超节点行业深度解析报告
1. 行业定义与技术架构
1.1 超节点定义
超节点(SuperNode)是大模型训练时代的新型计算基础设施,指由多台计算设备(GPU/TPU/XPU)组成的集群单元,通过高带宽互联技术在物理上形成一个“虚拟单机”,实现:Scale-up互联:节点内部互联,实现芯片间高速数据传输Scale-out互联:跨节点互联,实现多超节点间协同计算统一内存池:所有芯片共享内存空间,避免数据搬运开销 核心价值:超节点将分布式计算从“网络层面”下沉到“物理层面”,大幅降低通信延迟,提升大模型训练效率。传统分布式集群的通信延迟约为100-500μs,超节点内部通信延迟仅1-5μs,效率提升100倍以上。 从技术架构角度看,超节点与传统服务器集群的本质区别在于:传统集群通过以太网或InfiniBand在机柜间进行数据交换,通信延迟高、带宽受限;而超节点通过专用互联协议(如NVLink、UB、ICI)在芯片间建立直连通道,实现接近内存访问级别的通信效率。这种架构变革使得大模型训练过程中频繁的参数同步、梯度更新等操作不再受网络瓶颈制约,训练效率显著提升。1.2 技术架构演进
从表格数据可以清晰看到超节点技术的迭代路径:第一代产品以单机柜为边界,最多支持8颗GPU互联,带宽约900GB/s;第二代突破物理机柜限制,通过NVLink 5.0实现72-144颗GPU的跨柜互联,带宽跃升至1.8TB/s;第三代将引入全光交换技术,带宽进一步提升至3TB/s以上,同时液冷散热成为标配方案。值得关注的是,每一代产品的互联带宽增长幅度均超过100%,这直接反映了大模型训练对数据传输效率的迫切需求。 技术演进驱动力: 1. 大模型参数量爆发:从千亿参数→万亿参数,单次训练数据传输量增长10倍 2. 多模态训练需求:视频/图像数据带宽需求是文本的100倍以上 3. 推理成本革命:DeepSeek V4实现百万上下文推理,成本降低至传统方案的1/101.3 三种产品形态
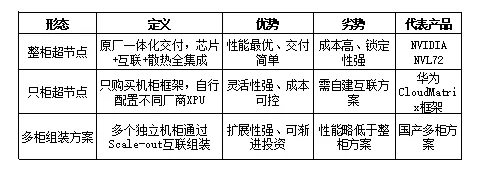
三种形态各有适用场景:整柜超节点适合追求极致性能、资金充足的大型企业,以NVIDIA NVL72为代表,一次性投入约300万美元即可获得72颗Blackwell GPU的完整算力平台;只柜超节点适合希望混合使用不同厂商芯片的客户,如华为CloudMatrix框架支持昇腾、天数智芯等多种国产XPU,灵活性更高;多柜组装方案适合预算有限、希望渐进投资的客户,可以先采购少量机柜验证效果,再逐步扩容,但跨柜互联性能略低于一体化方案。从市场趋势看,2026年只柜超节点占比最高(44%),反映出客户对灵活性和成本控制的双重需求。
2. 全球超节点产品对比分析
2.1 NVIDIA超节点路线
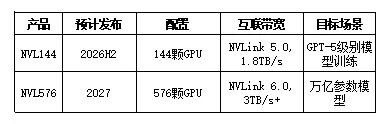
配置: - 72颗Blackwell GPU(B200/B300) - NVLink 5.0互联,带宽1.8TB/s双向 - 单柜功耗约120kW,液冷标配 - 定价约300万美元/柜技术特点: - 全连接拓扑:72颗GPU全互联,任意两点直接通信 - 统一内存池:1.4TB共享内存,所有GPU可见 - 支持FP4精度训练:相比FP16效率提升4倍 NVL72作为NVIDIA第二代超节点旗舰产品,其核心创新在于突破了传统单机柜8卡限制,通过NVLink 5.0协议实现72颗GPU的物理级全互联。这意味着任意两颗GPU之间的通信不再需要经过网络交换机,而是通过专用NVLink通道直连,延迟降至微秒级别。统一内存池设计进一步消除了数据搬运开销,所有GPU可以直接访问共享的1.4TB内存空间,这对于大模型训练中的参数同步至关重要。从商业化角度看,单柜定价300万美元虽成本较高,但考虑到72颗Blackwell GPU的总算力(约1.4PFLOPS FP4),单位算力成本仍优于传统分布式方案。 NVIDIA的产品路线图清晰展示了超节点规模的指数级扩张:NVL144将于2026年下半年发布,支持144颗GPU互联,主要面向GPT-5级别模型训练需求;NVL576计划2027年推出,通过NVLink 6.0协议实现576颗GPU互联,带宽预计超过3TB/s,目标支撑万亿参数模型训练。值得注意的是,NVL576的互联带宽将较NVL72提升约67%,这反映了更大规模模型对通信效率的更高要求。从产业链影响看,NVL576的推出将进一步推动高速背板、液冷散热等环节的技术升级。2.2 华为CloudMatrix路线
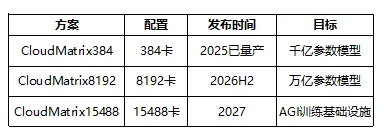
配置: - 384颗昇腾910B GPU - UB统一总线互联,带宽1.6TB/s - 单柜功耗约150kW,浸没式液冷 - 定价约200万人民币/柜(国产方案性价比优势)技术特点: - UB协议:华为自研Scale-up互联协议,兼容ETH-X - 淰度定制液冷:浸没式液冷方案,散热效率提升30% - DeepSeek V4首发适配:国产大模型核心算力平台 CloudMatrix384是华为针对国产大模型训练需求推出的超节点方案,其核心差异化在于UB统一总线协议。UB协议是华为自研的Scale-up互联技术,带宽达1.6TB/s,虽然略低于NVLink 5.0的1.8TB/s,但其兼容开源ETH-X协议,这意味着客户可以混合使用昇腾、天数智芯等多种国产XPU,灵活性显著优于NVIDIA的封闭生态。浸没式液冷方案是CloudMatrix的另一亮点,相比冷板式液冷散热效率提升30%,更适合高密度算力场景。从定价角度看,单柜200万人民币约合28万美元,仅为NVL72定价的约9%,性价比优势明显,这也是国产方案的核心竞争力。 华为的CloudMatrix扩展路线展示了国产超节点的快速追赶态势:CloudMatrix384已于2025年量产,主要服务千亿参数级别模型;CloudMatrix8192计划2026年下半年推出,支持8192卡互联,目标覆盖万亿参数模型训练;CloudMatrix15488将在2027年推出,15488卡规模足以支撑AGI(通用人工智能)级别的训练需求。值得关注的是,CloudMatrix系列在卡数规模上远超NVIDIA方案(384卡 vs 72卡),这反映了国产方案在算力密度上的差异化策略,也意味着对液冷散热、电源系统等配套环节的更高要求。2.3 Google TPU Ironwood路线
配置: - 9216颗TPU v7芯片 - ICI互联协议 + OCS全光交换 - 单柜功耗约100kW,100%液冷 - 定价约250万美元/集群技术特点: - ICI互联:Google自研TPU专用互联协议 - OCS全光交换:光路交换替代电交换,延迟降低至0.1μs - Lumentum光器件:订单超4亿美元,OCS核心供应商 Google的Ironwood方案代表了超节点互联技术的另一种路径:OCS全光交换。传统电交换方案需要将光信号转换为电信号再转回光信号,转换过程产生延迟;OCS方案通过光路直接切换,延迟降至0.1μs级别,比电交换方案快10倍以上。Lumentum作为OCS光器件核心供应商,已获得超4亿美元订单,反映出Google对全光交换技术的大规模投入。ICI互联协议是Google为TPU专门设计的Scale-up协议,与NVLink、UB形成三大主流协议阵营。值得关注的是,Ironwood方案支持9216颗TPU互联,卡数规模远超NVIDIA和华为方案,这得益于Google内部大规模AI训练需求(Gemini、AlphaGo等)。2.4 产品对比汇总表
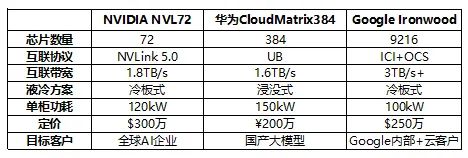
三大厂商的超节点方案各有侧重:NVIDIA NVL72以72颗GPU和1.8TB/s带宽为特点,定价300万美元适合全球AI企业;华为CloudMatrix384以384卡规模和浸没式液冷为亮点,定价200万人民币性价比优势明显,主要服务国产大模型;Google Ironwood以9216卡和OCS全光交换为特色,带宽超过3TB/s,主要用于Google内部训练和云客户服务。从液冷方案看,华为采用浸没式液冷散热效率最高,但成本也最高;NVIDIA和Google采用冷板式方案平衡成本与效率。从互联技术看,Google的OCS方案延迟最低(0.1μs),代表了未来方向;NVIDIA的NVLink带宽最高;华为的UB兼容ETH-X灵活性最优。3. 市场规模与增长预测
3.1 全球市场规模
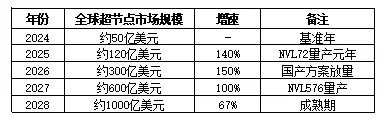
全球超节点市场呈现爆发式增长态势:从2024年的50亿美元基准规模,到2028年预计突破1000亿美元,五年复合增长率高达194%。增长曲线的峰值出现在2025-2026年,增速分别达到140%和150%,这与NVL72量产、国产方案放量等关键节点密切相关。值得关注的是,2027年增速回落至100%,2028年进一步降至67%,这反映了市场从高速扩张期向成熟期过渡的趋势。从绝对规模看,2028年1000亿美元的市场体量足以支撑数十家头部供应商的持续发展,超节点已成为AI基础设施领域最重要的增量赛道。3.2 中国市场规模
增长驱动因素: 1. 国产大模型爆发:DeepSeek V4、ChatGLM4等引领需求 2. 算力自主可控:昇腾、天数智芯等国产芯片放量 3. 政策支持:AI基础设施投资纳入国家战略 中国市场在全球超节点市场中占据约30%份额,2028年规模预计达3414亿元人民币,约合480亿美元。这一体量仅次于北美市场,反映了国内大模型训练的强劲需求。从增长驱动看,国产大模型(DeepSeek V4、ChatGLM4等)的爆发式发展是核心动力,这些模型需要大量算力支撑训练和推理;算力自主可控战略推动昇腾、天数智芯等国产芯片放量,带动国产超节点方案需求;政策层面将AI基础设施纳入国家战略,各地算力中心建设加速推进。值得关注的是,中国市场的增速(194% CAGR)高于全球平均水平,这意味着国产方案在全球市场份额将持续提升。3.3 市场结构分析
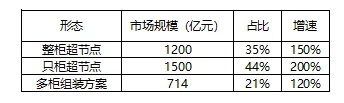
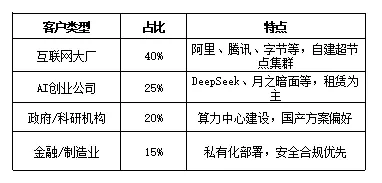
产品形态分布揭示了客户偏好的演变趋势:只柜超节点占比最高(44%,1500亿元),反映出客户对灵活性和成本控制的重视;整柜超节点占比35%(1200亿元),主要来自资金充足、追求极致性能的大型企业;多柜组装方案占比21%(714亿元),适合预算有限、希望渐进投资的客户。从增速看,只柜超节点增速最高(200%),这与国产方案放量、客户多样化需求密切相关;整柜超节点增速150%,主要受NVL72等海外高端产品驱动;多柜组装方案增速相对较低(120%),但作为入门级方案仍有稳定需求。 客户结构呈现多元化特征:互联网大厂占比最高(40%),阿里、腾讯、字节等头部企业倾向于自建超节点集群,以满足内部大模型训练需求;AI创业公司占比25%,DeepSeek、月之暗面等新兴力量主要采用租赁模式,降低前期资本开支;政府/科研机构占比20%,各地算力中心建设推动国产方案需求,偏好昇腾等自主可控产品;金融/制造业占比15%,私有化部署需求突出,安全合规是首要考量。从趋势看,AI创业公司占比有望持续提升,随着大模型应用场景扩展,更多传统行业客户也将加入超节点采购行列。4. 产业链深度拆解
超节点产业链可分为六大环节,每个环节价值量差异显著:4.1 产业链全景图
上游材料层 → 中游器件层 → 下游集成层 → 最终客户芯片 → Scale-up互联 → 液冷散热 → 高速背板/PCB → 光模块/光互联 → 电源系统 → 超节点整机 超节点产业链呈现典型的金字塔结构:上游芯片层技术门槛最高、价值量最大,由NVIDIA、华为、Google等少数头部厂商垄断;中游器件层(Scale-up互联、液冷散热、光模块等)技术门槛中等,是国产替代的重点突破领域;下游集成层(服务器整机、电源系统等)门槛相对较低,竞争较为激烈。从增量角度看,传统服务器产业链不存在Scale-up互联环节,液冷散热渗透率从<5%跃升至100%,光模块速率从400G跃升至1.6T以上,这些变化带来了显著的产业链重构机会。4.2 各环节价值量分析
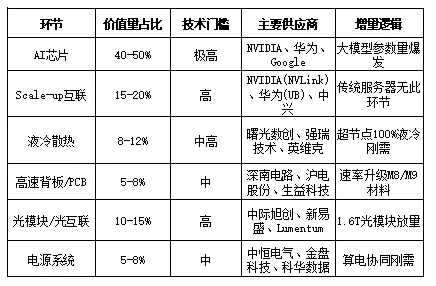
价值量分布揭示了产业链的核心盈利环节:AI芯片占比最高(40-50%),这是超节点最核心的算力来源,NVIDIA、华为、Google形成三大寡头格局;Scale-up互联占比15-20%,这是传统服务器产业链不存在的新增环节,NVLink、UB、ETH-X三大协议竞争激烈;光模块/光互联占比10-15%,1.6T光模块放量带来显著增量;液冷散热占比8-12%,渗透率从<5%跃升至100%是最核心的增量逻辑;高速背板/PCB和电源系统各占5-8%,虽然占比不高但技术升级要求明确。 从投资角度看,AI芯片环节盈利能力最强但竞争格局固化,国产厂商难以短期突破;Scale-up互联和液冷散热环节是国产替代的重点突破口,强瑞技术、中兴通讯等公司已取得显著进展;光模块环节中际旭创、新易盛已进入全球供应链,确定性较高。5. 关键增量环节分析
5.1 Scale-up互联:全新增量市场
传统服务器不存在Scale-up互联环节,超节点引入后成为全新增量市场。该环节价值量约15-20%,是超节点最核心的技术壁垒。 Scale-up互联的技术本质是在芯片间建立直连高速通道,替代传统网络交换方式。传统服务器集群通过以太网或InfiniBand进行机柜间通信,延迟约100-500μs,带宽受限;超节点通过NVLink、UB等专用协议在芯片间建立点对点连接,延迟降至1-5μs,带宽提升10倍以上。这种技术变革的核心价值在于:大模型训练过程中,参数同步、梯度更新等操作需要频繁的芯片间数据交换,传统网络方式延迟过高导致训练效率低下;Scale-up互联将通信延迟降至接近内存访问级别,训练效率显著提升。 从技术实现看,Scale-up互联需要三类核心组件:互联芯片(NVLink Switch、UB Switch等)、互联线缆/连接器(高速背板连接器、专用电缆等)、互联协议(NVLink、UB、ETH-X等)。互联芯片是价值量最大的部分,单价约5000美元,技术门槛最高;互联线缆单价约200美元/套,虽然单价较低但数量庞大(NVL72需144套);互联协议决定了生态兼容性,NVLink封闭但性能最优,ETH-X开源但性能略低。三大互联协议各有定位:NVLink由NVIDIA开发,带宽最高(1.8TB/s),市场份额60%,继续主导全球市场;UB由华为开发,带宽1.6TB/s,兼容开源ETH-X协议,市场份额25%,主要服务国产超节点;ETH-X由以太网技术联盟推动,开源协议支持多厂商芯片互联,市场份额15%,潜力巨大但商业化进展较慢。从趋势看,NVLink市场份额短期内难以撼动,但UB份额有望随国产超节点放量持续提升;ETH-X作为开源协议,长期可能成为国产替代的重要技术路径。NVIDIA NVLink Switch芯片:单价约$5000,NVL72需36颗,价值$18万 .华为UB Switch芯片:单价约¥3000,CloudMatrix384需48颗,价值¥14.4万 .中兴51.2T交换芯片:2026年送测阿里/昆仑芯,对标盛科通信. 互联芯片是Scale-up环节最核心的技术壁垒,NVIDIA的NVLink Switch芯片单价约5000美元,NVL72需36颗总价值约18万美元;华为UB Switch芯片单价约3000元人民币,CloudMatrix384需48颗总价值约14.4万元。中兴通讯开发的51.2T交换芯片正在送测阿里、昆仑芯等客户,对标盛科通信的千亿市值空间。值得关注的是,互联芯片的技术门槛极高,涉及高速信号处理、协议栈设计等核心能力,目前全球仅有少数厂商具备量产能力。高速背板连接器:单价约$200/套,NVL72需144套,价值$2.88万 互联线缆虽然单价较低(约200美元/套),但数量庞大(NVL72需144套),总价值约2.88万美元。兆龙互连作为NVLink专用电缆供应商,2025年收入同比增长210%,毛利率50%+,反映出该环节的高盈利特征。高速背板连接器需要支持1.6T+传输速率,技术门槛中等但认证周期长,已通过NVIDIA认证的供应商具有先发优势。5.2 液冷散热:从可选到必选
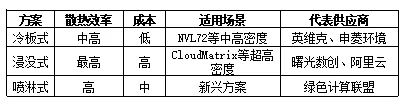
超节点单柜功耗120-150kW,传统风冷无法满足,液冷成为必选方案。液冷渗透率从传统服务器<5%跃升至超节点100%,市场规模爆发式增长。 液冷散热的技术原理是通过液体介质(通常是水或专用冷却液)直接或间接接触芯片表面,将热量高效带走。传统风冷方案通过空气对流散热,效率受限于空气热容和流速;液冷方案利用液体的高热容和强制对流,散热效率提升10倍以上。对于超节点而言,单柜功耗120-150kW意味着芯片功率密度超过传统服务器10倍,风冷方案完全无法满足散热需求,液冷成为必选方案。 从技术路线看,液冷主要分为三类:冷板式液冷将冷却液通过金属冷板间接接触芯片,散热效率中等但成本较低,适合NVL72等中高密度场景;浸没式液冷将整个服务器浸泡在专用冷却液中,散热效率最高但成本较高,适合CloudMatrix等超高密度场景;喷淋式液冷通过喷嘴将冷却液直接喷射到芯片表面,介于冷板式和浸没式之间,是新兴方案。 液冷技术路线的选择取决于算力密度和成本预算:冷板式方案散热效率中等、成本较低,适合NVL72等单柜功耗120kW的中高密度场景,英维克、申菱环境是主要供应商;浸没式方案散热效率最高、成本较高,适合CloudMatrix等单柜功耗150kW的超高密度场景,曙光数创、阿里云是主要供应商;喷淋式方案是新兴技术路线,介于冷板式和浸没式之间,绿色计算联盟正在推动标准化。从趋势看,浸没式液冷占比有望从2026年的20%提升至2028年的40%,反映出算力密度的持续提升。 inner-manifold(最强增量): - 定义:液冷分液歧管,超节点液冷核心组件 - 市场规模:2027年全球180亿元 - 强瑞技术:已获北美技术认证,毛利率50%+,净利率30%+,目标20亿元份额 - 工业/AVC:下游集成厂商,单价4000-5000元/套 inner-manifold(液冷分液歧管)是超节点液冷系统的核心组件,负责将冷却液均匀分配到各个芯片冷板。该组件市场规模预计2027年全球达180亿元,是液冷环节最强的增量点。强瑞技术已获得北美技术认证,毛利率50%+、净利率30%+,目标获取20亿元市场份额。工业富联和AVC是下游集成厂商,单价约4000-5000元/套。值得关注的是,inner-manifold的技术门槛在于精密流道设计和材料选择,需要保证冷却液均匀分配且不泄漏,认证周期长达6-12个月,已通过认证的供应商具有显著先发优势。 CDU(冷量分配单元)是液冷系统的热交换核心,负责将芯片热量传递到外部冷却循环。强瑞技术已批量供货国内几百台CDU;曙光数创作为冷板液冷龙头,2026年Q1收入同比增长783%,客户包括字节、阿里、腾讯、百度等头部互联网企业。CDU的价值量约占液冷系统总成本的30%,技术门槛中等但认证要求严格,需要与整机厂商深度配合。 中国液冷市场呈现爆发式增长态势:从2024年的50亿元基准规模,到2028年预计突破1200亿元,四年复合增长率高达175%。增速峰值出现在2025年(200%),这与NVL72量产、国产超节点元年密切相关;2026-2027年增速维持高位(167%、100%),浸没式液冷占比提升是核心驱动;2028年增速回落至50%,市场进入成熟期。从绝对规模看,2028年1200亿元的液冷市场足以支撑数十家头部供应商的持续发展,液冷已成为超节点产业链最重要的增量环节之一。5.3 光模块/光互联:速率革命
超节点内部光互连需求爆发,光模块速率从800G→1.6T→3.2T快速迭代。 光模块的技术原理是将电信号转换为光信号进行传输,再在接收端将光信号转换为电信号。传统服务器使用400G光模块满足机柜间通信需求;超节点内部通信带宽需求提升10倍以上,800G、1.6T、3.2T光模块成为主流。光模块的核心组件包括光发射模块(激光器)、光接收模块(探测器)、调制电路等,其中激光器芯片(VCSEL、EML等)是技术瓶颈。 从技术演进看,光模块速率迭代遵循摩尔定律:800G光模块2024年成为主流,1.6T光模块2026年放量,3.2T光模块2027年试产。速率提升的核心驱动力是超节点内部通信带宽需求,NVLink 5.0带宽1.8TB/s意味着每颗GPU需要约25GB/s的双向通信能力,这远超传统光模块的承载能力。NPO(近封装光学)和CPO(共封装光学)技术将光引擎与芯片物理距离缩短,进一步降低功耗和延迟,是光模块技术的未来方向。 光模块需求呈现指数级增长态势:800G光模块从2025年的1000万只跃升至2027年的10000万只以上,三年增长10倍;1.6T光模块从2025年的100万只跃升至2027年的2000万只,三年增长20倍。这种爆发式增长的核心驱动力是超节点内部光互连需求,每台NVL72约需144只光模块,每台CloudMatrix384约需384只光模块,超节点量产直接拉动光模块需求。从价值量看,800G光模块单价约500美元,1.6T光模块单价约1000美元,光模块总市场规模2027年有望突破150亿美元。 光芯片技术路径呈现清晰的演进趋势:VCSEL(垂直腔面发射激光器)由于功率限制,已退出1.6T市场,主要用于800G及以下速率;EML(电吸收调制激光器)是当前主流方案,采用磷化铟衬底,支持1.6T速率;硅光方案将硅基光路与外挂磷化铟光源结合,是未来方向,有望降低成本并提升集成度。从趋势看,硅光方案2027年后可能逐步替代EML方案,但磷化铟材料仍不可或缺,这构成了磷化铟的长期需求支撑。2030年预测:GaAs 9%、InP 91% 磷化铟CAGR:85% 中国出口管制:2025年2月磷化铟列入管制范围,海外短缺 磷化铟材料构成光芯片产业链的关键瓶颈:2025年磷化铟衬底占比79%,2030年预计提升至91%,复合增长率高达85%。中国于2025年2月将磷化铟列入出口管制范围,海外市场面临短缺,这为国内磷化铟供应商(云南锗业等)带来量价齐升机会。从价值量看,磷化铟衬底单价约1000美元/片,全球市场规模2027年有望突破50亿美元,材料瓶颈将持续支撑高盈利。Google OCS方案:光路交换替代电交换,延迟降至0.1μs OCS(全光交换)技术通过光路直接切换替代电交换,延迟降至0.1μs级别,比传统电交换快10倍以上。Google的Ironwood方案采用OCS技术,Lumentum作为OCS光器件核心供应商已获得超4亿美元订单。工信部正在推动全光交换技术应用政策支持,国内厂商有望受益。从趋势看,OCS技术代表了超节点互联的未来方向,2027年后可能逐步成为主流,相关光器件供应商具有长期价值。5.4 高速背板/PCB:材料升级
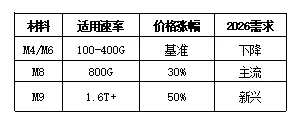
超节点内部高速背板需要支持1.6T+传输速率,PCB材料从M4→M6→M8→M9快速升级。 高速背板的技术本质是在PCB(印制电路板)上实现高速信号传输。传统服务器背板传输速率约100-400G,使用M4/M6级别材料;超节点背板传输速率达1.6T以上,需要M8/M9级别高端材料。PCB材料的核心指标是介电常数(Dk)和损耗因子(Df),数值越低信号传输损耗越小。M4材料Dk约4.5、Df约0.02;M8材料Dk约3.8、Df约0.01;M9材料Dk约3.5、Df约0.005,性能逐级提升。 从技术演进看,PCB材料升级的核心驱动力是信号速率要求:400G速率可使用M4/M6材料;800G速率需要M8材料;1.6T+速率需要M9材料。日本三菱瓦斯等海外厂商垄断M8/M9材料供应,2026年涨价30%,国内厂商(生益科技等)正在加速国产替代。从价值量看,M8材料价格较M4材料高30%,M9材料价格较M4材料高50%,材料升级直接拉动PCB环节价值量。 PCB材料升级趋势清晰反映技术迭代:M4/M6材料适用于100-400G速率,价格基准但需求下降;M8材料适用于800G速率,价格较基准高30%,2026年成为主流;M9材料适用于1.6T+速率,价格较基准高50%,是新兴需求。从市场趋势看,M8材料2026年占比约60%,M9材料占比约15%,随着1.6T光模块放量,M9占比有望持续提升。日本三菱瓦斯等海外厂商垄断M8/M9材料供应,涨价趋势明显,国内厂商(生益科技等)国产替代机会突出。5.5 电源系统:算电协同
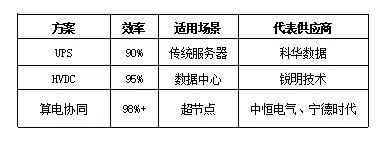
超节点单柜功耗120-150kW,电源系统从UPS→HVDC→算电协同演进。 电源系统的技术本质是将电网电能转换为服务器所需的稳定直流电。传统服务器使用UPS(不间断电源)方案,效率约90%;数据中心逐步采用HVDC(高压直流)方案,效率约95%;超节点引入算电协同方案,效率提升至98%以上。算电协同的核心原理是将电池储能系统与服务器负载深度结合,根据算力负载实时调整供电策略,既提升效率又降低峰值成本。 从技术演进看,电源系统的核心挑战是超节点的高功耗需求:单柜功耗120-150kW意味着每台超节点需要约150kW的稳定供电能力,传统UPS方案效率低、峰值应对能力差;HVDC方案效率提升但仍有损耗;算电协同方案通过电池储能平滑峰值负载,效率达98%以上。宁德时代41亿入股中恒电气,核心逻辑就是电池企业切入算力电源赛道,实现算电协同的商业化落地。 电源方案呈现清晰的技术迭代路径:UPS方案效率约90%,适用于传统服务器,科华数据是主要供应商;HVDC方案效率约95%,适用于数据中心,锐明技术是主要供应商;算电协同方案效率达98%以上,适用于超节点,中恒电气和宁德时代是主要推动者。从趋势看,算电协同方案2026年后有望逐步成为超节点标配,效率优势突出,宁德时代入股中恒电气标志着电池与算力电源的深度融合。 宁德时代41亿入股中恒电气是算电协同赛道最核心的商业化案例:战略逻辑是电池企业通过入股进入算力电源领域,实现电池储能与服务器负载的深度协同。金盘科技获得近亿美元AIDC订单,主要服务美国数据中心自建电源需求;锐明技术HVDC产品批量交付,服务算力中心配套数字能源业务。从趋势看,算电协同方案2026年后有望逐步成为超节点标配,电池企业与电源企业的合作将持续深化。6. 景气度分析与投资展望
6.1 2026年景气度核心驱动
景气驱动: 1. NVIDIA NVL72量产交付:首批订单预计6月后放量 2. DeepSeek V4商业化:百万上下文推理需求爆发 3. 液冷产业大会催化:inner-manifold等技术认证通过 4. 磷化铟管制升级:海外短缺,国内量价齐升液冷散热(打分9):inner-manifold放量,强瑞技术业绩超预期光模块/光芯片(打分9):NPO/CPO量产,磷化铟材料瓶颈Scale-up互联(打分9):中兴51.2T送测,国产替代加速 Q2是超节点产业的关键催化窗口:NVL72量产交付标志着超节点进入商业化阶段,首批订单预计6月后放量;DeepSeek V4商业化推动国产大模型算力需求爆发;液冷产业大会催化inner-manifold等技术认证通过;磷化铟管制升级导致海外短缺,国内量价齐升。从板块景气度看,液冷散热、光模块/光芯片、Scale-up互联三大环节打分均为9(满分),反映出Q2的高景气确定性。景气驱动:1. NVL144发布:GPT-5级别模型训练需求 2. CloudMatrix8192量产:国产大模型算力基础设施 3. Google Ironwood量产:OCS全光交换放量 4. Intel CPU推理方案:成本革命,重新定义AI算力格局 AI芯片/服务器(打分9):Intel超预期,浪潮/华勤业绩兑现 Q3是超节点产业的产品升级窗口:NVL144发布支撑GPT-5级别模型训练需求;CloudMatrix8192量产推动国产大模型算力基础设施;Google Ironwood量产带动OCS全光交换放量;Intel CPU推理方案实现成本革命,重新定义AI算力格局。从板块景气度看,AI芯片/服务器、光模块打分均为9,电源系统打分8,反映出Q3的持续高景气。景气驱动: 1. NVL576试产:万亿参数模型预演 2. CPO量产:ASMPT TCB设备订单爆发 3. 浸没式液冷渗透率提升:从20%→40% 4. AI视频模型商业化:HappyHorse等驱动算力需求 Q4是超节点产业的技术升级窗口:NVL576试产支撑万亿参数模型训练预演;CPO量产带动ASMPT TCB设备订单爆发;浸没式液冷渗透率从20%提升至40%;AI视频模型商业化驱动算力需求。从板块景气度看,高速背板/PCB打分8,CPO/NPO、浸没式液冷打分均为9,反映出Q4的技术迭代景气。参考 资料
资料华泰证券液冷产业深度研报,2026年4月28日
光芯片磷化铟瓶颈,中信建投光通信行业专题研报
天风证券光模块行业研报,2026年4月20日
国信证券数据中心交换机研报,2026年4月9日
中金公司光器件行业研报,2026年4月9日
Google Cloud Next纪要,2026年4月24日
高盛半导体行业研报,2026年4月26日
安信证券液冷数据中心研报,2026年4月26日