


大模型驱动算力变革,国产算力迎增量机遇
摘要
01 大模型加速迭代,算力需求从训练向推理扩散
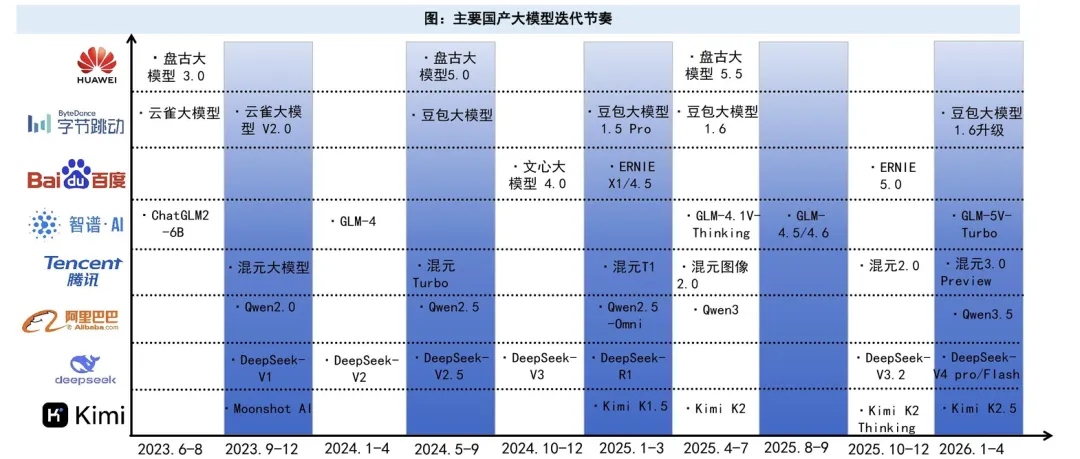
大模型发展趋势:更智能、更快捷、更便宜

与此同时,国产大模型在经历技术蓄力后,自2025年起迭代显著提速。以DeepSeek-R1、智谱GLM等为代表的产品在丰富度和性能上快速追赶,中美已成为全球大模型供给的两大核心。
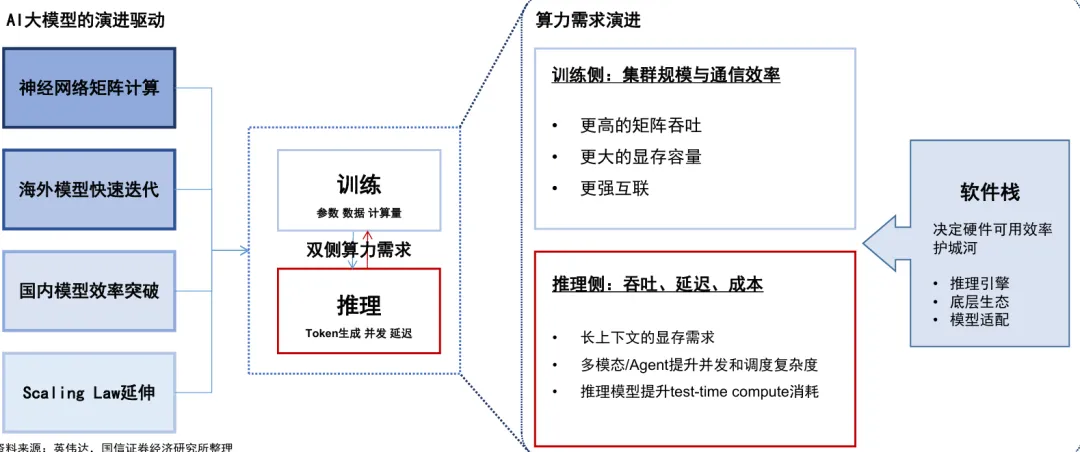
算力需求重心转移:从训练侧外溢至推理侧
AI大模型驱动的产业链升级需求
训练侧:需要更大规模、更高吞吐、更强互联,目标是将模型训练出来。
推理侧:需要更低延迟、更高并发、更低成本,目标是将模型持续服务出去。
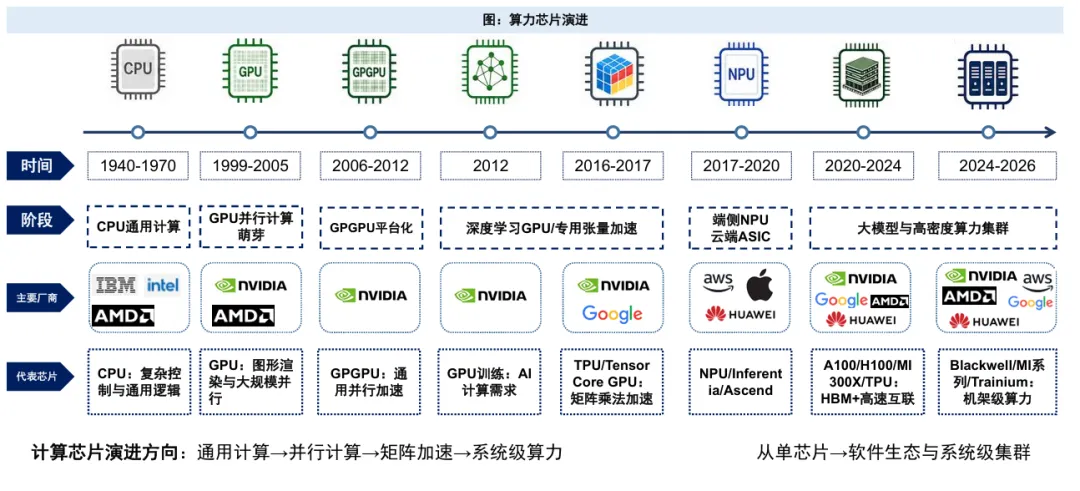
算力的“五层蛋糕”与硬件演进
算力发展趋势:互联与系统级
机柜级(Scale-up):向超节点模式发展,如GB200单机柜算力升级,带动液冷、铜缆等技术升级。
集群级(Scale-out):随着参数扩张,算力集群规模越来越大,对交换机间传输速度要求极高,CPO(共封装光学)和PCB材料升级成为重要方向。
02 AI计算异构化与系统级协同,芯片竞争从峰值性能转向综合效率
算力需求推动系统级协同
算力芯片演进:从通用到系统级
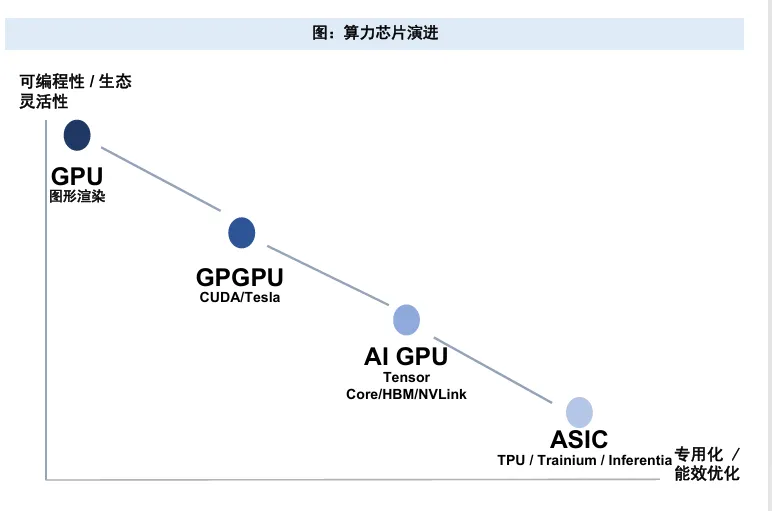
AI系统的本质:异构计算体系
CPU:擅长通用计算、逻辑控制和系统调度,是计算体系的基础。
GPU:依靠大规模并行计算能力,适合神经网络训练和推理中的矩阵、向量运算,成为AI时代的重要加速器。
ASIC(如TPU/NPU):针对特定AI算子做专门优化,在能效比、成本和特定场景性能上具备优势。
未来格局将是CPU、GPU、TPU、NPU及各类AI ASIC长期共存,构成百花齐放的异构算力生态。
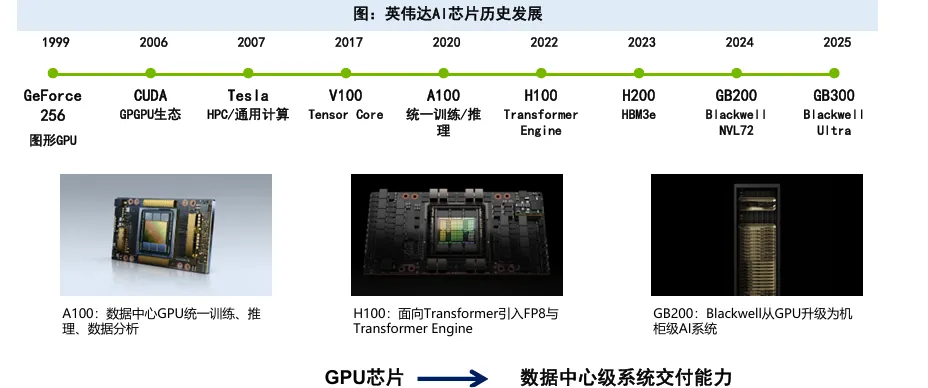
03 海外芯片龙头从单芯片竞争走向平台化交付
当前,海外AI芯片竞争已从单颗芯片性能比拼,演进为芯片、互联、软件、云服务、整机系统的综合交付能力竞争。
英伟达:从GPU供给走向AI数据中心整体效率
谷歌:从内部推理ASIC演进为云端TPU平台
AWS:训练与推理两条ASIC产品线降本
Inferentia:主攻低成本、低延迟AI推理。
Trainium:目标是在云端提供比GPU更具成本优势的AI训练方案。
2025年推出的Trainium3和Trn3 UltraServers,强调3nm工艺、更大HBM及面向智能体、推理模型的训练与推理成本优势。
04 国产大模型与信创需求共振,推动国产算力加速适配放量
国产大模型加速追赶
信创行业注重AI算力基础设施安全可控
通过安全可靠等级Ⅰ级认证的9款国产芯片:
表格
| 序号 | 产品名称 | 送测单位 | 安全可靠等级 |
|---|---|---|---|
| 1 | 昇腾310 | 深圳市海思半导体有限公司 | I级 |
| 2 | 昇腾910 | 深圳市海思半导体有限公司 | I级 |
| 3 | 真武M530 | 平头哥 (上海)半导体技术有限公司 | I级 |
| 4 | 真武M890 | 平头哥 (上海)半导体技术有限公司 | I级 |
| 5 | 壁砺TM 166 | 上海壁仞科技股份有限公司 | I级 |
| 6 | DCU-3G | 海光信息技术股份有限公司 | I级 |
| 7 | KCC-V100X芯片 | 上海天数智芯半导体股份有限公司 | I级 |
| 8 | MXC600 | 沐曦集成电路(上海)股份有限公司 | I级 |
| 9 | PH100 | 摩尔线程智能科技(北京)股份有限公司 | I级 |
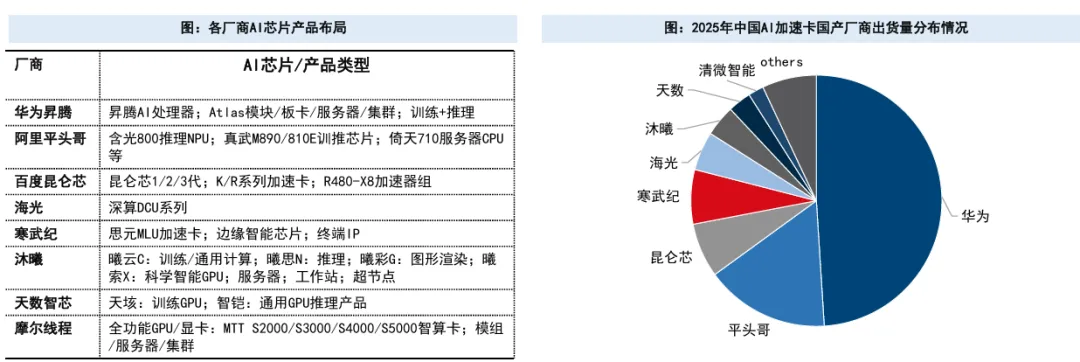
国产算力产业链与市场份额
华为:占比20.4%,位居国产第一。
平头哥:占比6.4%。
其他主要厂商还包括昆仑芯、寒武纪、海光信息等。
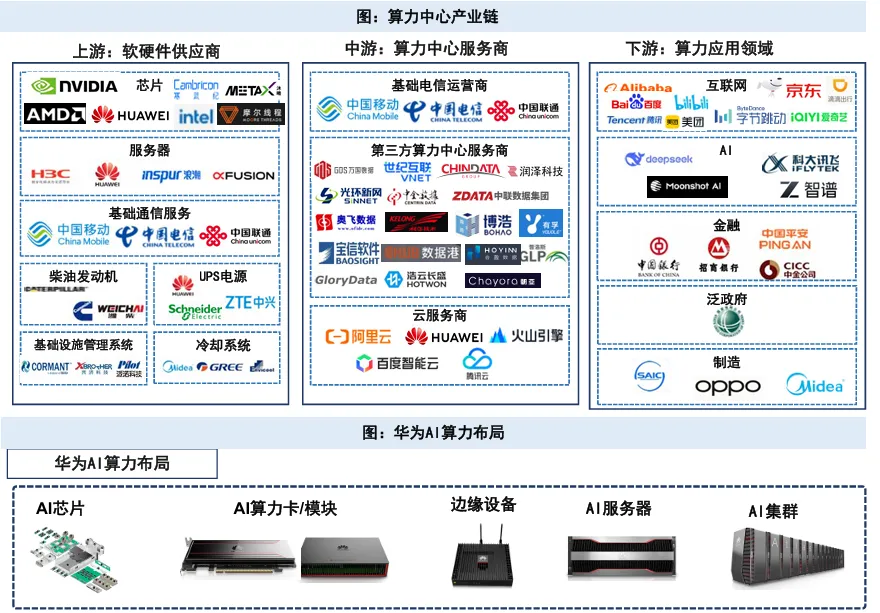
国产算力的竞争焦点已不仅是单卡峰值,而是“芯片 + HBM + 互联 + 服务器 + 编译器/算子库 + 推理引擎 + 模型适配”的全栈效率。
风险提示
国产替代进程不及预期:国内企业在技术、人才上与海外大厂存在差距。
下游需求不及预期。
行业竞争加剧的风险:政策和资本涌入可能导致细分市场竞争激烈,影响企业盈利。
国际关系发生不利变化的风险:产业链部分环节仍依赖海外,国际关系变化可能产生影响。
