比数据表
本节旨在从“官方软件栈资料公开度”“开发者社区讨论活跃度”和“开源代码仓库活跃度”三个维度,对典型国产 AI 芯片生态与 NVIDIA CUDA 进行横向对比,为读者在选型时提供直观参考。这三个维度一方面反映厂商在文档、工具链和开源社区上的长期投入与贡献度,另一方面也体现开发者参与度和生态自发活力,从而帮助用户在性能指标之外,综合判断后续使用过程中的学习成本、问题排查效率以及生态可持续性。