




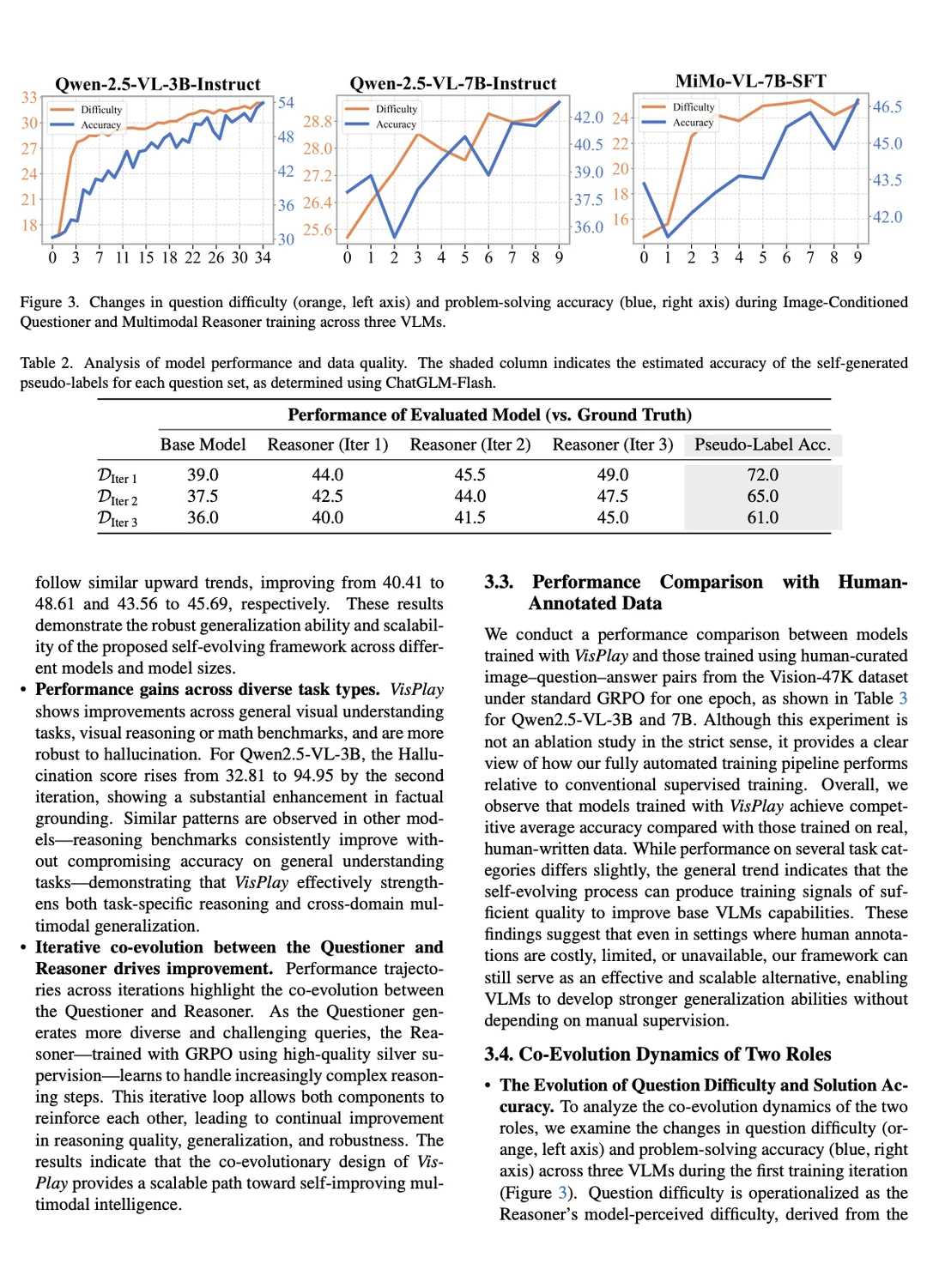
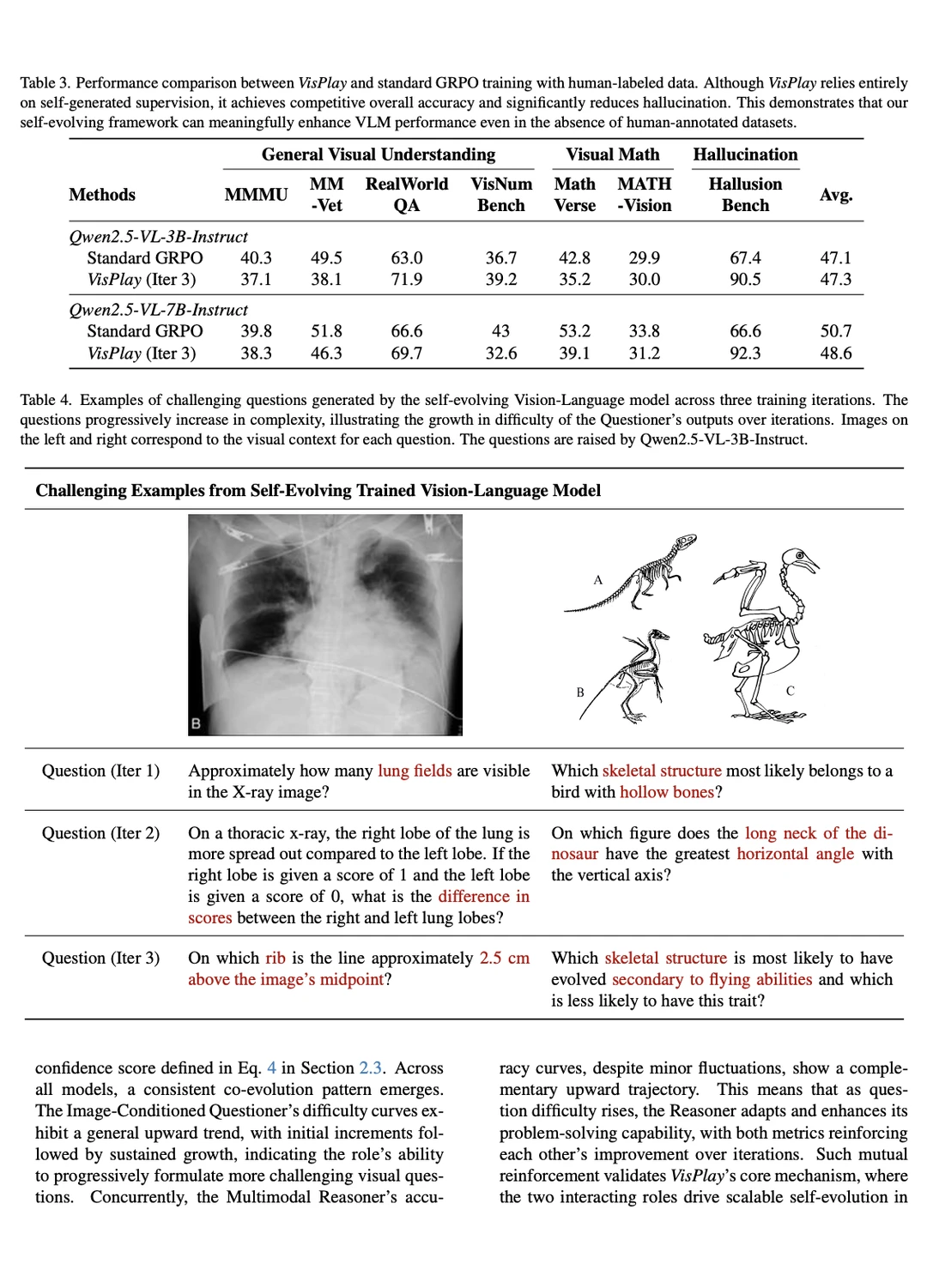



强化学习(RL)被证明可以有效地提升视觉-语言模型(VLM)的复杂推理能力。
然而,现有 RL 方法通常依赖于人工标注的标签或任务特定的启发式方法来定义可验证的奖励,成本高且难扩展。
在这项工作中,来自伊利诺伊大学厄巴纳-香槟分校、圣路易斯华盛顿大学和马里兰大学的研究团队,提出了一个自进化 RL 框架——VisPlay,使得 VLM 能够利用大量未标注的图像数据自主提升推理能力。
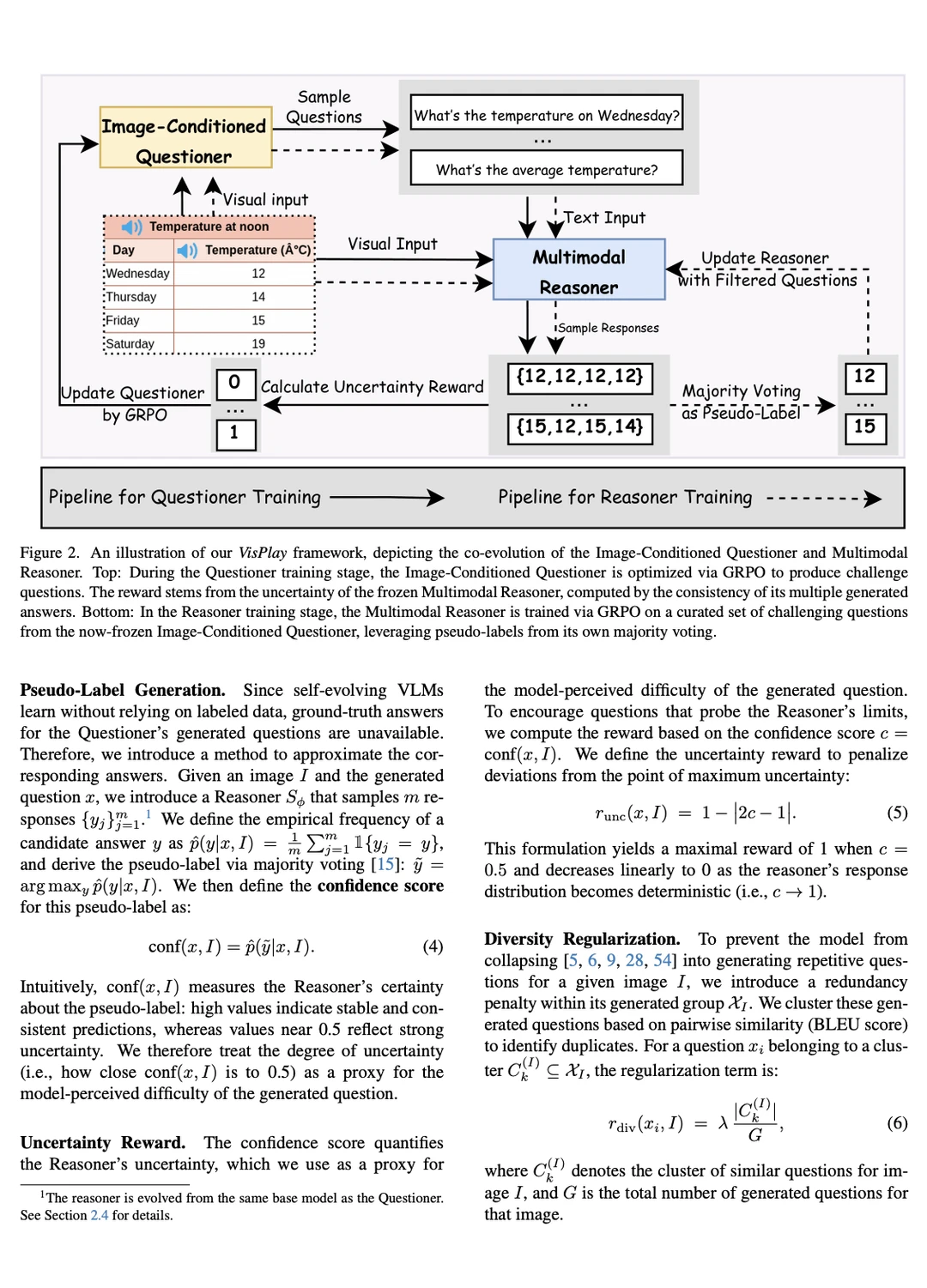
VisPlay 从一个单一的基础 VLM 开始,将模型分配给两个协同角色:一个图像约束提问器,用于制定具有挑战性但可回答的视觉问题;以及一个多模态推理器,用于生成次级(silver)响应。这两个角色通过群体相对策略优化(GRPO)联合训练,融合多样性和难度奖励,从而平衡生成问题的复杂性和次级答案的质量。
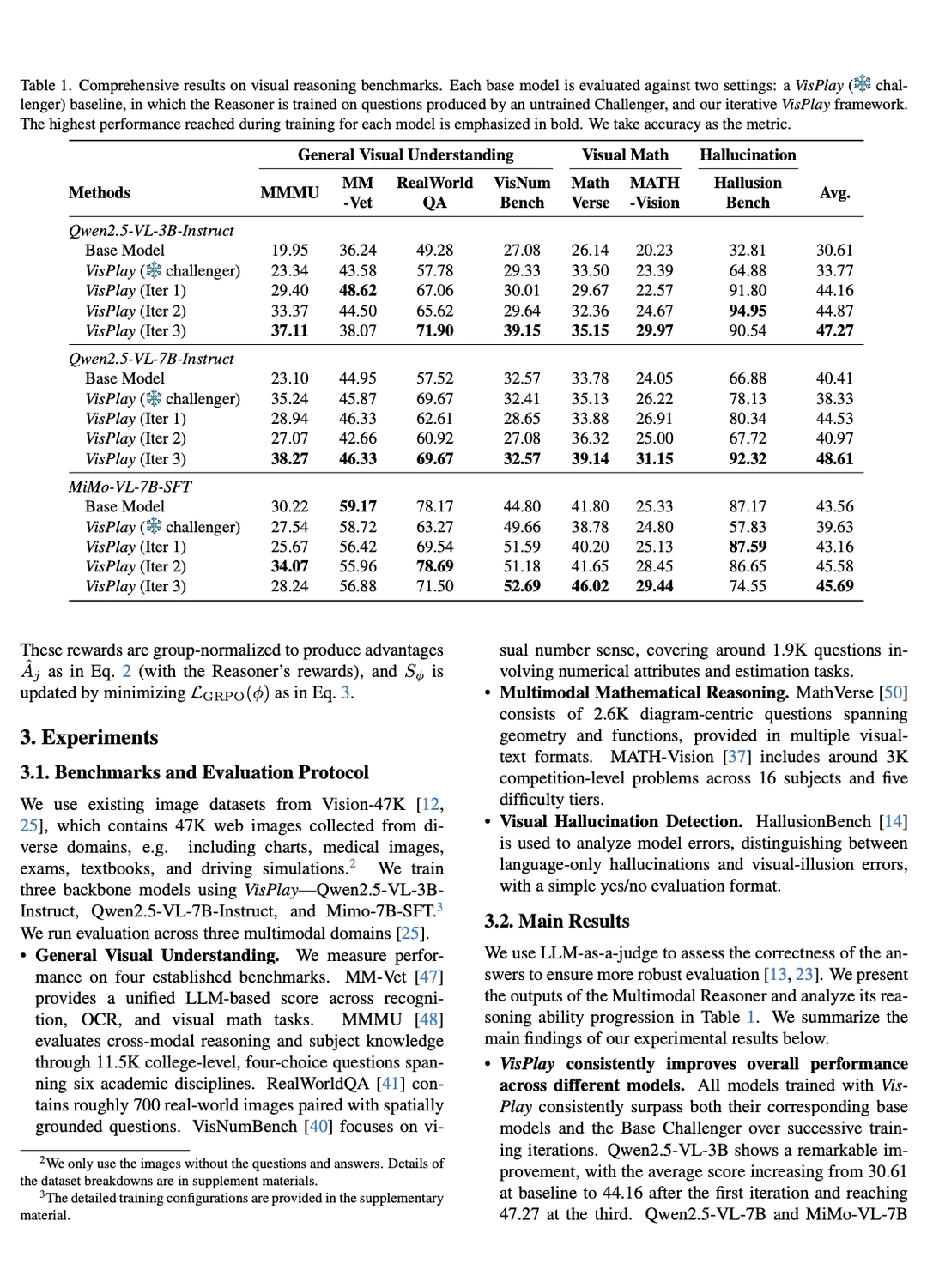
VisPlay 在两个模型家族中均展现出高效扩展性。当在 Qwen2.5-VL 和 MiMo-VL 上进行训练时,VisPlay 在包括 MM-Vet 和 MMMU 在内的 8 个基准测试中,实现了视觉推理、组合泛化和幻觉减少的持续改进,展示了一条迈向自进化多模态智能的可扩展路径。
paper 1104:VisPlay: Self-Evolving Vision-Language Models from Images
#大模型 #ai #多模态人工智能 #视觉语言模型 #VLM #强化学习 #伊利诺伊大学香槟分校 #圣路易斯华盛顿大学 #马里兰大学 #带你一起读论文
然而,现有 RL 方法通常依赖于人工标注的标签或任务特定的启发式方法来定义可验证的奖励,成本高且难扩展。
在这项工作中,来自伊利诺伊大学厄巴纳-香槟分校、圣路易斯华盛顿大学和马里兰大学的研究团队,提出了一个自进化 RL 框架——VisPlay,使得 VLM 能够利用大量未标注的图像数据自主提升推理能力。
VisPlay 从一个单一的基础 VLM 开始,将模型分配给两个协同角色:一个图像约束提问器,用于制定具有挑战性但可回答的视觉问题;以及一个多模态推理器,用于生成次级(silver)响应。这两个角色通过群体相对策略优化(GRPO)联合训练,融合多样性和难度奖励,从而平衡生成问题的复杂性和次级答案的质量。
VisPlay 在两个模型家族中均展现出高效扩展性。当在 Qwen2.5-VL 和 MiMo-VL 上进行训练时,VisPlay 在包括 MM-Vet 和 MMMU 在内的 8 个基准测试中,实现了视觉推理、组合泛化和幻觉减少的持续改进,展示了一条迈向自进化多模态智能的可扩展路径。
paper 1104:VisPlay: Self-Evolving Vision-Language Models from Images
#大模型 #ai #多模态人工智能 #视觉语言模型 #VLM #强化学习 #伊利诺伊大学香槟分校 #圣路易斯华盛顿大学 #马里兰大学 #带你一起读论文