


COMPUTER VISION系列连载 第 12 期
Classification and Understanding
Computer Vision - Classification and Understanding
Classification and Understanding
ABSTRACT
近期计算机视觉分类与理解领域的研究呈现出多元化的趋势,重点在于提升模型的鲁棒性、泛化能力与多模态适应性。在基础视觉表征方面,Burgert et al., 2025[1] 通过受控特征抑制实验重新审视了ImageNet训练模型的纹理偏好,挑战了“CNN偏向纹理”的既有认知。针对长尾分布与少样本场景,Lin et al., 2025[2] 提出了信息保持的两阶段学习策略,Zhao et al., 2025[3] 则通过元环境学习器实现了细粒度小样本增量学习。多模态与跨模态理解是另一重要方向:Zhou et al., 2025[4] 利用状态空间模型进行视频时空信息聚合,Luo et al., 2025[5] 在人物交互检测中引入上下文感知指令,而Zhou et al., 2025[6] 通过无偏原型一致性学习统一了多模态多任务目标再识别。在去偏与生成式模型方面,Ciranni et al., 2025[7] 利用合成偏差放大实现模型去偏,Wang et al., 2025[8] 则优化了扩散分类器的匹配噪声。此外,Hong et al., 2025[9] 证明了未标注数据能够提升多模态大语言模型在细粒度零样本分类上的表现,展示了数据增强与模型协作的潜力。这些工作共同推动了视觉分类与理解在数据偏斜、模态融合与高效学习等挑战下的进步。
01
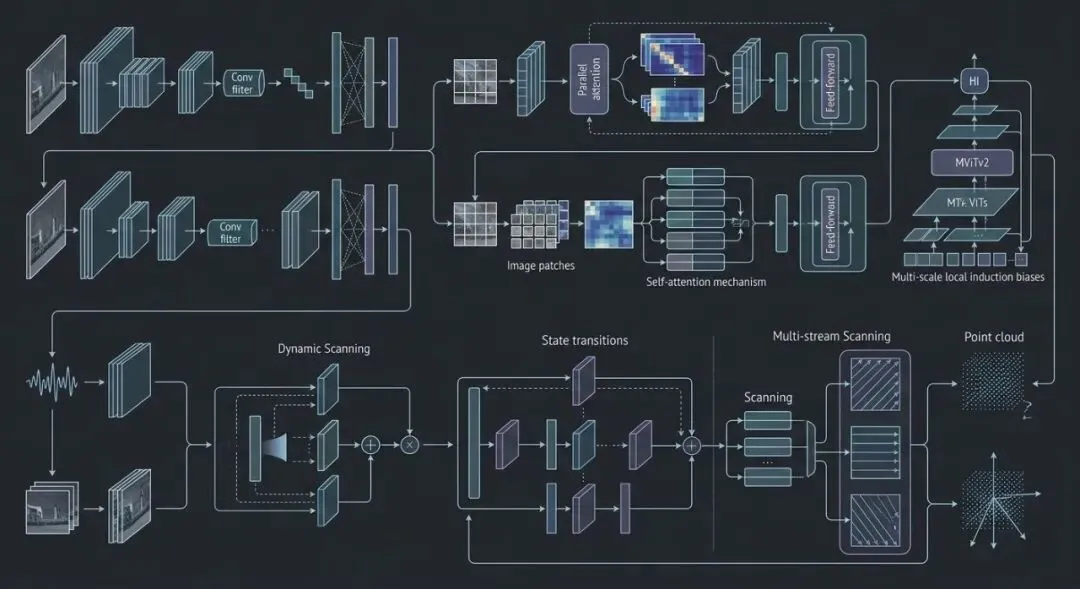
视觉骨干网络的架构演进:卷积、Transformer 与状态空间模型的技术路线分化
当前视觉分类与理解领域正经历骨干网络架构的深层分化,从以卷积为核心的深度残差网络,逐步演变为以自注意力机制为基础的 Transformer 变体,并进一步探索状态空间模型(SSM)等新型序列建模范式。早期研究奠定了卷积网络在 ImageNet 上的统治地位,但后续工作指出其存在频率偏差与纹理捷径问题 。针对这一局限,部分研究尝试通过高阶卷积或局部结构拟合来增强特征表达能力,例如 GPSformer 融合全局感知与局部结构 。Transformer 架构方面,MViTv2 通过多尺度分层设计在分类与检测任务上取得高效性能 ,而 LocalViT 则引入局部归纳偏置以弥补纯 Transformer 缺乏空间先验的不足 。近期,状态空间模型如 DAMamba 采用动态自适应扫描机制,Li et al., 2025[10] 在保持线性复杂度的同时实现了对长程依赖的有效建模,ZigzagPointMamba 则将其推广至点云理解,通过空间-语义双流扫描捕获三维几何结构 。Alias-Free ViT 则从信号处理角度出发,利用线性注意力实现分数阶平移不变性,Michaeli et al., 2025[11] 解决了传统 ViT 在下采样中的混叠问题。此外,MobileODE 提出基于神经微分方程的极轻量网络,Yu et al., 2025[12] 在资源受限场景下平衡了速度与精度。这些架构虽然数学基础不同,但共同趋势是:在保持计算效率的前提下,增强模型对空间结构与长距离语义的感知能力,并逐步摆脱对固定卷积核尺寸的依赖。
02
数据分布适应与增量学习:长尾识别、细粒度分类与类增量场景的统一框架
现实场景中的数据往往呈现长尾分布、类间细微差异或类别持续增加等挑战,促使研究者设计专门的训练与推理策略。针对长尾识别,Lin et al., 2025[2] 提出信息保持的两阶段学习框架,第一阶段用均衡采样保留特征多样性,第二阶段通过蒸馏修正分类器偏差,有效缓解了尾部类别的特征坍塌。细粒度分类方面,传统方法依赖于部件检测与局部对齐,而近期工作倾向于借助多模态大语言模型(MLLM)利用无标注数据提升零样本性能,Hong et al., 2025[9]发现通过将未标记图像的语言描述与视觉特征对齐, 能显著改善未见类别的泛化能力。在类增量学习场景下,Zhao et al., 2025[13]设计了元环境学习器,通过演化与正则化机制使模型在适应新类别时保持对旧知识的鲁棒性, 避免了灾难性遗忘。同时,面向开放词汇的目标检测任务,Sun et al., 2025[14] 的CQ-DINO 引入类别查询机制来缓解梯度稀释问题,使模型能在庞大词汇表上实现高效学习。这些方法虽然针对不同数据分布问题,但核心共性在于:通过两阶段训练、元学习或外部知识注入来平衡类别间的表示质量,并增强模型对稀有或未知模式的泛化能力。
03
多模态表征对齐与场景理解:视觉语言模型、跨域重识别与时空推理
视觉与语言的深度融合已成为提升分类与理解能力的关键技术路线,其应用范围从静态图像扩展到视频、三维场景乃至多模态重识别。针对视频理解,耦表示学习,将动作的语义信息与背景无关特征分离,提升了模型在复杂环境下的鲁棒性 。面向多模态重识别任务(如行人、车辆再识别),Zhou et al., 2025[15] 提出无偏原型一致性学习,通过跨模态原型对齐减少模态差异对分类的干扰。此外,点云与语言结合的场景理解如 SceneVerse 展示了三维视觉语言学习的潜力。遥感领域,Bai et al., 2025[16]的GeoLink 利用 OpenStreetMap 数据作为弱监督信号, 增强了基础模型对地理场景的分类能力。这些工作共同表明:多模态对齐不再局限于图像-文本匹配,而是向视频时序、三维几何、地理空间等更丰富维度拓展,并成为提升分类器泛化性与可解释性的重要手段。
04
模型行为分析与鲁棒性增强:偏差解释、去偏策略与扩散分类器
随着分类模型在安全关键场景中的应用,对其内部决策机制的理解与偏差校正成为研究热点。关于纹理与形状偏差的争论由来已久,Burgert et al., 2025[1] 通过受控抑制实验重新评估了 ImageNet 训练 CNN 的特征依赖,发现模型并非天然偏向纹理,而是对局部统计特征的过度利用导致了这一现象。频率偏差方面,Wang et al., 2025[8] [2023] 揭示了 CNN 倾向于学习高频快捷特征,这在高噪声或对抗样本下易导致错误分类。针对这些偏差,Ciranni et al., 2025[7] 提出一种基于扩散模型的合成偏差放大方法,通过生成极端偏差样本迫使模型学习去偏特征,从而提升下游分类的公平性与泛化性 。另一方面,扩散模型本身也可作为分类器使用,Wang et al., 2025[8] 发现匹配噪声的优化对扩散分类器的判别性能至关重要,通过调整噪声调度可显著改善图像分类精度。在 AI 生成图像检测这一新兴分类任务中,Chen et al., 2025[17] 采用双数据对齐策略,使检测器对不同生成方法具有更好的泛化能力 。这些工作从不同角度剖析模型行为的系统性偏差,并发展出基于合成数据、噪声控制或对比对齐的纠偏手段,为构建更可靠、更透明的视觉分类系统提供了方法论支撑。
REFERENCES
[1] ImageNet-trained CNNs are not biased towards texture: Revisiting feature reliance through controlled suppression. NeurIPS 2025.
[2] Long-Tailed Recognition via Information-Preservable Two-Stage Learning. NeurIPS 2025.
[3] Evolving and Regularizing Meta-Environment Learner for Fine-Grained Few-Shot Class-Incremental Learning. NeurIPS 2025.
[4] State Space Prompting via Gathering and Spreading Spatio-Temporal Information for Video Understanding. NeurIPS 2025.
[5] InstructHOI: Context-Aware Instruction for Multi-Modal Reasoning in Human-Object Interaction Detection. NeurIPS 2025.
[6] Unbiased Prototype Consistency Learning for Multi-Modal and Multi-Task Object Re-Identification. NeurIPS 2025.
[7] Diffusing DeBias: Synthetic Bias Amplification for Model Debiasing. NeurIPS 2025.
[8] Noise Matters: Optimizing Matching Noise for Diffusion Classifiers. NeurIPS 2025.
[9] Unlabeled Data Improves Fine-Grained Image Zero-shot Classification with Multimodal LLMs. NeurIPS 2025.
[10] DAMamba: Vision State Space Model with Dynamic Adaptive Scan. NeurIPS 2025.
[11] Alias-Free ViT: Fractional Shift Invariance via Linear Attention. NeurIPS 2025.
[12] MobileODE: An Extra Lightweight Network. NeurIPS 2025.
[13] Salient Concept-Aware Generative Data Augmentation. NeurIPS 2025.
[14] CQ-DINO: Mitigating Gradient Dilution via Category Queries for Vast Vocabulary Object Detection. NeurIPS 2025.
[15] EA3D: Online Open-World 3D Object Extraction from Streaming Videos. NeurIPS 2025.
[16] GeoLink: Empowering Remote Sensing Foundation Model with OpenStreetMap Data. NeurIPS 2025.
[17] Dual Data Alignment Makes AI-Generated Image Detector Easier Generalizable. NeurIPS 2025.
PREVIOUS
第 11 期 — Computer Vision: 3D Rendering & Reconstruction
NEXT ISSUE
Computer Vision — Image and Video Generation
深入解析计算机视觉领域前沿进展

- END -