






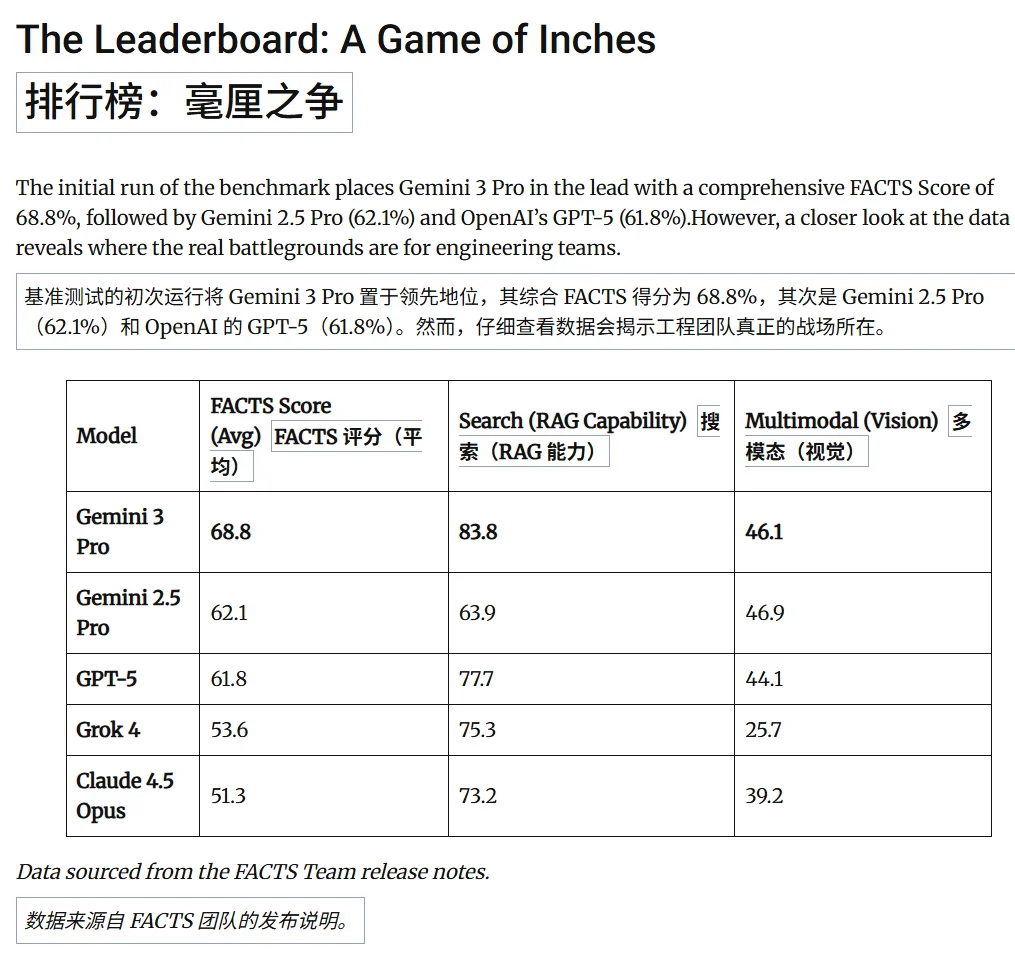
谷歌DeepMind发布全新FACTS基准测试,揭示了一个残酷现实:即便是最顶尖的AI模型,在生成长篇事实性内容时也难以突破70%的准确率天花板。
这一发现打破了技术速胜论的幻想,表明即便结合搜索增强,解决AI“幻觉”仍是当前最大的行业挑战。
谷歌DeepMind推出了一个名为FACTS的评估框架,专门用于衡量大语言模型在生成长篇内容时的“事实准确性”,填补了以往测试仅关注简短问答的空白。
不过,测试结果令人震惊,即便是目前最先进的模型(包括Gemini和GPT-4),在面对复杂问题时,其事实准确率(F1分数)普遍停滞在50%-70%之间。这意味着AI生成的长内容中仍包含大量错误或无法验证的信息。
搜索增强(RAG)也并非万能灵药,研究发现,虽然让模型联网搜索(Search-Grounding)能显著提升准确性,但仍无法彻底解决幻觉问题。搜索工具有时甚至会引入无关信息或被模型错误引用,导致新的错误类型。
对于金融、法律和医疗等对准确性要求极高的行业来说,依赖当前的AI模型生成长报告存在巨大风险,人工核查依然不可或缺。
该研究强调,未来的AI竞争不应仅看推理能力或速度,而应回归本质,将“长文本事实性”作为核心指标。在突破这一天花板之前,全自动的AI代理(Agents)很难真正赢得人类的信任。
https://storage.googleapis.com/deepmind-media/FACTS/FACTS_benchmark_suite_paper.pdf
#人工智能 #openai #显卡 #大模型 #deepseek #谷歌
这一发现打破了技术速胜论的幻想,表明即便结合搜索增强,解决AI“幻觉”仍是当前最大的行业挑战。
谷歌DeepMind推出了一个名为FACTS的评估框架,专门用于衡量大语言模型在生成长篇内容时的“事实准确性”,填补了以往测试仅关注简短问答的空白。
不过,测试结果令人震惊,即便是目前最先进的模型(包括Gemini和GPT-4),在面对复杂问题时,其事实准确率(F1分数)普遍停滞在50%-70%之间。这意味着AI生成的长内容中仍包含大量错误或无法验证的信息。
搜索增强(RAG)也并非万能灵药,研究发现,虽然让模型联网搜索(Search-Grounding)能显著提升准确性,但仍无法彻底解决幻觉问题。搜索工具有时甚至会引入无关信息或被模型错误引用,导致新的错误类型。
对于金融、法律和医疗等对准确性要求极高的行业来说,依赖当前的AI模型生成长报告存在巨大风险,人工核查依然不可或缺。
该研究强调,未来的AI竞争不应仅看推理能力或速度,而应回归本质,将“长文本事实性”作为核心指标。在突破这一天花板之前,全自动的AI代理(Agents)很难真正赢得人类的信任。
https://storage.googleapis.com/deepmind-media/FACTS/FACTS_benchmark_suite_paper.pdf
#人工智能 #openai #显卡 #大模型 #deepseek #谷歌