


多靶点mRNA药物序列设计的调研报告
绪论
在2020年之后,信使核糖核酸(mRNA)技术已完成从预防性疫苗向复杂治疗性药物的战略跨越。多靶点mRNA药物,即在单一制剂或单一转录本中整合多个抗原表位或功能蛋白的药物形式,已成为多价病毒疫苗、肿瘤免疫治疗及复杂代谢疾病领域的研发核心。与早期仅编码单一抗原的mRNA不同,多靶点设计要求在受限的物理空间内实现多个开放阅读框(ORF)的精确表达平衡、结构稳定性和免疫原性控制。这种复杂性促使序列设计从传统的基于经验的密码子替换,转向由AI驱动、计算生物学算法支撑的全局优化范式。
多靶点mRNA的设计挑战在于其序列长度通常超过常规转录本,这不仅增加了物理降解的风险,也对细胞翻译机器的持续性提出了更高要求。在多靶点设计中,研究者必须通过精密操纵编码区(CDS)、非翻译区(UTR)以及多聚腺苷酸尾部(poly(A) tail)的核苷酸序列,来规避细胞内天然免疫传感器的识别,并确保多个靶点蛋白的化学计量比符合预期治疗目标。
多靶点mRNA的分子架构设计策略
多顺反子构建机制与表达平衡
多顺反子mRNA设计是实现在单条转录本上表达多个独立蛋白的主流路径。在真核细胞翻译机制下,实现多基因表达主要依赖内含核糖体进入位点(IRES)和2A自剪切肽。这两种策略在序列设计上具有截然不同的逻辑。
IRES序列(如来源于EMCV病毒的IRESwt)通过在mRNA内部建立核糖体募集位点,允许翻译在不依赖5’帽子结构的情况下启动。研究表明,IRES的优势在于其不改变上下游蛋白质的一级结构,从而保持了蛋白的天然构象。然而,IRES介导的下游基因表达效率通常显著低于上游基因,通常仅为上游水平的10%至20%。这种不平衡性在需要等摩尔比表达的场景(如双特异性抗体的轻重链组装)中构成了技术障碍。此外,IRES序列长度通常超过500 bp,意味着载体可插入的目的基因长度不能太长,可能会增加载体构建和病毒包装的难度。
相比之下,2A肽(如P2A、T2A等)利用“核糖体跳跃”机制实现多蛋白产生。2A肽在翻译至甘氨酸与脯氨酸残基之间时,会诱导核糖体发生肽键形成失败,从而释放上游多肽并继续翻译下游序列。2A肽体积短小(18-25 aa),且能实现接近1:1的表达水平,因此在多靶点治疗设计中备受青睐。
下表对比了当前主流的多顺反子连接子性能:
在2A肽的选择上,研究数据指出P2A在人类细胞系及多种动物模型中具有最高的剪切效率,通常接近100%,其次是T2A。然而,2A肽的实际表现受上下游序列环境的影响显著,研究发现,在三基因多顺反子中,最接近启动子的ORF表达水平最高,第三个位置的ORF表达水平比第一个位置至少降低80%。此外,在某些应用中,若未经过序列优化,可能会产生未切割的融合蛋白产物,这类意外的融合蛋白可能引发预料之外的细胞毒性或免疫干扰。
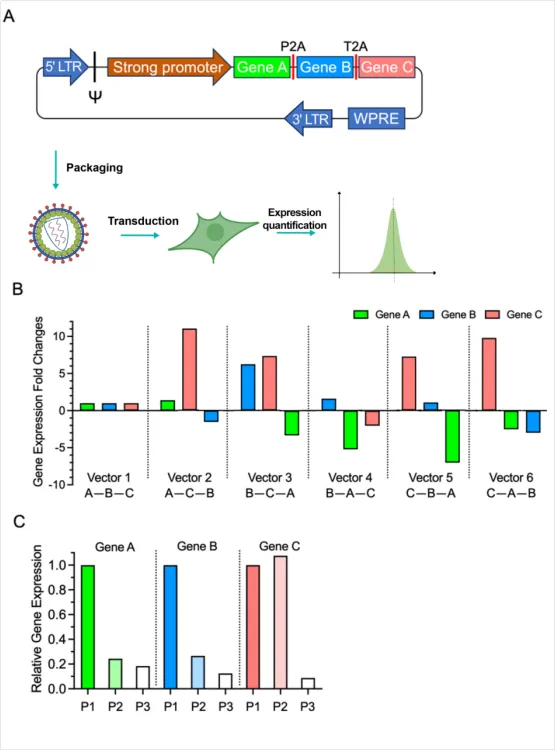
图1. 2A连接的多顺反子载体中位置依赖性基因表达水平的比较。(A)携带三个ORF且中间以P2A、T2A间隔的三个慢病毒载体被包装成慢病毒。哺乳动物细胞随后被转导,并通过流式细胞术评估三个ORF的所有六种排列模式中每个基因的表达。(B)这六种排列包括A-B-C、A-C-B、B-C-A、B-A-C、C-B-A和C-A-B。为了便于更直接的比较,我们将每个基因在任何给定排列中的表达水平与A-B-C顺序中的表达水平进行齐一化。(C)比较三顺反子载体中特定位置的蛋白表达水平。我们将不同位置的每个基因的表达水平齐一化为其在第一个位置的表达水平。
多表位串联与嵌合序列工程
在肿瘤免疫治疗中,多靶点mRNA通常以编码多个新抗原(Neoantigens)表位的形式存在。这种多表位设计要求序列能够同时激活CD4+和CD8+ T细胞反应。
典型的多表位串联mRNA序列由信号肽、多个新抗原序列(由Linker连接)、辅助佐剂序列及胞内转运信号组成。为了确保抗原片段能被有效加工并呈递,序列中必须整合特定的连接子(接头)。研究发现,AAY或GPGPG连接子能够通过优化蛋白酶体剪切位点,确保抗原片段的独立性并防止产生新的接头表位(Junction epitopes)。
此外,为了增强免疫应答,序列中常嵌入MHC-I类分子靶向结构域(MITD),这种特定的氨基酸序列能够引导合成的肽段进入内质网,从而显著提升MHC-I分子的负载效率。在序列设计阶段,通过添加分泌信号肽(如tPA信号肽),可以使翻译出的多肽被分泌至胞外,被抗原呈递细胞(APC)摄取,从而触发更广泛的免疫监测。
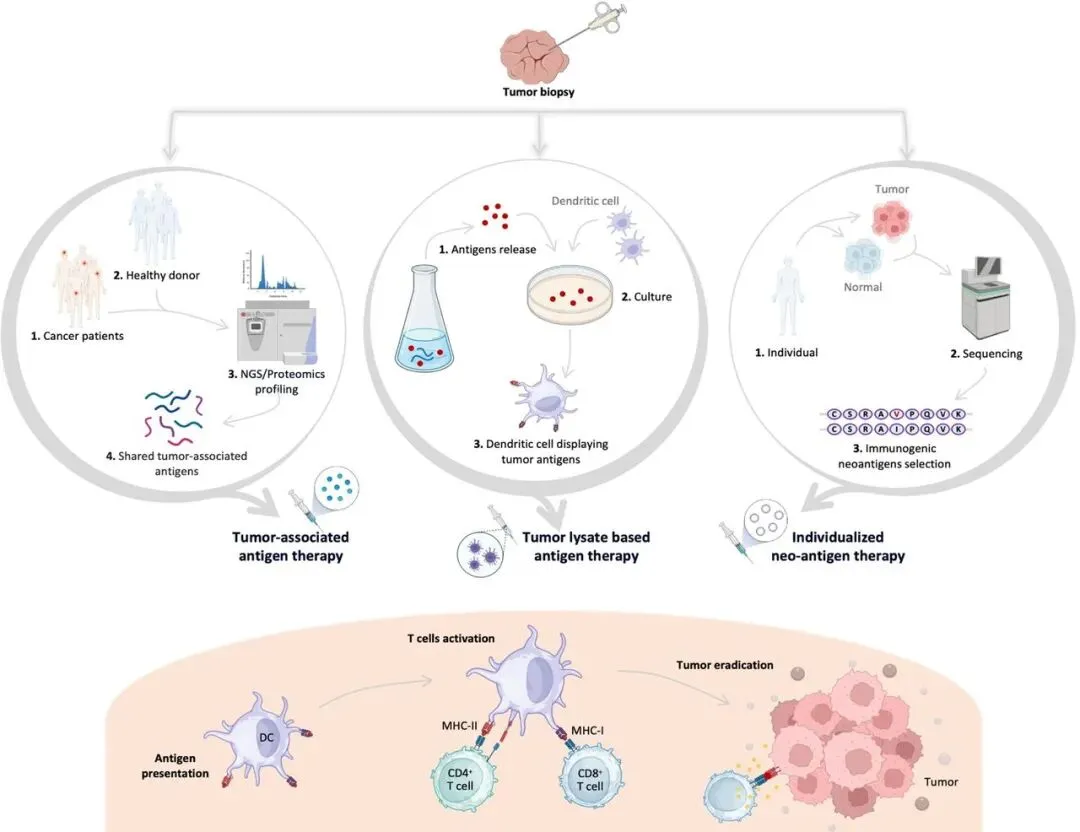
图2. 现成疫苗与个性化癌症疫苗抗原靶点比较图示[doi: 10.1136/jitc-2024-010569]
编码区(CDS)的in-silico优化
密码子优化的多维目标博弈
CDS的序列设计已不再是简单的同义密码子替换。现代算法(如mRNArchitect)通过在密码子自适应指数(CAI)、GC含量和二级结构稳定性之间寻找最优平衡点,来提升翻译效率。
GC含量的精确调控:较高的GC含量通常与mRNA的半衰期正相关,但过高的GC含量可能导致形成复杂的二级结构,阻碍核糖体的扫描与延伸。目前工业界的优化目标通常将GC含量控制在60%-70%之间。
尿苷消耗(uridine depletion):由于尿苷会被内源性Toll样受体(如TLR7)识别并引发炎症反应,通过同义替换尽可能减少U碱基含量,可以显著降低药物的免疫原性并延长表达时间。
翻译速度匹配:并非所有的密码子都应追求最快。在某些复杂多靶点蛋白中,需要特定的“慢密码子”来允许新生肽链进行正确的共翻译折叠,防止形成无功能的聚集体。
深度学习模型辅助设计
除了基于物理化学规律的模型外,基于大数据的深度学习模型(如RiboDecode和mRNABERT)正成为设计多靶点mRNA的新工具。RiboDecode通过直接学习大规模核糖体测序(Ribo-seq)数据,捕捉密码子选择与实际翻译负荷之间的复杂关系,而非依赖于预设的生物学规则。
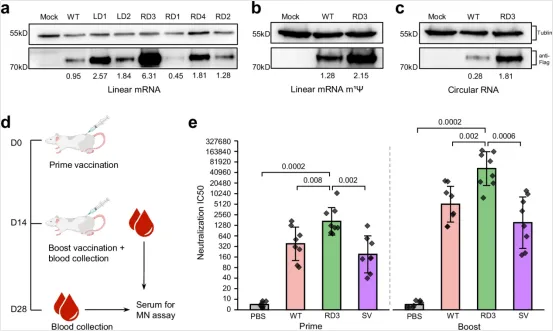
图3. 通过RiboDecode密码子优化实现更有效的mRNA流感疫苗
mRNABERT则采用了Transformer架构,在1800万条非冗余mRNA序列上进行预训练。该模型能够识别5’ UTR中的翻译启动效率特征、CDS中的翻译延伸障碍以及3’ UTR中的稳定性元件。在多靶点设计中,AI模型可以预测不同靶点序列串联后是否会产生预料之外的折叠模式或RBP(RNA结合蛋白)结合位点,从而在干靶实验前进行风险排除。
非翻译区(UTR)与末端调节工程
5’ UTR的精密扫描与启动优化
5’ UTR是翻译启动的关键调控区。在多靶点mRNA设计中,5’ UTR必须具备极高的核糖体募集能力。目前的研究重点在于优化Kozak序列及其周边环境,以确保第一个启动密码子(AUG)能被扫描复合体精准识别,然后启动翻译。
AI驱动的UTR筛选技术已能够识别出比天然珠蛋白UTR更高效的人工序列。这些人工UTR通过消除内部的二级结构,降低了核糖体扫描的障碍。同时,针对特定组织(如肝脏或肿瘤组织)的靶向性设计,通过在3’ UTR中嵌入特定的miRNA结合位点,可以实现多靶点mRNA在非靶组织中的表达沉默,从而降低脱靶毒性。
Poly(A)尾部的结构化与遗传稳定性
Poly(A)尾部在决定mRNA半衰期方面起着至关重要的作用。在多靶点药物的设计中,Poly(A)的稳定性是制造和药效的共同瓶颈。
分段式 Poly(A):传统的连续A重复序列(如A100)在质粒制备过程中极易发生重组和丢失。研究发现,通过插入非腺苷酸间隔子(如G、C或特定的6-10 nt序列),可以显著提高其在细菌培养中的遗传稳定性。RG2 变体性能分析:在多项对比实验中,名为RG2的变体(由60A-间隔子-55A组成的复杂分段结构)表现出优于工业标准A30-70的性能。RG2不仅在质粒传代中保持稳定,其驱动的蛋白质表达水平也显著高于传统的单一或简单分段设计[doi: 10.1016/j.omtn.2025.102809]。
RG2 (5′-60A-6 nt spacer-19A-G-19A-G-17A-3′) AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAGATATCAAAAAAAAAAAAAAAAAAAGAAAAAAAAAAAAAAAAAAAGAAAAAAAAAAAAAAAAA.
末端环状结构(Loop Structures):通过在Poly(A)尾部引入特定的茎环结构,可以阻碍去腺苷化酶的降解过程,从而将mRNA的胞内寿命延长数倍 。如Oh, A., 等人(npj Vaccines,2025)设计的A50L50LO Poly(A)尾。这种策略在需要持续产生治疗性蛋白(如细胞因子或激素)的多靶点疗法中具有重要价值。
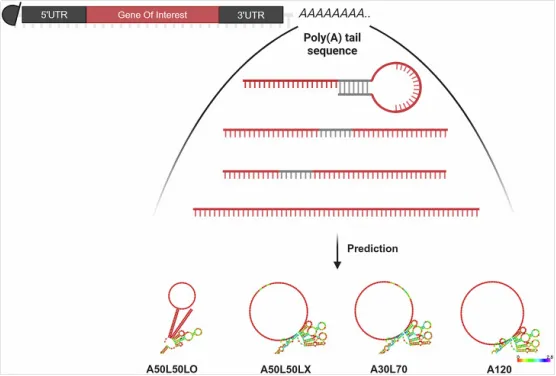
图4. mRNA-poly(A)结构[doi: 10.1038/s41541-025-01287-7]
免疫原性控制与安全性设计
化学修饰与序列设计的协同效应
为了实现多靶点mRNA的临床应用,必须解决其作为外源RNA引发的剧烈先天免疫反应。虽然N1-甲基假尿苷(N1m-ψ)的化学修饰已成为标准,但序列本身的优化同样关键。
设计中需严格避免长达33 bp以上的完全互补双链区域,因为此类结构是RIG-I和PKR等dsRNA传感器的强力激活剂。在多靶点串联设计中,不同抗原之间的连接区可能意外形成分子内双链。因此,在in silico分析阶段,必须使用计算工具预测全长mRNA的二级结构分布,并通过同义突变破坏潜在的长双链区。
组织特异性与脱靶风险预测
在肿瘤mRNA疫苗研究中,利用OmniNeo等计算框架,研究者可以整合转录组学和蛋白组学数据,对多靶点序列进行全方位的免疫原性评估。在设计抗癌mRNA疫苗时,管道会计算每个候选表位与自体蛋白的同源性,剔除可能诱导自身免疫反应的序列。
同时,通过免疫系统模拟器(UISS)等模拟平台,可以在序列设计阶段预测mRNA-LNP复合物进入人体后的生物分布及其在淋巴结、肝脏等器官中的抗原表达动态(但不一定很准确)。这种预测性设计能够显著缩短多靶点药物的从“序列到临床”的转化时间。
多靶点mRNA设计的前沿工具链
在过去三到五年中,一系列专门用于mRNA设计的软件工具矩阵已经形成,这些工具各具特色:
mRNArchitect:基于DNA Chisel框架,支持快速组装CDS、UTR和Poly(A),还特别强调制造约束的自动规避。LinearDesign:CDS密码子优化工具,核心优势在于结构稳定性优化和计算效率,适用于极长转录本。然而我们实际测评中,LinearDesign优化效果并不理想。
mRNAdesigner:集成了UTR筛选、GC平衡和密码子适应性的综合性Web工具。
OmniNeo:专注于多表位肿瘤疫苗的设计,涵盖了从突变鉴定到表位排序的全流程。
行业发展趋势与技术前瞻
从“静态”设计到“动态逻辑”设计
多靶点mRNA药物正向着智能化的方向演进。新兴的“多感觉”mRNA(Multi-sense mRNA)不仅编码治疗蛋白,还包含能感知细胞状态的逻辑门元件。通过在序列中整合miRNA反应元件或特定的核糖开关,多靶点mRNA可以实现“如果XX则(表达靶点A+B);否则(保持沉默)”的遗传逻辑。这种设计能有效解决多靶点疗法在复杂人体环境中的毒性管理问题。例如,Strand Therapeutics已开发出仅在特定细胞环境中激活翻译的遗传逻辑电路。Radar Therapeutics在mRNA设计中引入了调控开关,利用细胞自身的RNA编辑酶来驱动mRNA的细胞类型特异性翻译。在这些系统中,mRNA被设计成能够“感知”其自身输出或细胞环境,并在达到特定阈值时调节翻译。
自扩增mRNA(saRNA)在多靶点中的应用
saRNA通过编码病毒复制酶复合体(RdRp),实现在胞内的自我复制。在多靶点设计中,saRNA能够以极低的初始剂量提供持续且大量的抗原表达。然而,saRNA的设计挑战在于如何规避复制酶诱发的剧烈免疫干扰。目前的趋势是通过2A肽将RdRp与抗原序列进行精巧串联,或引入病毒免疫抑制蛋白来调节宿主反应。
总结:多靶点mRNA序列设计的核心准则
综合过去三至五年的研究进展,多靶点mRNA的序列设计应遵循以下核心准则:
分段式优化:针对不同的功能区域(CDS、UTR、PolyA)采用专门的算法,同时在全长水平进行结构冲突检查。
表达均衡化控制:优先选用剪切效率接近100%的P2A肽,并在关键组分之间通过调整UTR强度来实现翻译水平的精确配比。
结构强化与U消耗并重:利用密码子优化工具最大化MFE稳定性和CAI最优解,同时通过同义替换将尿苷含量降至最低。
数据驱动的验证:集成AI模型与高通量测序数据,在实验室合成前对序列的生物分布、翻译负荷和免疫风险进行深度模拟。
多靶点mRNA药物不仅是多种抗原的物理集合,更是高度集成的遗传信息处理系统。随着生物信息学、深度学习与RNA生物学的深度融合,序列设计将继续向着更稳定、更精准、更智能的方向发展,为人类战胜异质性极高的肿瘤及复杂感染性疾病提供核心技术支撑。