


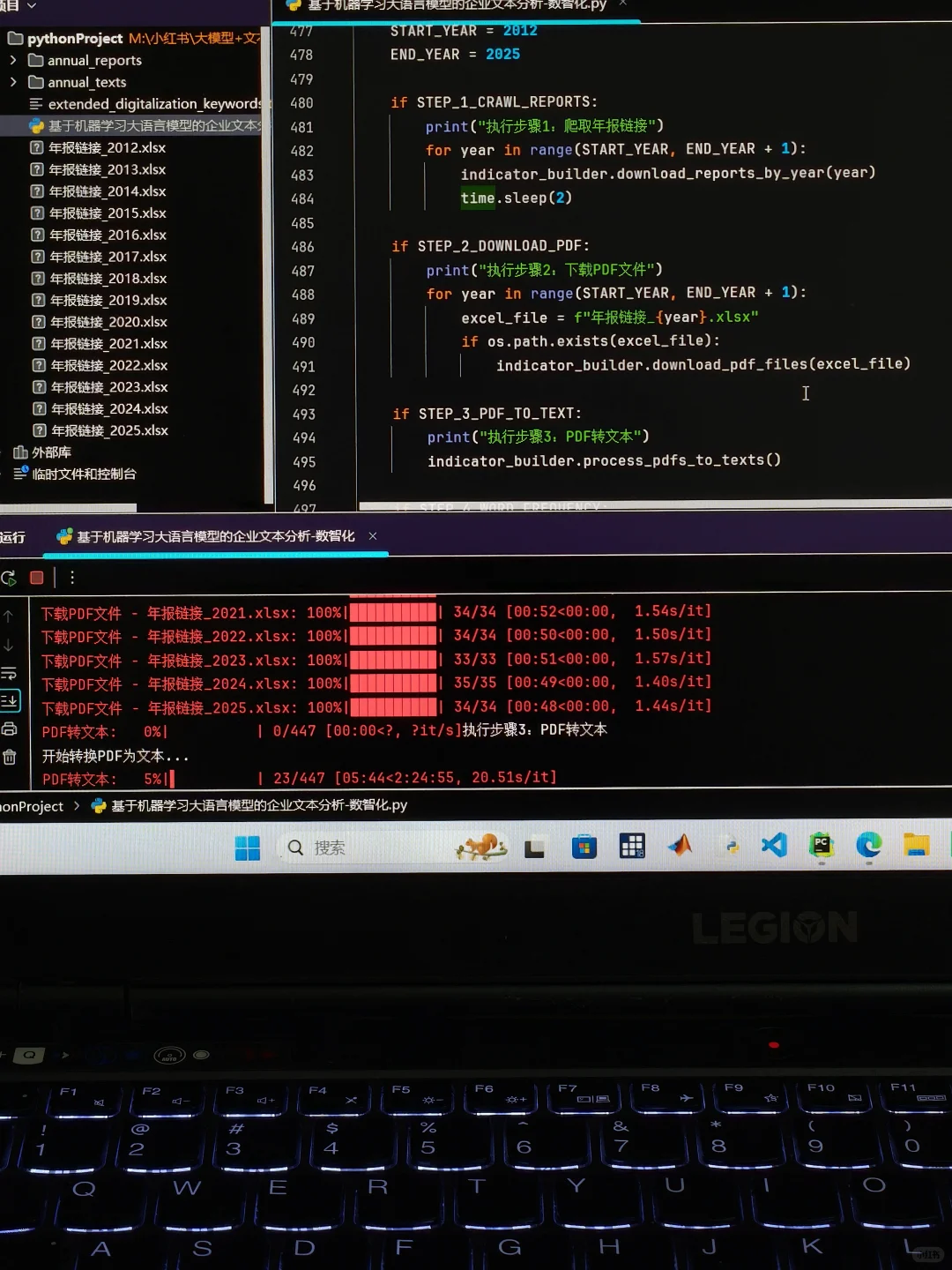
基于上市公司企业年报和MD&A数据实现企业数智化转型测度,主要工作如下:
—— 1.数据挖掘 ——
从巨潮资讯网(cninfo)爬取A股上市公司PDF年报
过滤非年报内容(摘要,英文版,公告等)
—— 2.PDF文件处理 ——
将PDF转换为TXT格式
使用pdfminer提取文本内容
批量处理多个年份的PDF文件
—— 3.文本预处理与分词 ——
使用jieba进行中文分词,并去除停用词
过滤单字词和无关词汇
按句子分割文本,构建训练语料
—— 4.关键词扩展与语义建模 ——
使用Word2Vec模型训练词向量
基于初始数智化关键词,扩展相似词汇
通过词向量相似度筛选相关词汇
构建扩展后的数智化关键词库
—— 5.数智化测度 ——
统计六类关键词词频:人工智能,大数据,云计算,区块链技术,数字技术应用,智能化应用
计算总词频,词频占比及对数化指标
按年份和公司输出结果
其实思路类似于企业数字化转型的测度方法~
#论文写作 #统计学 #计量经济学 #数据挖掘 #爬虫 #Python #量化 #大模型 #大语言模型 #企业数字化
—— 1.数据挖掘 ——
从巨潮资讯网(cninfo)爬取A股上市公司PDF年报
过滤非年报内容(摘要,英文版,公告等)
—— 2.PDF文件处理 ——
将PDF转换为TXT格式
使用pdfminer提取文本内容
批量处理多个年份的PDF文件
—— 3.文本预处理与分词 ——
使用jieba进行中文分词,并去除停用词
过滤单字词和无关词汇
按句子分割文本,构建训练语料
—— 4.关键词扩展与语义建模 ——
使用Word2Vec模型训练词向量
基于初始数智化关键词,扩展相似词汇
通过词向量相似度筛选相关词汇
构建扩展后的数智化关键词库
—— 5.数智化测度 ——
统计六类关键词词频:人工智能,大数据,云计算,区块链技术,数字技术应用,智能化应用
计算总词频,词频占比及对数化指标
按年份和公司输出结果
其实思路类似于企业数字化转型的测度方法~
#论文写作 #统计学 #计量经济学 #数据挖掘 #爬虫 #Python #量化 #大模型 #大语言模型 #企业数字化