









vLLM是基于PagedAttention的高效推理框架,通过创新内存管理实现快速经济的大模型服务。
? 核心技术PagedAttention
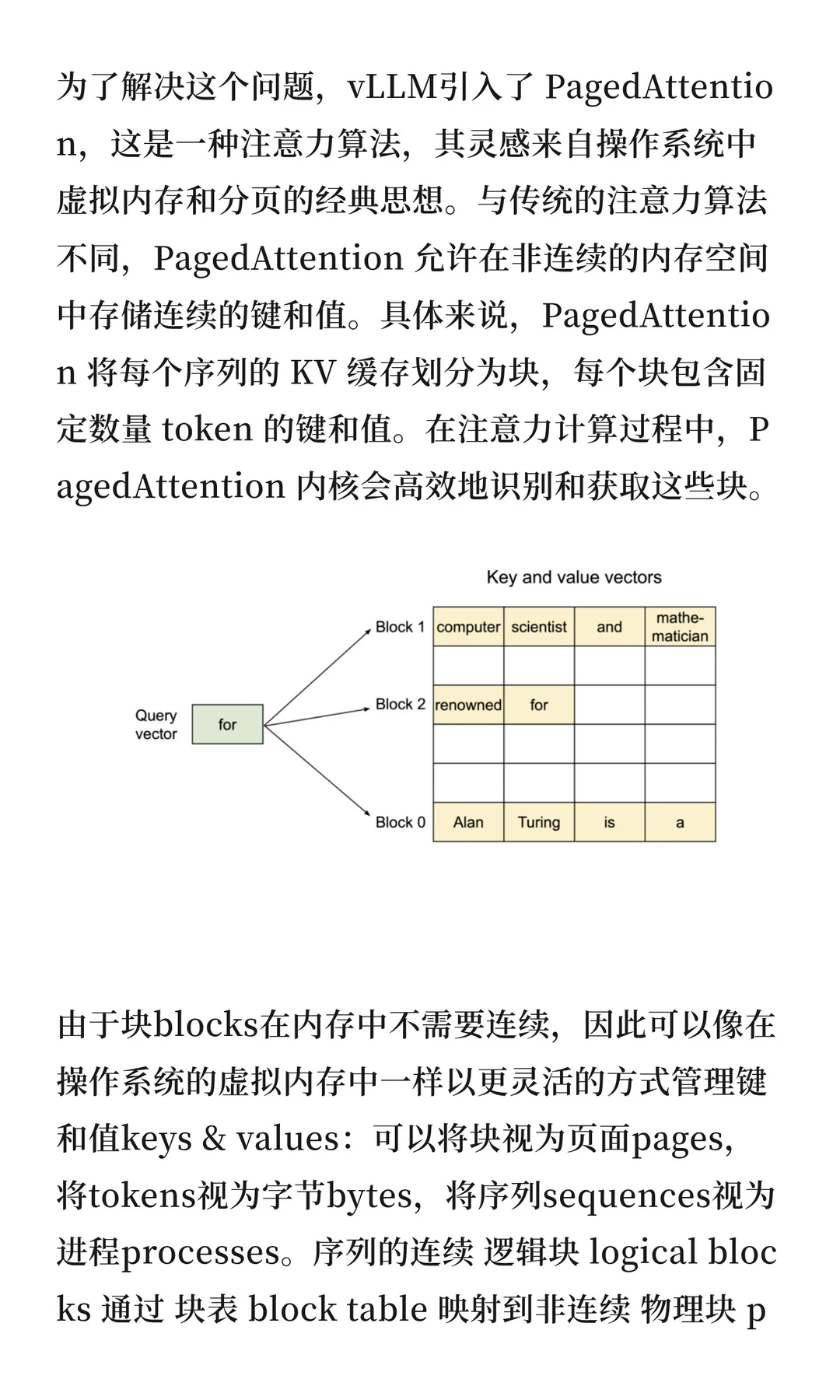
传统LLM推理的瓶颈在于显存。KV缓存占用巨大,现有系统浪费60-80%的内存。PagedAttention借鉴操作系统虚拟内存思想,将KV缓存分块存储,无需连续内存空间。通过块表映射逻辑块到物理块,内存浪费率降至4%以下。这种设计能批处理更多序列,显著提高GPU利用率和吞吐量。
? 内存共享机制
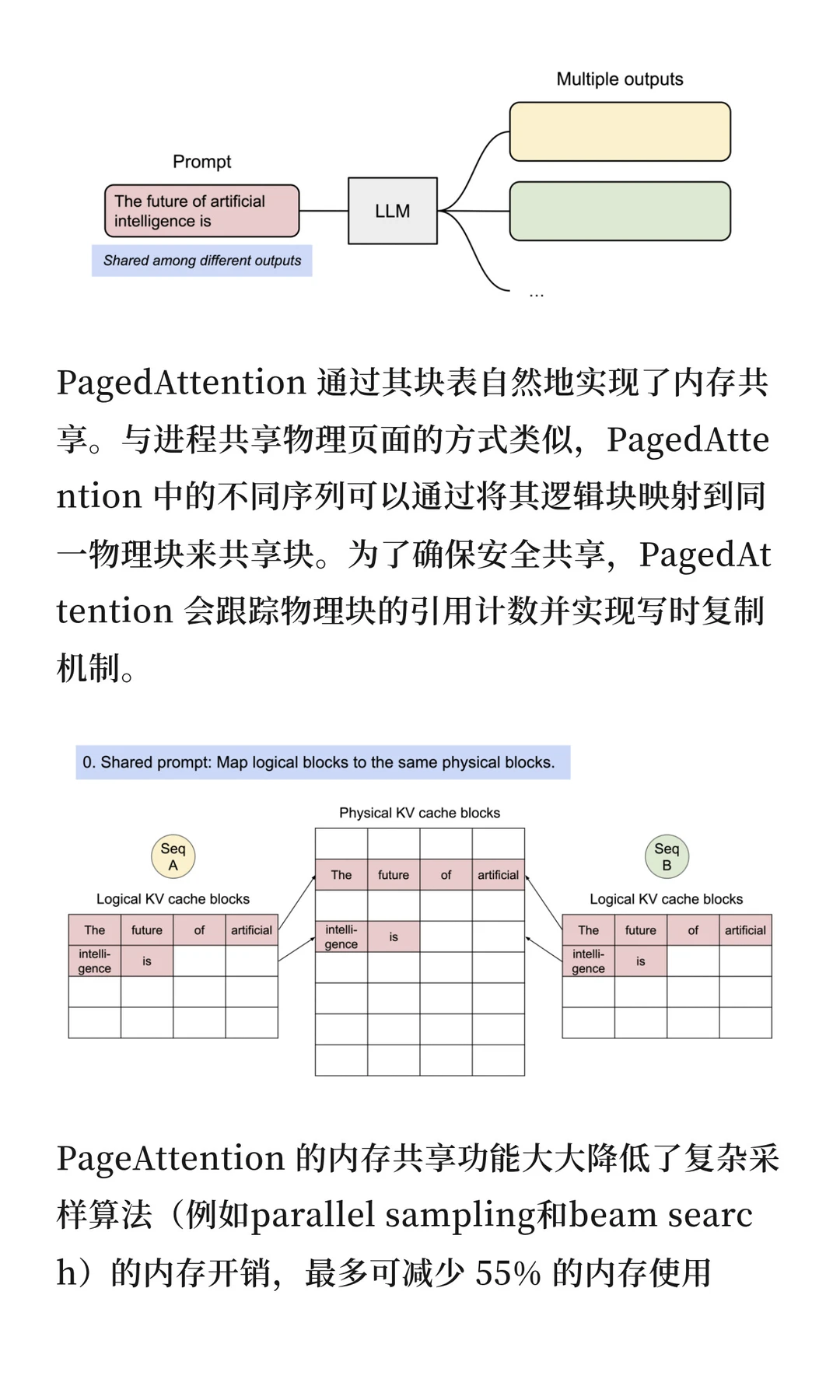
支持多序列共享相同prompt的计算和内存,采用写时复制机制。内存使用最多减少55%,吞吐量提升可达2.2倍。
⚡ 其他核心特性
多GPU支持与连续批处理
推测性解码优化延迟
无缝集成HuggingFace模型
兼容OpenAI API
支持int8量化技术
#动手学大模型 #大模型面试 #LLM #大模型 #大模型推理 #AiChannel #vLLM #PagedAttention #大模型入门
? 核心技术PagedAttention
传统LLM推理的瓶颈在于显存。KV缓存占用巨大,现有系统浪费60-80%的内存。PagedAttention借鉴操作系统虚拟内存思想,将KV缓存分块存储,无需连续内存空间。通过块表映射逻辑块到物理块,内存浪费率降至4%以下。这种设计能批处理更多序列,显著提高GPU利用率和吞吐量。
? 内存共享机制
支持多序列共享相同prompt的计算和内存,采用写时复制机制。内存使用最多减少55%,吞吐量提升可达2.2倍。
⚡ 其他核心特性
多GPU支持与连续批处理
推测性解码优化延迟
无缝集成HuggingFace模型
兼容OpenAI API
支持int8量化技术
#动手学大模型 #大模型面试 #LLM #大模型 #大模型推理 #AiChannel #vLLM #PagedAttention #大模型入门