


给财报卸妆:NLP如何揪出上市公司的“语言陷阱”
“一份份光鲜亮丽的财报背后,正有机器学会阅读字里行间的微妙变化,捕捉那些试图掩盖真相的语言把戏。
”
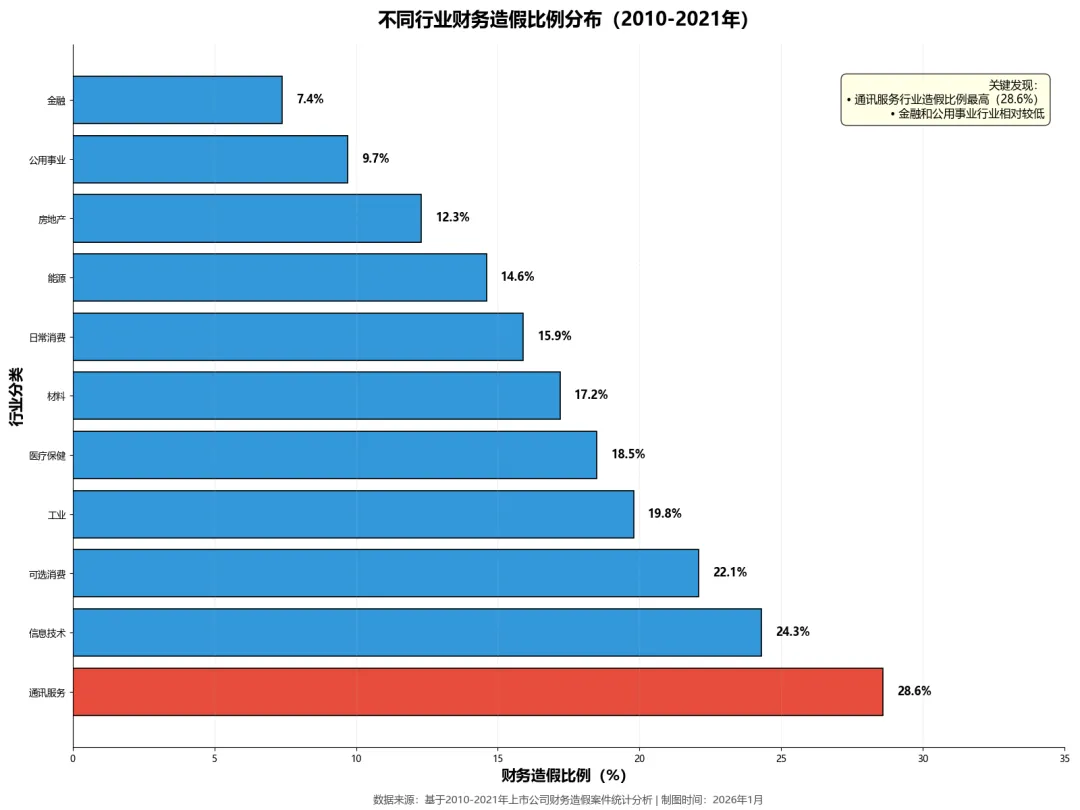
2010年至2021年间的财务造假数据显示,通讯服务行业造假比例高达28.6%,而金融和公用事业公司最低。当投资者翻阅这些财报时,往往被华丽的业绩增长数字吸引,却忽略了管理层讨论与分析(MD&A)中那些闪烁其词的表述。
基于自然语言处理(NLP)的财务造假识别研究揭示,造假企业的管理层语气积极度显著低于正常企业,而信息披露一致性差异更为明显。这些微妙变化正成为机器识别财务陷阱的新线索。
01 财报的“春秋笔法”,文字游戏下的数字魔术
翻开任何一份上市公司财报,你都会看到两部分内容:冷冰冰的数字表格和充满温度的文字叙述。咱们这些在市场里摸爬滚打的老兵,往往一头扎进数字堆里,却忽略了文字里可能藏着的玄机。
通讯服务行业2010-2021年间财务造假比例高达28.6%,这个数字背后,有多少是通过巧妙的文字叙述来配合数字魔术的?
财报的文字部分,特别是“管理层讨论与分析”(MD&A),是公司解释业绩、展望未来的主战场。这里的每一个形容词、每一个程度副词、每一个转折词,都可能成为语言陷阱的藏身之处。当业绩不佳时,管理层会用“面临挑战”“短期调整”来淡化问题;当需要夸大成就时,则会用“显著增长”“历史新高”来渲染气氛。
山东大学经济学院耿春晓博士后的研究指出一个关键问题:舞弊公司报告的会计数据存在重大错报。这意味着我们看到的数字本身就是“化过妆”的,而文字叙述则是这妆容的完美解释。
想想看,当一家公司的现金流与利润严重脱节时,管理层会在MD&A中如何解释?他们可能会强调“行业特殊账期”“战略性投资增加”,而绝口不提可能存在资金链紧张的问题。
02 语言陷阱的伪装术,从情绪矛盾到行业异常
财务造假公司的文字游戏有其规律可循。国信证券2025年4月的研究发现,通过分析财报文本情感语调,可以捕捉到三类关键信号:情绪矛盾、模糊表述和行业异常。
情绪矛盾是最容易被忽视的信号。当一家公司财务指标亮眼,但管理层语气却异常谨慎甚至消极时,这种表里不一可能就是警报。相反,当业绩平平甚至下滑,管理层却用极其乐观的语言描述时,同样值得警惕。
看看具体数据:基于2015-2024年的样本分析,造假企业的净资产收益率(ROE)明显低于非造假企业,同时经营现金流比率也较低,这反映了利润与现金流的脱节。这些数字异常通常会在文字叙述中被“合理化”。
模糊表述是另一种常见手法。当公司面临难以解释的财务变化时,往往会使用“由于多重因素”“受宏观环境影响”等笼统表述,避免提供具体可验证的信息。这种模糊性正是NLP模型可以量化分析的指标。
行业异常则更为隐蔽。当同行业公司普遍面临挑战时,某家公司却宣称“逆势增长”,且缺乏具体业务支撑,这种与行业趋势背道而驰的表述需要特别关注。特别是在2010-2018年期间,上市公司财务造假数量及占比呈上升趋势,这些公司的文字叙述往往与行业整体情况格格不入。
03 NLP的拆解术,从词向量到情感分数
传统财务分析主要关注数字,而现代NLP技术开始撕开文字的伪装。这一过程涉及文本预处理、特征提取和建模分析三个关键环节。
首先是文本预处理。中文财报分析需要使用结巴分词等工具,识别财务术语、专业名词和机构名称,然后去除停用词、统一标点格式,将“减少”“降低”“下降”等同义词归并为同一类。这个过程就像给财报文字“卸妆”,去除那些装饰性的语言,留下实质内容。
特征提取阶段更为关键。传统方法如词袋模型简单但有限,而词频-逆文档频率(TF-IDF)模型能对“虚增”“重组”“违规”等区分性强的词赋予更高权重。更先进的方法是词向量嵌入,它能在语义空间中让相近含义的词语距离更近,从而捕捉“规避责任”“提前确认收入”等隐含舞弊表达。
情感语调分析是NLP拆解财报的核心技术。国信证券的研究使用DeepSeek R1模型分析财报文本情感语调,设计相关函数和处理流程获取情感语调分数。结果清晰显示,财务造假公司的情感语调分数整体低于正常公司。
这种情感分析不仅停留在积极或消极的简单判断,还能识别更微妙的语气变化,如过度防御性、刻意模糊或不当强调等。这些细微差别往往是人工分析容易忽略的,却能被NLP模型精准捕捉。
04 多模态融合,当数字遇见文字
单一的文本分析或传统的财务比率分析都有局限性,而将两者结合的多模态模型正在改变游戏规则。最新研究构建了融合MacBERT与Transformer的财务造假识别模型。
这个模型的工作流程很聪明:先用MacBERT获取财务文本的深层语义特征,再与企业财务指标进行特征融合,然后通过Transformer建模企业行为模式。简单说,就是让数字和文字“对话”,从中发现不一致的蛛丝马迹。
实验数据显示,这种双通道结构效果显著。模型采用“预训练-微调”策略,先在大规模中文语料上学习通用语言知识,再在年报、公告与财经新闻等领域语料上微调。这样既保证了模型的通用理解能力,又增强了对行业词汇与舞弊表达的识别。
从数据来看,这种融合方法确实有效。造假企业在财务指标上表现出明显特征:ROE较低、资产负债率较高、经营现金流比率较低、应计利润比较高。当这些数字异常与文本中的特定表述模式同时出现时,风险信号就会大大增强。
重要的是,这种多模态方法能够识别那些财务指标看似正常,但文字叙述存在问题的公司。这类公司往往通过复杂的交易结构或会计处理来美化数字,却在文字描述中无意间暴露真实情况。
05 数据还原难题,寻找“卸妆后”的真实面貌
耿春晓博士后在《会计研究》2025年第5期发表的论文提出了一个根本性问题:虚假会计数据影响财务舞弊模型的识别效力吗?
这个问题直击要害。如果我们用来训练模型的数据本身就是被操纵过的,那模型学到的可能只是“如何识别被美化后的财报”,而不是真正的财务舞弊模式。就像用美颜照片训练人脸识别系统,系统可能永远认不出素颜的人。
研究团队做了件很有意思的工作:通过阅读行政处罚公告和会计差错更正公告,尽可能将舞弊公司的虚假会计数据还原至舞弊前水平。他们发现,“一刀切”地对所有会计变量进行虚假数据还原未必能提升舞弊模型的识别效力,有针对性的还原才能稳定提升模型表现。
这个发现对实务工作有重要启示。当我们使用基于历史数据训练的财务预警模型时,必须考虑这些历史数据本身的“纯净度”。如果训练集中包含大量未被发现的造假案例,模型的效果就会大打折扣。
山东大学的研究提出了区分两类变量的思路:依赖于操纵前会计数据的变量和依赖操纵后会计数据的变量。前者在数据还原后识别效力增强,后者则可能削弱。这种差异化处理思路,比简单粗暴的全面还原更加有效。
06 模型的战场表现,理想与现实的差距
理论很美好,现实呢?EDINET-Bench研究提供了日本市场的实证数据,结果令人深思:在会计舞弊检测任务中,最先进的LLM模型表现仅略优于简单的逻辑回归。
具体来说,Claude 3.5 Sonnet模型在添加文本信息后,ROC-AUC约为0.73,而逻辑回归为0.68。这个差距并没有想象中那么大。在盈利预测任务中,模型表现更差,最佳ROC-AUC仅0.61。这说明,仅凭年报信息进行复杂财务判断,即使对最先进的AI也是巨大挑战。
为何会有这种差距?一方面,财报分析本质上是多源信息交叉验证的过程,而模型通常只能接触到公开的年报信息。实际审计工作需要查阅原始凭证、进行访谈、了解行业情况,这些都是单一财报文本无法提供的。
另一方面,标签质量问题也不容忽视。EDINET-Bench研究指出,数据集中部分“欺诈”标签可能涵盖了非恶意的会计更正。这会导致模型学习到错误的模式。此外,财务报表解析的不一致性也可能导致误判。
不过,积极的一面是,文本信息的加入确实提升了模型对欺诈样本的识别能力。这说明NLP分析是有价值的,但需要更精细的设计和更多元的信息输入。
07 行业差异,造假也有“地方特色”
财务造假不是均匀分布的,不同行业有不同的“特色”。2010-2021年间的数据显示,通讯服务行业财务造假比例最高,达到28.6%,而金融和公用事业最低。
这种行业差异背后有深刻的业务逻辑。通讯服务行业可能因为技术快速迭代、资本开支大、收入确认复杂等因素,为财务操纵提供了更多空间。而金融和公用事业受到更严格的监管,财务透明度要求更高,造假难度也更大。
从时间趋势看,2010-2018年上市公司财务造假数量及占比呈上升趋势,2019年后有所下降。这一变化可能与监管加强、技术手段提升有关。同时,信息披露违规成为主流,虚构利润和虚列资产等传统手段减少。
NLP模型需要考虑到这种行业差异性。不同行业的财报有不同的语言习惯和关注重点,统一的标准可能失效。例如,高科技公司财报中常见的“研发投入”“无形资产”等表述,在传统制造业中可能很少出现。

行业景气度也会影响财务造假的特征和动机。在行业下行期,企业可能更倾向于通过财务操纵来维持表面繁荣;而在上行期,则可能为了迎合市场预期而提前确认收入。NLP模型如果能够结合行业周期特征,动态调整财务指标权重,将能更精准地识别异常。
08 投资者工具箱,如何让NLP为你所用
对咱们普通投资者来说,这些高大上的NLP技术似乎遥不可及。但实际上,基本原理和思路完全可以应用到日常分析中。不需要自己搭建复杂模型,但可以借鉴NLP的思维方式。
首先,培养对财报文字的敏感度。阅读MD&A时,不要只关注结论,要注意语言的微妙变化。比较公司不同时期的表述,特别是当业绩发生变化时,管理层解释方式是否有重大转变?与同行业公司的表述相比,是否存在明显差异?
其次,寻找数字与文字的矛盾点。当财报显示业绩大幅增长,但管理层讨论中却充满谨慎用词时,要打个问号。相反,如果业绩平平而管理层异常乐观,同样值得警惕。这种表里不一往往是问题的前兆。
再者,关注信息披露的一致性。耿春晓博士后的研究发现,虚假会计数据对模型识别效力的影响不能一概而论。在分析公司时,要特别注意财务数据与文字描述是否自洽,前后期报告是否存在矛盾。
实用建议是建立自己的“红色关键词”清单。根据研究,某些词语和表述模式与财务风险高度相关。例如,过度使用模糊词语、频繁改变会计政策解释、异常复杂的业务描述等,都可能是预警信号。
09 未来战场,AI与造假的军备竞赛
财务造假与检测技术之间,永远是一场动态博弈的军备竞赛。随着NLP技术的发展,造假者也在进化他们的“语言艺术”。未来的战场将在哪里展开?
基于Zero-Shot的财报文本直接分析模式正在兴起,利用大模型的通用语义理解能力挖掘潜在造假信号。这种方法不需要大量标注数据,能够快速适应新的造假手法。另一方面,基于违规说明的Fine-Tuning模式,通过对基座大模型进行微调构建专家模型,能够实现更精准的匹配。
更前沿的方向是多模态、多阶段的分析框架。EDINET-Bench研究指出,未来可设计多阶段、多模态代理流程,提升大语言模型对财报复杂性的适应能力。这意味着AI将不再仅仅分析年报文本,而是整合业绩发布会记录、投资者交流内容、媒体报道等多源信息。
社会伦理风险也不容忽视。模型可能存在的偏见、误判可能对公司造成严重损害,这些都需要在技术发展中充分考虑。特别是在中国资本市场环境下,如何平衡风险预警与市场稳定,是需要深思的课题。
对于监管机构而言,这些技术提供了全新的监管工具。通过大规模文本分析,可以系统性监测整个市场的语言风险,及时发现异常模式。但这同样提出了新的挑战:如何解释基于复杂AI模型的监管决策?如何在技术自动化和人工判断之间找到平衡点?
当算法开始阅读财报字里行间的微妙变化,传统财务分析的边界正在被重新定义。通讯服务行业28.6%的造假比例背后,是数字与文字合谋的精密戏剧。
那些曾被忽视的管理层语气积极度差异和文本信息披露不一致,如今成为机器眼中的风险信号。从简单的逻辑回归到复杂的多模态模型,技术正在追赶人类操纵语言的智慧。
这场猫鼠游戏永无止境——当造假者学会用更精妙的语言编织陷阱,AI也正在构建更复杂的语义网络来拆解伪装。在这场没有硝烟的语言战争中,最终胜出的,或许是那些既懂得数字又理解文字的市场参与者。
