


【本文定位】
AI 行业 · 芯片与存储 · HBM(高带宽存储器),读者知道 HBM 是什么,但需要系统理解行业逻辑。本文从技术路线→ 产业链 → 市场规模→ 竞争格局→ 商业模式 → 市场环境等逐一讲解。 下一篇主要围绕 HBM 产业链代表性企业讲解。 免责声明:本文仅为行业研究交流,不构成任何投资建议。文中数据来源于公开资料,如有出入以官方发布为准。
2022 年,HBM 在 DRAM 行业里是一个边缘品类——年收入不到 30 亿美元,占 DRAM 市场不足 4%。一块 GPU 加速卡上,最昂贵的部件是逻辑芯片,内存只是配套。
2025 年,同一块加速卡上,HBM 内存占据了 63% 的物料成本。全球 AI 芯片设计商一年在 HBM 上的采购支出超过 320 亿美元,是 2022 年全市场规模的十倍以上。AI 芯片的成本结构已经逆转——内存取代逻辑芯片,成为价值主体。
这一转变的起点是 2022 年底生成式 AI 的产业化突破。大语言模型的训练和推理对内存带宽提出了远超传统计算的需求,而 HBM 凭借 1024 bit 超宽接口和 3D 堆叠架构,成为唯一能满足这一需求的存储器方案。此后三年,HBM 从存储行业的边缘品类跃升为 AI 基础设施的核心瓶颈。
一个结构性问题:当一块 AI 芯片 63% 的成本被一种内存占据,这个行业的底层逻辑——技术路线如何演进、利润由谁分配、竞争格局是否稳固、中国产业链的机会在哪里——究竟是什么。
一、HBM 是什么:不只是“快一点的 DRAM”
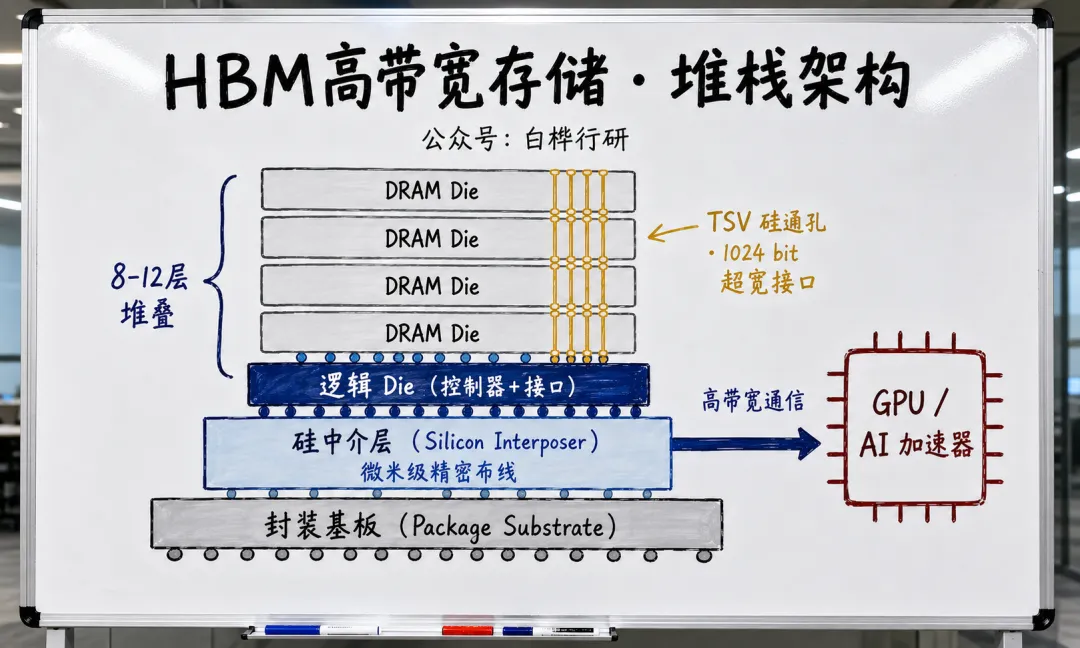
HBM(High Bandwidth Memory,高带宽存储器)是 DRAM 的一个特殊品类。但它跟 DDR5、LPDDR5 这些常见内存有本质区别——HBM 不是插在主板上的一根内存模组,它是通过 3D 堆叠 + TSV 垂直互连 把多层 DRAM die 直接焊在 GPU 旁边(甚至上面)的硅中介层上。它跟 GPU 的物理距离从“厘米级”缩短到了“毫米级”,这才是它“高带宽”的物理根源。
? 什么是 DRAM die? DRAM:动态随机存取存储器,就是我们常说的内存、运存核心芯片。 Die(晶粒 / 裸片):从 硅晶圆 (Wafer) 上切割下来、还没封装的最小芯片本体。 简单一句话:DRAM Die 就是内存芯片去掉外壳、最核心的半导体裸片。
? 什么是 TSV? TSV(Through-Silicon Via),硅通孔,在芯片上钻出垂直贯穿的微孔并填充铜等导电材料。 打个比方:传统平面布线相当于数据“绕远路”从芯片边缘进出,TSV 相当于在芯片上打了电梯井——数据从 1 楼直达 12 楼,物理距离缩了一万倍。HBM 能把多层 DRAM 堆叠在一起,全靠 TSV 做垂直互连。
? 什么是硅中介层(Silicon Interposer)? 硅中介层是一块没有晶体管功能的“纯硅底板”,上面有精密的布线层。 它像一个“芯片级 PCB”——GPU 和 HBM 堆栈不直接焊在主板上,而是先焊在这块硅底板上。因为硅底板上的布线可以做到微米级精度(比普通 PCB 精细上百倍),所以 GPU 和 HBM 之间能实现超高速通信。代价是贵——硅中介层本身的制造成本就不低。
这个概念很重要。HBM 和 DDR5 的核心差异不在于 DRAM 单元本身——两者的存储单元是一样的——而在于 接口宽度和物理距离:
1024 bit 的“超宽接口”是 HBM 一切性能优势的来源,也是一切成本和制造难度的来源。
代际演进:每 2-3 年带宽翻倍
HBM 已走过六代,从 2015 年的 HBM1(1 GB、128 GB/s)进化到 2025-2026 年的 HBM4(64 GB、>2 TB/s)。每一代的带宽翻倍、容量翻倍、堆叠层数增加。
| HBM3E | 当前主力(2025H2-2026) | |||
| 2025 标准发布 / 2026 规模量产 | 关键窗口 |
? 什么是 JEDEC? JEDEC(Joint Electron Device Engineering Council),固态技术协会,全球半导体行业的标准制定组织。
当前正处于 HBM3E→HBM4 的快速迭代窗口。 这个窗口之所以关键,是因为 HBM4 不仅是带宽的提升——它的 I/O 位宽从 1024 bit 翻倍到 2048 bit、独立通道数从 16 翻倍到 32、首次引入了逻辑 Base Die(4nm 工艺,集成错误检测/电源管理/预取功能)、16Hi 堆叠需要引入 Cu-Cu 混合键合(Hybrid Bonding)替代传统微凸块。HBM4 不是 HBM3E 的“升级版”,是一次架构重构。
? 什么是混合键合(Hybrid Bonding)? 混合键合是一种芯片-芯片直接连接技术:把两层芯片的铜触点直接压在一起,通过固态扩散让铜原子自己“长”到一起,同时周围的介电层也粘结在一起。 传统方法(微凸块 + TCB/NCF)相当于两块芯片中间夹着“焊球”——有间隙、有材料损耗、占高度。混合键合是铜对铜“无缝焊接”——省掉了微凸块所占的几十微米高度,I/O 密度可以提升 10 倍以上。工艺难度大:铜面必须平整到原子级别,否则界面有空隙、接触电阻升高。当前良率约 10%。
行业生命周期:科技成长期中段
HBM 行业处于 高速成长期中段——已过导入期(HBM1/HBM2 时期,只有极少数 GPU 用),尚未进入成熟期(短期内看不到天花板)。
2024 年市场规模约 160-170 亿美元,同比增长约 290% 2025 年约 307-380 亿美元(含渠道库存口径差异),同比增长约 80-123% 2026 年预计 500-580 亿美元,同比增长约 54-70%
三年 CAGR 远超半导体行业平均——这不是 DRAM 周期性的复苏,而是一个结构性的新需求驱动。AI 训练芯片对显存带宽的刚性需求,正在创造一个独立于传统 DRAM 周期的新品类。
二、技术路线:已收敛,但良率是所有人的瓶颈
路线收敛:3D TSV 堆叠是一致方向
HBM 行业走到了一个舒服的阶段:技术路线没有根本性分歧。 不像新能源电池在磷酸铁锂和三元锂之间反复摇摆,也不像 AI 芯片在 GPU 和 ASIC 之间争论不休——HBM 的技术方向是明确的:3D TSV 堆叠 + 硅中介层 + TCB/混合键合。三大原厂(SK 海力士、三星、美光)虽然在具体封装工艺上各有选择,但大方向一致。
路线收敛意味着竞争焦点不再是谁选了“对的方向”,而是 谁能先解决制造问题——具体说,就是 16Hi 堆叠的良率问题。
被低估的瓶颈:16Hi 堆叠良率 < 40%
HBM 的核心矛盾是:堆叠层数越高→带宽越高→但良率非线性下降。
传统 DRAM 的良率通常在 90% 以上。而 16Hi HBM 堆叠的总良率可以低至 40% 以下。这意味着每生产 100 颗 16Hi HBM,超过 60 颗是不合格的。
良率问题不是一个“技术细节”,它是理解 HBM 行业一切竞争和定价的核心变量。 具体传导链:
1 2 3 4 5 6 16Hi 良率 < 40% ↓ 有效产能 = 名义产能 × 良率 ↓ 若名义 TSV 产能 38 万片/月,16Hi 有效产能仅约 15 万片/月 ↓ 供不应求→ASP 维持高位 ↓ 谁能把良率从 40% 提到 65%+,谁的利润就翻倍 ↓ HBM4 量产窗口 = 下一次格局洗牌的触发器 “市场以为 HBM 紧缺是因为 AI 需求太猛。这个理解只对了一半。另一半是供给的结构性约束——良率瓶颈决定了有效产能远小于名义产能。这不是一个‘等产能建好就缓解’的临时问题,而是一个‘每代升级都要重新爬良率’的系统性挑战。”
混合键合:下一个技术变量,但不是近期威胁
HBM 行业有一个被讨论很多但短期影响被高估的技术变量——混合键合(Hybrid Bonding)。它的逻辑是:用铜-铜直接键合替代传统微凸块+TCB/NCF,可以把 I/O 间距从 40-50μm 缩到 10μm 以下,理论上能实现更高密度、更低功耗。
2026 年 4 月,SK 海力士完成了 12-die HBM 混合键合验证——12 层 DRAM die 通过铜-铜直接键合,堆叠高度约 720μm(低于 JEDEC 现行 775μm 标准)。技术可行性已被证实。
但关键数字在良率:当前混合键合 HBM 良率约 10%,而商业化量产需要 ≥60%。 主要失效模式包括铜-铜界面空隙、对准误差、NCF 去除不彻底。行业共识是:混合键合 HBM 商业化量产需要一定的时间。
更值得注意的信号是:JEDEC 正在考虑将 HBM4 堆叠高度标准从 775μm 放宽到 900μm。如果通过,传统 TCB+NCF 方案可以继续用于 12-16Hi HBM4 量产——这意味着混合键合的商业化紧迫性降低,时间窗口可能延后。
三、产业链:价值高度集中,利润分配不对称
全景:六段链与利润集中
HBM 从砂子到 GPU 加速卡,经过六个环节:
1 2 3 [上游材料/设备] → [中游 IDM 制造] → [中游封测代工] → [下游 GPU/加速卡] → [终端云厂商] 前驱体/CMP液/球硅 SK海力士/三星/美光 通富/长电/深科技 NVIDIA/AMD Google/MSFT TSV刻蚀/键合/电镀 TSV+先进封装一体化 配套封装测试 设计+集成 训练/推理 这六段的利润分配极不均衡。产业链利润呈高度集中分布——中游 IDM 原厂占据绝大部分价值,上下游环节利润微薄。 理解这一结构,是理解 HBM 逻辑的前提。
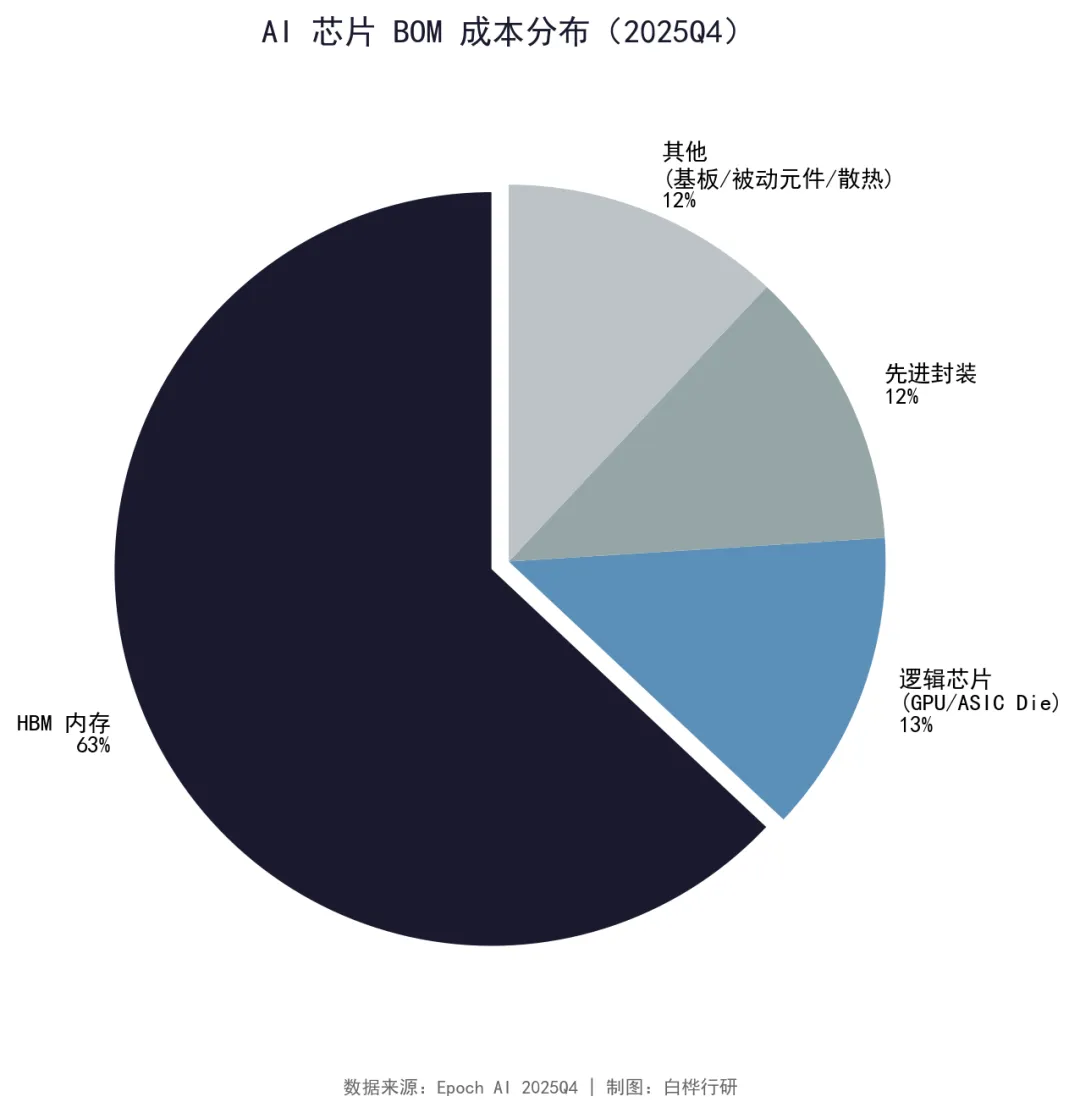
BOM 成本:63% 的结构性含义
Epoch AI 对 2025Q4 主流 AI 芯片的 BOM 分析显示:HBM 内存占 AI 芯片原材料成本的 63%,而逻辑芯片(GPU/ASIC die 本身)仅占 13-14%。
比如一块 AI 加速卡售价约 30,000 美元,其中近 20,000 美元花在了 HBM 内存上,GPU 芯片本身只值 4,000-5,000 美元。AI 芯片实质上成为“HBM + GPU 的封装体”。
价值分配:微笑曲线的反转
用毛利率来衡量产业链各段的议价能力:
| 中游 · IDM 制造(TSV+先进封装) | SK 海力士 / 三星 / 美光 | >60% | 价值最集中、壁垒最高、利润规模最大 |
这个表揭示了一个与直觉相悖的结构特征:在 HBM 产业链上,利润最厚的环节不在“设计”也不在“品牌”,而在“制造+封装的一体化能力”。
传统半导体产业的微笑曲线是“设计利润高、制造利润低”——高通和 NVIDIA 等设计企业利润率最高,台积电等制造企业利润率偏低。但 HBM 产业链呈现相反形态:三家 IDM 原厂同时扮演了台积电(先进制造)+ 日月光(先进封装)的角色——TSV 和先进封装合计占 HBM 成本的 60%+,而这两段都在自己手里。外部封测厂只能做传统封装配套,毛利率 15-18%;IC 载板厂只能供基板,毛利率 20-32%;材料厂只能供耗材,体量有限。
谁掌握了不可替代的制造能力,谁就拿走了产业链上绝大部分利润。 这和台积电近年毛利率从 45% 升至 57% 的逻辑一致:当制造工艺成为稀缺资源,制造就不再是微笑曲线的谷底,而是顶点。HBM 比台积电更极端——IDM 模式意味着制造利润没有外溢给任何代工厂,全部集中于三家原厂。
壁垒矩阵:各环节进入门槛
这张表的核心信息:壁垒最高的三个环节——HBM 芯片制造、TSV 制造、先进封装——国产化率较低。壁垒稍低的环节——材料、载板、封测——中国企业已实现局部突破。
国产替代产业链:三条路径
第一条路:自主研发 HBM 芯片。 TSV + 先进封装 + DRAM 工艺三重壁垒叠加,认证周期 12 个月以上,EUV 光刻机被禁运。长鑫存储 HBM3 12Hi 堆叠后良率仅 35-40%,距离 70-80% 的商业量产线还有一定的提升空间。
第二条路:材料与设备的单点切入。 雅克科技的前驱体(毛利率 41%)、联瑞新材的球硅球铝(毛利率 49%)、安集科技的 CMP 抛光液(毛利率 61%)、北方华创的 TSV 刻蚀——这些企业在单一品类上已经做到了全球前三或国内较高的水平。毛利率 30-60%,远高于封测代工。但从体量看,国产 HBM 材料市场整体收入规模与 SK 海力士单家 HBM 收入相比仍有明显差距。中微公司 PrimoTSV 设备已交付长鑫存储 2 台(订单排至 2027Q2),北方华创 HBM 相关订单占比从 18% 跃升至 35%。
第三条路:封测代工与载板的伴随增长。 通富微电、长电科技、深科技、兴森科技——这些企业不挑战原厂的制造壁垒,而是伴随原厂产能扩张同步增长。毛利率不高(15-32%),但增长确定性强——原厂出货量每增长 50%,封测和载板的需求也同步增长。长电科技 8 层堆叠良率已达 98.5%,深科技 HBM3 封装样品通过 NVIDIA 平台级验证(良率 98.2%),通富微电绑定 AMD MI300X 封测订单。
? 什么是 ABF 载板? ABF(Ajinomoto Build-up Film),味之素堆积膜——一种用于芯片封装基板的绝缘材料,由日本味之素公司开发。
四、市场规模:340 亿美元,但关键在“结构性”
量:CAGR 33%,2025 年 340 亿美元
2025 年全球 HBM 收入约 340 亿美元(Yole Group),占 DRAM 总产值超过 30%。2025-2030 年 CAGR 约 33%。
放在更大的坐标系里:全球存储芯片市场 2025 年约 2,000 亿美元(DRAM 约 1,290 亿 + NAND 约 650 亿)。HBM 仅占存储市场的约 17%,但贡献了 DRAM 市场增长的绝大部分增量。
AI 芯片设计商(NVIDIA、AMD、Google、Amazon 等)2025 年的 HBM 支出已约 320 亿美元——这个数字接近整个 HBM 市场的规模,说明 AI 训练/推理是 HBM 需求的绝对主力(占比 > 90%)。
价:从“量价齐升”到“量增价稳”
HBM 的定价正在经历一个结构性的转变。 2025 上半年 HBM3E ASP 峰值约 17-20 美元/GB,下半年混合 ASP 已回落至 13-17 美元/GB。HBM4 预计 ASP 约 14 美元/GB(TrendForce)。
这个趋势本身不意味着行业利润压缩——因为:
HBM 单价约为 DDR5 的 5 倍,ASP 即使从 18 美元/GB 降到 14 美元/GB,仍然是超高利润产品 ASP 下行主要来自混合效应(HBM3E→HBM4 的初期阶段)+ 供给增加,而非需求萎缩 2025 年 HBM 价格谈判仍初步上调 5-10%,说明供需整体仍偏紧
但从“量×价”双驱动进入了“量持续高增 + 价温和下行”的新阶段。 这不是行业见顶的信号,而是行业进入新一轮产能爬坡的正常节奏。
产能:三强扩产但仍偏紧
2025 年底全球 HBM TSV 产能约 38 万片晶圆/月:
三星约 17 万片/月(全球第一) SK 海力士约 15.5 万片/月 美光约 5.5 万片/月
三家 2025 年资本支出合计超 280 亿美元,2026 年有望超 300 亿美元。美光一家 FY2026 资本开支就约 180 亿美元(同比+30%),主要用于 HBM 产能。
回到基本判断:名义产能 ≠ 有效产能。 当 16Hi 良率仅 40% 时,38 万片/月的名义产能折算下来有效产能仅约 15 万片/月。而且扩产周期长达 2-3 年(TSV 设备交期 + 产线认证 > 18 个月),意味着 2026-2027 年的供给弹性仍然有限。
五、竞争格局:CR3=100%,但“稳”是假象
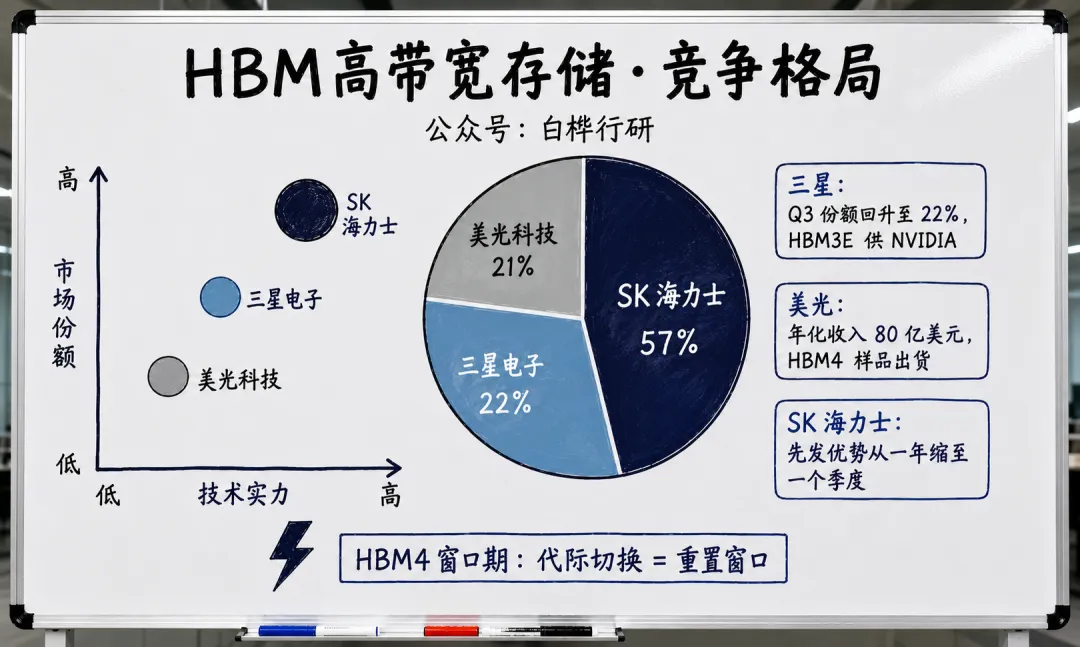
现状:SK 海力士 57% 领先,但差距在缩小
2025Q4 全球 HBM 市场份额(Counterpoint Research):
SK 海力士:约 57% 三星:约 22% 美光:约 21%
但这张“静态照片”掩盖了正在发生的动态变化:
- 三星 HBM 份额从 Q2 的 17% 回升至 Q3 的 22%,Q3 HBM 出货量环比增长 85%,HBM3E 开始供给 NVIDIA。 同时三星 DRAM 总份额从 33.3% 重新反超 SK 海力士至 34.8%,重回全球第一。 [Fact]?( 三星 2025Q3 数据)
- 美光 HBM 年化收入已达约 80 亿美元(Q4 FY2025 run-rate),HBM4 样品已出货(带宽 > 2.8 TB/s,引脚速度 > 11 Gbps),MSCI 目标份额 25%。美光跳过 HBM3 直接量产 HBM3E 的“跨越追赶”策略正在见效。
- SK 海力士的先发优势在衰减。 三家在 HBM4 上的技术差距不到 1 个季度——SK 海力士 2025Q4 量产 vs 三星/美光 2026H1 量产。先发优势从 HBM3E 的“一年以上”缩短到了 HBM4 的“一个季度”。
格局的本质:代际切换 = 重置窗口
HBM 竞争格局的底层逻辑不是“市场份额的惯性延续”,而是“每代产品需要重新通过客户认证”。
NVIDIA 的 HBM 认证周期超过 12 个月。每次代际切换(HBM2E→HBM3→HBM3E→HBM4),所有供应商都要重新送样、测试、认证。这意味着每 2-3 年,竞争格局有一扇重新洗牌的窗口。
HBM4 的这扇窗口正在打开。NVIDIA HBM4 验证(含三星、美光)计划 2026Q2 完成。据行业推算,NVIDIA HBM4 供应商分配为 SK 海力士约 50%(主力)、三星约 30%(验证进度最快)、美光约 20%(补位)。但三星验证进度领先——有望在 2026Q2 率先获得 NVIDIA Rubin HBM4 量产认证。
“SK 海力士一家独大”是一个基于 HBM3E 窗口的静态判断。 三星在 TSV 产能(17 万片/月 vs SK 15.5 万片/月)和先进封装布局上更深,美光在跳过 HBM3 的跨越追赶上速度最快。三家在 HBM4 起跑线上的差距远小于 HBM3E 时代。格局从“一家独大”向“三强拉锯”演变——HBM4 量产窗口是下一次洗牌节点。
六、商业模式:高利润 ≠ 高议价权
商业模式要素
HBM 不是标准化大宗商品,它的交易结构与传统 DRAM 有本质差异。
销售模式:长协锁产能。 HBM 的销售以长期供应协议(LTSA)为主,期限通常 1-3 年,客户提前锁定产能分配。SK 海力士 FY2025 财报披露客户预付款项规模较大,实质上构成产能预订机制——客户先付钱锁定未来 1-2 年的供货量。这与 DDR5 的现货+季度合约混合模式不同。
三家原厂的商业模式差异。 虽然都是 IDM(设计+制造+封测一体化),三家在封装工艺路线上有所不同:
三家商业模式高度趋同:都是 IDM,都深度合作 NVIDIA,都以长期协议锁定产能。
客户合作模式:半定制化联合开发。 HBM 不是标准品——每代 HBM 的接口规格、堆叠层数、功耗参数需要与 GPU 厂商联合定义。以 HBM4 为例,其逻辑 Base Die(4nm 工艺,集成错误检测/电源管理/预取功能)的功能定义是在 NVIDIA 和三家供应商的联合工程团队中确定的。这种“半定制化”合作意味着切换供应商的成本较高——新的 HBM 供应商需要同时通过 JEDEC 标准认证和 GPU 厂商的平台级验证(周期 12-18 个月)。
产能投资模式:CAPEX 由原厂承担,客户预付款分担现金流压力。 三家原厂的 HBM 相关年 CAPEX 合计在数百亿美元量级(三星 2025 年存储相关 CAPEX 约 170 亿美元,含 HBM/DRAM/NAND)。这些投资由原厂自行承担——没有客户共同投资的公开案例。但客户预付款在实质上起到了分担现金流的作用:长约客户的预付款在财报中列于“合同负债”项下,在原厂大规模扩产期间提供无息资金支持。
定价机制:按顆粒计价,代际溢价显著。 HBM 以“顆粒”(stack)为单位定价,ASP 随代际升级而跳升。HBM3E 12Hi 的 ASP 约为 HBM3 8Hi 的两倍以上,HBM4 预计进一步上行。价格每年协商一次,非实时波动。与 DDR5 的现货定价不同,HBM 的 ASP 主要由代际结构(HBM3 vs HBM3E vs HBM4 的出货占比)和技术溢价决定,而非 DRAM 周期的短期供需。
利润有多高?
SK 海力士 FY2025 的核心财务数据:
营收 97.15 万亿韩元,同比 +47% 营业利润 47.21 万亿韩元,同比 +101% 营业利润率 49% Q4 营业利润率 58% 创历史新高 净利润 42.95 万亿韩元,净利润率 44%
HBM 毛利率推算约 60-65%。这个推算的逻辑是:DRAM 整体 OPM 约 49%,加回折旧摊销率约 10-12%,再考虑 HBM 单价为 DDR5 的 5 倍(晶圆消耗量约 3 倍但良率较低)——综合推算 HBM 毛利率约 60-65%。(来源:行业推算,非官方披露。)
美光 CMBU(计算与移动业务部,含 HBM)FY2025 营收 45.4 亿美元(同比 +214%),毛利率 59%。
但利润 ≠ 议价权
HBM 是一个“高利润不等于高议价权”的生意。
为什么?因为利益链两端的力量不对等:
- NVIDIA 数据中心 GPU 毛利率约 75%——NVIDIA 从每块 GPU 中拿走的利润,比 HBM 供应商从每块 GPU 中拿走的利润更多
- NVIDIA 占全球数据中心 AI 加速器收入约 80% 以上(含 AMD、Google TPU、AWS Trainium 等 ASIC)——HBM 三厂对 NVIDIA 的依赖度过高
- NVIDIA 正在推动三源供应商策略——降低单供应商集中度,这意味着议价权向 GPU 厂进一步倾斜
- HBM 高利润来自技术溢价(IDM 模式 + 客户认证壁垒)而不是市场竞争不足——一旦认证壁垒因技术标准化而降低,利润率可能向正常水平回归
HBM 的三重利润驱动:量(出货量增长 70%+)× 价(年涨 5-10%)× 结构升级(HBM4 占比提升)。三重驱动叠加创造了 FY2025 的利润爆发。但 SK 海力士净利润率 44% 在代际切换(HBM4 格局拉锯 + ASP 温和下行)后的持续性,需要进一步观察。
七、政策:中国市场的结构性约束
BIS 出口管制:不是“背景”,是“结构”
? 什么是 BIS? BIS(Bureau of Industry and Security),美国商务部工业与安全局,负责美国出口管制规则的制定和执行。 对华芯片出口管制(包括 HBM 带宽限令、实体清单等)均由 BIS 发布。HBM 行业是 BIS 出口管制的重点领域——HBM 是 AI 芯片的关键组件,而 AI 芯片是美国对华出口管制的核心标的。
美国 BIS 于 2026 年 1 月 15 日发布 final rule,针对先进计算芯片(以 NVIDIA H200、AMD MI325X 为参考基准)对华出口建立双阈值审批体系:
- TPP(Total Processing Performance)< 21,000 且 DRAM 带宽 < 6,500 GB/s → 从美国直接出口至中国适用 case-by-case 审批(需满足 8 项认证条件,包括美国第三方实验室测试、中国出货量不超过美国出货量的 50%、KYC 终端审查等)
- 超过任一阈值 → 适用 presumption of denial(推定拒绝)
- 从第三国转口或境内转让 → 仍适用 presumption of denial,即使芯片本身符合阈值
同日,总统签署公告对非美国生产、经美国转口至中国的先进计算芯片加征 25% 关税——这意味着 SK 海力士和三星的 HBM 若取道美国再出口中国,需额外承担 25% 关税成本。BIS 的 case-by-case 审批路径与关税机制共同实现了“允许出口,但附加成本与条件”的政策设计。
HBM4 带逻辑 die 的品类可能额外触发 ECCN 3A090 和 3A001 分类,以及美国成分 > 25% 规则——这意味着 HBM4 的出口管制可能比 HBM3E 更复杂。
对中国市场的影响是结构性的: 中国 AI 芯片客户(华为昇腾、寒武纪等)的 HBM 需求巨大,但供给端受限——能从合法渠道获取的最高规格 HBM 受带宽阈值约束。长鑫存储 HBM3 12 层堆叠已突破、2025 年底向华为交付样品,但截至 2026 年 4 月尚未接到量产订单,TSV 良率约 60-65%(韩厂 70-75%+),距离规模量产仍有距离。长鑫 HBM3 较三星/SK 海力士落后约 2-3 年,HBM 晶圆投片量全球份额约 3%(2025 年)。
政策风险方向: 美国是否会进一步将带宽限令延伸至 HBM3E 级别?是否将封装载板/TSV 设备纳入管制扩大清单?这两个问题的答案将直接影响中国 HBM 生态的供给结构。
八、结尾
HBM 的核心逻辑清晰:AI 时代,算力需要带宽。带宽不在 CPU、不在 GPU die 本身——而在 GPU 旁边的 HBM DRAM 堆叠体中。HBM 从一种“高性能显卡的专用内存”变成了“AI 算力系统的核心卡位资源”。
HBM 的重要性上升,也意味着竞争规则在改变:HBM3E 时代,SK 海力士凭借先发优势占据 57% 的份额时,市场倾向于认为“格局已定”。但 HBM4 时代的规则不同——三星在 TSV 产能上反超,美光在 HBM4 上跳过 HBM3 跨越追赶,三家在 HBM4 起跑线上的差距不到一个季度。代际切换 = 格局重置。
同时,良率瓶颈(16Hi < 40%)决定了供给的结构性紧张不会因为产能数字增长而自动缓解。有效产能远小于名义产能,这是 HBM 行业相当一段时间内的核心矛盾。
对中国产业链而言,更现实的路径不是追求 HBM 芯片的自主量产(短期内技术代差太大),而是抓住封装载板、材料、设备等配套环节的进口替代窗口——这个窗口正在打开,大基金三期的投资方向也指向这个方向。
免责声明
本文仅为行业研究交流,不构成任何投资建议。文中数据来源于公开资料,如有出入以官方发布为准。