基于大数据模型的贷款违约预测分析
摘要:针对贷款违约给商业银行带来的信用风险损失,本文基于Kaggle平台的Loan Defaulter数据集,通过建立机器学习模型预测客户违约情况,以降低信贷风险。本文根据贷款数据类别不平衡和特征维度高的特点,对其进行数据处理以及探索性数据分析,得出与贷款违约高度相关的重要特征。在比较各类基线模型和Stacking集成学习模型基础上,发现基于集成学习的模型能够平衡基线模型的性能,并能取得较好的预测效果。
关键词:贷款违约预测;机器学习;集成学习;数据分析;

四、数据分析
(一)探索性分析
探索性数据分析是指使用图、表等直观方法探究单变量以及两两变量之间的关系,本文通过使用非平衡处理前的数据,探究贷款违约与不同特征之间的关系。
1、总体贷款违约情况
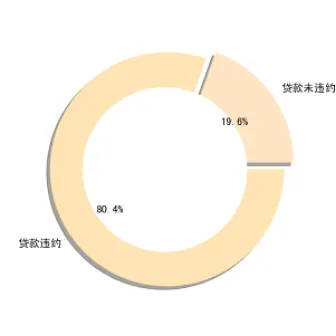
首先研究编写Python代码实现将训练集中的贷款是否违约人数进行统计,然后通过环形图的可视化方式直观呈现违约人数与未违约人数之间的关系。如图所示,在训练集中,贷款未违约的人数与贷款违约人数之比约为1:4,数据集具有不平衡的属性,可能会影响模型训练的效果。
2、贷款违约与贷款金额的关系
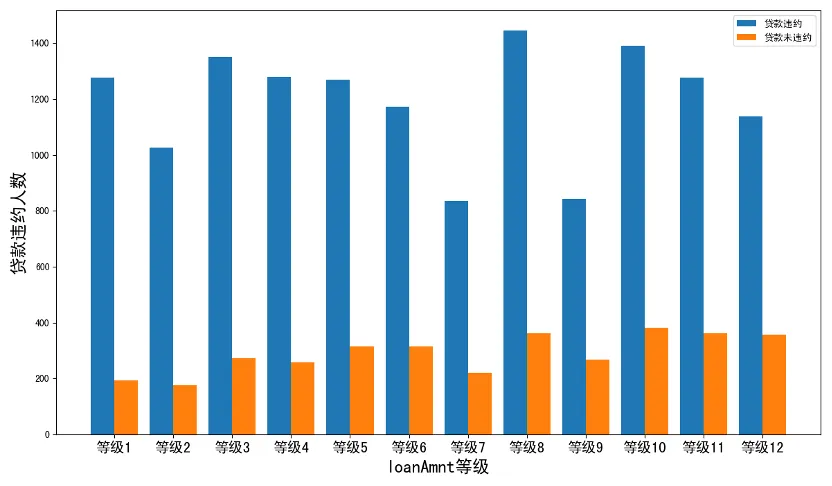
在我们一般认知中,贷款违约可能会与贷款金额具有较高的相关性,因为高贷款金额往往会成为人们无法及时还债的一个重要原因。因此,下面探索了不同区间内贷款违约与未违约的人数情况。从图中不难看出,越高的贷款金额并未呈现出贷款违约人数上升的情况,反而贷款未违约人数较低的贷款金额人数更多。因此,贷款金额这一特征可能与贷款违约情况存在弱负相关的关系。
3、贷款违约与贷款金额的关系
贷款利率可能影响到借贷人的还贷,因此统计interestRate(贷款金额)来帮助分析是否高贷款率造成了过多的贷款违约情况。
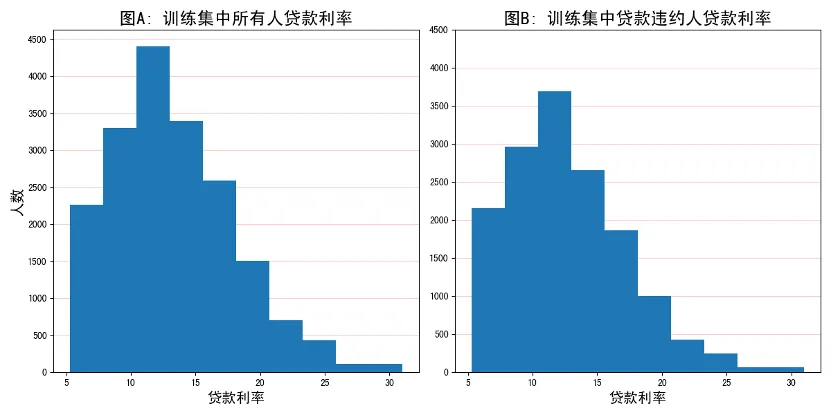
从图A和图B两个可视化柱状图的分析中可以看到,未违约贷款人主要的贷款利率集中在区间[12.5,22.5],因此贷款违约情况可能与贷款利率不存在很强的相关关系。
4、贷款违约与年收入的关系
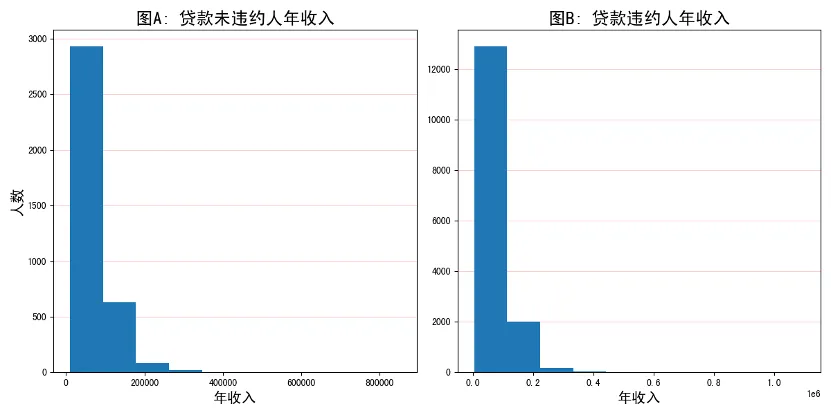
一般在银行或者机构发放贷款之前,都会对贷款人进行一个综合评估,评估通过之后银行或者机构才会发放贷款。因此,一些人并不是想违约,而是由于一些其他的因素被迫违约,而这其中最大的影响因素便是贷款人的年收入。通过对贷款违约人和贷款未违约人进行统计,发现在贷款违约人中,绝大部分人都是收入低下的群体,这一现象说明个人的年收入是影响贷款违约的重要因素。
5、特征相关关系可视化
最后,本研究在经过数据预处理的基础上,进一步探索训练数据集中各个特征之间的相关关系,并以制作热力图的方式来呈现。
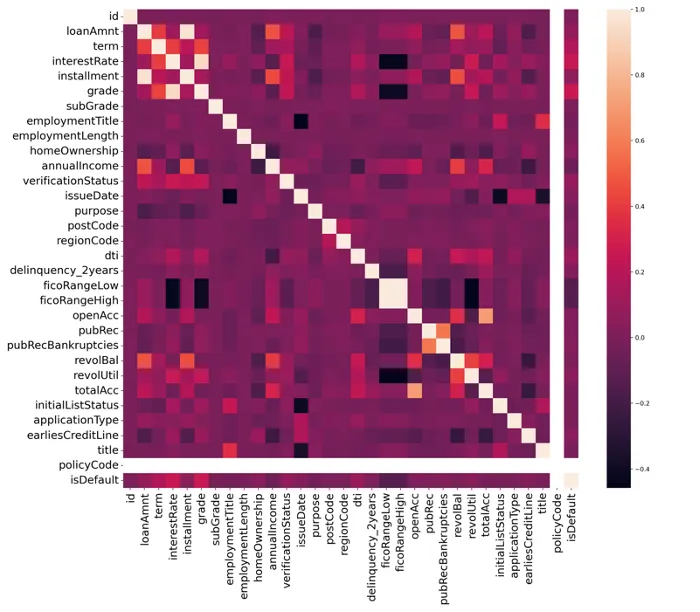
如图所示,policyCode特征与其他所有特征均无明显相关性,因此考虑将该特征进行筛除。
......
以上是本次分享的部分内容,完整版报告内容请在后台发送关键词“基于大数据模型的贷款违约预测分析”即可获取完整版Word报告!