


COMPUTER VISION系列连载 第 11 期
3D Rendering & Reconstruction
Computer Vision - 3D Rendering & Reconstruction
3D Rendering & Reconstruction
ABSTRACT
近期3D渲染与重建领域的研究呈现出多维度突破,核心聚焦于提升场景表示的鲁棒性、动态适应性与计算效率。基于3D高斯溅射(3DGS)的框架持续演进:针对非受控环境,LI et al., 2025[1]提出非对称双高斯模型以抑制伪影;Liao et al., 2025[2]与Wu et al., 2025[3]分别引入事件相机信号,实现自由轨迹与极端光照下的动态重建。He et al., 2025[4]通过元学习Phong模型实现分布外场景重光照,而Zhang et al., 2025[5]则用可交换高斯表示平衡几何与外观。在几何重建方面,Li et al., 2025[6]利用稀疏体素先验提升表面精度,Shin et al., 2025[7]结合扩散先验与曲率匹配实现自适应重建。动态场景处理上,Xu et al., 2025[8]提出4D高斯Transformer从单目视频学习时空场,Hu et al., 2025[9]则专攻眼科手术中手-器械交互的精细重建。此外,Wang et al., 2025[10]通过压缩光场令牌显著降低渲染计算成本,Kulhanek et al., 2025[11]引入层级细节机制以支持大规模场景高效渲染。这些工作共同推动了从静态到动态、从实验室到真实世界、从单模态到多模态感知的范式跃迁。
01
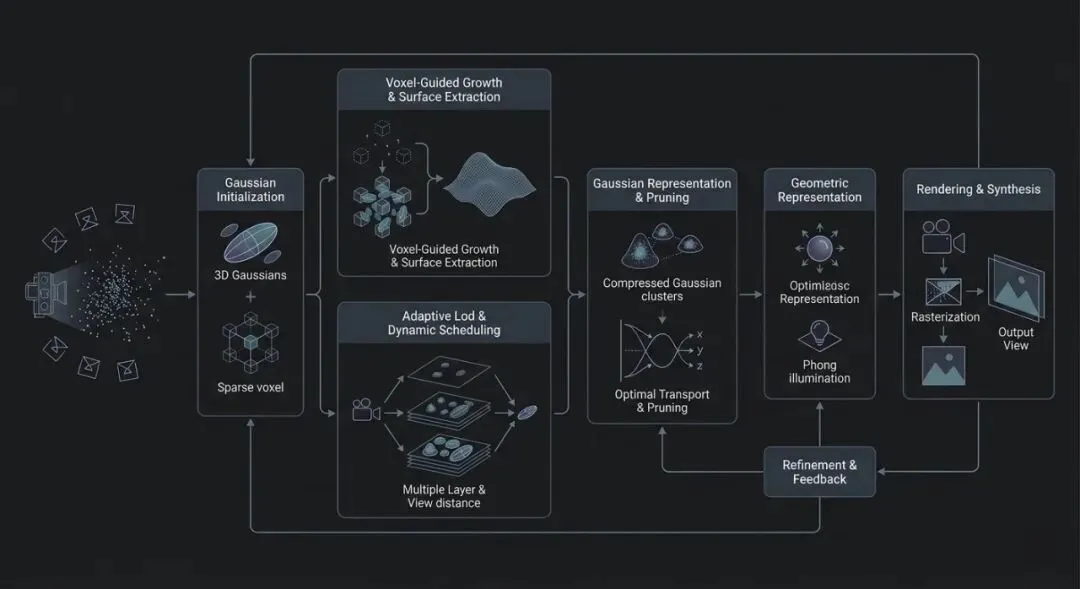
从高斯原语到表面约束:3DGS的几何保真度与紧凑化演进
3D高斯泼溅(3DGS)凭借其显式表示与实时渲染优势,已成为场景重建的基座技术,但早期工作普遍面临几何不精确与存储开销大的问题。近期研究从多个维度对此进行改进。在几何对齐方面,Zhang et al., 2025[5] 提出的EGGS通过可交换的2D/3D高斯表示,在视角合成中平衡了几何与外观的权重,使得高斯既能保持渲染质量又能输出更准确的表面。而 Li et al., 2025[6] 的GeoSVR则另辟蹊径,利用稀疏体素引导高斯生长,从离散原语中提取连续曲面,显著提升了表面重建的几何精度。在存储与效率方面,Wang et al., 2025[12] 将高斯裁剪建模为最优传输问题,通过“牧群”策略全局压缩冗余高斯,实现3-4个数量级的存储缩减,且不影响渲染质量。针对大规模场景,Kulhanek et al., 2025[11] 提出的LODGE引入层级细节(Level-of-Detail)管理,根据视角距离动态调度高斯原语,在保持帧率的同时扩展了3DGS的适用尺度。此外,He et al., 2025[4] 的MetaGS将元学习与Phong光照模型融合,使高斯表示具备对分布外光照的适应能力,间接提升了重光照场景下的几何一致性。这些工作共同表明,3DGS正从纯渲染利器向兼顾几何、紧凑性与鲁棒性的通用表示迈进,其核心在于为高斯原语注入更强的表面先验或结构化约束。
02
动态世界的时间维度:4D重建从多视同步到单目视频的突破
动态场景重建长期依赖多视角同步视频或已知时序信息,而近期研究正将其推向更灵活的单目视频输入。针对手术等复杂交互场景,Hu et al., 2025[9] 聚焦手持器械与眼组织的动态重建,通过专门设计的运动分解模块实现了高精度4D重建。更进一步,Xu et al., 2025[8] 提出的4DGT将4D高斯与Transformer架构结合,仅从单目视频学习时空高斯变换,避免了多视同步的严苛要求。对于极端动态或光照条件,事件相机提供了高速、高动态范围的替代输入。Liao et al., 2025[2] 的EF-3DGS利用事件流辅助自由轨迹的高斯泼溅,在剧烈运动下仍能维持稳定的渲染质量;Wu et al., 2025[3] 的EAG3R则直接从事件数据估计几何,在弱光或快速运动场景中表现出色。在参数优化层面,Li et al., 2025[13] 提出仅用RGB图像监督动态场景中的相机参数优化,无需位姿标注即可实现一致的4D重建。这些工作揭示了一个趋势:动态重建正从“离线多视+强监督”转向“在线单目+弱/自监督”,其中事件相机与Transformer架构分别扮演了解决运动模糊和建模长时序依赖的关键角色。
03
先验驱动的稀疏视图重建:扩散模型、Transformer与多模态LLM的竞争与协同
从单视图或稀疏视图中恢复完整3D结构是极具挑战的逆问题,当前解决方案正围绕强大的生成先验展开激烈竞争。基于扩散模型的路线,Shin et al., 2025[7] 通过前向曲率匹配似然更新,将扩散先验与几何似然结合,实现了自适应的稀疏视图重建,克服了传统方法对精确位姿的依赖。而Ye et al., 2025[14] 的ShapeLLM-Omni则引入多模态大语言模型(LLM),将文本、图像统一到3D生成与理解框架中,突破了纯视觉先验的语义瓶颈。在场景理解层面,Xu et al., 2025[15]的SIU3R超越了特征对齐范式,同时进行场景语义解析与3D重建,使得重建结果不仅几何完整还具备语义一致性。Li et al., 2025[16] 的Rig3R进一步引入刚体感知条件,在重建过程中自动发现物体部件级刚体结构,适用于机械臂操作等任务。对比这些方法:扩散模型擅长补全纹理和细节,但计算开销较大;Transformer端到端方案(如LRM变体)速度快但依赖大规模合成数据;而LLM驱动的方案则实现了多模态融合,但其几何精度仍有提升空间。未来趋势可能是将扩散先验的强生成能力与Transformer的高效推理结合,同时借助LLM的语义理解实现更可控的重建。
04
跨越模态与物理屏障:多传感器融合与物理约束重建
当传统RGB相机在散射介质、弱光或非可见光场景中失效时,多模态传感器与物理先验成为重建的关键桥梁。射频信号穿透性强,Lu et al., 2025[17] 的GeRaF首次将几何重建拓展至射频域,利用信号强度与飞行时间恢复3D结构,为穿墙或无光场景开辟了新路径。X射线成像在医疗和工业领域不可或缺,Wang et al., 2025[18] 的X-Field构建了物理信息引导的神经表示,将射线衰减模型嵌入网络,实现了高保真的3D X射线重建,缓解了稀疏投影下的病态性。在计算成像端,Wang et al., 2025[10] 的CLiFT提出压缩光场令牌,将高维光场信息编码为紧凑特征,在自适应神经渲染中兼顾效率与质量,适用于光场相机等特殊硬件。针对传统几何的鲁棒性问题,Li et al., 2025[19] 的Cycle-Sync通过增强循环一致性同步,在噪声或缺失匹配下仍能恢复全局相机位姿,为多模态重建提供了可靠的几何锚点。值得注意的是,Chen et al., 2025[20] 将点云补全任务提升到完整结构引导的层面,利用聚类与实例级对比学习,使补全结果服从物体级结构先验,与物理约束重建形成了互补。这些工作共同表明,3D重建正从单一RGB模态向“传感器融合+物理模型”转型,其核心挑战在于如何设计统一的表示来融合异质数据,同时保持对物理过程的可解释性。
REFERENCES
[1] Robust Neural Rendering in the Wild with Asymmetric Dual 3D Gaussian Splatting. NeurIPS 2025.
[2] EF-3DGS: Event-Aided Free-Trajectory 3D Gaussian Splatting. NeurIPS 2025.
[3] EAG3R: Event-Augmented 3D Geometry Estimation for Dynamic and Extreme-Lighting Scenes. NeurIPS 2025.
[4] MetaGS: A Meta-Learned Gaussian-Phong Model for Out-of-Distribution 3D Scene Relighting. NeurIPS 2025.
[5] EGGS: Exchangeable 2D/3D Gaussian Splatting for Geometry-Appearance Balanced Novel View Synthesis. NeurIPS 2025.
[6] GeoSVR: Taming Sparse Voxels for Geometrically Accurate Surface Reconstruction. NeurIPS 2025.
[7] Adaptive 3D Reconstruction via Diffusion Priors and Forward Curvature-Matching Likelihood Updates. NeurIPS 2025.
[8] 4DGT: Learning a 4D Gaussian Transformer Using Real-World Monocular Videos. NeurIPS 2025.
[9] Towards Dynamic 3D Reconstruction of Hand-Instrument Interaction in Ophthalmic Surgery. NeurIPS 2025.
[10] CLiFT: Compressive Light-Field Tokens for Compute Efficient and Adaptive Neural Rendering. NeurIPS 2025.
[11] LODGE: Level-of-Detail Large-Scale Gaussian Splatting with Efficient Rendering. NeurIPS 2025.
[12] Gaussian Herding across Pens: An Optimal Transport Perspective on Global Gaussian Reduction for 3DGS. NeurIPS 2025.
[13] RGB-Only Supervised Camera Parameter Optimization in Dynamic Scenes. NeurIPS 2025.
[14] ShapeLLM-Omni: A Native Multimodal LLM for 3D Generation and Understanding. NeurIPS 2025.
[15] SIU3R: Simultaneous Scene Understanding and 3D Reconstruction Beyond Feature Alignment. NeurIPS 2025.
[16] Rig3R: Rig-Aware Conditioning and Discovery for 3D Reconstruction. NeurIPS 2025.
[17] GeRaF: Neural Geometry Reconstruction from Radio Frequency Signals. NeurIPS 2025.
[18] X-Field: A Physically Informed Representation for 3D X-ray Reconstruction. NeurIPS 2025.
[19] Cycle-Sync: Robust Global Camera Pose Estimation through Enhanced Cycle-Consistent Synchronization. NeurIPS 2025.
[20] Complete Structure Guided Point Cloud Completion via Cluster- and Instance-Level Contrastive Learning. NeurIPS 2025.
PREVIOUS
第 10 期 — Applications: Time Series
NEXT ISSUE
Computer Vision — Classification and Understanding
深入解析计算机视觉领域前沿进展

- END -