


面向 Dual Home 以太网场景的链路联动、故障感知与快速收敛机制
在双上联接入、园区汇聚、站内网络以及其他需要主备路径的以太网场景中,链路冗余并不等于业务一定可用。设备本地看到的端口 Link 可能仍然存在,但上游路径已经失去真实连通性;如果缺少跨端口、跨设备的联动机制,网络就可能在“链路未断、业务已断”和“主备并存、形成环路”之间反复暴露风险。
Follow Link 是福州太微信息技术有限公司推出的一套链路联动机制,其中使用的 FLP(Follow Link Protocol)属于太微私有协议报文。它面向 Dual Home 场景里的路径判断、主备切换和 MAC 快速收敛问题,用来让备用链路在需要时接管业务,同时尽量避免主备链路并存带来的环路风险。
从工程视角看,Follow Link 的价值不在于“多一个功能项”,而在于把链路可用性判断、备用链路控制和状态恢复后的邻居刷新组织成一条完整的控制链路。这样,设备既能抑制环路,又能在主路径失效时推动业务尽快切换到可用路径。

图 1 Follow Link 在 Dual Home 以太网场景中的联动与切换示意
为什么 Dual Home场景需要Follow Link
从以太网双上联的通用理解看,Dual Home的本质是把边缘设备同时接入两个上游方向,以获得接入侧的冗余能力。常见做法并不是让两条路径同时无条件转发,而是让一条路径承担主业务,另一条路径作为备用通道等待接管。这种结构部署直接、成本可控,因此在各类接入侧和汇聚边缘都很常见。
但 Dual Home天生带来两个工程难题。第一,如果主备路径同时放开,二层网络很容易形成环路;第二,如果设备只看本端口的Link状态,就可能出现“链路看起来还在,真正到上层网络的通路却已经失效”的情况。也就是说,Dual Home不只是冗余问题,更是路径判定和联动控制问题。
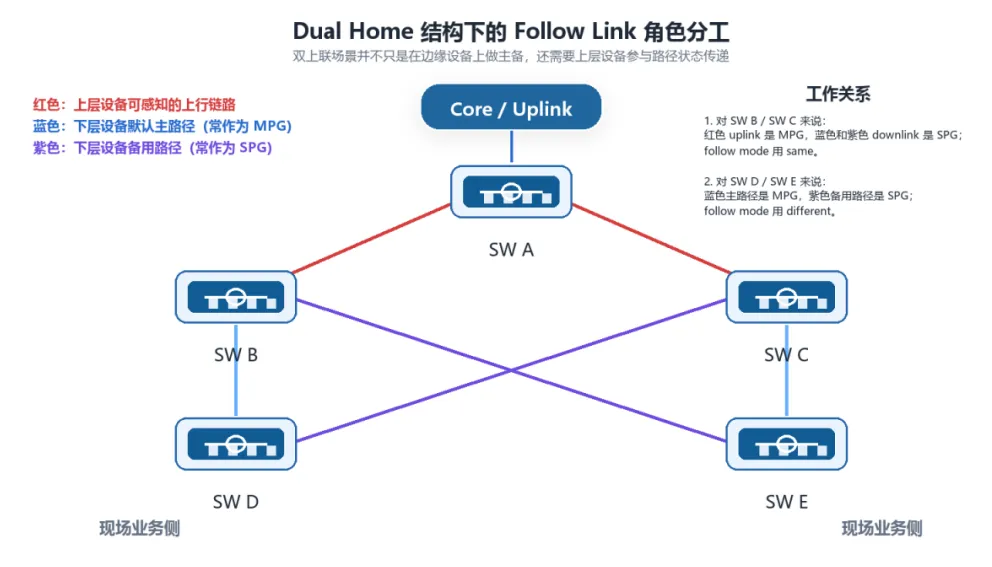
图2 Dual Home结构下Follow Link的角色分工与路径关系
Follow Link的核心对象:FLG、MPG与SPG
Follow Link以FLG(Follow Link Group)为基本组织单元。一个FLG内部包含两个核心对象:MPG(Master Port Group)和SPG(Slave Port Group)。可以把MPG理解为“负责触发判断的主端口组”,把SPG理解为“根据主端口组状态进行联动的从端口组”。
在工程使用上,MPG和SPG都可以由物理端口或聚合端口组成。它们并不是简单的端口开关,而是在一个状态机里协同工作:MPG先得到自身是否处于Normal、Down、Disconnect或Close等状态,SPG再根据Follow mode选择进入Normal或Forbidden。
这种抽象的好处,是把“路径判断”和“动作执行”稳定地分开。网络规模扩大后,运维人员不需要逐端口记忆主备逻辑,而是围绕FLG理解一组链路如何一起行动。
源文档里的配置案例有一个很关键的理解点:MPG和SPG是按设备本地FLG来定义的,不是给一根物理链路贴一个全局唯一角色。也正因为这样,同一根蓝色物理链路,对SW B / SW C来说属于downlink SPG,对SW D / SW E来说却属于上行MPG;紫色链路虽然也同时出现在上下层设备中,但对应的是不同设备、不同FLG里的备用方向。
链路可用性如何被判断
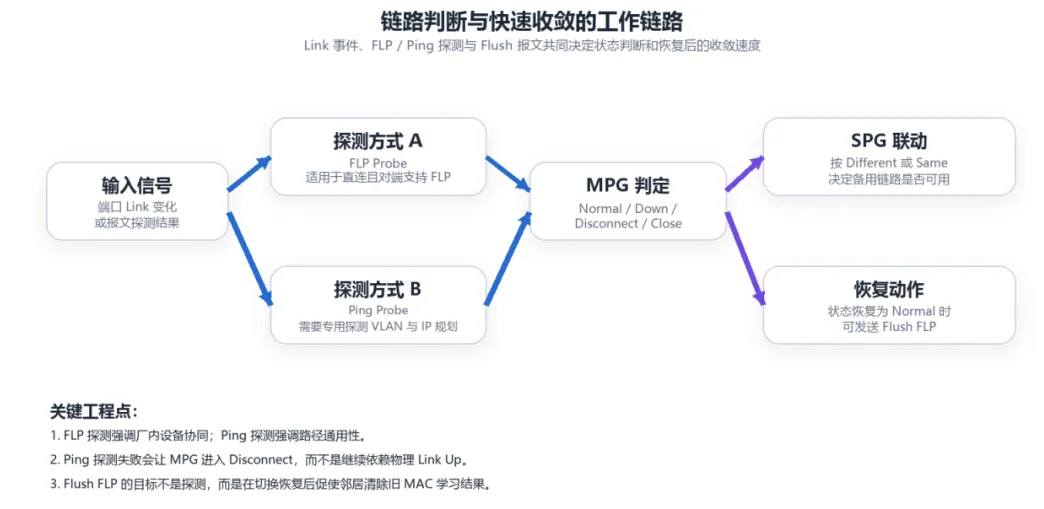
Follow Link不把链路可用性简单等同于物理Link Up。源文档给出的判断依据有两类:一类是成员端口的Link事件,另一类是报文探测结果。前者反映端口物理层状态,后者反映路径在业务层面的真实可达性。
在 Link事件层面,MPG支持any与all两种down判定方式。any更保守,只要任一成员端口down,MPG即可进入Down;all更强调整体冗余能力,只有所有成员端口都down,MPG才进入Down。这决定了设备对局部故障是“立即收缩”还是“继续容忍”。
在报文探测层面,FLP Probe与Ping Probe面向不同场景。FLP Probe更适合直连、同厂设备协同的探测;Ping Probe则更通用,可以穿越中间二层设备,但需要额外规划探测VLAN和IP地址。也就是说,Ping的优势是通用,代价是部署前提更明确。
当探测连续失败时,MPG会进入Disconnect,而不是继续把物理Link Up当作可用。对Dual Home组网来说,这一点非常关键:它让设备具备了“链路没断,但路径已失效”的识别能力。
跟随机制如何实现业务切换与环路抑制
SPG的行为由Follow mode决定,其中最有工程意义的是Different和Same两种模式。Different模式适合下层双归设备:当MPG正常时,SPG被置为Forbidden,备用链路不承载业务;当MPG进入非Normal状态时,SPG恢复可用,网络由此完成主备切换。
Same模式更适合上层设备把故障向下游显式传递。换句话说,上层设备一旦发现自己的上行路径异常,就可以让与之关联的SPG也进入受控状态,从而让下游设备尽快感知“这条方向的网络已经不可用”,而不是继续盲目选择一条局部看似可达的路径。

图3 Different / Same两种联动模式下的MPG与SPG关系
切换过程如何直接增加网络可用性
网络可用性不是由“有没有备用链路”决定的,而是由“故障是否能被识别、备用路径是否能被及时放开、恢复后邻居是否能尽快更新转发表”决定的。Follow Link的价值,就体现在它把这三个动作串成了一次有顺序的切换过程。
源文档里的双归案例并不是两个独立场景,而是在同一套拓扑里叠加了两层联动。对 SW B / SW C而言,红色uplink是MPG,蓝色和紫色downlink是SPG,follow mode取same;对SW D / SW E而言,蓝色主路径是MPG,紫色备用路径是SPG,follow mode取different。
以 SW A到SW B的红色uplink断开为例,SW B会先把本机红色MPG判为非normal;按照same模式,它本机的蓝色和紫色downlink SPG会同步进入受控状态,常见工程动作就是shutdown。这样一来,SW D会先感知自己的蓝色MPG不再可用,随后再按different模式放开本机的紫色SPG,业务改经SW C方向转发。
这个例子里并不是所有下层设备都会一起翻转。左侧受影响的 SW D会完成主备切换,而右侧SWE的蓝色MPG仍然可用,所以它会继续走原来的主路径。也正因为切换是按本地FLG状态触发的,网络才能在避免环路的同时,把影响范围限制在真正受故障波及的那一侧。
恢复阶段同样重要。主路径恢复后,如果不及时处理旧的转发表,业务仍可能朝着故障前的方向发送。Follow Link把Flush FLP纳入恢复链路,正是为了让邻居设备尽快知道:网络现实已经改变,转发路径也应随之更新。
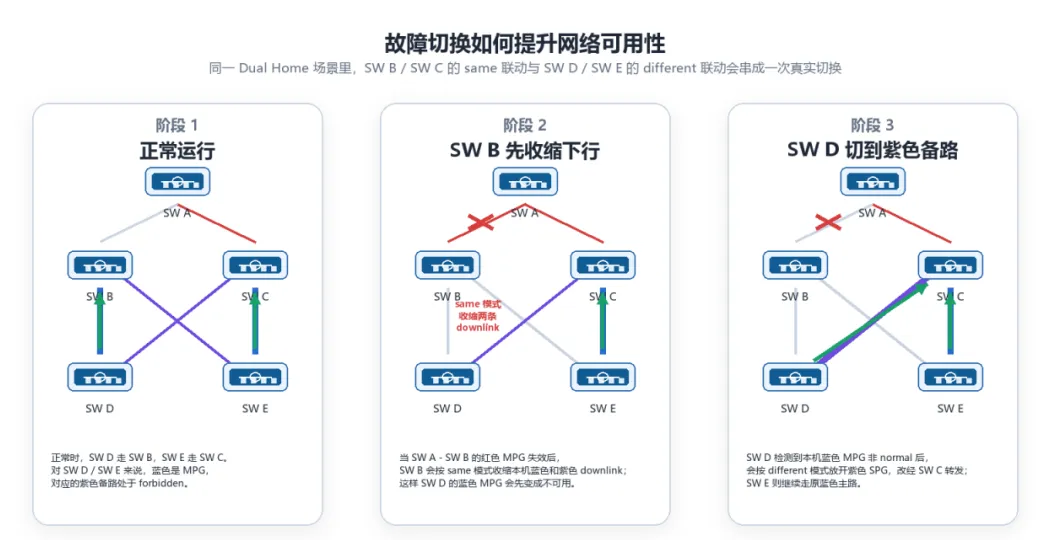
图4同一 Dual Home场景下,same与different两级联动完成一次切换
从状态机视角理解 Follow Link
如果把前面的角色关系和切换过程再往下拆一层,就会进入状态机视角。Follow Link的关键并不是“发现故障后把某个端口关掉”这么简单,而是先定义哪些输入会改变MPG的状态,再定义SPG在不同Follow mode下如何跟随MPG变化。
对 MPG来说,状态机把Link事件、Probe结果、Manual控制等输入统一放进同一套判定框架里,因此设备能够区分Normal、Down、Disconnect、Close等不同语义。对SPG来说,状态机把业务口是否放开、是否禁止、是否继续跟随主路径,变成了稳定可重复的逻辑动作,而不是临场判断。
把这两张状态机放在正文里看,会更容易理解 Follow Link为什么既能解决主备切换,又能约束环路风险。它不是只做一次故障动作,而是让“识别-传递-切换-恢复”形成了闭环。
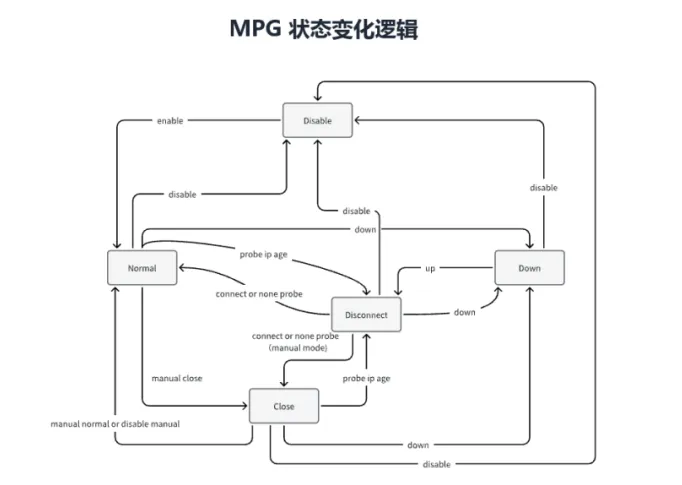

图 5 MPG 状态变化逻辑示意
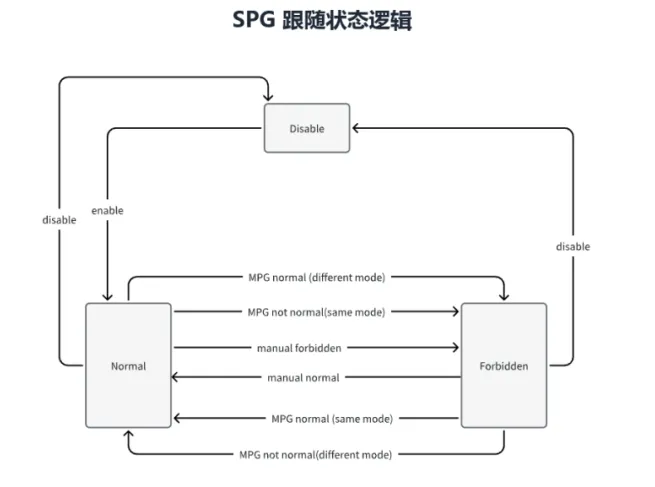

图 6 SPG 跟随状态逻辑示意
FLP 私有协议的两个关键作用
FLP 是 Follow Link 机制中的私有协议报文。它的第一项作用,是在满足条件的直连场景中承担探测任务,让 MPG 不仅依赖物理端口状态,还能得到对端设备的协议级反馈。对于强调同厂设备协同的网络,这种探测方式更直接,也更贴近设备之间的控制语义。
FLP 的第二项作用,是在路径恢复后触发 Flush。网络切换完成并不代表业务立刻恢复,如果邻居设备仍然保留旧的 MAC 学习结果,报文可能继续发往旧路径。Flush FLP 的意义,就是在状态从非 Normal 恢复到 Normal 的关键时刻,推动邻居尽快清除相关 MAC 表项,从而缩短业务恢复时间。
因此,FLP 不是一个单纯的“连通性检测包”,而是把探测和收敛两个环节联在一起的私有控制报文。它体现的是一种工程策略:先让设备知道哪条路径可信,再让邻居尽快跟上新的转发表现实。
典型 Dual Home 场景下的工作原理
在典型 Dual Home 场景中,下层设备往往各自拥有两条向上的可选路径。正常情况下,设备会把其中一条视为主路径,另一条视为备用路径;为了避免形成环路,备用路径在业务上需要被限制。
这时,上层设备先利用自身更靠近核心侧的位置,对上行路径进行判断。如果上行不可达,它们会通过 Same 模式收缩下行路径可用性;下层设备再根据本地 FLG 中的 Different 模式,自动放开原本受控的备用路径。这样,故障既能被上层识别,也能被下层及时转化为实际的业务切换动作。
当上行路径恢复时,MPG 状态重新回到 Normal,SPG 重新进入禁止状态,主路径恢复承载业务;如果同时启用了 Flush 发送与接收,邻居还会尽快清除旧的 MAC 学习结果,使转发表同步回到恢复后的网络现实。
从网络行为上看,Follow Link 不是简单地“关端口”或“开端口”,而是在主备路径之间建立一套能够闭环的状态传递机制:可用性判断、端口受控、下游感知、MAC 收敛,缺一不可。
工程使用边界与部署前提
Follow Link 的能力边界同样重要。首先,FLP Probe 和 Flush FLP 依赖对端设备支持相应的私有协议处理能力,这并不是通用跨厂商特性;如果网络中需要穿越不支持该机制的设备,应优先考虑 Ping Probe 的通用探测能力。
其次,Ping Probe 的前提不是“能 Ping 就行”,而是需要单独规划探测 VLAN 与 IP 地址,并保证中间二层转发链路正确承载这一探测流量。否则,探测失败反映的可能是规划或承载问题,而不一定是目标路径本身失效。
再次,MPG 与 SPG 的端口归属、成员数量、跟随模式以及受控方式,都会直接影响故障时的网络动作。如果把 Follow Link 仅仅当作一套命令去配置,而不先想清楚“谁负责判定、谁负责切换、谁负责向下游传播状态”,就很容易出现逻辑上看似正确、工程上却不闭环的设计。
更实际的建议是:先从拓扑关系出发划定 FLG,再根据链路角色决定 Different 或 Same 的使用位置,最后再选择 FLP Probe 还是 Ping Probe。这样,Follow Link 才是网络方案中的控制机制,而不是孤立的配置项。
结语
对于 Dual Home 以太网来说,真正困难的往往不是“有没有冗余链路”,而是“网络是否知道何时该切、切向哪里、切完后怎样尽快恢复正确转发表”。Follow Link 通过 FLG、MPG、SPG 以及 FLP / Ping / Flush 这些机制,把这三个问题连接成了一套可落地的工程闭环。
从这个意义上说,Follow Link 的核心价值不在命令数量,而在机制组织方式:让路径判断、端口联动和收敛恢复不再彼此割裂。对于追求高可用、低环路风险和快速恢复的双上联以太网场景,这正是它最值得被理解的地方。