



不知不觉,大模型已经融入我们工作好几年了。
但说句实在话,大部分人手里的 AI,依然只是个**“高级聊天框”**。
你输入一个 Prompt,它给你回一段代码或者文字。你复制走,它功成身退。下一次你想做个新任务,对不起,新建会话,重新复制粘贴上下文,重新教它你的规矩。
这就好比你雇了个助理,人挺聪明,但有个毛病——每天下班一睡觉,第二天准失忆。每天早上你都得花半小时把昨天的进度、公司的规矩重新教他一遍。
累不累啊?
最近,OpenAI 内部悄悄流出一份白皮书,名字叫 《Codex-maxxing for long-running work》(基于 Codex 的长期工作极限优化)。这份白皮书里,OpenAI 首次把 AI 如何从“一次性聊天框”转变为“长期 persistent(持续运行)的工位”这事儿给彻底讲透了。
白皮书的核心主角是一个叫 Codex 的 Agent 环境,以及硅谷知名 AI 开发者 Jason Liu 的真实日常工作流。
读完这份白皮书,我只有一个强烈的感觉:AI Agent 竞争的下半场,拼的根本不是谁的模型推理能力多高几分,而是谁能给 AI 打造一个最舒服的、能干脏活累活的“长期工位”。
今天,咱们就把这份白皮书里透露 of 10 个代表未来 Agent 交互形态的核心能力,掰开揉碎聊一聊。
01. 持久线程与记忆保险库:让 AI 也有个“工位”
首先,大伙儿得明白一件事:为啥以前的 AI Agent 只能活在 Demo 里?
因为“会话丢失”。以前我们和 AI 沟通,所有的上下文都塞在一个 Thread(线程)里。当这个线程越来越长,上下文窗口的成本会成倍暴涨,模型也会开始变得“健忘”和“弱智”。
OpenAI 在白皮书里给出的第一个解法,就是 Durable threads(持久线程) 与 Memory vault(记忆保险库)。
持久线程,说白了就是给特定的项目安个家。比如你有一个“日常周报编写”的项目,或者“开源代码库维护”的项目,你就应该给它开一个置顶且永远不关的持久线程。
在这个线程里,随着时间推移,AI 记住的不仅仅是你的聊天历史,更是你每一次纠正它之后的“偏好”、你们达成的“旧决策”以及还没解决的“开放性问题”。
但这还不够。因为随着时间推移,线程本身的上下文还是会过载。这就需要配合第二件武器:Memory vault(记忆保险库)。
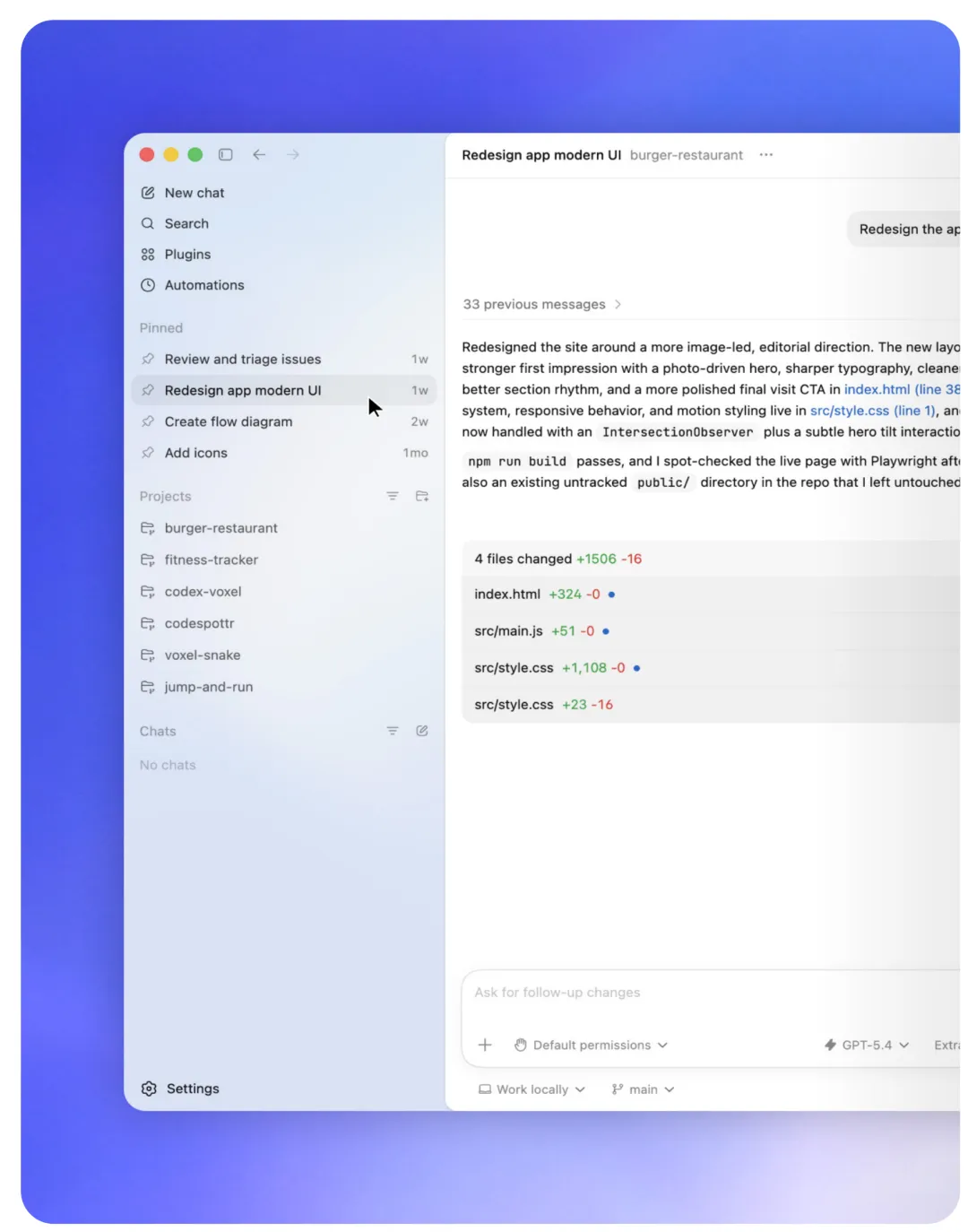
白皮书里提到,真正的 Agent 记忆不应该静默地堆积在聊天历史里。它应该是一个独立的、人机均可读写的结构化文件夹:
1 2 3 4 5
vault/├── TODO.md # 项目的代办清单├── people/ # 项目相关人员的偏好与角色├── projects/ # 各个子项目的状态└── notes/ # 研究、决策和学习沉淀
“代码放在代码仓库,但关于工作的所有滚动上下文,应该放在记忆保险库里。”
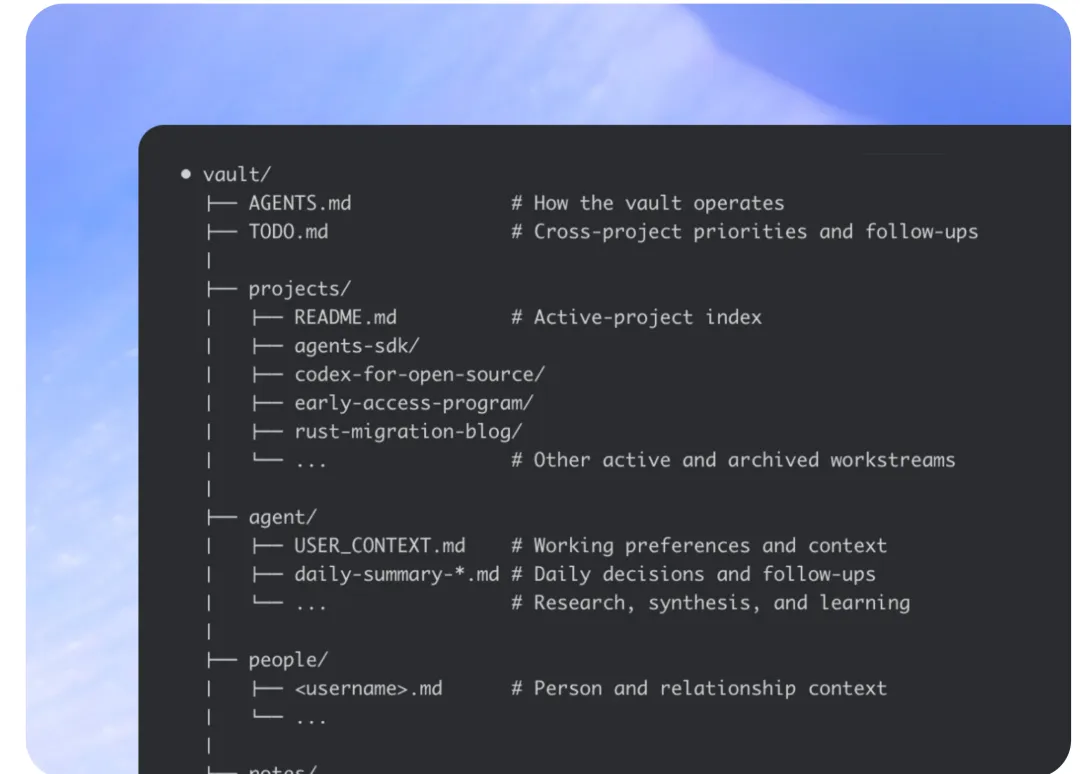
最妙的地方在于,当这个记忆保险库托管在 GitHub 上时,AI 对你偏好或项目规则的每一次更新,都会变成一次 Git Commit。
你可以像审查代码一样,通过**看 Diff(代码对比)**去审查 AI 记下的笔记:
AI 记下了“某某客户不喜欢太激进的文风”; AI 记下了“这个模块的接口在 V2 版本已经弃用”。
你点个同意,这块记忆才真正“写入固化”。这才是真正的可审计、可编辑的 AI 记忆。
02. 语音输入与动态引导:如何把“脑子里的乱线团”扔给 AI?
很多人觉得,给 AI 写 Prompt 是一件极其痛苦的事情。为了让 AI 干对活,你得字斟句酌,生怕说错一个词把它带偏了。
但白皮书里展示了 Jason Liu 的一个反直觉做法:用 Voice input(语音输入)把“最脏最乱”的直觉直接扔给 AI。
比如 Jason 录下的这段语音:
“我想 Slack 里应该有个叫 Ben 的哥们提过这事,我不太记得具体细节了,你去找找看。”
要是让你打字,你大概率不会这么写。因为这听起来太敷衍、太模糊了。但白皮书指出,Spoken input(口语输入)往往包含了最真实的、没有经过人工修饰的思考粗胚。
这种“带着不确定性”和“半记半忘”的语境,反而能够帮助 AI 更好地理解你的意图,并在后续的步骤中,替你去核对和补全那些缺失的线索。
有了这种乱线团式的输入,再配合 Steering(动态引导),人机协作的效率就彻底起飞了。
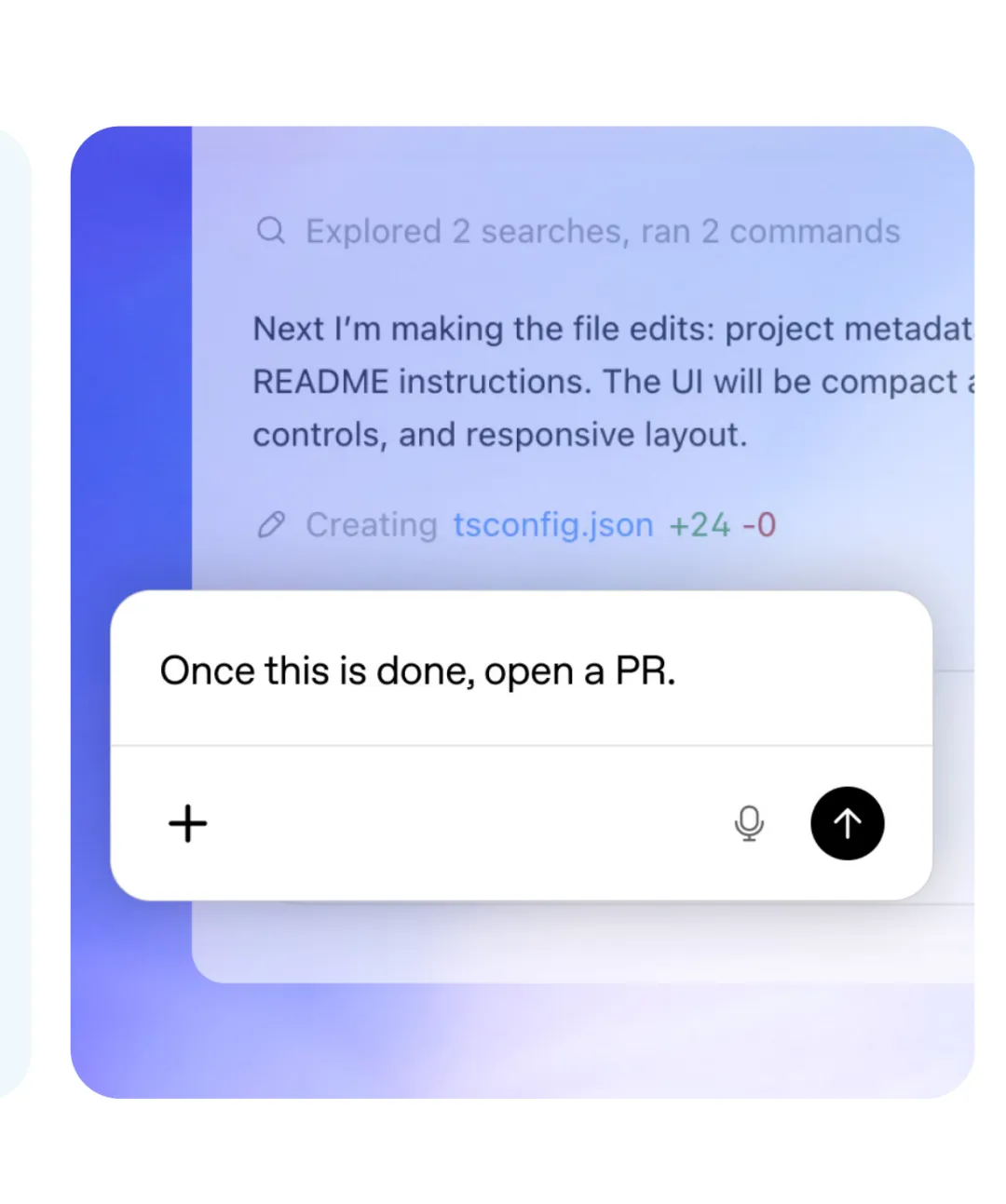
什么是 Steering?说白了就是“车还没停,你就能打方向盘”。
在传统的交互里,AI 运行一个复杂任务时,你只能干看着,直到它输出完毕。如果它在中途走歪了,你只能等它全部跑完,再发一句“不对,重来”。这就像你看着助理花了两天做完一叠 PPT,最后发现第一页的方向就错了。
而在 Codex 的运行环境里,AI 是一边干活,你一边在旁边插话的:
“把这里调小一点。” “这一页的文案写错了。” “完成后,直接去开个 PR。” “在发布预览链接前,先让我确认一下。”
你输入的这些指令,会被实时挂载到 AI 正在执行的**任务队列(Queue)**里。AI 会在执行下一步工具调用前,自动读取并调整自己的行动方向。
这才是真正的“人在回路”(Human-in-the-loop),你不需要等它完全犯了错再去惩罚它,你可以在它刚迈出歪脚的一瞬间,拉它一把。
03. Chrome、本地预览与远程控制:Agent 是怎么“长出四肢”的
当 AI 有了工位和驾驶员,下一步就是给它“长出四肢”,去触碰真实的世界。
白皮书将 Agent 可以触碰的“数字表面”分成了极具工业美感的五个层次:
[$browser]:本地网页沙盒,用于渲染、预览和前端交互。[@chrome]:已登录的浏览器会话,让 AI 可以带着你的身份去操作 SaaS 工具。[@computer]:纯 GUI 桌面操作,AI 像人一样通过点击和拖拽来搞定那些没有 API 的软件。[Connectors]:Slack、Gmail、日历、GitHub 等核心办公表面的连接器。[Skills]:可复用的脚本 and 工作流,让 AI 不用每次都重复造轮子。
这就完美解释了 Jason Liu 是怎么在日常工作里无缝使用 AI 的。
当他在本地开发一个应用时,AI 会在本地通过 [$browser] 实时渲染前端页面,并把预览呈现在**侧边栏(Side panel)**里。
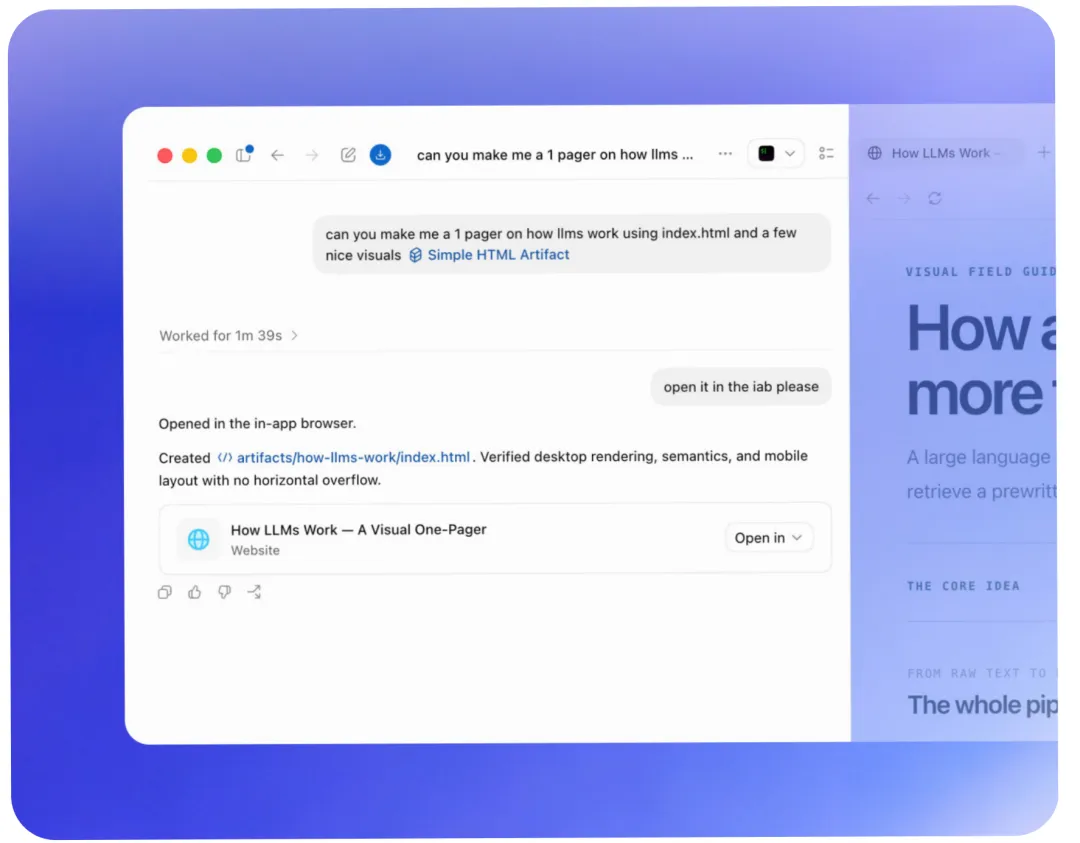
这个侧边栏可不是普通的预览窗口。它是你和 AI 协同操作的实体表面:
屏幕上渲染出来的页面,你可以直接在上面涂鸦,画个圈写上“这里间距调小”,这个圈和文字就会立刻变成 Prompt 传给 AI; AI 生成的 CSV 表格,在侧边栏里可以直接双击单元格修改,修改后的数据立刻作为上下文同步回 AI; 你甚至可以在侧边栏里直接运行 Jupyter 笔记本或 Streamlit 应用,和 AI 交互调试。
“侧边栏,是 Codex 停止成为一个聊天框,真正成为工作发生地的地方。”
更绝的是,这种长期的、需要耗费几个小时甚至几天的任务,不需要你一直守在电脑前。
白皮书展示了 Remote control(远程控制) 的威力:
你在办公室的电脑上启动了一个复杂的重构任务,然后直接下班。在地铁上或者在家里,你掏出手机,通过 Codex 的移动端界面,就能看到 AI 跑到了哪一步。
AI 会弹出一个确认信息:“我已经重构了核心模块,所有单元测试已通过。是否开始部署到预发环境?”
你躺在沙发上,用大拇指点一下“确认”,大洋彼岸的服务器就开始了自动部署。
远程控制不是为了让你逃避审核,而是为了让那些超长周期的任务,不再把人死死扣在电脑桌前。
04. 心跳式的后台唤醒:三个经典 Agent 闭环
如果你觉得上面的技术听起来还有点抽象,咱们来看白皮书里给出的三个最接地气的 Loops(闭环工作流) 实例。
要实现这些闭环,核心是利用 Thread automations(线程自动化)——一种给持久线程设置“心跳闹钟”的机制。它不用每次都从头输入,而是每隔一段时间,自动唤醒当前线程,带着之前的全部记忆去跑一次。
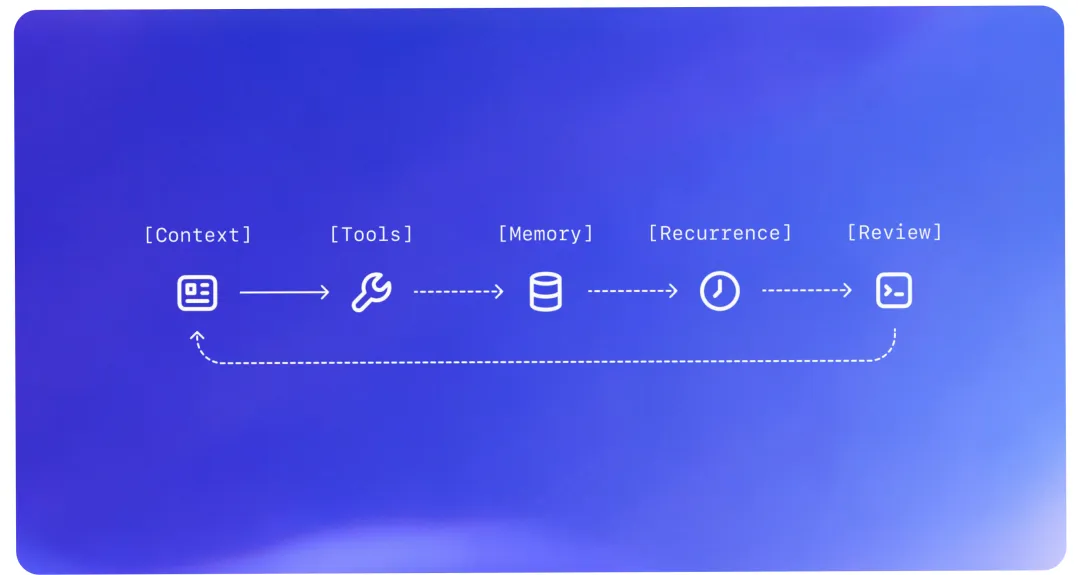
循环 1:【幕僚长】(Chief of Staff)
设定:AI 每 30 分钟被自动唤醒一次。 干的活:去 Slack 和 Gmail 里翻看有没有未读的、需要回复的重要消息;结合记忆库里的项目上下文,去搜索背景资料;给每一条重要消息自动起草好回复草稿,并整理出需要主人亲自做决策的难点问题。 你做的事:早上醒来,打开侧边栏,花三分钟审核 AI 拟好的草稿,修改语气,点击“发送”。
循环 2:【反馈监控员】(Monitor for feedback)
设定:每当 Slack 频道里有人对动画演示提出反馈意见时,自动唤醒。 干的活:AI 读取 Slack 里的文字反馈,自动修改本地的 Remotion(一个用 React 写视频的框架)代码,在后台重新渲染视频,并生成一份改动清单,把新的视频链接贴在审核区。 你做的事:点开视频看看改得合不合心意,做出审美判断,点击同意发布。
循环 3:【退款谈判专家】(Get a refund)
设定:每 5 分钟自动检测一次某客服网页的客服是否上线。 干的活:一旦客服客服加入聊天,AI 自动切换到“每分钟唤醒”的高频状态,用事先准备好的订单证据和客服进行退款交涉,自动撰写回复,但把所有可能导致不可逆结果的敏感操作拦住,等待人类最终确认。 你做的事:授权同意退款方案。
这三个例子,直接把 AI Agent 从“玩具”拉到了“数字劳动力”的高度。它不是一次性帮你写首诗,而是像一个看不见的影子员工,在后台年复一年地帮你盯着那些繁琐的日常。
05. 什么是“可验证的目标”?别再给 AI 提模糊要求了
不过,要让这种长期运行的 Agent 不掉链子,白皮书里提出了最关键的一个思维转变:Set goals Codex can verify(设定 AI 可以自行验证的目标)。
OpenAI 在书里无情地嘲讽了那些“弱目标”(Weak goals):
❌ 弱目标:“去把这个 Markdown 文件里的重构方案给实现了。”
这种目标对 Agent 来说就是灾难。因为 AI 根本不知道自己做到什么程度才算“完成了”。最后的结果大概率是,它改了几个文件,然后告诉你“我改好了”,至于改对没有、跑得通不,它一概不管。
而白皮书极力推崇的是“强目标”(Strong goals):
强目标:“把这个 Python 库移植到 Rust。保证所有的公共 API 与原库完全兼容,并使用原库自带的单元测试集作为成功标准。当且仅当所有测试全部通过,且两者的接口差异被完整记录到 diff.md 里时,任务才算完成。”
这个“强目标”的精髓就在于可验证性。
白皮书里举了 Jason Liu 亲自做的一个“Rich 库向 Rust 移植”的例子。在这个任务里,Agent 会不断在后台修改代码,然后自动运行测试命令:
cargo test
$$passed$$
只要有一个测试挂了,Agent 就知道任务没完,它会读取测试报错,自己回炉重造,继续改代码,直到终端屏幕上绿色的 passed 铺满屏幕。
只有当目标能够被程序化验证时,AI Agent 才能真正实现后台的“自主纠错”与“自动停机”。否则,它要么在死循环里烧光你的 Token,要么在敷衍了事中交付一堆垃圾。
结语:剥掉 AI 的营销糖衣,终局在工位上
聊到最后,大伙儿应该看出来了。
OpenAI 这份白皮书,其实是在给大伙儿“祛魅”。
它把那些被炒上天的、玄而又玄的 AI Agent 概念,剥掉了所有科幻外衣,还原成了一个非常现实的软件工程和交互设计问题。
未来的 AI,绝不是一个你输入一句话就能替你拯救世界的“许愿机”。
它更像是一个有些粗心但极度勤奋 of 初级员工。要让他发挥出真正的价值,我们需要给他提供:
一个放得下项目图纸的工位(Durable threads); 一本随时更新、写满公司规矩的备忘录(Memory vault); 一套能随时看到工作进度的仪表盘(Side panel); 以及一条能随时纠正他方向的安全绳(Steering)。
科技依然在狂飙,但大局已定。
未来的工作方式,不取决于谁能写出最精妙的 Prompt,而取决于谁能先一步把自己的日常,拆解并组装成这一个个精密的、可验证的后台循环。
而这一天,已经离我们不远了。