


期末临近,各位老师又要着手准备学生素质报告单了。其实等所有数据收集完毕后,只需通过邮件合并就能快速生成每位学生的素质报告单,但数据收集环节往往最耗费精力 —— 不仅需要和多位教师沟通对接,收集完成后还要逐一整合大家填写的信息,这些琐碎的工作才是真正增加工作量的 “痛点”。
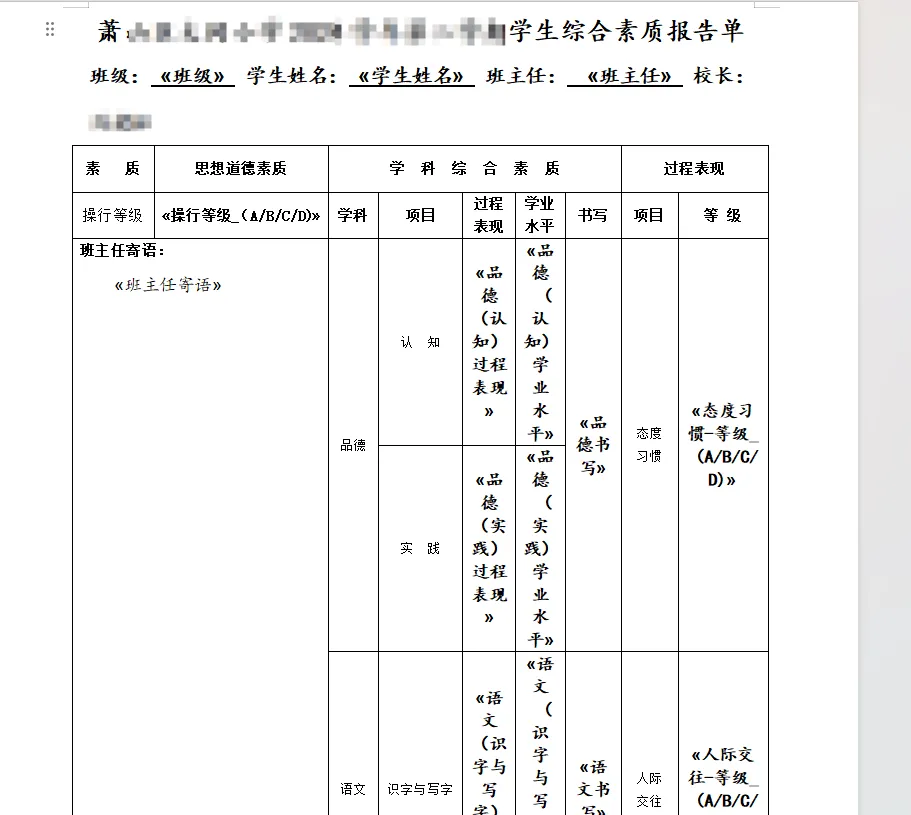

今天就给大家分享两种高效收集所需信息的方法,帮你大幅减少手动操作的工作量:
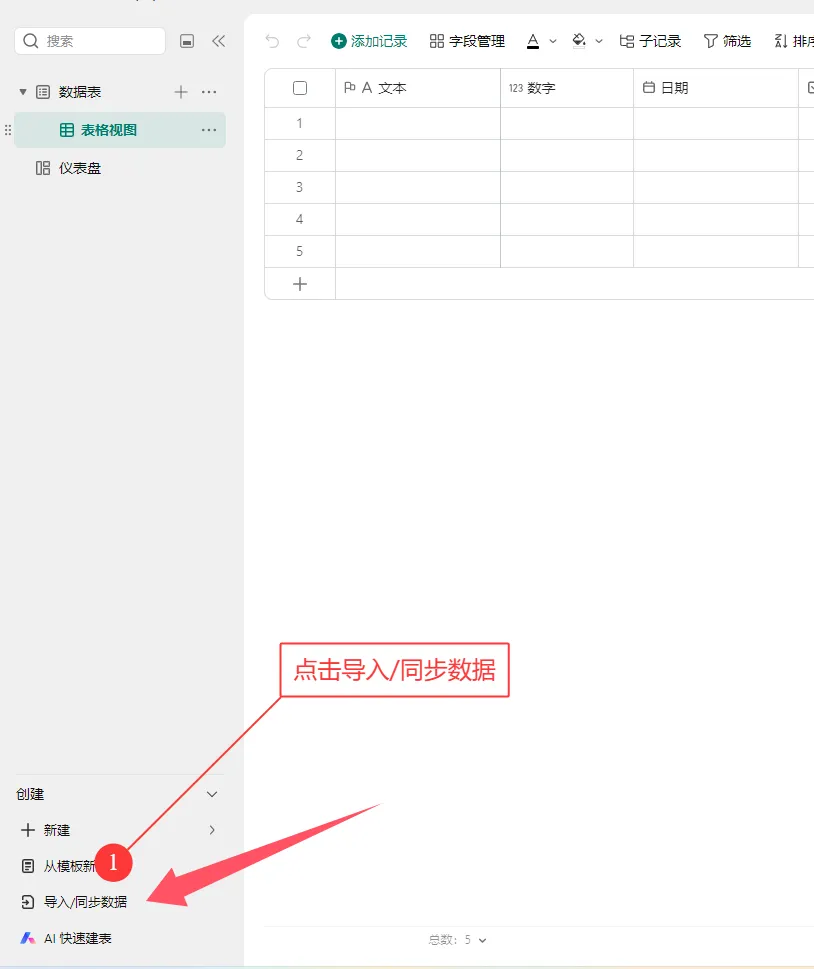
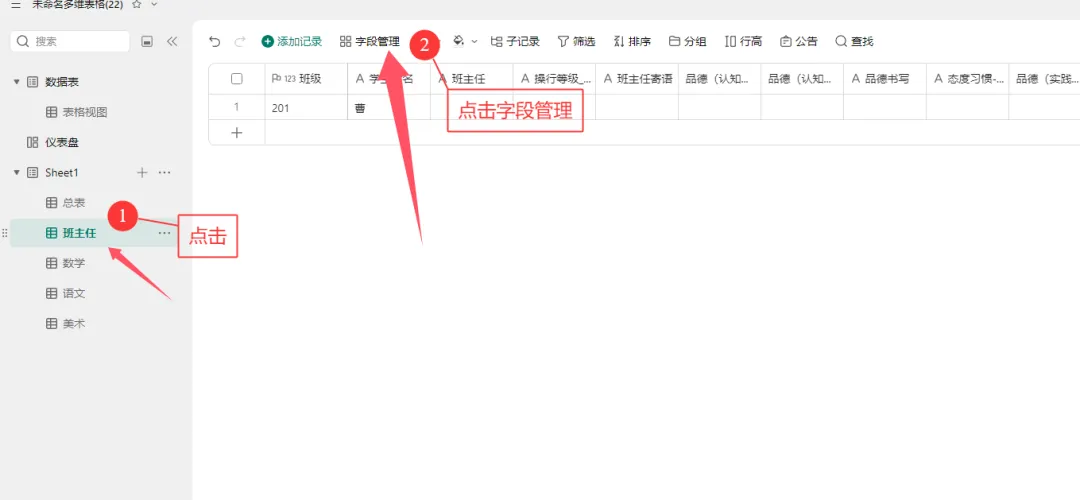
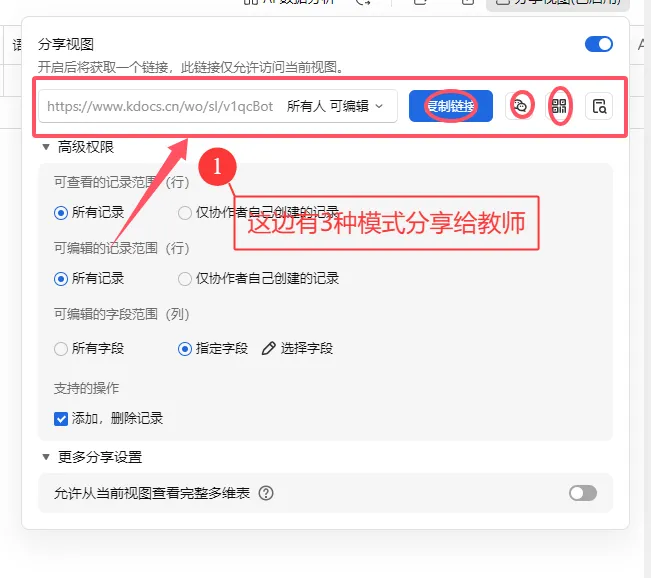
方法一:纯多维表格收集
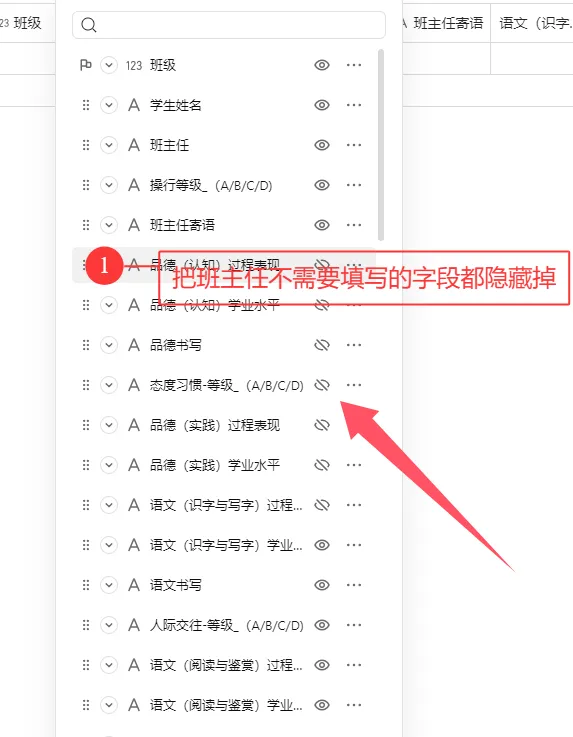
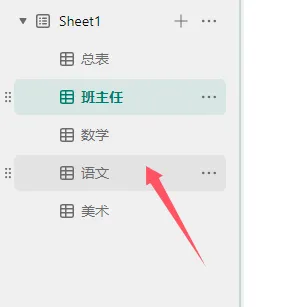
这种方式的不足在于,需要先将学校所有班级、学生姓名等基础信息完整录入表格,老师们再按预设好的格式填写对应数据。如果老师们熟悉表格筛选等操作,使用起来基本无压力;但对于不熟悉的老师来说,操作会显得繁琐。此外,若表格包含 60 多个字段,逐一设置字段隐藏、显示等权限也需要花费不少时间。不过它的优势也很明显:所有数据汇总后,你只需直接下载总表即可使用,无需额外做数据合并的操作。
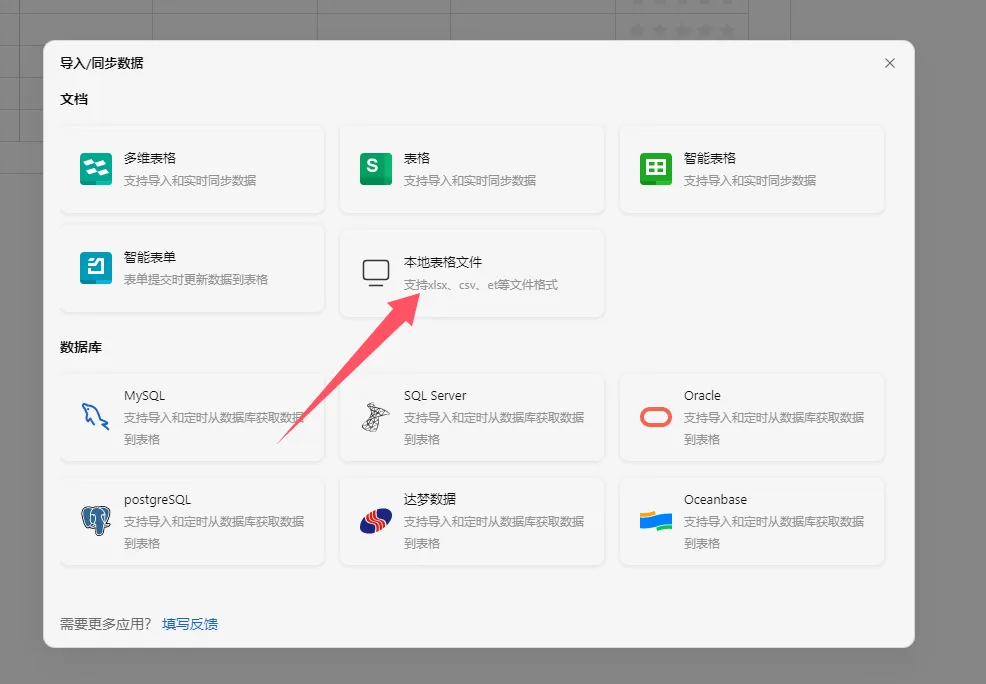
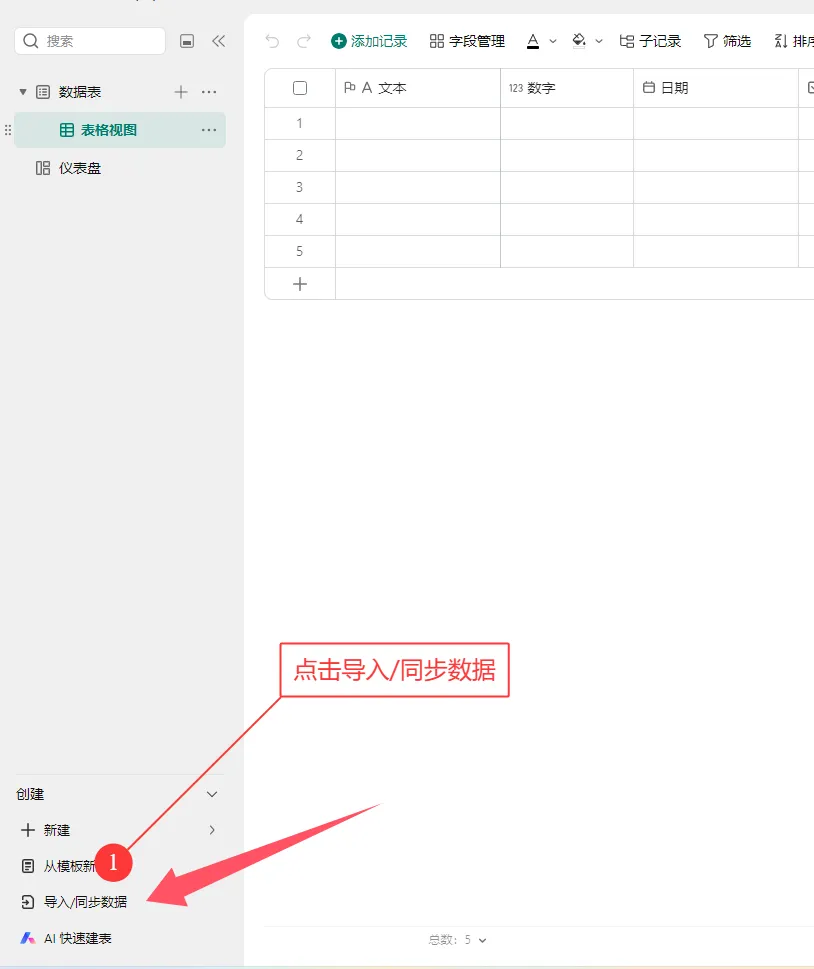
方法二:多维表格 + 脚本辅助
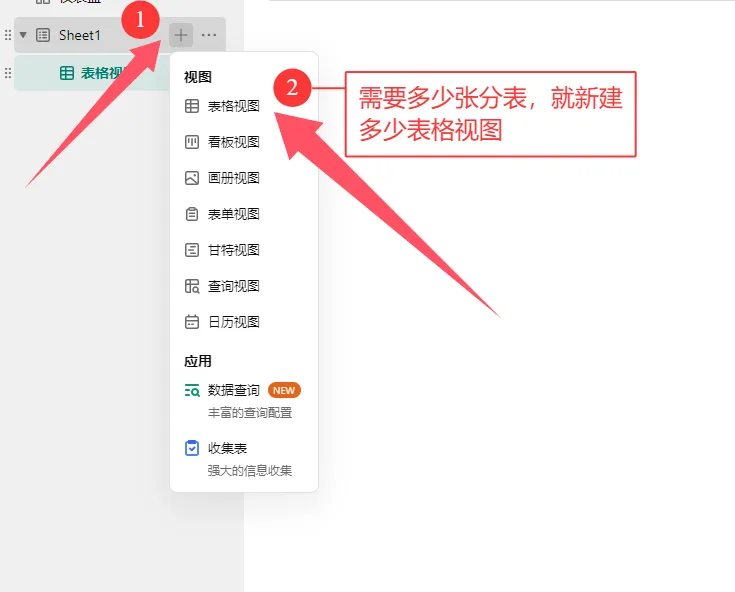
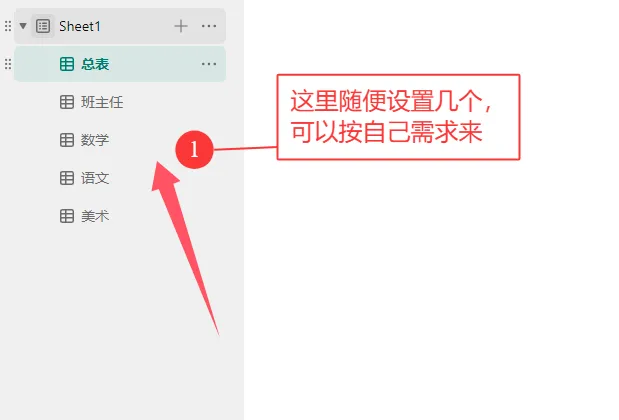
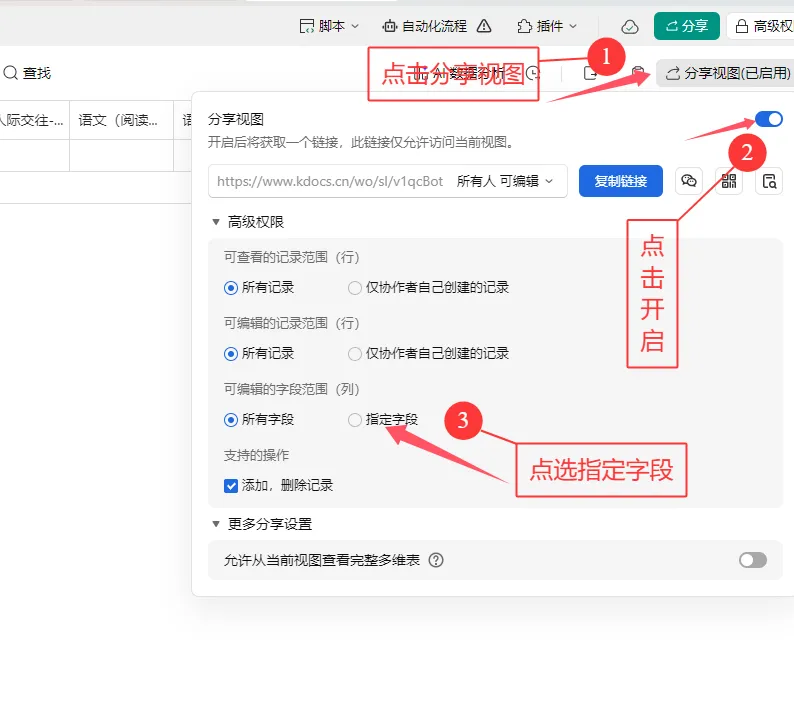
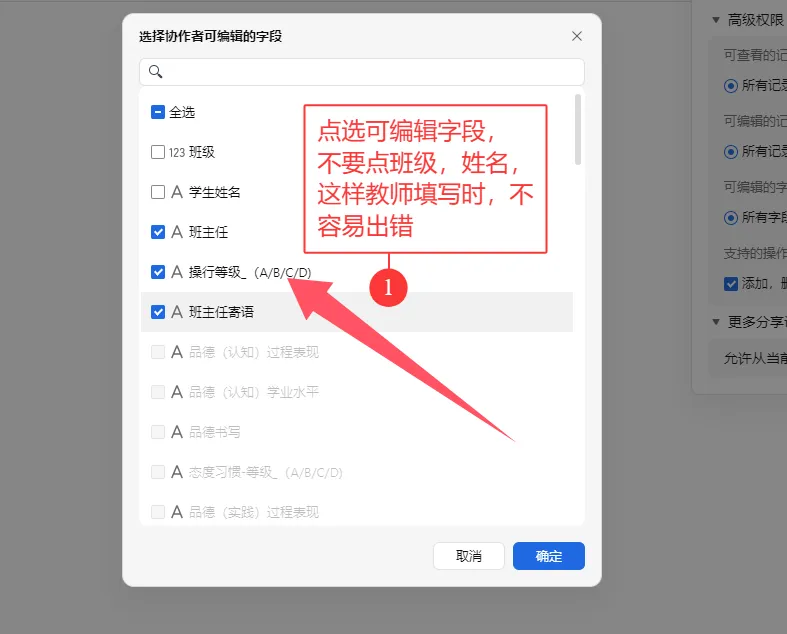
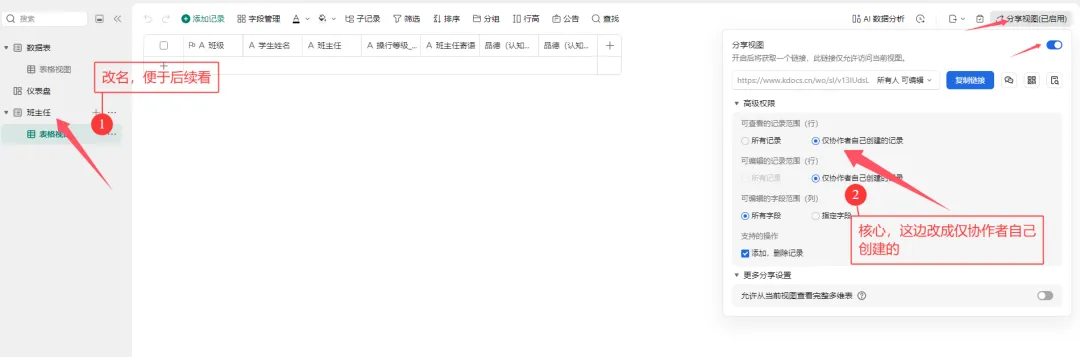
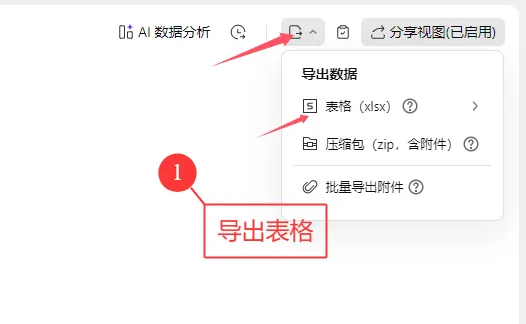
这种方法的唯一门槛是需要掌握基础的 Python 知识(当然相关代码也可以借助 AI 生成,关键在于你是否会灵活使用)。但优势十分突出:无需提前在表格中录入所有班级和学生信息,每位教师只需填写自己负责的学生数据即可,且无法查看其他教师填写的内容,既降低了教师的填写门槛,也保障了数据的私密性,对填写的老师们来说更友好。
总结
纯多维表格法:无需后期合并数据,但需提前录入基础信息,对不熟悉表格操作的教师不够友好; 多维表格 + 脚本法:对教师更友好、数据更私密,仅需掌握基础 Python(或借助 AI 生成代码)即可实现。













import pandas as pdimport osdef merge_excel_files(folder_path, output_file="merged_result.xlsx"):"""合并多个Excel文件,按班级+姓名合并相同行的数据Args:folder_path: 存放Excel文件的文件夹路径output_file: 合并后的输出文件名"""# 存储所有读取的数据all_data = []# 获取文件夹中所有xlsx文件excel_files = [f for f in os.listdir(folder_path) if f.endswith('.xlsx') and not f.startswith('~$')]if not excel_files:print("未找到任何Excel文件!")return# 逐个读取Excel文件for file in excel_files:file_path = os.path.join(folder_path, file)try:# 读取Excel文件(默认读取第一个工作表)df = pd.read_excel(file_path)# 检查是否包含必要的列if '班级' not in df.columns or '姓名' not in df.columns:print(f"警告:文件 {file} 缺少班级或姓名列,已跳过")continue# 添加源文件名列(可选,用于追踪数据来源)df['源文件'] = fileall_data.append(df)print(f"成功读取:{file},共{len(df)}行数据")except Exception as e:print(f"读取文件 {file} 出错:{str(e)}")continueif not all_data:print("没有可合并的有效数据!")return# 逐步合并所有DataFrame(按班级和姓名外连接)merged_df = all_data[0]for df in all_data[1:]:merged_df = pd.merge(merged_df,df,on=['班级', '姓名'],how='outer', # 外连接保留所有行suffixes=('', '_drop') # 重复列添加后缀)# 删除重复的列(合并时产生的_drop列)merged_df = merged_df.loc[:, ~merged_df.columns.str.endswith('_drop')]# 重置索引并填充空值(可选,根据需求调整)merged_df = merged_df.reset_index(drop=True)merged_df = merged_df.fillna('') # 空值替换为空字符串# 保存合并后的文件merged_df.to_excel(output_file, index=False)print(f"\n合并完成!结果已保存至:{output_file}")print(f"合并后数据总行数:{len(merged_df)}")print(f"合并后总列数:{len(merged_df.columns)}")print(f"所有列名:{list(merged_df.columns)}")# ------------------- 使用示例 -------------------if __name__ == "__main__":# 替换为你的Excel文件所在文件夹路径folder_path = "C:\\Users\周国峰\Desktop\新建文件夹 (16)\数据" # 这边的文字替换成你的文件夹# 调用合并函数merge_excel_files(folder_path, "合并结果.xlsx")
