




百度智能云今年的表现真猛,我翻了下最近发布的三季度财报,百度智能云收入同比增长33%。果然,百度智能云“内化AI能力,基础设施先行”的理念起到了作用。
说实话,这个结果我并不意外,百度智能云一直以来都很被重视。比如说,最近百度百舸,将一套经过生产系统严苛验证的MTP(Multi-Token Prediction,多token预测)高性能推理代码正式开源了。
这可是经过了内部大规模服务验证,稳定性和可靠性都蛮顶的,妥妥的开箱即用神器。重点是“生产级代码”,可直接部署生产级别的优化方案。
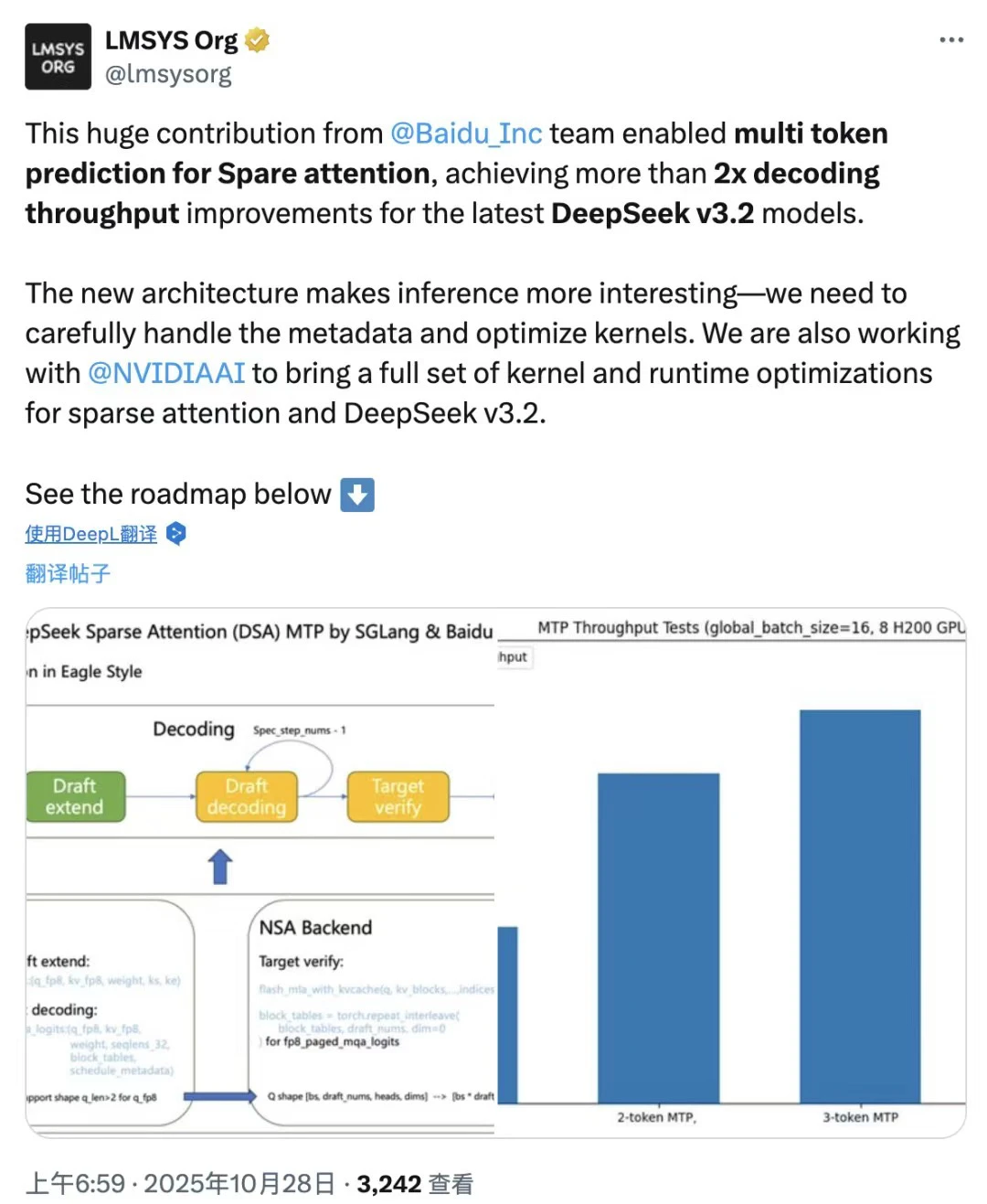
SGLang社区实测,用上这套代码后,最新的DeepSeek-V3.2模型解码吞吐量直接提升2倍。2倍啊,这是什么概念?就是让你的AI模型跑得飞快,效率翻倍,省下的时间都能多喝两杯奶茶了。
本次开源的核心,是一个为DeepSeek-V3.2 全新 DSA(DeepSeek Sparse Attention)架构量身定制的 MTP 实现。
DeepSeek Sparse Attention 通过“只计算有价值的注意力”,在保证模型理解力的前提下,大幅提升长序列处理效率,为长上下文、低成本推理提供了基础设施级的优化。
也就说,MTP通过让模型在单个前向传播中一次性预测多个未来 token,然后统一验证的方式,显著减少了生成完整序列所需的总步骤数。其核心价值在于,通过改变传统解码模式来突破效率瓶颈。
是不是有点摸不着头脑?我再详细解释下。
传统方式(自回归解码):模型每次只生成一个 token,生成下一个时,必须等待上一个完成。如同逐字输入,过程稳定但速度存在瓶颈。
MTP方式(批量生成,集中验证):模型会一次性智能地推算出多个后续 token 作为候选,然后统一进行验证。这好比从逐字输入升级为智能联想输入,一次性能提供多个候选词句,从而大幅减少生成轮次,突破序列化瓶颈。
百度百舸这次开源,是面向自己部署DeepSeek-V3.2的开发者和团队。主要是作用在开发者自己部署的模型中,而且百度百舸团队后面还会持续向SGlang等社区开发更多生产级别的代码。
对于百度智能云的这波领先,你怎么看?
#百度百舸#百度智能云#大模型#科技#大厂#deepseek
说实话,这个结果我并不意外,百度智能云一直以来都很被重视。比如说,最近百度百舸,将一套经过生产系统严苛验证的MTP(Multi-Token Prediction,多token预测)高性能推理代码正式开源了。
这可是经过了内部大规模服务验证,稳定性和可靠性都蛮顶的,妥妥的开箱即用神器。重点是“生产级代码”,可直接部署生产级别的优化方案。
SGLang社区实测,用上这套代码后,最新的DeepSeek-V3.2模型解码吞吐量直接提升2倍。2倍啊,这是什么概念?就是让你的AI模型跑得飞快,效率翻倍,省下的时间都能多喝两杯奶茶了。
本次开源的核心,是一个为DeepSeek-V3.2 全新 DSA(DeepSeek Sparse Attention)架构量身定制的 MTP 实现。
DeepSeek Sparse Attention 通过“只计算有价值的注意力”,在保证模型理解力的前提下,大幅提升长序列处理效率,为长上下文、低成本推理提供了基础设施级的优化。
也就说,MTP通过让模型在单个前向传播中一次性预测多个未来 token,然后统一验证的方式,显著减少了生成完整序列所需的总步骤数。其核心价值在于,通过改变传统解码模式来突破效率瓶颈。
是不是有点摸不着头脑?我再详细解释下。
传统方式(自回归解码):模型每次只生成一个 token,生成下一个时,必须等待上一个完成。如同逐字输入,过程稳定但速度存在瓶颈。
MTP方式(批量生成,集中验证):模型会一次性智能地推算出多个后续 token 作为候选,然后统一进行验证。这好比从逐字输入升级为智能联想输入,一次性能提供多个候选词句,从而大幅减少生成轮次,突破序列化瓶颈。
百度百舸这次开源,是面向自己部署DeepSeek-V3.2的开发者和团队。主要是作用在开发者自己部署的模型中,而且百度百舸团队后面还会持续向SGlang等社区开发更多生产级别的代码。
对于百度智能云的这波领先,你怎么看?
#百度百舸#百度智能云#大模型#科技#大厂#deepseek