



当AI算力成为新时代的“石油”,争夺的焦点远不止于开采工具本身,更在于铺设输油管道、建造炼油厂乃至定义整个能源贸易的规则。
英伟达GTC大会的舞台上,黄仁勋再次举起一颗Blackwell架构的GPU,会场响起掌声。这颗芯片拥有2080亿个晶体管,其AI算力指标达到令人咋舌的20 petaflops。然而,真正令竞争对手感到窒息的,或许并非这个数字本身。
同一时间,北京的一家数据中心里,工程师们正在调试一台搭载了国产AI加速卡的服务器集群。他们的目标不是在这台集群上训练千亿参数的大模型,而是要将已有的数百个AI模型,以最优的能效和性价比部署上线,处理每天来自数亿用户的实时请求。
这两个场景,勾勒出当今全球算力竞赛的一体两面:一面是追求极致性能的“珠峰攀登”,另一面是解决实际需求的“普惠工程”。而连接这两面的,是一个正在从“一元垄断”走向“多极博弈”的复杂市场——算力加速卡。
01 霸权真相:英伟达构筑的“围墙花园”
要理解算力加速卡市场的博弈,必须首先剖析那座看似不可逾越的高墙——英伟达的垂直整合帝国。其统治地位远非仅靠硬件优势,而是一个由硬件、系统软件、平台软件和应用生态构成的、层层锁死的“围墙花园”。
第一层:硬件平台的持续代差英伟达通过其GPU架构的快速迭代(从Volta到Ampere,Hopper再到Blackwell)和 “GPU+NVLink+NVSwitch” 的系统级设计,始终在绝对算力和大规模互联能力上保持至少一代的领先。其整合HBM的先进封装能力,更是将内存墙推远,构建了强大的性能壁垒。
第二层:CUDA生态的“数字联邦”这是最核心的护城河。历经近二十年培育的CUDA生态,已形成一个拥有超过400万开发者的“数字联邦”。从科研人员到工业工程师,绝大多数人的第一行AI代码都基于CUDA编写。这种习惯和依赖,形成了巨大的迁移成本和路径依赖。即便竞争对手的硬件纸面参数更优,用户也会因重写、调试和适配的巨额成本而望而却步。
第三层:系统软件的“隐形地基”在CUDA之上,英伟达构建了庞大的软件栈:用于深度学习的cuDNN,用于线性代数的cuBLAS,用于大规模模型并行训练的NCCL通信库等。这些高度优化的库,是将硬件算力释放给上层应用的关键“转换器”。自研这些基础软件,需要顶尖人才和漫长的时间积累。
第四层:平台与应用生态的“引力场”从自动驾驶(DRIVE) 到科学计算(Clara),再到元宇宙(Omniverse),英伟达不断定义新的平台,将算力与具体行业场景深度绑定。这使其从一家芯片公司,演进为平台与生态的定义者,吸引力呈指数级增长。
正是这四层相互增强的壁垒,构成了所谓的“CUDA税”——任何挑战者,都必须说服客户,其带来的性能提升或成本节约,足以覆盖逃离这个成熟、稳定生态的巨大风险。
02 挑战者图谱:“多极世界”的生存逻辑
然而,霸权之下,并非铁板一块。巨大的市场需求和技术演进的多样性,为不同类型的挑战者提供了差异化的生存空间。今天的算力加速市场,已从GPU的“大一统”演变为一个分层、分场景的“多极世界”。
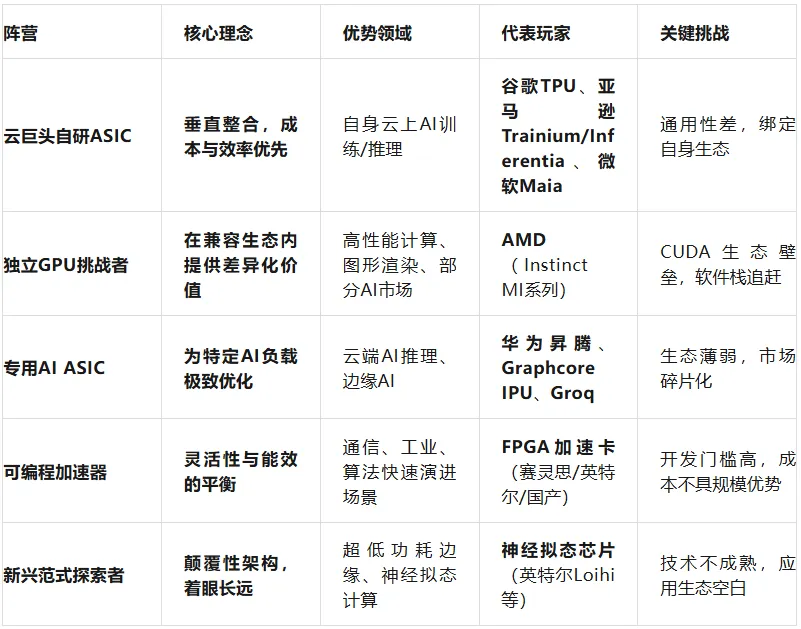
这个“多极世界”的形成,源于一个根本性变化:AI算力需求正在“解耦”和“分层”。
训练与推理解耦:大模型训练需要极致算力与内存,而海量推理则追求 “每瓦性能” 和 “每元成本” ,这为专用推理芯片创造了空间。
云端与边缘解耦:云端追求规模经济,而边缘侧受制于功耗、体积和实时性,需要完全不同的芯片架构。
算法快速迭代:AI算法尚未完全固化,这就要求硬件具备一定的灵活性和可编程性,而非完全固化的ASIC。
因此,没有一种芯片能“通吃”所有场景。多元化的技术路线,正是对不同细分市场需求的技术回应。
03 国产路径:“梯度替代”与“换道突围”的并行战略
对于中国算力产业而言,面对的是一个极其复杂的局面:既要突破核心技术封锁,又要在强大的既有生态下寻找市场入口。实践中,国产算力芯片正走出一条 “梯度替代”与“换道突围”相结合 的务实路径。
梯度替代:在价值链条上“农村包围城市”这是面对现实生态壁垒的务实选择。国产GPU和AI加速卡厂商(如海光、壁仞、摩尔线程、沐曦、燧原等)普遍采取分步走的策略:
第一步:软件兼容层。通过开发CUDA兼容层(如海光的 ROCm 增强、其他厂商的移植方案),让现有的PyTorch、TensorFlow模型能够以较低的迁移成本在国产卡上运行。目标是 “先用起来” ,解决“有无”问题。
第二步:抢占“价值高地”。避开在最顶尖的大模型训练领域与英伟达正面交锋,而是将重心转向AI推理、行业AI应用(如智慧城市、智能制造)、科学计算(如生物制药、气象模拟)和图形渲染等领域。这些场景对绝对算力要求相对较低,但对成本、本土化服务和安全可控有更强需求。
第三步:构建原生生态。在特定行业或场景中站稳脚跟后,与国内软件厂商、高校、ISV(独立软件开发商)合作,从底层算子、框架优化到上层应用,逐步培育基于国产硬件的原生应用生态。
换道突围:在技术变革期“另辟蹊径”这是着眼未来的前瞻布局。在传统通用GPU赛道上追赶异常艰难,但在一些新兴的技术变革窗口期,国内外差距相对较小。
Chiplet(芯粒)架构:这是国产芯片绕过先进制程限制、实现系统性能跃升的关键路径。通过将大型单芯片拆分为多个小芯粒(如计算芯粒、存储芯粒、I/O芯粒),分别采用合适工艺制造,再用先进封装集成。国内厂商正积极布局自研芯粒、互连接口(如ACC、UCIe)和封装技术,试图在系统级集成上建立优势。
存算一体与近存计算:如上一篇所述,这是突破内存墙的革命性方向。国内在忆阻器存算一体芯片等领域已有世界级的研究成果和早期商业化产品(如知存科技),在边缘低功耗AI场景形成独特优势。
领域专用架构:针对自动驾驶、科学计算、推荐系统等特定领域的计算特征,设计高度定制化的ASIC。例如,华为昇腾NPU的达芬奇架构,即为AI矩阵运算深度优化。避开通用性,追求在特定领域的极致效率和性能。
04 未来战场:系统级竞争与“软硬一体”的升维
未来的算力竞争,将彻底告别“比纸面算力”的初级阶段,升维至 “系统级效率” 和 “软硬一体全栈能力” 的竞争。
竞争维度一:从“单卡算力”到“集群算效”客户购买的最终是解决问题的速度,而非芯片的峰值FLOPS。这意味着竞争焦点将从单一加速卡的性能,转向包含高速互联(NVLink/CXL)、拓扑结构、存储分层、液冷散热在内的整个集群的系统效率。谁能提供更高有效算力利用率、更低总拥有成本 的一体化解决方案,谁将赢得市场。
竞争维度二:从“硬件出货”到“服务交付”算力正在变得像电力一样“即插即用”。云厂商和头部芯片公司都在推动 “算力即服务” 模式。英伟达的DGX Cloud,以及国内厂商与云服务商深度绑定的“算力一体机”,都是这种趋势的体现。未来的商业模式,可能是芯片厂商直接提供搭载自研芯片的服务器级产品或云服务,而不仅仅是销售板卡。
竞争维度三:编译与调度软件的“灵魂之战”硬件是躯体,软件是灵魂。下一阶段的竞争核心,在于谁能提供更智能的编译器和任务调度器。这需要软件能够:
深度理解算法:自动将AI模型的计算图最优地映射到复杂的异构硬件(CPU+GPU+其他加速器)上。
动态优化资源:根据负载实时调整算力、内存和通信资源的分配,实现全局最优。
降低使用门槛:提供高度抽象的编程界面,让应用开发者无需深入了解底层硬件细节。这场“灵魂之战”,将是决定国产算力能否从“能用”走向“好用”的关键。
05 结语:在霸权的裂缝中播种未来
算力加速卡的博弈,是一场涵盖技术、生态、商业和地缘政治的立体战争。英伟达的霸权建立在长达二十年的生态积累之上,其壁垒深厚且自我增强。
然而,技术的生命力在于分化与演进。AI应用的多样化、计算范式的变革(非冯架构)、以及供应链安全的国家意志,正在这座霸权的围墙上凿开一道道裂缝。国产算力厂商在这些裂缝中看到了曙光:在推理市场立足,在边缘计算扎根,在特定行业中构建闭环,并在Chiplet、存算一体等新赛道上同步起跑。
这场博弈没有速胜论。它需要的不仅是硬件设计的奇思妙想,更是打磨软件的耐心、构建生态的远见,以及进行全栈系统优化的工程能力。国产算力的崛起,注定是一条漫长而艰辛的“攀登之路”。但可以确定的是,全球算力版图的“多极化”已成定局,而中国力量,必将是其中不可或缺的一极。
至此,我们已经探讨了从硬件基石、核心架构到关键软件的三大支柱,并分析了作为产品核心的算力加速卡的竞争格局。最后,所有这些技术将如何集成,并以何种形态交付给最终用户,创造最大价值?
下一站,系列终章——《第五支柱:集成化算力产品——从“硬件堆砌”到“场景定义”的价值升维》。我们将探讨,智算服务器、边缘一体机等终极产品形态,如何完成技术价值的“最后一公里”转化。
免责声明:本文仅供学习、工作探讨,不做任何决策及推荐等意见和价值。
系列总览: