



“超节点与Scale up网络行业:谷歌、AMD、国产超节点持续发力,打破英伟达独大格局”由东兴证券发布。
本报告共计:68页。完整版PDF电子版报告下载方式见文末。
超节点与Scale-up 网络是突破算力与通信瓶颈、支撑万亿级大模型与高实时性应用的关键基础设施。本篇超节点与Scale up 网络行业深度报告,详细研究英伟达、谷歌、AMD 以及华为四家头部AI 算力芯片厂商在此领域的布局进展以及各自优势。我们认为,超节点与Scale-up 网络正处于快速发展期,并将成为算力芯片、网络部件(PCB 板、交换芯片、光器件、高速铜缆)、存储部件、供电和散热设施部件等新兴技术的重要应用市场。

(1)英伟达:超节点领先优势建立在NVLink 和NVLink Switch。
在超节点技术方案上,英伟达处于领先优势。2024-2025年,英伟达陆续推出GH200 NVL72、GB200/ GB300 NVL72 等成熟超节点解决方案。根据大摩预测,2025 年英伟达GB200/300 NVL72 出货量约2800 台。展望2026-2027 年,英伟达计划推出Vera Rubin NVL144 和Rubin Ultra NVL576。互联GPU 数将从72 颗进一步向576 颗发展。届时,英伟达将发布新一代Kyber 机架,架构引入NVLink Switch Blade(NVLink 交换机刀片),通过PCB 中板替代传统5000+根有源铜缆。可以看到,Rubin Ultra NVL576 仍保持较强的工程创新能力。
英伟达超节点的优势建立在NVLink 和NVLink Switch。为实现AI 训练集群高带宽与低延迟数据传输,NVLink 重新设计通信架构,并引入一系列先进技术,包括网状拓扑、差分信号传输、流量调度信用机制、多Lane绑定技术、统一内存空间等。截止2025年,NVLink 5 Switch实现支持单GPU到GPU带宽1800GB/s,可构建72 GPU 的NVLink 域,总带宽达130 TB/s(双向),支持72 GPU 全互联通信。在后续计划中,NVSwitch Gen6 和Gen7 的GPU-to-GPU 通信带宽继续升级为3.6TB/s。
但另一方面,Scale up 网络兴起源于满足大模型分布式训练和推理中的张量并行(TP)与专家并行(EP)。目前AI 产业也在探索降低TP 与EP 规模的技术方案,从而降低Scale up 网络规模的上限。我们认为,Scale up 网络的发展空间或限制英伟达在超节点领域的领先优势。为保持领先优势,实现Scale up 网络和Scale out 网络融合或将成为英伟达超节点新的发展趋势。
(2)华为:对外开放灵衢互联协议,超节点性能追赶英伟达。
国内Scale Up 协议尚未统一,华为灵衢协议尚未被国内业界广泛接受。在Scale Up 协议方面,华为推出灵衢协议,并从2.0 版本起转向开放标准。除此之外,国内其他厂商正探索多种互联协议,包括中移OISA、腾讯ETH-X、高通量以太网ETH+以及中兴通讯OLink 等。为打破生态壁垒,国内正积极推动标准统一,比如工信部正牵头推动CLink 协议,旨在形成统一的国内标准。华为超节点依靠集群化方式实现性能追赶。Atlas 950 超节点预计2026 年第四季度发布,相比英伟达同样将在2026 年下半年上市的NVL144 总算力2.52 EFLOPS(FP8),其算力达到8 EFLOPS(FP8)。
此外,Atlas 950 超节点在内存容量1152TB 与互联带宽16.3PB/s,也实现大幅领先。我们认为,短期内,华为超节点依靠集群化实现性能追赶,但在超节点复杂性、可靠性、功耗等维度需要平衡。从整体解决方案看,英伟达在超节点的芯片工艺、软件生态与系统集成上的优势仍难以撼动。Atlas 950 超节点互联方案或将调整,显示华为超节点技术在标准化阶段仍需夯实。相比上一代超节点,华为Atlas 950 超节点不再使用全光互联架构,其通过“柜内正交铜互联+柜间光互联”的混合设计,在机柜 内部利用铜互联实现高可靠、低成本和低功耗的连接,跨机柜则通过光互联保障系统的可扩展性,从而在 维持系统可扩展性的同时,有效控制总体拥有成本(TCO)。
(3)谷歌:建立光互联超节点,与英伟达形成不对称竞争。
谷歌TPU 超节点建立成熟的光互联Scale up 网络。从技术成熟度看,2023-2025 年谷歌陆续推出TPU v4、TPU v5p、TPU v7 三代超节点,完成了技术路线探索和方案标准化。此外TPU v7 也获得外部企业认可。2026 年,Anthropic 将直接从博通采购近100 万颗TPU v7 Ironwood AI 芯片,本地部署在其控制的数据中心。2027 年,谷歌将推出第8 代TPU,对标Nvidia Vera Rubin。可以看到,届时谷歌TPU 超节点的性能指标进一步优化提升。谷歌TPU 超节点竞争优势建立在OCS 交换机,技术路线独树一帜。相比英伟达、华为、AMD 等超节点厂商,谷歌是全球首个将光电路交换机(OCS)大规模商用部署于Scale up 网络的企业,技术路线独树一帜。谷歌OCS 交换机,涉及精密光学、机械工程与半导体工艺的深度交叉应用,在光互联领域构筑一道高壁垒的技术护城河。
相较于电分组交换机,光电路交换技术具备诸多优势:光电路交换机可跨多代光收发模块技术复用、光电路交换机的每比特能耗较电分组交换机低数个数量级、光电路交换机引入的时延极小。OCS 交换机商用落地存在多重困难:光电路交换机需扩展至数百个端口以支撑足够数量NPU 互连;受限于光电路交换机的控制软件和反射镜配置时延,商用光电路交换机的交换时延通常为10~20 毫秒;为降低链路功率,光电路交换机插入损需要控制在理想水平。为搭建高性价比、大规模的光交换层,谷歌创新研发三大核心硬件组件:光电路交换机、波分复用光收发模块和光环形器。其中谷歌Palomar 光电路交换机的光学核心模块是实现光转向功能的MEMS 微反射镜;波分复用光收发模块是提升布线效率、支撑大规模且持续扩张数据中心的关键;光环形器是实现光电路交换机链路双向通信的核心器件,将所需的光电路交换机端口和光纤数量减半。
(4)AMD:UALink 成为重要开放标准,超节点有望成为英伟达有力竞品。
作为Scale up 网络开放技术路线方,UALink 成为重要标准。2025 年1.0 版本规范正式发布;2026 年,UALink 2.0 版本有望发布。我们认为,目前UALink 正处于从标准制定阶段走向产品落地阶段,预计UALink 生态将在2027 年迎来突破发展,被众多数据中心接纳。目前UALink 联盟受到业内广泛支持,截止2026 年1 月底,成员单位超过100 家,将成为英伟达NVLink 有利挑战方。AMD 超节点Helios 机架有望成为行业主流选择。Helios 机架采用双宽机架设计,宽度从1 个机架提升到2 个机架,在复杂性、可靠性和性能间实现良好平衡。从算力、内存、互联带宽等指标,MI455x 系列Helios 机柜是目前业界最能挑战英伟达的NVL72 机柜的竞品;而在功耗领域,对比GB200 NVL72 机柜,Helios 机架优势显著。此外,双宽结构为未来升级预留物理空间,例如可扩展至144GPU 配置,而无需重新设计机架基础设施。
幻影视界整理分享报告原文节选如下:










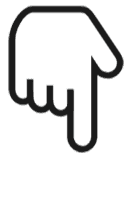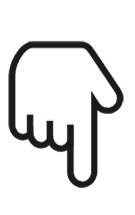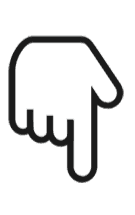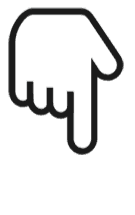 戳“阅读原文”下载报告。
戳“阅读原文”下载报告。