


“LABOR-LLM: LANGUAGE-BASED OCCUPATIONAL REPRESENTATIONS WITH LARGE LANGUAGE MODELS” 聚焦于劳动经济学领域中职业轨迹预测的核心问题,提出了 LABOR-LLM 框架,旨在通过大型语言模型(LLMs)构建更具代表性的职业预测模型,突破传统方法在数据规模、模型灵活性与预测准确性上的局限。该论文由来自斯坦福大学、哈佛大学的 5 位研究者合作完成。
Many empirical studies of labor market questions rely on estimating relatively simple predictive models using small, carefully constructed longitudinal survey datasets based on hand-engineered features. Large Language Models (LLMs), trained on massive datasets, encode vast quantities of world knowledge and can be used for the next job prediction problem. However, while an off-the-shelf LLM produces plausible career trajectories when prompted, the probability with which an LLM predicts a particular job transition conditional on career history will not, in general, align with the true conditional probability in a given population. Recently, Vafa et al. (2024) introduced a transformer-based “foundation model”, CAREER, trained using a large, unrepresentative resume dataset, that predicts transitions between jobs; it further demonstrated how transfer learning techniques can be used to leverage the foundation model to build better predictive models of both transitions and wages that reflect conditional transition probabilities found in nationally representative survey datasets. This paper considers an alternative where the fine-tuning of the CAREER foundation model is replaced by fine-tuning LLMs. For the task of next job prediction, we demonstrate that models trained with our approach outperform several alternatives in terms of predictive performance on the survey data, including traditional econometric models, CAREER, and LLMs with in-context learning, even though the LLM can in principle predict job titles that are not allowed in the survey data. Further, we show that our fine-tuned LLM-based models’ predictions are more representative of the career trajectories of various workforce subpopulations than off-the-shelf LLM models and CAREER. We conduct experiments and analyses that highlight the sources of the gains in the performance of our models for representative predictions.

在研究背景与问题提出部分,论文指出传统劳动市场实证研究多依赖小型、精心构建的纵向调查数据集,采用人工设计特征的简单预测模型(如逻辑回归、条件 logit 模型),这类模型往往受限于数据量,只能捕捉职业历史中有限的依赖关系(如仅考虑上一份工作或少量历史统计信息),导致预测能力较弱。近年来,虽有基于 Transformer 的专用模型(如 Vafa 等人 2024 年提出的 CAREER 模型)通过大规模简历数据预训练提升了预测效果,但 CAREER 依赖专有简历数据,且未充分利用 LLMs 所蕴含的海量世界知识。LLMs 虽能生成看似合理的职业轨迹,但其预测的职业转换概率与真实人群的条件概率难以对齐,直接使用时代表性不足,无法满足政策分析、反事实模拟等场景对 “基于职业历史和人口特征的代表性预测” 的需求。
为解决上述问题,论文首先明确了职业建模的核心目标:构建能预测个体下一份职业的概率模型,且该模型需在总体及细分人群(如不同教育背景、种族)中具备 “条件代表性”—— 即预测的职业分布与真实调查数据中基于职业历史和人口特征的条件分布一致。为评估代表性,论文采用美国三大权威纵向调查数据集:Panel Study of Income Dynamics(PSID)、National Longitudinal Survey of Youth 1979(NLSY79)和 1997(NLSY97),这些数据集因采用全国代表性抽样,成为检验模型代表性的黄金标准。
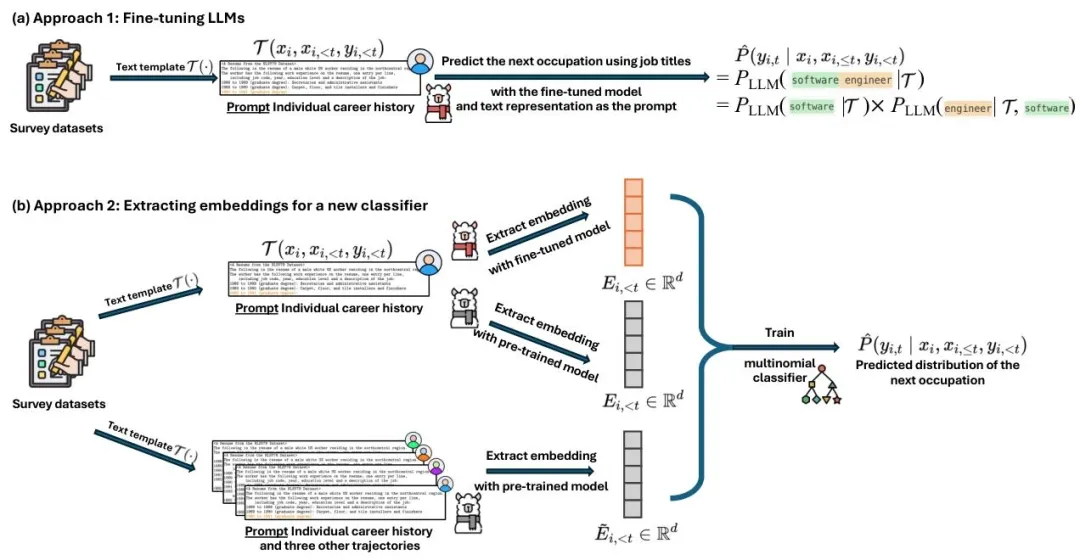
在方法设计上,论文提出两种基于 LLMs 的职业预测路径,并与传统计量模型、CAREER 模型及零样本 LLMs 进行对比。第一种路径是直接微调 LLMs:将个体职业历史与特征通过文本模板转换为自然语言(如 “1988-1989(本科学历):秘书与行政助理”),以因果语言建模(CLM)为目标,在调查数据集的训练集上微调 Llama-2 系列模型(7B、13B、70B 参数),让模型学习预测职业标题的 token 序列。第二种路径是基于 LLM 嵌入的分类器:先通过 LLM(零样本或微调后)提取职业历史文本的嵌入向量,再在嵌入向量上训练多分类逻辑回归模型,直接预测职业编码。此外,论文还探索了 “提示中加入职业列表”“上下文学习(在提示中加入 3 个完整职业轨迹示例)” 等优化策略,以提升零样本 LLMs 的表现。
实验结果方面,论文通过 “困惑度”(Perplexity,越低表示预测分布与真实分布越接近)、ROC 曲线、AUC 值、校准曲线等指标,全面验证了 LABOR-LLM 的优势。首先,零样本 LLMs 表现不佳:即使在提示中加入职业列表,Llama-2(70B)在 PSID 的困惑度仍达 131.29,远高于 CAREER 的 13.88;而微调后,Llama-2(70B)在 PSID、NLSY79、NLSY97 的困惑度分别降至 13.14、11.03、13.87,不仅显著优于零样本 LLMs,还超越了专为职业预测设计的 CAREER 模型(其困惑度分别为 13.88、11.32、14.16)。通过 1000 次 bootstrap 抽样验证,微调后的 Llama-2(70B)在三个数据集上的困惑度较 CAREER 平均降低 0.28-0.77,且差异具有统计显著性。其次,在细分任务与人群中,微调 LLMs 优势更明显:在 “预测是否换工作” 的二分类任务中,微调 Llama-2(70B)的 AUC 值略高于 CAREER,且校准效果更优 ——CAREER 对部分群体存在 “高估或低估换工作概率” 的问题,而微调 LLMs 的预测概率与真实换工作比例更接近;在 “条件于换工作时预测具体职业” 的任务中,微调 Llama-2(70B)的困惑度较 CAREER 平均降低 1.82-4.14,尤其在罕见职业转换(如低频率的职业流动)和长职业历史(如个体后期职业生涯)场景中,优势更突出,这得益于 LLMs 预训练中积累的世界知识与 Transformer 的注意力机制。此外,在不同教育背景人群中,微调 LLMs 均保持优势:对 “大学及以上” 和 “非大学” 群体,其困惑度均低于 CAREER,且校准曲线更贴近完美校准线,说明模型在细分人群中仍具备良好的代表性。
论文还深入分析了微调 LLMs 优势的来源:一方面,LLMs 通过预训练掌握了职业标题的语言语义(如 “软件工程师” 与 “系统工程师” 的关联性),无需像 CAREER 那样依赖专有简历数据学习职业间的关联;另一方面,微调过程让模型学会了 “聚焦有效职业标题”—— 零样本 LLMs 仅将约 1/3-2/3 的概率分配给有效职业,而微调后 Llama-2(7B/13B)分配给有效职业的概率达 99%,无需额外归一化即可近似满足概率公理,大幅降低计算成本。同时,论文对比了不同方法的成本与收益:微调 LLMs 虽需较高的固定计算成本(如 70B 模型微调需 3 个 epoch、批量大小 32),但预测性能最优;基于 LLM 嵌入的分类器虽计算成本较低(仅需推理提取嵌入),但困惑度高于直接微调(如微调 Llama-2(13B)的嵌入分类器在 PSID 的困惑度为 13.39,高于直接微调的 13.32);传统计量模型(如二元马尔可夫模型)成本最低,但性能最差(PSID 困惑度 27.16)。
最后,论文总结了理论与实践贡献,并指出未来方向。理论上,它证明了通用 LLMs 通过微调可适配劳动经济学的专业预测任务,且无需依赖专有数据,为 “将 LLMs 用于其他经济建模问题” 提供了新思路;实践上,公开可用的微调 LLMs 降低了职业轨迹研究的门槛,研究者无需获取专有简历数据或训练专用 Transformer 模型,即可构建 state-of-the-art 模型。未来研究将聚焦三方面:优化 70B 模型的归一化步骤以更精准评估性能、采用深度神经网络替代简单逻辑回归以充分利用高维 LLM 嵌入、利用长上下文窗口 LLMs 探索更多上下文学习示例的影响。