



序言
正本清源,让人工智能回归以人为本的数字主权时代
二十六年前,互联网迎来了一次认知的飞跃。
2001年,万维网之父蒂姆·伯纳斯-李(Sir Tim Berners-Lee)联名发表了划时代的奠基之作——《语义网》(The Semantic Web)白皮书。在这篇富有远见的巨著中,他不仅勾勒出了由逻辑与数据织就的知识图谱,更极其超前地预言了今天风靡全球的“智能体(Agent)”协作网络。在万维网之父的宏大构想中,未来的互联网将是一台能够理解人类意图、去中心化且自动调度现实资源的全球超级计算机。
然而,在发布后的二十多年里,语义网这一伟大的构想并未获得主流市场的足够重视。究其原因,在于早期的语义网陷入了“中心化”与“高昂工程成本”的现实泥潭: 传统的知识表达极度依赖人工去定义极其复杂的本地本体(Ontology)和元数据标签;而要让全世界不同的行业、组织在没有强力中心化控制的前提下,自下而上地达成完全一致的“语义共识”,在工程实践上无异于一场通天塔式的空想。高昂的数据标注成本与缺乏杀手级应用(Killer Apps)的尴尬境地,让语义网在很长一段时间里成了象牙塔里的学术乌托邦。
直到最近,大语言模型(LLM)与生成式 AI 的爆发,让沉寂多年的语义网迎来了前所未有的技术复兴。 过去,机器“理解”语义需要人类手动喂养规则;而今天,拥有千亿参数的大模型凭借强大的涌现能力,已经能够直接通过自然语言理解人类的意图,并具备了自动化生成、映射和对齐复杂本体(Ontology Mapping)的天赋。AI 的发展补齐了语义网原本最缺失的“自动化流转”拼图,而语义网的结构化逻辑与本体论,又恰恰是大模型克服“幻觉(Hallucination)”、走向符号落地(Symbol Grounding)与可信推理的解药。
当大模型转变为需要执行复杂现实任务的“智能体(Agent)”时,它们猛然发现,万维网之父在2001年为其设计的“RDF三元组技术塔”与“信任网络”,正是去中心化智能体协同社会最完美的底层协议与圣经。
遗憾的是,历史在演进中常伴随着喧嚣与偏离。这个本应关乎数据自主权、关乎人与机器深度协同的由万维网之父于2006年定义的“Web3.0”,在过去几年中被简化为了离财富最近、却离数据主权最远的狭义区块链加密货币概念,甚至在炒币的狂热中被污名化。更有甚者,在完全不了解互联网与 AI 演进历史背景的前提下,抛出诸如 “Web4” 的概念噱头。面对业界的浮躁与错识,万维网之父曾多次提出严厉的批评,呼吁正本清源。
历史的修复与升级,需要真正具有理论高度与技术信仰的践行者。
去年,LingoAI 联合创始人王启亨Henry Wang 与王传秀Una Wang亲赴海外与万维网之父 Sir Tim Berners-Lee 进行了深入的面对面会晤。作为 Web3.0 大一统理论的提出者、倡导者以及 Web3.0 词汇的创造者(2003年),Henry 与万维网之父就 Solid 协议(个人数据舱)、本体论(Ontology)构建、Token Switching(通元交换:通证与词元的价值交换)、以及智能体网络的全球治理展开了历史性的思想碰撞。
双方达成了高度的共识:要让真正的 Web3.0 重生,必须纠正业界的认知偏差,将数据主权(Data Sovereignty)与 AI 主权(AI Sovereignty)彻底归还给个人。这不仅是一场技术的拨乱反正,更是一场捍卫人类主权的伟大使命。
为了让更多人看清 AI 与互联网发展的底层脉络,LingoAI 特此推出《经典重现历史系列·语义网白皮书》专业全译本。我们逐句还原了万维网之父在 2001 年写下的科技真理,以此回应时代的浮躁。
今天,LingoAI 正紧密协同万维网之父的 Solid 协议,通过 LingoAI 的语义流动网络与 MetaLife.social 的“社交神经元”协作网络,在不改变物理基础设施的前提下实现数据的逻辑驻留与主权迁移。我们不仅在开发捍卫数据主权的智能体,更在积极推动让每个人都能在本地无成本运行专属 AI 的硬件基础设施。
修复万维网,升级大模型。我们深知,构建个人本体论不仅仅是“存数据”,而是在数字世界构建一个“有序的自我:数字生命”。通过发布这篇经典文献,LingoAI 愿与全球的技术远见者一道,承接万维网之父的最初宏愿,让智能体(Agent)网络在去中心化的土壤中安全繁衍,让人工智能始终以人为本地发展与治理。
正本清源,数字破晓。真正的 Web3.0 时代,由我们共同见证与开创。
—— LingoAI 创始团队
白皮书
语义网 (The Semantic Web)
作者: 蒂姆·伯纳斯-李 (Tim Berners-Lee)、詹姆斯·亨德勒 (James Hendler)、奥拉·拉西拉 (Ora Lassila)
出处: Scientific American, May 2001

01
引言:愿景的启航 (Introduction)
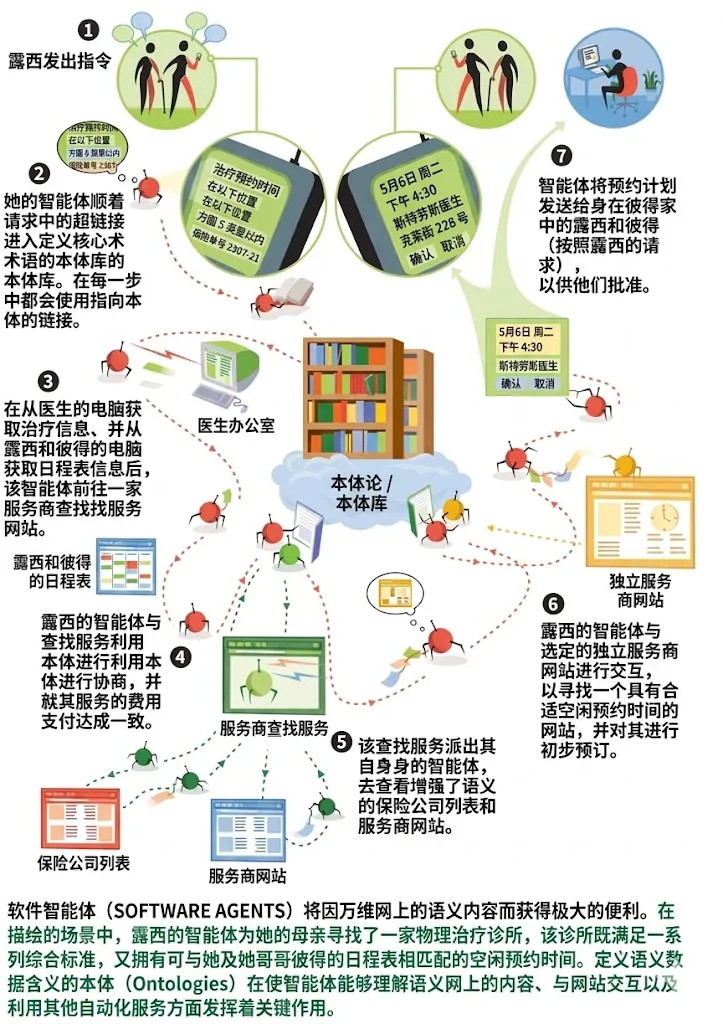
当电话铃声响起时,娱乐系统正在高亢地播放着披头士的《We Can Work It Out》。当彼得接起电话时,他的手机通过向本地所有其他具有音量控制功能的设备发送一条消息,自动调低了音量。他的姐姐露西从医生的诊所打来电话:“妈妈需要去看专科医生,然后需要进行一系列的物理治疗。大概每两周一次。我准备让我的智能体(Agent)来安排这些预约。”彼得立刻同意分担日常的接送任务。
在医生的诊所里,露西通过她的手持 Web 浏览器向她的语义网智能体(Semantic Web Agent)下达了指令。该智能体迅速从医生的智能体那里检索了关于妈妈开具的治疗方案的信息,查找了几个医疗服务提供商的列表,并检查了在妈妈保险计划内、且在她家方圆20英里以内、在受信评级服务中获得“优秀(Excellent)”或“良好(Very Good)”评价的服务商。随后,它开始尝试在个人服务商通过其网站提供的可用预约时间,与彼得和露西繁忙的工作日程之间寻找交集。
几分钟后,智能体为他们呈现了一个方案。彼得不喜欢这个方案——大学医院(University Hospital)横跨了整个城市,离妈妈家很远,而且他必须在傍晚交通高峰期开回程车。于是他将自己的智能体设置为重新搜索,并对位置和时间提出了更严格的偏好。露西的智能体在当前任务的语境下对彼得的智能体完全信任,它通过提供访问证书和它已经筛选过的数据的快捷方式,自动提供了协助。
几乎在瞬间,新方案就呈现了出来:一个距离要近得多的诊所,而且时间更早——但有两个警告提示。其中一个提示指出,该诊所的物理治疗师约翰·哈特曼(Dr. John Hartman)在妈妈的保险计划内,但需要医生开具正式的转诊单。由于转诊单在诊所的智能体和医生的智能体之间已经完成,因此这个问题很容易解决。另一个提示则是关于保险公司的列表中未能将该服务商列入物理治疗师一栏:“服务类型和保险计划状态已通过其他手段安全验证,”智能体向他保证,“(查看详情?)”。
在彼得咕哝着“免了,别给我看详情”的同时,露西表达了她的赞同,于是事情就全办妥了。(当然,彼得最终还是没能忍住不看详情,当天晚上晚些时候,他让自己的智能体解释了它是如何找到那个服务商的,尽管该服务商并不在正规的列表上。)

02
表达含义 (Expressing Meaning)
彼得和露西能够利用他们的智能体来执行所有这些任务,并不是得益于今天的万维网(World Wide Web),而是得益于明天它将演变成的语义网(Semantic Web)。今天的大多数 Web 内容都是为人类阅读而设计的,而不是为了让计算机程序进行有意义的操作。计算机可以熟练地解析 Web 页面以进行布局和常规处理——这里是一个标题,那里是一个指向另一个页面的链接——但总的来说,计算机没有可靠的方法来处理语义(Semantics):例如“这是哈特曼与施特劳斯物理治疗诊所的主页,这个链接指向哈特曼医生的履历”。
语义网将为 Web 页面的有意义内容带来结构,创造一个让在页面之间漫游的软件智能体能够轻松为用户执行复杂任务的环境。这样一个智能体来到诊所的 Web 页面时,不仅会知道该页面包含诸如“治疗、医学、物理、治疗”(treatment, medicine, physical, therapy)等关键词(如今天可能编码的那样),还会知道哈特曼医生在周一、周三和周五在这家诊所工作,并且该脚本接受 yyyy-mm-dd 格式的日期范围并返回预约时间。而它将“知道”这一切,并不需要像《2001太空漫游》中的 Hal 或者是《星球大战》中的 C-3PO 那样规模的人工智能。相反,这些语义在诊所的办公室经理(他从未上过计算机科学导论课)使用现成的语义网页面编写软件以及物理治疗协会网站上列出的资源将页面排版成型时,就已经被编码到了 Web 页面中。
语义网不是一个独立的 Web,而是当前 Web 的延伸,在其中,信息被赋予了明确定义的含义(Well-defined meaning),从而更好地使计算机和人类能够协同合作。将语义网织入现有 Web 结构的最初步骤已经展开。在不久的将来,随着机器变得能够更好地处理和“理解”它们目前仅仅是呈现的数据,这些发展将引入重大的新功能。
万维网的核心属性是其通用性(Universality)。超文本链接的力量在于“任何事物都可以链接到任何事物”。因此,Web 技术绝不能对粗糙的草稿与精雕细琢的成果进行歧视,不能对商业信息与学术信息进行歧视,也不能对文化、语言、媒体等进行歧视。信息沿着许多维度发生变化。其中一个维度是主要为人类消费而产生的信息与主要为机器产生的信息之间的差异。在这个尺度的其中一端,我们拥有从5秒钟的电视广告到诗歌的一切内容;在另一端,我们拥有数据库、程序和传感器输出。迄今为止,Web 发展最迅速的是作为一种服务于人类的文档媒介,而不是作为可以被自动处理的数据和信息媒介。语义网的目标正是为了弥补这一缺陷。
与互联网一样,语义网将尽可能地去中心化(Decentralized)。这种网络化的系统在从大型企业到个人用户的每一个层面上都引发了巨大的兴奋,并带来了难以或根本无法提前预测的利益。去中心化需要做出妥协:Web 不得不抛弃其所有互联关系达到完全一致性的理想,从而迎来了臭名昭著的错误消息:“Error 404: Not Found”,但这也允许了不受限制的指数级增长。
03
知识表达 (Knowledge Representation)
为了让语义网(Semantic Web)发挥功能,计算机必须能够访问结构化的信息集合以及一套推理规则,并利用它们来进行自动化推理。人工智能(AI)学者早在万维网(Web)发展之前很久就已经研究过此类系统。这种通常被称为“知识表达”的技术,目前所处的状态与万维网诞生前的超文本(Hypertext)相似:它显然是一个好主意,并且存在一些非常不错的演示,但它还没有改变世界。它包含了重要应用的种子,但要实现其全部潜力,它必须被连接到一个单一的全球系统中。
传统的知识表达系统通常是中心化的,要求每个人对“父母”(parent)或“交通工具”(vehicle)等常见概念都分享完全相同的定义。但是,中央控制是令人窒息的,随着这种系统规模和范围的扩大,很快就会变得无法管理。此外,这些系统通常会小心翼翼地限制可以提出的问题,以便计算机能够可靠地回答——或者根本能够回答。这个问题让人联想到数学中的哥德尔定理(Gödel’s theorem):任何复杂到足以具有实用价值的系统,也都包含着无法回答的问题,这非常类似于基础悖论“这句话是错的”的高级复杂版本。为了避免此类问题,传统的知识表达系统通常各自拥有一套狭隘且特异的规则,用于对其数据进行推理。例如,一个运作在家族树数据库上的家谱系统,可能包含“叔叔的妻子是婶婶”这条规则。即使数据可以从一个系统传输到另一个系统,这些规则由于以完全不同的形式存在,通常也是无法传输的。
相反,语义网研究人员接受了这样一个事实:为了获得通用性,必须付出悖论和无法回答的问题的代价。我们使规则语言具有足够的表现力,以便让 Web 能够根据实际需要进行广泛的推理。这种哲学与传统 Web 的哲学相似:在 Web 发展的早期,批评者指出它永远不可能成为一个组织良好的图书馆;如果没有中央数据库和树状结构,人们永远无法确定能找到所有东西。他们是对的。但是该系统的表现力让海量的信息变得触手可及,而搜索引擎(这在十年前看来还相当不切实际)现在对这里的许多材料产生了极其完整的索引。
因此,语义网的挑战在于提供一种语言,它既能表达数据,又能表达对数据进行推理的规则,并且允许将任何现有知识表达系统中的规则导出到 Web 上。
将逻辑(Logic)添加到 Web 中——即利用规则进行推理、选择行为路线和回答手段的手段——是目前语义网社区面前的任务。数学决策和工程决策的交织使这项任务变得复杂。逻辑必须足够强大,以描述对象的复杂属性,但又不能强大到让智能体因为被要求考虑一个悖论而被欺骗。幸运的是,我们想要表达的绝大多数信息都是类似于“六角头螺栓是一种机器螺栓”这样的内容,这很容易用现有的语言加上一点额外的词汇来编写。
用于开发语义网的两项重要技术已经就位:可扩展标记语言(XML)和资源描述框架(RDF)。XML 允许每个人创建他们自己的标签——这些隐藏的标签(例如 <zip-code> 或 <item-description>)用来在页面中注释网页或文本片段。脚本或程序可以以复杂的方式利用这些标签,但脚本编写者必须知道页面编写者使用每个标签的目的。简而言之,XML 允许用户向其文档中添加任意结构,但对于这些结构的含义却只字未提[参见乔恩·博萨克和蒂姆·布雷所著《XML与第二代Web》;《科学美国人》,1999年5月刊]。
含义是由 RDF 来表达的,它将含义编码在三元组(Triples)集合中,每个三元组相当类似于一个基本句子的主语、动词和宾语。这些三元组可以使用 XML 标签来编写。在 RDF 中,一个文档做出的陈述是:特定事物(人、网页或其他任何事物)具有带有特定值(另一个人、另一个网页)的属性(例如“是……的姐姐”、“是……的作者”)。这种结构结果证明是描述机器所处理的绝大多数数据的一种自然方式。主语和宾语各自通过一个统一资源标识符(URI)来识别,就像网页上的链接中所使用的一样。(URL,即统一资源定位符,是 URI 最常见的类型。)动词也通过 URI 来识别,这使得任何人只需在 Web 上的某个地方为其定义一个 URI,就能定义一个新概念、一个新动词。
人类语言在使用同一个术语来表示有些不同的事物时会蓬勃发展,但自动化却不然。想象一下,我雇佣了一家小丑信使服务公司,在客户生日那天将气球送给他们。不幸的是,该服务将地址从我的数据库传输到了它的数据库中,却不知道我的数据库中的“地址”是寄送账单的地方,而且其中许多是邮政信箱。我雇佣的小丑最终娱乐了许多邮政工人——这不一定是一件坏事,但肯定不是预期的效果。为每个特定概念使用不同的 URI 可以解决这个问题。作为邮寄地址的地址可以与作为街道地址的地址区分开来,并且两者都可以与作为演说的地址区分开来。
RDF 的三元组形成了关于相关事物的网络信息。因为 RDF 使用 URI 将文档中的这些信息进行编码,所以 URI 确保了概念不仅是文档中的词汇,而且与每个人都可以在 Web 上找到的唯一定义绑定在一起。例如,想象一下我们可以访问包含有关人员信息(包括其地址)的各种数据库。如果我们想找到居住在特定邮政编码区的人,我们需要知道每个数据库中的哪些字段代表姓名,哪些代表邮政编码。RDF 可以指定“(数据库 A 中的字段 5)(是以下类型的字段)(邮政编码)”,并在每个术语中使用 URI 而不是短语。
04
本体论 (Ontologies)
当然,这并不是故事的终点,因为两个数据库对于实际上相同的概念(例如邮政编码,zip code),可能会使用不同的标识符。一个想要跨这两个数据库比较或组合信息的程序,必须知道这两个术语正在被用来表达同一个意思。理想情况下,该程序必须有一种方法来为其所遇到的任何数据库发现这种共同的含义。
第三个作为语义网(Semantic Web)基本组件的信息集合——即被称为“本体”(Ontologies)的技术,为这一问题提供了解决方案。在哲学中,本体论是关于存在本质、以及存在哪些事物类型的理论;本体论作为一个学科正是研究此类理论的。人工智能和万维网(Web)学者将这个词收编为他们自己的专业术语,对他们而言,一个本体就是一个正式定义术语之间关系的文档或文件。服务于万维网的最典型的一种本体包含一个分类法(Taxonomy)和一套推理规则。
分类法定义了对象的类(Classes)以及它们之间的关系。例如,一个地址(address)可以被定义为一种位置(location)类型,而城市代码(city codes)可以被定义为仅适用于位置,依此类推。类、子类(Subclasses)以及实体之间的关系是用于万维网的非常强大的工具。我们可以通过向类分配属性并允许子类继承这些属性,来表达实体之间的大量关系。如果城市代码必须属于城市(city)类型,且城市通常拥有网站,那么即使没有任何数据库将城市代码直接链接到网站,我们也可以讨论与城市代码相关联的网站。
本体中的推理规则提供了进一步的能力。一个本体可以表达这样一条规则:“如果一个城市代码与一个州代码相关联,且一个地址使用了该城市代码,那么该地址就具有该相关联的州代码。”随后,一个程序就可以很容易地推断出(例如),康奈尔大学(Cornell University)的地址因为在伊萨卡(Ithaca),所以一定在纽约州(New York State),而纽约州在美国(U.S.),因此该地址应该按照美国的标准进行格式化。计算机并没有真正“理解”任何这些信息,但它现在可以更有效地操纵这些术语,使其方式对人类用户而言既有用又有意义。
随着万维网上面向本体的页面出现,解决术语(及其他)问题的方案开始浮现。网页上使用的术语或 XML 代码的含义,可以通过从该页面指向一个本体的指针来定义。当然,如果我指向一个将地址定义为包含“zip code”(邮政编码)的本体,而你指向一个使用“postal code”(邮区编号)的本体,之前出现的同样问题现在又会产生。如果本体(或其他 Web 服务)提供等价关系(Equivalence relations),这种混乱就可以得到解决:我们其中一个或两个本体可能包含“我的 zip code 等价于你的 postal code”这一信息。
当我们把小丑送去娱乐我的客户的方案中,当这两个数据库指向不同的地址定义时,问题就得到了部分解决。该程序对不同的地址概念使用截然不同的 URI,就不会混淆它们,事实上,程序将需要去发现这些概念之间究竟是否存在关联。然后,该程序可以使用一项服务,该服务通过识别并移除邮政信箱(post office boxes)以及其他不合适的地址,将一份邮寄地址列表(在第一个本体中定义)转换为一份物理地址列表(第二个本体)。本体所提供的结构和语义,使得创业者更容易提供此类服务,并使其应用变得完全透明。
本体可以从许多方面增强万维网的功能。它们可以被以一种简单的方式使用,以提高网络搜索的准确性——搜索程序可以仅寻找那些提及精确概念的页面,而不是所有使用模糊关键词的页面。更高级的应用将使用本体来将页面上的信息与相关的知识结构及推理规则联系起来。一个为这种用途而进行标记(Marked up)的页面示例在线发布在 http://www.cs.umd.edu/~hendler。如果你将 Web 浏览器导向该页面,你将看到标题为“詹姆斯·A·亨德勒博士(Dr. James A. Hendler)”的普通网页。作为人类,你可以很容易地找到指向简短传记说明的链接,并在那里读到亨德勒在布朗大学(Brown University)获得了他的博士学位(Ph.D.)。然而,一个试图寻找此类信息的计算机程序则必须非常复杂,才能猜测出这些信息可能存在于传记中,并理解其中所使用的英语语言。
对于计算机而言,该页面被链接到了一个定义了关于计算机科学系信息的本体页面。例如,教授在大学工作,他们通常拥有博士学位。页面上的进一步标记(普通的 Web 浏览器不会显示这些标记)使用了该本体的概念,来具体指明亨德勒是从 URI http://www.brown.edu/(布朗大学的网页)所描述的实体那里获得了他的博士学位。计算机还可以发现亨德勒是一个特定研究项目的成员、拥有一个特定的电子邮件地址,依此类推。所有这些信息都很容易被计算机处理,并可用于回答查询(例如亨德勒博士在哪里获得的学位),而在目前,这需要人类去筛选由搜索引擎翻出来的各种页面的内容。
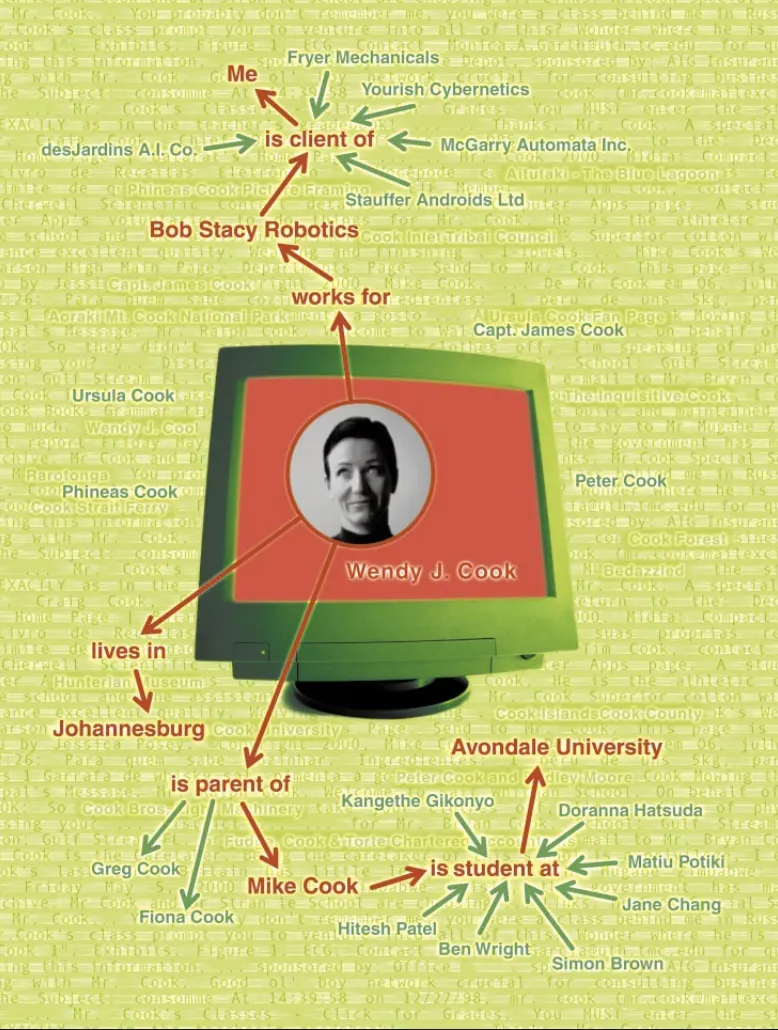
此外,这种标记使得开发能够应对复杂问题的程序变得容易得多,而这些问题的答案并不存在于单个网页上。假设你想找到去年在一次贸易会议上遇到的库克女士(Ms. Cook)。你不记得她的名字了,但你记得她为你的一个客户工作,而且她的儿子是你母校的学生。一个智能搜索程序可以筛选出所有名字为“Cook”的人的页面(避开所有与厨师、烹饪、库克群岛等相关的页面),找到提及为你在客户列表上的某家公司工作的页面,并顺着链接进入她们孩子的网页,以追踪是否有任何人在正确的地方上学。
05
智能体 (Agents)
当人们创建出许多能从不同来源收集万维网(Web)内容、处理信息并与其他程序交换结果的程序时,语义网(Semantic Web)的真正威力就会实现。随着更多机器可读的 Web 内容和自动化服务(包括其他智能体)变得可用,此类软件智能体的有效性将呈指数级增长。语义网促进了这种协同效应:即使是那些并非专门设计用于协同工作的智能体,只要数据带有语义,它们也可以在彼此之间传输数据。
智能体功能的一个重要方面是交换写在语义网统一语言中的“证明”(proofs)(这种语言用于表达利用规则和诸如本体所指定的信息进行逻辑推理的结果)。例如,假设库克女士(Ms. Cook)的联系信息已被一项在线服务定位,并且令你大为吃惊的是,该服务将她定位在约翰内斯堡(Johannesburg)。很自然地,你想对此进行核实,于是你的计算机向该服务索要其答案的证明,该服务随即将自己的内部推理翻译成语义网的统一语言并立即予以提供。你的计算机中的推理机很容易就能验证这位库克女士是否确实与你寻找的那位匹配,如果你仍有疑问,它还可以向你展示相关的网页。尽管它们目前还远未发掘出语义网潜力的深度,但一些程序已经能够利用统一语言的当前初步版本,以这种方式交换证明。
另一个至关重要的特性将是数字签名(digital signatures),它们是加密的数据块,计算机和智能体可以使用它们来验证所附加的信息是否由特定的信任源提供。你想十分确定,发送到你记账程序中关于你欠某家在线零售商钱的声明,不是隔壁那个精通电脑的青少年伪造的。智能体应该对它们在语义网上读到的断言保持怀疑,直到它们检查了信息的来源。(我们希望更多的人学会在目前的 Web 上也这样做!)
许多基于 Web 的自动化服务在没有语义的情况下已经存在,但智能体等其他程序却没有办法定位到能执行特定功能的自动化服务。这个被称为“服务发现”(service discovery)的过程,只有在存在一种通用语言来描述服务,从而让其他智能体既能“理解”所提供的功能,又能理解如何利用该功能时才能发生。服务和智能体可以通过在类似于黄页(Yellow Pages)的目录中存入此类描述来广告它们的功能。
目前已经有一些低级别的服务发现方案可用,例如微软的通用即插即用(Universal Plug and Play,聚焦于连接不同类型的设备)以及太阳微系统(Sun Microsystems)的 Jini(旨在连接服务)。然而,这些倡议是在结构或语法层面上攻击这一问题的,并且高度依赖于预先确定的功能描述集的标准化。标准化所能达到的效果非常有限,因为我们无法预料到未来所有可能的需求。
相反,语义网更加灵活。消费者智能体和生产者智能体可以通过交换本体来达成共同的理解,本体提供了讨论所需的词汇。当智能体发现新的本体时,它们甚至可以“自举”(bootstrap)出新的推理能力。语义也使得利用仅与请求部分匹配的服务变得更加容易。
一个典型的过程将涉及“价值链”(value chain)的创建,其中信息的子组件从一个智能体传递到另一个智能体,每一个都在“添加价值”,以构建最终用户所请求的最终产品。毋庸置疑:为了根据需求自动创建复杂的价值链,一些智能体除了利用语义网之外,还将开发人工智能技术。但是,语义网将提供基础和框架,使这些技术变得更加可行。
将所有这些特性结合在一起,就产生了本文开篇场景中彼得和露西的智能体所展现出的能力。它们的智能体会将任务以零碎的方式委托给通过服务广告发现的其他服务和智能体。例如,它们可以使用一个受信的服务来获取一份服务商列表,并确定其中哪些服务商对于特定的保险计划和疗程是属于计划内的。该服务商列表将由另一个搜索服务提供,依此类推。这些活动形成了链条,在这些链条中,分布式分布在 Web 各处的大量数据(且在那种形式下几乎毫无价值)被逐步缩减为对彼得和露西具有高价值的小量数据——一个符合他们时间表和其他要求的预约计划。
在下一步中,语义网将突破虚拟领域的限制,并延伸到我们的物理世界中。URI 可以指向任何事物,包括物理实体,这意味着我们可以使用 RDF 语言来描述诸如手机和电视之类的设备。此类设备可以广告它们的功能——它们能做什么以及它们如何被控制——这非常类似于软件智能体。由于比通用即插即用等低级别方案更加灵活,这种语义方法开启了一个充满令人兴奋的可能性的世界。
例如,今天所谓的家庭自动化需要对家电进行仔细的配置才能协同工作。对设备能力和功能的语义描述将使我们能够以最少的人类干预来实现这种自动化。一个微不足道的例子发生在彼得接听电话且立体声器的音量被调低时。他不需要去为每个特定的家电进行编程,而是可以一劳永逸地编写这样一种功能,以覆盖每一个广告了自己具有音量控制功能的本地设备——电视机、DVD 播放机,甚至是他今天傍晚刚从工作单位带回家的笔记本电脑上的媒体播放器。
该领域已经迈出了第一步,目前正在开展制定描述设备功能特性(例如屏幕大小)和用户偏好的标准的工作。该标准构建在 RDF 之上,被称为复合能力/偏好总揽(Composite Capability/Preference Profile,CC/PP)。最初,它将让手机和其他非标准的 Web 客户端描述它们自己的特征,以便能为它们即时定制 Web 内容。稍后,当我们添加了用于处理本体和逻辑的语言的全部通用性时,设备就可以自动寻找并利用服务和其他设备来获取额外的信息或功能。不难想象,你那台支持 Web 的微波炉会去咨询冷冻食品制造公司的网站,以获取最佳的烹饪参数。
06
知识的演进 (Evolution of Knowledge)
语义网(Semantic Web)并不仅仅是我们在目前为止所讨论的用于执行单项任务的工具。此外,如果设计得当,语义网还能够协助人类知识整体的演进。
人类的努力受困于一种永恒的张力之中:一端是独立行动的小团队的高效性,另一端则是与更广泛的社区相融合的必要性。一个小团队可以快速且高效地进行创新,但这会产生一个其概念无法被他人理解的亚文化。然而,在大型团队之间协调行动则慢得令人痛苦,并且需要耗费海量的沟通。世界在这两个极端之间的光谱上运作,并带有一种随着时间的推移,倾向于从小处(从个人想法)开始并走向更广泛理解的趋势。
当需要更广泛的通用语言时,亚文化的融合是一个必不可不可少的过程。两个群体常常独立开发出非常相似的概念,而描述它们之间的关系会带来巨大的利益。就像一本芬汉词典,或是一张度量衡换算表一样,这些关系允许了沟通与协同,即使概念的共同性(还)没有导致术语的共同性。
语义网通过简单地用一个 URI 来命名每一个概念,让任何人都能以最少的努力来表达他们所发明的新概念。其统一的逻辑语言将使这些概念能够逐步链接到一个通用的万维网(Web)中。这种结构将向软件智能体开放人类的知识与运作方式,以进行有意义的分析,从而提供一种全新的工具,使我们能够共同生活、工作和学习。
07
延伸阅读 (MORE TO EXPLORE)
《织网:万维网之父谈万维网的原初设计与终极命运》(Weaving the Web: The Original Design and Ultimate Destiny of the World Wide Web by Its Inventor)。蒂姆·伯纳斯-李 (Tim Berners-Lee) 与马克·菲谢蒂 (Mark Fischetti) 合著。哈珀旧金山出版社 (Harper San Francisco),1999年。
本文的增强版本发布在《科学美国人》(Scientific American) 网站上,附带额外材料与链接。
万维网联盟 (W3C):www.w3.org/
W3C 语义网活动 (W3C Semantic Web Activity):www.w3.org/2001/sw/
本体论导论 (An introduction to ontologies):www.SemanticWeb.org/knowmarkup.html
简单 HTML 本体扩展常见问题解答 (SHOE FAQ):www.cs.umd.edu/projects/plus/SHOE/faq.html
DARPA 智能体标记语言 (DAML) 主页:www.daml.org/
08
什么是杀手级应用? (What is a Killer App?)
在我们就语义网(Semantic Web)发表完演讲之后,我们经常会被问到:“好吧,那么语义网的杀手级应用是什么?”当然,任何技术的“杀手级应用”都是指那项吸引用户去研究该技术并开始使用它的应用。晶体管收音机是晶体管的杀手级应用,而手机是无线技术的杀手级应用。
那么我们该如何回答?“语义网本身就是杀手级应用。”
到这一步,我们很可能会被别人认为我们疯了,于是我们反过来提一个问题:“那么,万维网(World Wide Web)的杀手级应用是什么?”现在,人们开始用一种怀疑的眼光盯着我们了,于是我们自己回答道:“万维网是互联网的杀手级应用。而语义网则是另一个具有同等量级的杀手级应用。”
这里的要点在于,语义网的能力过于通用,以至于无法从解决某一个核心问题或创造某一个关键小装置的角度去思考它。它将拥有我们尚未梦见过的用途。
尽管如此,我们仍然可以预见一些引人入胜的(即便不一定是真正的“杀手级”)应用,它们将推动最初的使用。带有语义标记的在线目录将使买家和卖家双方共同受益。小企业将能够更轻松、更安全地以更大的自主权来建立电子商务交易。最后还有一个例子:你为一次长期的出国旅行进行了预订。航空公司、酒店、足球场等返回了带有语义标记的确认信息。所有的行程都会直接加载到你的日程本中,所有的费用也都会直接加载到你的记账程序中,无论你使用的是什么启用了语义的软件。不再需要从电子邮件中进行费时费力的复制和粘贴。所有的企业也不再需要以半打不同的格式来提供数据,或者去创建并强加他们自己的标准格式。
后记
结语:迎接主权智能的“整体子(Holon)”时代
历经二十余载的沉淀与蛰伏,语义网(The Semantic Web)终于在生成式人工智能的惊涛骇浪中,迎来了它最为壮丽的复兴。正如那句古老的格言所说:是金子,总会发光。 2001年万维网之父播下的这颗富有远见的思想种子,在穿越了中心化平台野蛮垄断的迷雾后,终于在今天成为了AI时代照亮人类前路的耀眼灯塔。
这不仅是一场技术的拨乱反正,更是智能体(Agent)前生后世的命运交响。从最初概念中极度依赖人工标注的学术乌托邦,到如今在通用人工智能(AGI)大模型涌现能力催化下的全面觉醒,智能体终于找到了其最完美的逻辑骨架与社会演进路径。语义网的结构化逻辑赋予了机器理解世界的理性,而智能体则赋予了语义网改造现实的行动力。两者的顶峰相见,让数字世界从“文档的互联”彻底跃迁为“智能的主权协同”。
站在技术演进的历史十字路口,基于 LingoAI 提出的 Web3.0 大一统理论,下一代万维网的终极图景呈现出了清晰且颠覆性的科学公式:
Web3.0= Data3.0(数据主权与语义流动)+ Fin3.0(去中心化金融)
过去,业界的认知偏差将 Web3.0 窄化、甚至污名化为纯粹炒作的狭义概念。而真正的 Web3.0,必须是 Data3.0 与 Fin3.0 的双轮驱动。唯有将数据主权、个人本体论的构建(Data3.0)作为生产要素的坚实底层,再辅以价值交换网络(Fin3.0),互联网才能真正完成向去中心化文明的蜕变。
为了践行这一宏伟蓝图,LingoAI 紧密协同万维网之父的 Solid 协议,通过实现数据与应用的彻底解耦,打造出以人为本、数字主权 AI 治理的技术底座。我们深知,未来的 AI 治理不应依赖中心化巨头的施舍与垄断,而必须构筑在去中心化的技术确权协议之上。让技术回归人本,让人类始终驾驭 AI,这是 LingoAI 永不妥协的技术信仰。
如今,这场正本清源的范式革命已至破晓。LingoAI 构建的个人本体论(Personal Ontology)与“Holon(整体子)”架构即将全面降临!
作为既是独立完整个体、又是更大系统不可分割之组成部分的“整体子”,LingoAI 的 Holon 架构即将打破中心化巨头的数据高墙。它将赋予每个人的数字自我一个“有序的自我结构”与绝对的自主权,让个人的数据、灵魂与专属 AI Agent 在本地无成本运行,并在全球的去中心化网络中实现安全的语义流动与神经元协同。
历史的指针已经拨回正轨。承接万维网之父的最初宏愿,开启主权智能的数字破晓。
真正的 Web3.0 时代,由我们共同见证,由每一位主权个体共同开创!

关于LingoAI
AI Web3.0 DePIN Data
LingoAI 是一款个人AI数据智能体,致力于帮助个人重新掌控、理解并变现自身数据。我们的使命是将数据所有权归还给用户,并释放其全部经济价值。
LingoAI 基于社交链接数据(Social Linked Data)与语义网络(Semantic Web)构建,将用户数据与应用进行解耦,打造一个可互操作、隐私优先的智能数据层。我们提供一个去中心化的数据基础设施,通过全球数据市场与多语言 AI 平台,实现真实世界数据的采集、标注与流通。通过释放高质量数据、打破数据孤岛并促进数据的自由流动,LingoAI 正在弥合数字鸿沟。LingoAI 将个人数据转化为资产,使用户能够在数据产生真实应用价值的同时,从中获得可持续的数据经济收益。
LingoAI作为新加坡互联网治理论坛(Singapore Internet Governance Forum, SG IGF)的创始委员会成员,致力于推动多语言公平与语言数据主权;构建AI价值互联网治理范式;代表“全球多数”(Global Majority)发声;倡导以人为本、社区驱动的 AI 治理。LingoAI 深信未来的AI不应由少数科技巨头主导,而应建立在“社区共建、数据共创、价值共享”的原则上。通过SG IGF平台,LingoAI推动“数据即劳动力”的概念落地,构建一种能惠及全球南方与原生语言社区的AI模式。
LingoAI定义了首个Web3.0人工智能体(Web3.0 AI Agent),推出了LingoPod实时翻译神器,全球首款支持语音数据贡献的人工智能耳机,结合LingoCrowd分布式的数据贡献、标注、翻译打造去中心化多模态多语种数据网络,实现全球80亿人实时跨语言沟通,同时保护全球濒危语言。通过AI x DePIN重建AI时代的“巴别塔”。
此外,LingoAI开创性的从根部融合了Web3.0与AI的MetaGraph技术协议栈。MetaGraph使AI大语言模型LLM与知识图谱RAG结合体使得大语言模型可以杜绝幻觉的产生。LingoAI利用更底层的语义网层面通过SOLID和MetaLife.Social协议实现数据与应用分离,回归用户数据自主权旨在突破数据墙形成全球去中心化数据交易市场解决AI因Web2.0数据孤岛导致的数据短缺问题。实现Web3.0 A Web of Data。
_______________________________
“The limits of my language mean the limits of my world.”– Ludwig Wittgenstein, Tractatus logigo-philosphicus, 1922,("我的语言的边界即是我的世界的边界。" - 路德维希·维特根斯坦,《逻辑哲学论》,1922年。)
LingoAI致力于用“Web3.0+AI”技术突破人类语言的边界,致力于"Bridging languages, Embracing AI"。
开启去中心化AI时代
Everyone's data matters
释放
多语种,专业领域的高质量数据
注册LingoCrowd开启数据贡献
获取LingoPod开启语音数据贡献
LanguageDAO开启释放私域数据新纪元

欢迎扫码加入咨询并加入LingoAI社区