




























判别式推荐模型本质上是一个基于评分的框架,通过预测用户对候选物品的点击、购买等交互概率来进行排序。尽管应用广泛,但其面临着三个核心瓶颈:
嵌入层局限:传统模型为海量稀疏ID分配独立嵌入的方式,导致了严重的“语义孤岛”问题,加剧了冷启动挑战。更为关键的是,庞大的嵌入表占据了模型超过90%的参数,带来了巨大的存储和计算开销,这种方式在参数利用上是极其低效的。
架构效率低下:判别式系统通常依赖于多种专用、异构的计算算子,这不仅导致了显著的通信开销,还造成了极低的硬件利用率。其模型浮点运算利用率 (Model FLOPS Utilization, MFU) 通常低于5%,与大语言模型 (LLM) 训练时超过40%的MFU形成鲜明对比,凸显了其架构上的根本性低效。
优化目标局限:判别式训练策略通常局限于优化局部决策边界,缺乏对物品完整概率分布的刻画。在工业实践中,为应对延迟约束而设计的多阶段级联系统(如召回、粗排、精排、重排)更是不可避免地引入了累积误差,逐层的信息损失最终会降低推荐质量。
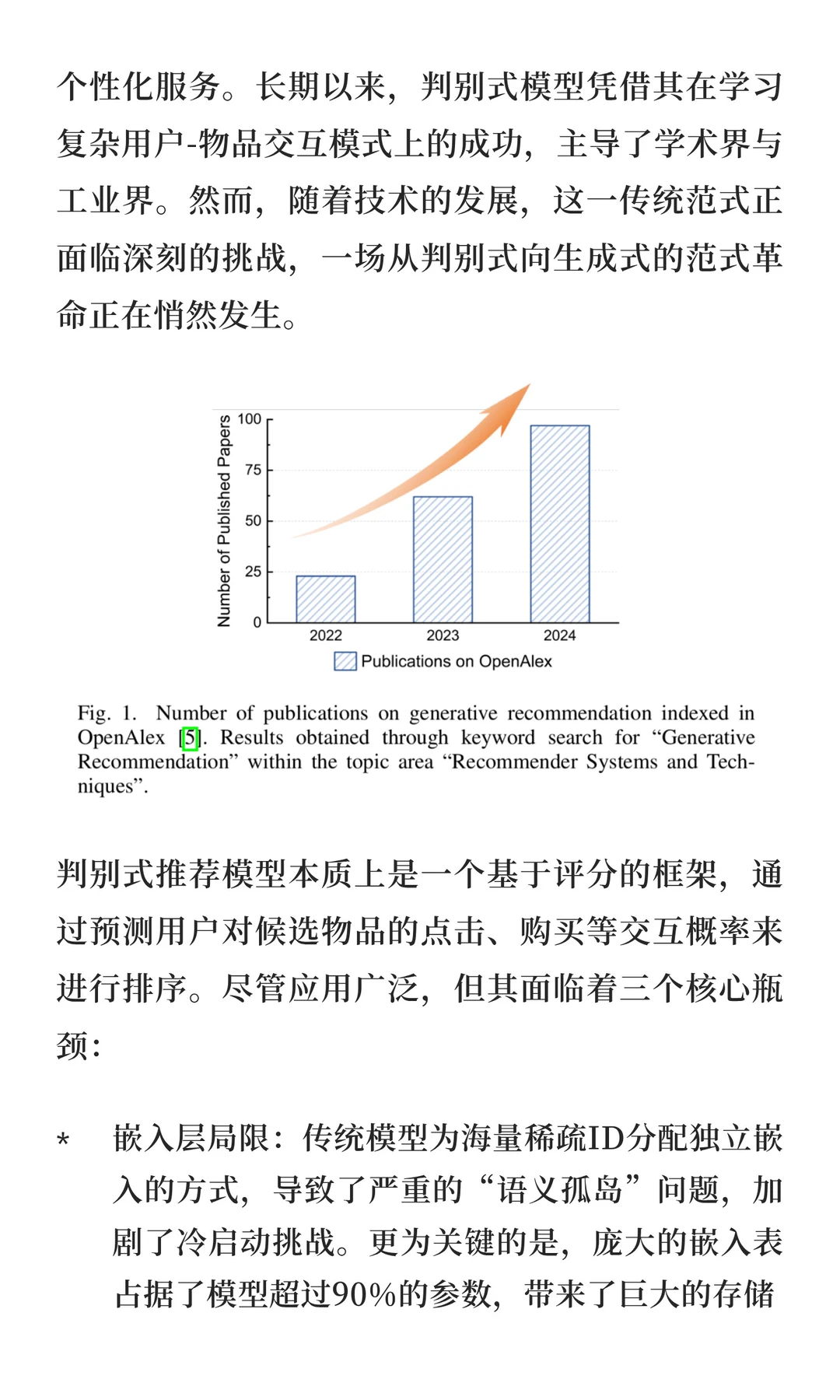
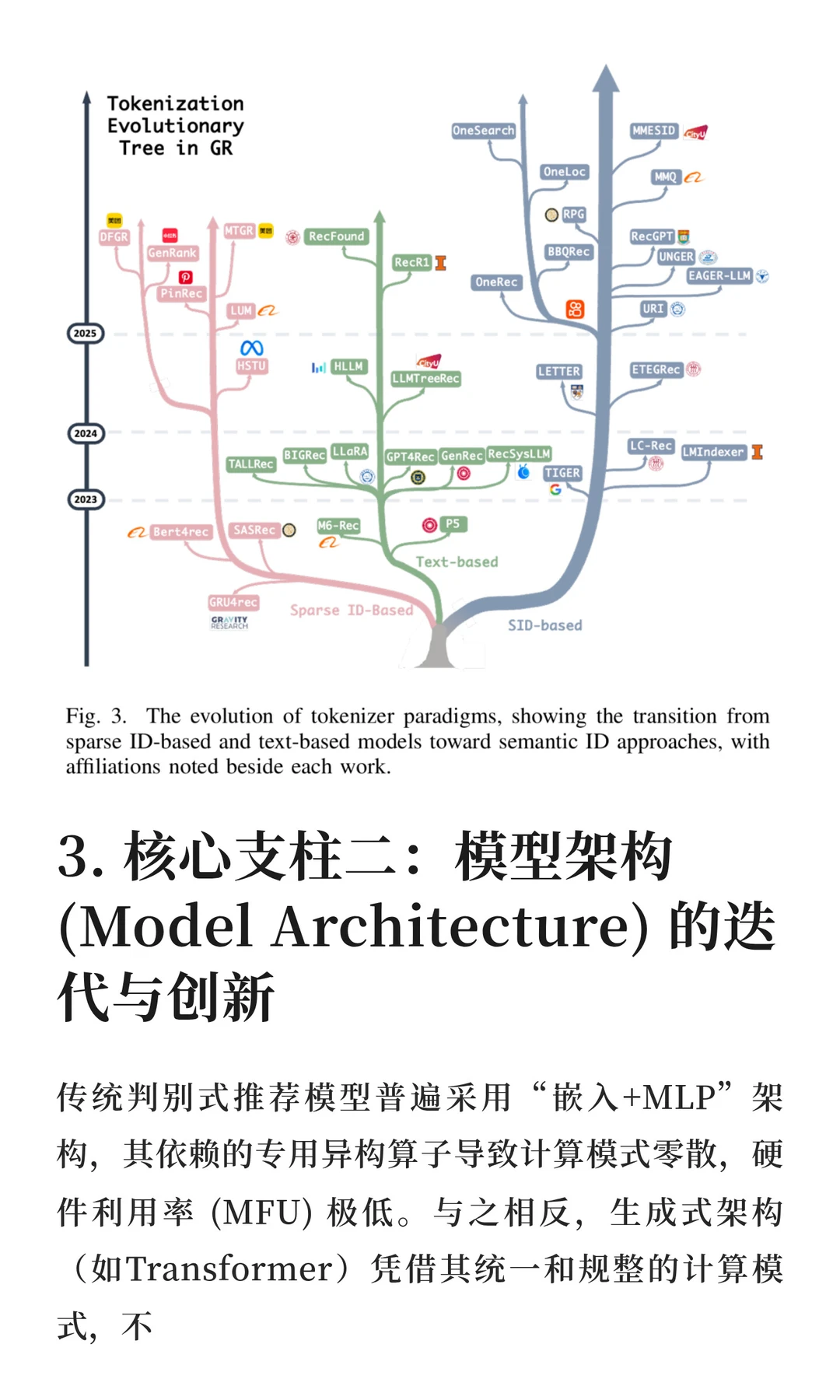
为突破这些瓶颈,生成式推荐 (Generative Recommendation, GR) 应运而生。它将推荐任务重构为一个序列生成问题,不再对候选集进行评分排序,而是直接生成物品标识符。这一新范式在词元化 (tokenization)、模型架构 (architecture)和优化策略 (optimization)三个核心维度上实现了革命性突破。
#算法 #算法岗 #推荐算法 #推荐系统 #生成式推荐 #文献综述 #快手 #推广搜 #研究报告
嵌入层局限:传统模型为海量稀疏ID分配独立嵌入的方式,导致了严重的“语义孤岛”问题,加剧了冷启动挑战。更为关键的是,庞大的嵌入表占据了模型超过90%的参数,带来了巨大的存储和计算开销,这种方式在参数利用上是极其低效的。
架构效率低下:判别式系统通常依赖于多种专用、异构的计算算子,这不仅导致了显著的通信开销,还造成了极低的硬件利用率。其模型浮点运算利用率 (Model FLOPS Utilization, MFU) 通常低于5%,与大语言模型 (LLM) 训练时超过40%的MFU形成鲜明对比,凸显了其架构上的根本性低效。
优化目标局限:判别式训练策略通常局限于优化局部决策边界,缺乏对物品完整概率分布的刻画。在工业实践中,为应对延迟约束而设计的多阶段级联系统(如召回、粗排、精排、重排)更是不可避免地引入了累积误差,逐层的信息损失最终会降低推荐质量。
为突破这些瓶颈,生成式推荐 (Generative Recommendation, GR) 应运而生。它将推荐任务重构为一个序列生成问题,不再对候选集进行评分排序,而是直接生成物品标识符。这一新范式在词元化 (tokenization)、模型架构 (architecture)和优化策略 (optimization)三个核心维度上实现了革命性突破。
#算法 #算法岗 #推荐算法 #推荐系统 #生成式推荐 #文献综述 #快手 #推广搜 #研究报告