


昨天DeepSeek 太快了!文章提到:
国内几家大模型在不同的方向上投入资源,而且开源出来造福全行业。每个模型团队在训练时可以采集各家之长,每一家的技术突破都会迅速变成全行业的“公共养料”。
这篇文章就来看看智谱 AI 6 月开源的LLM 后训练框架:slime 。
它被定位为面向 RL Scaling 的后训练系统,提供两大核心能力:
高性能训练与灵活的数据生成。
它是智谱内部"炼丹炉",GLM-5.2、GLM-5.1、GLM-5、GLM-4.7、GLM-4.6、GLM-4.5 共六个大版本的模型都是基于这个后训练系统训练。
框架名称"slime"灵感来源于《勇者斗恶龙》中的史莱姆,寓意轻量、灵活、易扩展。
slime 包含Megatron 训练、SGLang rollout、自定义数据生成、奖励计算、验证器反馈和环境交互,全部流经同一条 training / rollout / Data Buffer 路径。
核心架构
slime 的架构由三个核心模块组成,中间通过 Data Buffer 模块连接。
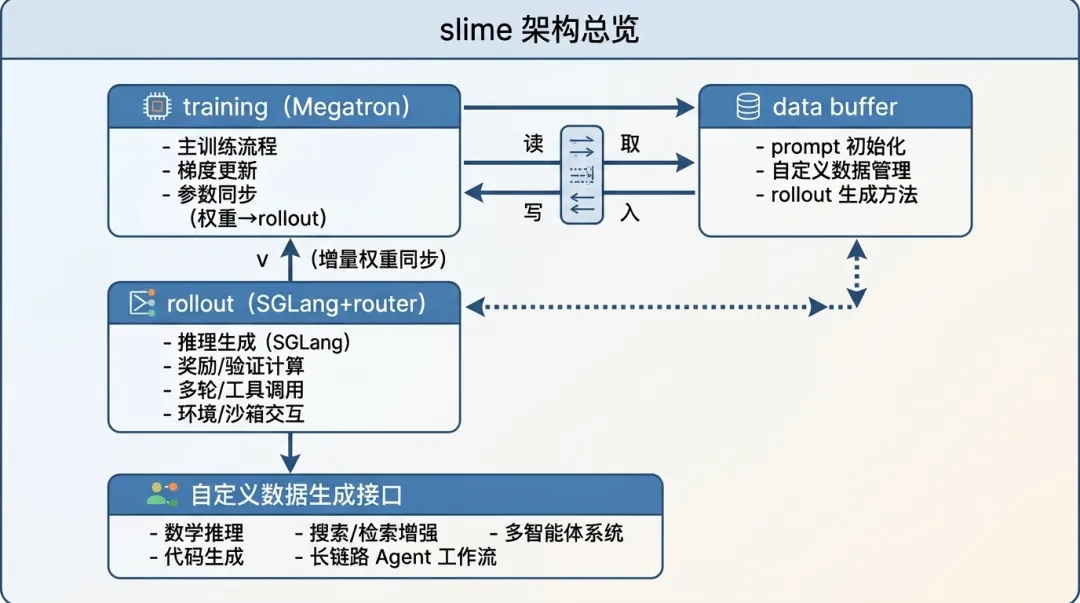
Training 模块(Megatron 训练引擎)
Training 模块是 RL 工作的起点,承担四个关键职责:
• 管理训练数据队列,从 Data Buffer 消费训练数据 • 执行梯度更新,将 RL 信号注入模型权重 • 计算 log-probability,供 RL 算法计算 advantage • 同步更新后的权重到推理/数据生成节点
Megatron 的所有参数在 slime 中直接透传,不做二次封装。这意味着 Megatron 社区的最新优化可以在 slime 中直接使用,无需等待框架适配。
支持的并行策略包括:
• TP(张量并行): --tensor-model-parallel-size• PP(流水线并行): --pipeline-model-parallel-size• CP(上下文并行,Ring Attention): --context-parallel-size• EP(专家并行,MoE): --expert-model-parallel-size• ETP(专家独立张量并行): --expert-tensor-parallel-size
Checkpoint 支持两种格式:旧版 torch 格式(mp_rank_xxx 文件夹结构)和推荐的 torch_dist 格式(.distcp 文件,支持不同并行策略共用同一 checkpoint)。
Rollout 模块(SGLang + Router)
Rollout 模块负责推理生成,包含一个 Router 和一个或多个 SGLang 引擎:
• Router:管理请求的 session affinity 路由,确保同一 session 的请求路由到同一引擎(对多轮 Agent 场景至关重要)。同时接收训练模块推送的权重更新。 • SGLang 引擎:承担实际的推理工作,包括 rollout 生成、tokenize/detokenize 和 reward model scoring(RM 推理可与 rollout 共用模型权重,无需额外部署)。
slime 有意选择 SGLang 作为唯一的 rollout 后端,不做多后端抽象。这使其可以深度利用 SGLang 特有的能力:
• Speculative Decoding:推测解码加速 • PD Disaggregation:Prefill/Decode 分离部署 • RL Cache:强化学习专用 KV cache 复用 • FP8 推理:低精度量化推理,提升吞吐和 KV cache 容量
Rollout 模块的 GPU 数量通过 --rollout-num-gpus 配置,每个引擎的 GPU 数通过 --rollout-num-gpus-per-engine 配置。当设为 0 时,只启动 Router,不启动本地 SGLang server,适用于仅做数据路由或调试的场景。
Data Buffer 模块
Data Buffer 是 Training 和 Rollout 之间的桥梁。它负责初始化 prompt 并管理整个数据流的生命周期。
数据流程如下:
1. 用户数据源( .jsonl格式)被加载2. Data Buffer 为每个 prompt 初始化状态 3. Rollout 模块消费 prompt,生成 response 4. 生成的样本(tokens + reward + loss_mask)写回 Data Buffer 5. Training 模块从 Data Buffer 消费样本进行训练
这种显式的数据流设计使得调试变得简单:可以在 rollout 完成后暂停,检查中间数据;也可以通过指定状态来复现特定训练步。
设计哲学
原生引擎透传
slime 不抽象 Megatron 和 SGLang 的参数。
Megatron 参数直接透传,SGLang 参数通过 --sglang- 前缀暴露。
新的上游训练和 serving 优化可以直接使用,不需要在 slime 中加一层 wrapper。
正确性优先
设计决策明确以正确性验证为第一优先级。
数据流是显式的,状态可检查,支持 --rollout-only(仅执行 rollout)和 --train-only(仅执行训练)两种调试模式。
CPU 正确性测试默认运行,GPU E2E 测试覆盖真实 Megatron + SGLang 的训练/rollout 路径。
单一后端深度优化
专注于 SGLang,不为了兼容多个 inference engine 而牺牲性能。
这使得可以直接发挥 SGLang-specific 的 serving、routing、caching、disaggregation 和 weight-sync 能力。
数据生成最大自由度
Agent 工作流(tool use、sandbox 交互、verifier reward、environment feedback、multi-agent loop 和长周期 agentic workflow)都被视为数据生成的一部分,接入同一条路径,而不是 fork 训练内核。
BF16 训练 + FP8 推理
大规模 MoE 训练使用 Megatron BF16 训练状态搭配 SGLang FP8 rollout/inference。
Long-context rollout 还可以通过 --sglang-kv-cache-dtype fp8_e4m3 提升有效的 KV cache 容量。
支持的 RL 算法
slime 支持多种 advantage estimator,用户通过 --advantage-estimator 参数选择。
grpo(Group Relative Policy Optimization,组内相对策略优化)是 slime 的默认算法,无需 Critic 模型,论文地址 arxiv.org/abs/2402.03300。
gspo(Group Sampling Policy Optimization),同样无需 Critic,论文地址 arxiv.org/abs/2507.18071。
cispo(Clip Importance Sampling Policy Optimization),无需 Critic,论文地址 arxiv.org/abs/2506.13585。
reinforce_plus_plus(REINFORCE++),一种类 REINFORCE 的无 Critic 方法,论文地址 arxiv.org/abs/2501.03262。另有一个带 baseline 的变体 reinforce_plus_plus_baseline,通过引入基线值来降低方差。
ppo(Proximal Policy Optimization)是经典算法,也是六种中唯一需要单独训练 Critic 模型的方案,论文地址 arxiv.org/abs/1707.06347。
GRPO(推荐默认)
GRPO 是 slime 的默认算法。它不需要 Critic 模型,节省约 30-50% 的显存和计算资源。核心思想是对每个 prompt 采样多个 response(通过 --n-samples-per-prompt 配置),在组内计算相对 advantage,避免训练单独的 value 网络。
OPD(在策略蒸馏)
OPD 是与 advantage estimator 正交的一项能力,通过 --use-opd 启用。它在标准 RL 目标函数上叠加一个 KL 惩罚项,让学生模型(即正在训练的 actor)匹配教师模型(通常是一个更强的推理模型)的 token 级 log-probability 分布。
OPD 的核心公式:
A_t' = A_t + λ_opd × D_KL(student || teacher)其中 A_t 是基础 estimator(如 GRPO)的原始 advantage,λ_opd 是 --opd-kl-coef 系数,D_KL 是 token 级的 KL 散度。
OPD 支持两种教师模型部署模式:
• SGLang 模式:教师模型通过 SGLang 引擎服务,在 rollout 时实时计算 log-probability • Megatron 模式:教师模型与 actor 共用 Megatron 引擎,以权重共享的方式计算
OPD 已被验证在 GLM-5.2 的后训练中起到了关键作用:仅用约 2 天时间完成蒸馏,显著提升了模型的指令遵循和推理能力。
(On-Policy Distillation(OPD) 的核心意思是:“基于当前策略的蒸馏” 。
蒸馏(Distillation):用一个大模型(老师)的“软输出”(概率分布)去教一个小模型(学生),让学生模仿老师的思考逻辑,而不仅仅是学标准答案。
On-Policy(同策略):在强化学习里,指“用来学习的数据,必须是由当前正在执行的策略(最新版本的模型)亲自采集的”。与之相对的是 Off-Policy(异策略),后者可以用旧模型或别人的数据来学
OPD 就是:
“用当前最新版本的模型自己生成的数据,来蒸馏(教)自己或学生模型。”
它要求教师信号和学生模型的学习均基于学生当前策略实时采样的轨迹生成,以此在强化学习微调中提供稳定的约束信号,防止模型坍缩。
也就是说使得后续的大模型蒸馏先进的大模型变得有迹可循。)
概念详解
PD 分离(Prefill/Decode Disaggregation)
PD 分离将推理过程拆分为 Prefill(预填充)和 Decode(逐 token 生成)两个阶段,分配给不同的 GPU 节点。
• Prefill 引擎:处理输入序列的并行编码,计算密集,适合高吞吐 GPU • Decode 引擎:逐 token 生成输出,内存带宽密集,适合高内存带宽 GPU
配置方式:通过 --prefill-num-servers 指定 prefill 引擎数量,通过 --sglang-config YAML 中的 worker_type: prefill 和 worker_type: decode 分别指定。
优势在于可以针对 Prefill 和 Decode 的不同计算特征使用异构硬件资源。slime 还支持 Mooncake Transfer Engine,可以实现跨节点的零拷贝 KV cache 传输,进一步降低 PD 分离的通信开销。
增量权重同步(Delta Weight Sync)
传统方法在训练完成后需要传输完整模型权重到推理引擎,对大模型而言传输开销巨大。
Delta Weight Sync 只传输训练前后权重的差异部分(delta),大幅减少传输数据量。
slime 支持两种传输模式:
• Disk 模式:delta 写入共享文件系统,推理引擎读取后应用 • RDMA 模式:通过远程直接内存访问直接传输 delta,延迟更低
配置方式:--update-weight-mode delta 和 --update-weight-transport disk
会话亲和性路由(Session Affinity Routing)
在多轮 Agent 对话场景中,同一个 session 的多个请求必须路由到同一个 SGLang 引擎。
这是因为引擎内部维护了该 session 的 KV cache,路由到其他引擎会导致 cache miss,性能急剧下降。
slime 的 Router 内置了 session affinity 机制:通过 session_id 哈希将同一 session 的请求始终路由到同一引擎。
这比简单的轮询或随机路由更适合 Agent 场景。
对应的路由器均衡阈值可通过 --router-balance-abs-threshold 控制,设为 0 时强制均衡分配(适用于单轮场景)。
SGLang Config YAML
通过 --sglang-config 参数,用户可以用 YAML 文件定义完整的推理部署拓扑:
sglang: - name: actor update_weights: true server_groups: - worker_type: regular num_gpus: 8 num_gpus_per_engine: 4 - name: ref model_path: /path/to/ref_model update_weights: false server_groups: - worker_type: regular num_gpus: 4 num_gpus_per_engine: 2支持四种 worker_type:
• regular:标准推理节点 • prefill:专用预填充节点(PD 分离) • decode:专用解码节点(PD 分离) • placeholder:占位节点(为后续扩展预留)
多模型部署场景(如同时需要 actor 和 reference model)可以通过定义多个 sglang 配置项实现。
Agent Runtime Adapters
为支持 Agentic RL 工作流,slime 提供了 Agent Runtime Adapter 机制。
Adapter 定义了 slime 生成的数据如何分发给不同的 Agent Runtime(如 SWE-bench shell、terminal、API 等)执行,以及它们的 tool call 如何被解释。
官方文档中提及了两种 Adapter 参考:
• AnthropicAdapter:适配 Anthropic 风格的 tool use 格式 • OpenAIAdapter:适配 OpenAI 风格的 function call 格式
这为社区接入其他 Agent Runtime(如 CodeAct、SWE-agent 等)提供了标准化的接口模式。
Agentic Workflow 与数据生成
slime 将 Agentic workflow 视为数据生成的一部分。
无论是 tool use、sandbox 交互、verifier reward、environment feedback,还是 multi-agent loop 和长周期 agentic workflow,都接入同一条 training / rollout / Data Buffer 路径。
这种设计避免了在训练内核之外 fork 一个独立的 Agent 框架。
训练数据可以通过自定义生成函数(--custom-generate-function-path)或完全自定义 rollout 函数(--rollout-function-path)灵活构建,支持从简单的 reward model scoring 到复杂的多轮 agentic interaction 的各种场景。
训练模式
slime 支持五种训练部署模式,适应不同的硬件和场景。
训推分离(默认):训练和推理使用独立 GPU 资源,通过 --actor-num-nodes、--actor-num-gpus-per-node、--rollout-num-gpus 分别配置两类 GPU 数量。
训推一体:训练和推理共用同一批 GPU,通过 --colocate 开启。不训练时 GPU 做推理,不推理时 GPU 做训练,先后 offload,适合 GPU 资源有限的场景。
PD 分离:Prefill 和 Decode 分开部署在不同 GPU 节点上,通过 --prefill-num-servers 指定 prefill 引擎数量。适合需要针对 Prefill 和 Decode 不同计算特征使用异构硬件的场景。
外部引擎:连接外部预先启动的 SGLang engine,通过 --rollout-external-engine-addrs 指定地址。适合已有独立推理集群的场景。
多模型部署:同时服务多个模型(如 actor 和 reference model),通过 --sglang-config YAML 文件定义拓扑。适合需要多模型协同推理的场景。
支持的生态
slime 不仅支持 GLM 系列模型,还通过社区支持扩展到多个主流模型系列。
GLM 系列:GLM-5.2、GLM-5.1、GLM-5、GLM-4.7、GLM-4.6、GLM-4.5,共六个已发布版本。
Qwen 系列:Qwen3.6、Qwen3.5、Qwen3Next、Qwen3MoE、Qwen3、Qwen2.5。
DeepSeek V3 系列:DeepSeek V3、V3.1、DeepSeek R1。
Llama 系列:Llama 3。
支持的模型参数范围从 7B 到 700B+,涵盖稠密模型和 MoE 模型。预置的模型配置可在 scripts/models 中直接复用,包括 Qwen3 4B/8B/32B/235B、DeepSeek V3 系列、GLM 系列等。
生态衍生
slime 开源后,社区围绕它衍生出一系列生态项目,形成完整的 RL post-training 工具链。
Miles:数据飞轮类型,大规模数据引擎,覆盖 pre-training 数据混入、SFT 数据配比、RL data collection。
vime:视觉 RL 类型,Vision Model RL,专注于视觉多模态模型的 RL 训练。
Relax:推理加速类型,Relaxed Verification,解决推理任务的验证瓶颈,如数学证明和代码生成中的奖励信号延迟问题。
P1:Agentic RL 类型,专注 agent code RL 数据的生成和收集。
TritonForge:编译器优化类型,Triton kernel 编译优化,提升训练吞吐。已开源。
APRIL:数据处理类型,自动化数据处理流水线。已开源。
Dressage:训练编排类型,大规模训练编排系统,支持 TITO(Token-Level Importance Sampling)等高级算法。
SGLang:推理引擎,slime 的推理后端,是 slime 深度适配的上游项目。
Megatron-LM:训练引擎,slime 的训练后端,slime 直接透传其参数不做二次封装。
其中 Miles、vime 和 Dressage 已明确为内部项目,TritonForge 和 APRIL 已开源。
工程保障
测试体系
slime 建立了四层测试框架:
• Unit Tests:纯 Python 正确性测试,默认运行,无 GPU 依赖 • Contract Tests:核心函数接口级正确性测试 • Integration Tests:模块间集成测试,覆盖配置解析、数据流转、权重同步等 • GPU E2E Tests:真实 Megatron + SGLang 训练/rollout 路径端到端测试,覆盖 dense/MoE recipe、async rollout、checkpoint、precision 和 debug replay
调试与可观测性
• CPU Debug Mode:可以在无 GPU 环境下运行完整的训练逻辑,验证正确性 • Trace Viewer:可视化训练时间线,定位性能瓶颈 • Profiling:内置 profiling 支持,分析 GPU 利用率和通信开销 • Reproducibility:通过种子固定和状态检查点确保训练可复现 • rollout-only / train-only 模式:分阶段调试,先验证 rollout 数据正确性,再验证训练正确性
CI 持续集成
CI 默认运行 CPU correctness tests。
GPU E2E tests 在合并前按需触发,确保每次代码变更都经过真实训练环境验证。
总结
slime 是一套经过六个 GLM 大版本实战验证的 RL post-training 框架。
它的核心价值在于将 Megatron 训练、SGLang rollout、数据生成和 Agent workflow 统一到一条 training / rollout / Data Buffer 路径中,避免了多系统集成的工程复杂度。
在此之前,RL post-training 领域缺乏一套同时兼顾高性能训练和灵活数据生成的标准化框架。
slime 的 OPD、PD 分离、增量权重同步、会话亲和性路由等设计都是在大规模模型训练中验证过的实践方案,对社区具有直接参考价值。
参考资料
1. slime 官方文档:https://thudm.github.io/slime/zh/ 2. GitHub 仓库:https://github.com/THUDM/slime 3. GLM 技术博客:https://z.ai/blog
推荐阅读:
11 页 Claude Loop Engineering 实战手册
Loop Engineering:从提示者到循环设计者的14步路线图
比 Superpowers 更贴近AI编程工程实践的51 个 Agent 和 35 个技能
Loop Engineering 如何使用AI编程智能体:构建可循环系统
Hermes 桌面应用发布 Slate Pod:一键安装开箱即用、好用,支持多智能体
Claude Fable 5 系统提示词曝光:Anthropic 为适应最强大模型做了哪些改动?
大模型黑箱揭秘:GPT、Claude、Gemini、Grok、Hermes 系统提示词全公开