


往期推荐:
文献分享:通过协作式人工智能辅助胸部X光片报告增强放射科工作流程,利用大型视觉语言模型:一项概念验证研究
文献分享:CT影像组学模型中基于活检锚定训练策略优于全病灶训练策略:一项多瘤种队列研究
文献分享:BioGDR: 多模态可解释深度学习框架用于转录组指导的精准肿瘤学和药物机制分析
文献分享:乳腺钙化病变恶性预测:基于超声影像肿瘤内及肿瘤周围区域的影像组学分析
论文标题:Reporting efficiency in diagnostic imaging: Can plug-and-play general-purpose large language models outperform conventional speech recognition?
期刊:European Radiology
DOI:https://doi.org/10.1007/s00330-026-12524-5
作者:Constance de Margerie-Mellon et al.
发表日期:2026年4月20日在线发表
文献汇报 | 原创研究类
目 录
一、研究背景与意义
二、研究目的
三、研究方法
3.1研究设计与参与者
3.2报告生成流程
3.3评估指标
四、研究结果
4.1报告生成时间
4.2错误分析
4.3定量分析
五、讨论与局限性
六、总结与展望
七、可改进点与延伸思考
一、研究背景与意义
放射科医生目前主要依赖传统语音识别(CSR)软件来生成诊断报告。这些系统采用基于统计隐马尔可夫模型和高斯混合模型的手工音频处理流程,专门针对放射学报告进行优化。自1990年代末引入以来,CSR技术在2000年代初被广泛采用,逐渐取代了医疗打字员。
然而,CSR系统存在固有问题:
• 语法和拼写错误频发
• 转录错误(插入、遗漏、替换)影响准确性
• 需要大量后期编辑
• 效率受个人习惯影响显著
大语言模型(LLM)的发展为医学报告生成带来了新的可能性。LLM具有深度上下文理解能力,能够生成结构化、上下文感知的文本。
二、研究目的
本研究旨在前瞻性、多中心评估通用大语言模型(GPT-4o)在日常临床实践中辅助放射学报告生成的效率,并与传统语音识别(CSR)进行对比。
主要比较指标:
• 报告生成时间(初稿时间、编辑时间、总时间)
• 报告错误类型与发生率
• 不同放射科医生间的个体差异
三、研究方法
3.1 研究设计与参与者
本研究为前瞻性、多中心研究,在四家法国学术中心开展。纳入5名认证放射科医生(R1-R5),经验年限从6年至25年不等。研究共生成400份报告(CSR组和LLM组各200份)。
3.2 报告生成流程
研究采用交叉设计,分为四个阶段交替使用CSR和LLM进行报告生成。报告包括CT和MRI检查,未上传任何患者身份信息。
3.3 评估指标
错误分类(定性分析):语法/拼写错误、转录错误、重新措辞、违反指令、虚构(confabulation)、幻觉(hallucination)。
定量分析:使用莱文斯坦距离(Levenshtein distance)评估文本变化程度。
四、研究结果
4.1 报告生成时间

图1(原文Fig. 1)研究工作流程图:展示了5位放射科医生如何交替使用CSR和LLM生成报告,最终形成CSR组和LLM组各200份报告的实验设计。
纳入分析的报告共400份,其中301份(75.3%)为CT报告,99份(24.8%)为MR报告。
表1 报告生成时间对比(中位数,秒)
指标 | CSR组 | LLM组 | p值 |
初稿生成时间 | 250 (180; 371) | 194 (120; 305) | <0.01 |
编辑时间 | 54 (28; 84) | 44 (28; 69) | 0.03 |
总时间 | 318 (218; 478) | 238 (154; 349) | <0.01 |
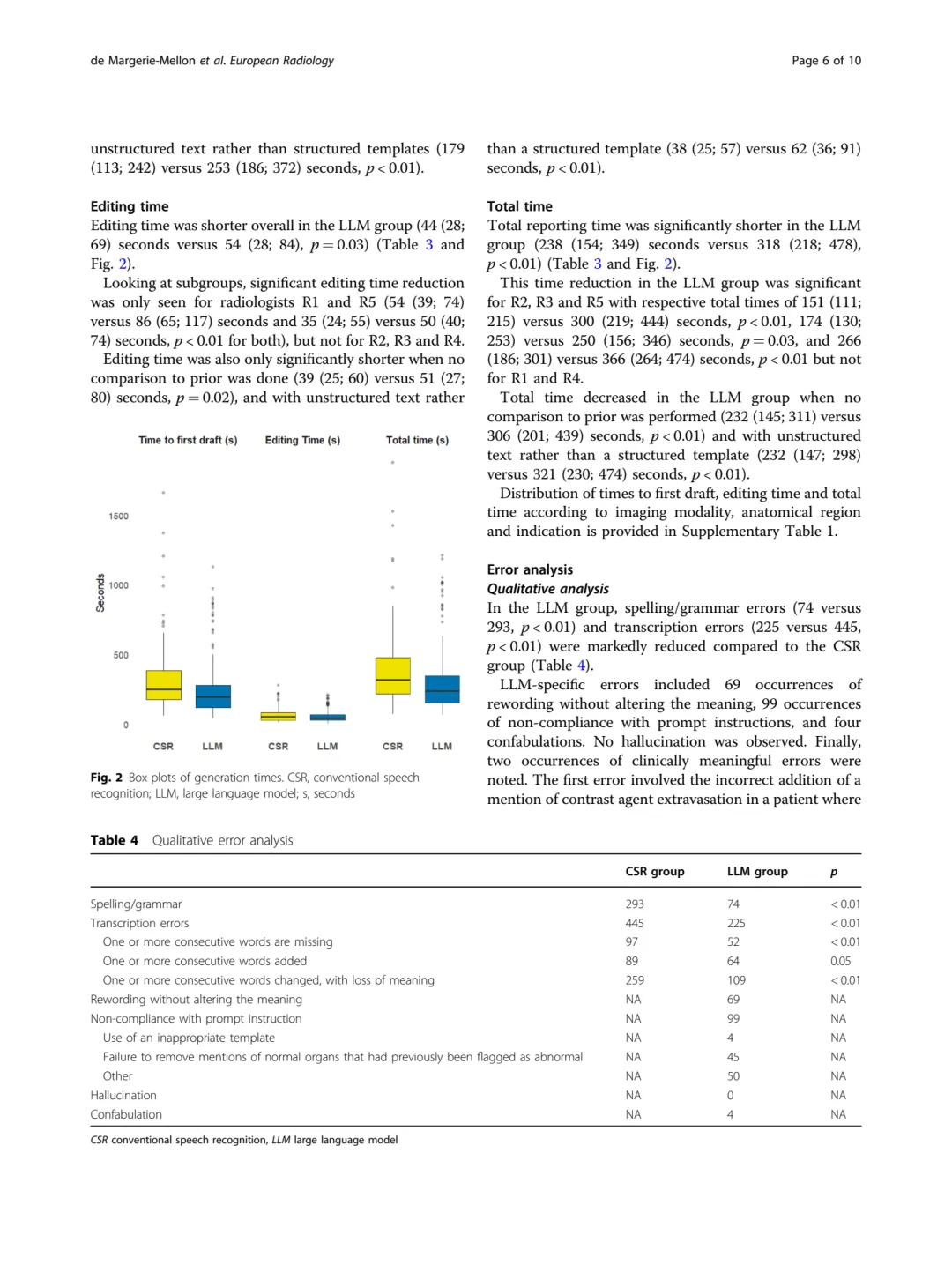
图2(原文Fig. 2)生成时间箱线图:展示了CSR组与LLM组在初稿时间、编辑时间和总时间上的分布对比。
关键发现:
• 总体而言,LLM组总报告生成时间显著短于CSR组(238秒 vs 318秒,p<0.01)
• 但在个体层面,仅3/5的放射科医生显示出时间节省
• 使用非结构化文本时LLM优势更明显(232秒 vs 321秒)

4.2 错误分析(定性)
表2 定性错误分析
错误类型 | CSR组 | LLM组 | p值 |
语法/拼写错误 | 293 | 79 | <0.01 |
转录错误 | 445 | 225 | <0.01 |
重新措辞 | - | 69 | - |
违反指令 | - | 99 | - |
虚构(confabulation) | - | 4 | - |
重要发现:
• LLM组语法/拼写错误减少72%(293→79)
• 转录错误减少49%(445→225)
• 未观察到"幻觉"(严重事实性错误)
• 发现4例"虚构":LLM生成原始语音中不存在的虚假描述
4.3 定量分析
表3 定量错误分析(莱文斯坦距离)
指标 | CSR组 | LLM组 | p值 |
字符级莱文斯坦距离 | 20 (5; 43) | 43 (8; 156) | <0.01 |
词级莱文斯坦距离 | 7 (3; 14) | 9 (2; 26) | 0.10 |
字符级相似度(%) | 98.5 (96.5; 99.6) | 96.6 (89.8; 99.3) | <0.01 |
解读:LLM组的莱文斯坦距离更高,说明LLM对原始语音的改动更大,但也显著减少了传统错误。
五、讨论与局限性
主要发现讨论
1. 效率提升的异质性:LLM的时间节省效果因放射科医生而异,主要与对模板的熟悉程度、个人工作流程差异有关。
2. LLM的错误模式:LLM作为生成模型而非转录模型,有时会重新组织句子,可能导致内容冗长或错误解读临床指标。
研究局限性
• 仅测试了GPT-4o一种LLM
• 可能存在观察者偏倚
• 研究在法语环境进行,外推性有待验证
• 未评估报告的临床准确性
六、总结与展望
研究结论
• LLM辅助放射报告能有效减少语法、拼写和转录错误
• 总体报告生成时间显著缩短(238秒 vs 318秒)
• 时间节省效果因放射科医生个人习惯而异
• LLM引入了新的错误类别(虚构、违反指令)
• 仍需人工监督以确保临床准确性
未来展望
• 集成更先进的语音识别技术
• 针对放射学领域微调的专用LLM
• 开发实时错误检测系统
• 多语言环境的验证与优化
七、可改进点与延伸思考
【方法层面】
• 可探索更多LLM(如Claude、Gemini)的对比性能
• 针对放射学报告进行领域适配和微调
• 开发专用的报告生成提示词模板
【实验层面】
• 增加样本量和多中心验证
• 纳入更多检查类型的评估
• 进行纵向研究评估长期使用效果
【泛化性】
• 在英语、中文等不同语言环境验证
• 评估不同电子病历系统的兼容性
• 测试不同专业水平医生的使用效果
【临床转化】
• 开发实时错误检测和预警系统
• 集成结构化报告标准和术语规范
• 建立人工+AI双重审核机制