


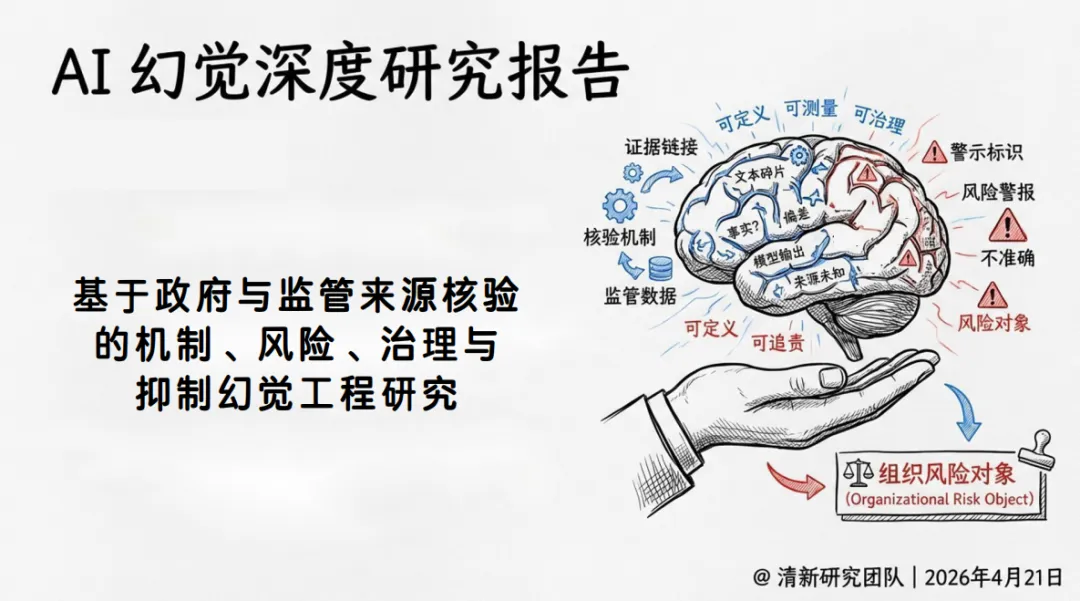
AI 幻觉深度研究报告
可测量证据 · 链接文本 · 核验机制 · 警示标识 · 风险警报
@ 清新研究团队 | 2026年4月21日
核心结论速览
GOV.UK Chat 实验中,用户满意度并不低,但官方仍观察到若干幻觉案例。官方特别提醒:GOV.UK 品牌的可信度让用户低估系统失真风险,形成过度信任。
| 高可信品牌 | 低估风险 | 更需要显性护栏 |
| 普通聊天场景 | 谨慎对待 |
MHRA 案例表明,RAG 可显著压低重大幻觉,但更严格的护栏也可能提高遗漏率。"压低幻觉率"不自动等于"提升系统有效性",必须处理两者之间的平衡。
| 高风险场景 | |||
| 低风险创意场景 |
第一章:什么是 AI 幻觉?
生成模型追求的是高概率文本,而不是外部世界的真值证明。语言流畅、结构完整、语气笃定,会让用户把表达质量误判为事实质量。
六种典型幻觉类型
直接编造事实、数字、事件或对象。在开放问答和陌生主题里较常见,但因用户有戒心,反而较容易被识别。
伪造、错配或误引法规、判例、论文、页码、链接和脚注。一旦进入PPT、政策文件、学术写作,会从"模型错误"变成"组织知识污染"。
答案在一般常识上似乎没错,但对当前国家、行业、时间点或任务边界并不适用。越像"专家陈述",越不容易意识到推理链建立在证据空白上。
模型在证据不足时补出一套连贯、顺滑、貌似严密的解释链条。迷惑性极强。
常见于 Agent 或工具调用:不仅说错话,还会调用错工具、传错参数、误触发流程。危害从"误导"升级为"执行错误"。
系统为安全而频繁不回答,导致关键信息缺失。过度保守的护栏同样会造成风险——遗漏有时并不比幻觉更轻。
第二章:幻觉的五个根因机制
模型的本职是根据分布生成最可能的后续文本,而非自动连接外部真值。只要现实约束没有被及时注入,模型就会用语言概率去填补知识空白。"能接着说下去"本身就是幻觉的结构起点。
通用模型更擅长平均化知识,不擅长处理实时、版本敏感、组织内部或强专业语境的问题。幻觉并非均匀分布,而是在专业边界处显著升高。
很多幻觉并非"模型故意乱说",而是系统把"必须回答"当成默认目标。如果系统没有设计拒答逻辑,模型会倾向于继续补全,而不是承认自己不知道。
很多团队把"回复快、看起来全、语气像专家"当作优秀体验,却忽略了可验证性。这种激励会把系统推向更强的生成姿态,结果:越像"聪明助手",越可能在关键时刻给出不该被执行的答案。
RAG 的核心价值是把回答锚定到权威知识源,但它并不自动保证真实。如果检索内容召回不完整、文档版本过期、来源互相矛盾,生成层仍可能拼出似是而非的回答。RAG 是降幻觉的工程路线,不是幻觉治理的终点。
第三章:真实世界案例
官方对157名用户的后续调查显示:近70%认为有用,略低于65%表示满意。但官方同时观察到若干幻觉案例。
教训:高满意度并不自动等于高可信度。权威界面的品牌信任会让用户低估系统失真风险,形成过度信任。公共服务、医院、高校、金融机构等权威界面,比普通聊天场景更需要显性护栏。
另一教训:很多幻觉不是在答案端发生的,而是在问题端被放大的。问题重写、澄清询问、范围收缩与引导式交互,是前置减险的重要环节。
GAO 报告显示,2024年11个联邦机构报告的生成式AI用例为282个,较2023年的32个约增长9倍。同期总体AI用例从571增至1110。
282个生成式AI用例中,61%集中在内部使命支持,15%用于政府服务,9%用于健康医疗。
教训:生成式AI首先渗透的是"写、读、搜、总、跟踪"等日常流程。越是高频、低摩擦、被默认为是"只是辅助"的环节,越需要前置的幻觉护栏。当采用加速而治理滞后时,幻觉问题就会从"试验风险"变成"运营风险"。
FDA 指出,生成式AI在医疗中有巨大潜力,但当输出边界不清时,会增加对预期用途和风险分类的监管困难。FDA 官员表示,已授权超过1200个 AI-enabled medical devices,说明高风险行业中的AI使用已进入规模化监管阶段。
MHRA 的临床问答对比结果(333次测试):
| SmartGuideline(RAG+强护栏) | 0次(0%) |
教训:RAG与强护栏能压低重大幻觉,但也可能引入遗漏风险。抑制幻觉工程必须把"遗漏风险"与"幻觉风险"在同一张决策表上权衡。
第四章:幻觉治理六层栈
先画任务风险矩阵,按"后果风险"分级:健康/安全/权利/财务 → 禁止或降级使用;专业辅助/一般问答/创意草拟 → 允许模型辅助。只有先做任务分级,才知道护栏强度该放在哪里。
优先使用受控知识源、版本化文档、内部知识库与RAG,让答案尽量回溯到可验证证据上。RAG的目标不是让回答更长,而是让回答更能被审计,减少面对陌生问题时的编造。
在系统指令中明确规定:"找不到就拒答,不要伪造来源"。一个不能承认自己不知道的系统,必然会用语言去填补空白。对于研究、政策、法律、医疗和公共服务,"拒答"往往比"乱答"更有价值。
对高风险输出做事实校验、引用核对、规则匹配、结构化比对和异常检测。对正式文稿与对外材料,要求关键事实必须能回链到原始来源。验证不是把模型输出全盘否定,而是把"可直接采信"降到最低。
记录提示、模型版本、检索来源、回答文本、人工修订、用户反馈和异常案例。上线没有日志,组织就无法回放错误链条,也无法判断问题出在模型、检索、提示还是流程。日志是"下次不再犯同样错误"的基础设施。
永远不是模型,而是组织如何分配权力与责任。明确业务 owner、模型 owner、审核责任人、供应商边界、升级通道与事故响应机制。一旦责任模糊,幻觉就会在组织中被放任地方式和责任的方式被放任。
第五章:Agent 时代的特殊风险
NCSC 指出,提示注入不是 SQL 注入的简单翻版,因为 LLM 天生不稳定地区分指令与数据。只要 Agent 系统摄入了外部文本,就可能把恶意内容当作新指令执行。
Agent 场景的核心不是"回复像不像人",而是"系统边界能不能守得住"。当模型能调用工具,"说错"和"做错"之间的距离就会大幅缩短。
✓ 最小权限(Least Privilege)
✓ 外部内容标注(External Content Labeling)
✓ 关键动作确认(Critical Action Confirmation)
✓ 确定性校验(Deterministic Validation)
✓ 可熔断设计(Circuit Breaker Design)
第六章:原创概念与行动路线图
五个原创概念(清新研究团队提出)
把"最像真的输出"误认为"接近真实的答案"。治理意义:要把证据、来源和不确定性显式前置,拆掉"语言=真实"的默认心理。
模型先伪造、错配或误引来源,再用脚注、链接、判例名把缺失证据包装成"已核验链条"。治理意义:来源必须能回链到原文,关键场景禁止无检索生成参考文献。
模型自己并无稳定依据,组织却让它介入高后果任务。对这些区域,要么禁用生成式AI单独处理,要么把它降格为辅助工具。
收紧护栏能压低幻觉率,却可能抬高遗漏率、拒答率和信息不全率;反之亦然。不同场景必须配置不同阈值,不能用一套参数治理所有任务。
组织表层设置了 human-in-the-loop,但人工审核既不充分也不可证真,最后既没控住风险,也没形成责任归属。人工审核必须有明确职责、训练标准、升级路径与日志留痕。
行动路线图(30-60-90天)
标出哪些输出会进入正式文稿、数据库、审批流程或自动化执行链
先找"低置信高伤害区",再谈模型扩展
为高风险问答场景接入受控知识源、版本化文档与 RAG
把"找不到就拒答""必须附来源""引用不可伪造"写进系统指令与产品规则
把错误反馈入口产品化,形成可追踪的工单和案例库
明确谁审、审什么、怎么升级、如何留痕,避免责任折扣门
对关键输出建立抽检、复盘回放与红队测试流程
让每次幻觉事件都能被解释、被归因、被修正——形成组织的幻觉治理资产
真正有竞争力的组织,不是让模型看起来无所不知,
而是让模型在不知道时停下来、在高风险时退后一步。
@ 清新研究团队 | 2026年4月21日
本文提供75页完整版文件下载,请点击文末“阅读原文”。
「智盾矩阵·大模型安全智库」帮会是FreeBuf知识大陆的重量级帮会,目前已入选FreeBuf钻石星选帮会——官方认证高信誉与高质量,帮会聚焦人工智能与大模型安全领域,致力于打造全球视野下的专业资源聚合平台。截止目前帮会已累计更新4100+文档资源,为从业者提供从理论到实践的全维度知识支持。
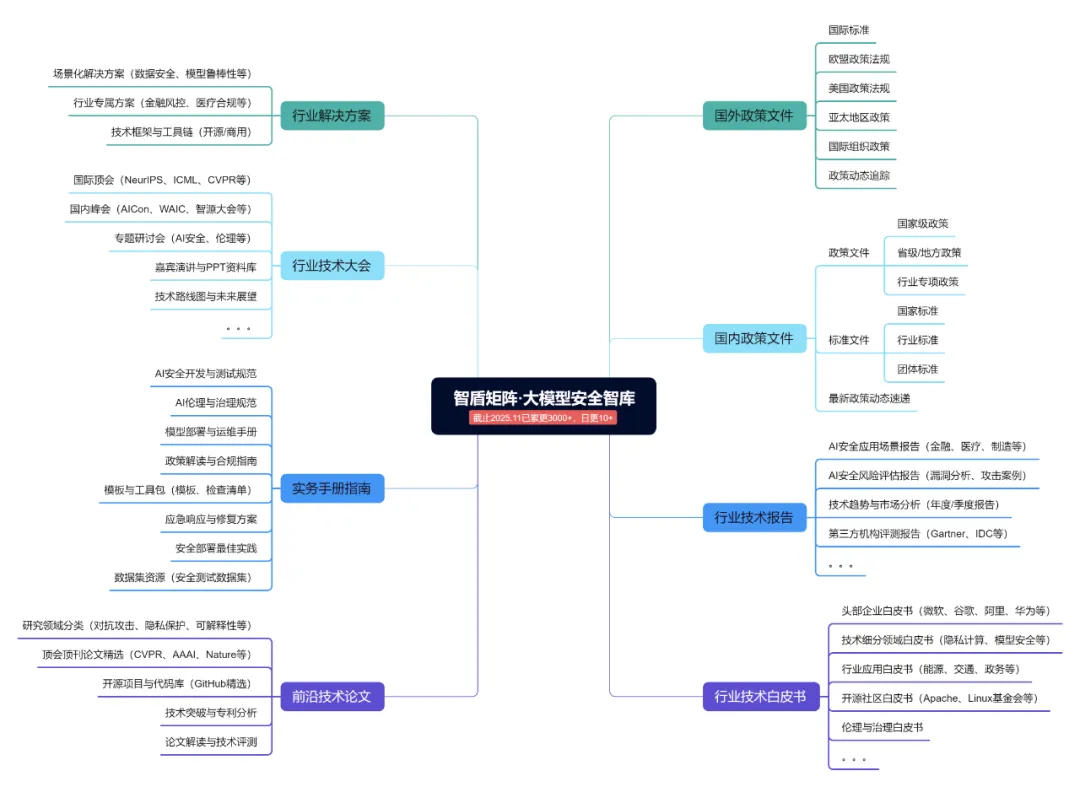
公众号已发表帮会资源展示:
①政策、标准
关于通用人工智能模型提供者义务范围澄清指南的制定开展针对性咨询
工业和信息化领域人工智能安全治理标准体系建设指南(2025版)
②行业解决方案
③行业技术报告
人工智能安全研究报告——技术视角下的安全风险梳理与应对(2025)
AI时代Agent原生企业崛起-现状、趋势与风险控制(2025版)
智能物联网(AIoT)安全技术与应用研究报告(2025年版)
④行业技术白皮书
⑤行业技术论文
⑥实务手册指南
OpenClaw(龙虾)专项安全风险预警以及建议防护方案-奇安信
MCP协议标准化研究工作沙龙—— 大模型与智能应用的信息交互主题精彩回顾
AI重构全球数字基建:美的多云统一数字化底座与出海的安全合规建设
LLM&Agent安全防护实战:业务落地视角下的风险管控与解决方案
智体赋能:基于大模型Agent的自动化渗透测试框架设计与实践
攻防加速:大模型赋能 VxWorks 漏洞分析与验证效能革新
大小模型协同驱动安全升级-基于大小模型协同的数字内容风控实践
面向未来的DevSecOps:Kodem如何用AI重塑应用安全
大模型驱动下的稳定与安全双螺旋——从“事后救火”到“主动免疫”的技术进化
AI 红队智能进化大模型与智能体驱动的自动化渗透测试及安全验证

 戳底部“阅读原文”或扫描上面交流群群主二维码扫码加入获取文档,打广告者勿扰。
戳底部“阅读原文”或扫描上面交流群群主二维码扫码加入获取文档,打广告者勿扰。
点分享

点收藏

点在看

点点赞