


1、为什么 AI 越智能,反而越“危险”?
如今 AI 已经遍地开花:图像识别、语音控制、智能推荐……华为甚至预测,到 2025 年全球会有 1000 亿设备联接,85% 的企业应用跑在云上。
但问题也随之而来:
AI 算法在设计之初,大多没把“安全攻击”算进去;
加上深度学习本身像个“黑盒”,一旦被盯上,后门和偏见很难被发现。
结果就是:AI 系统正面临实实在在的安全风险,尤其在医疗、交通、工业等关键领域,一次误判可能直接威胁人身安全或造成重大损失。
二、AI 安全的五大“死穴”
白皮书把 AI 风险归纳为五个核心挑战:
软硬件安全:模型、芯片、平台都可能藏漏洞或后门,且因“不可解释”,后门极难检测。
数据完整性:训练时掺“恶意数据”,或推理时加“微小噪音”,都能让 AI 跑偏。
模型保密性:仅开放查询接口,但攻击者可通过多次查询,反推出模型参数(偷走核心知识产权)。
模型鲁棒性:训练样本覆盖不足,遇到恶意样本直接“不会判”。
数据隐私:通过反复查询,有可能反推并窃取用户训练数据里的隐私信息。
一句话:AI 越开放、越通用,被攻击的“口子”就越大。
三、四大典型攻击:AI 是怎么被“骗、毒、埋、偷”的?
1)闪避攻击(骗 AI“看错”)
在输入里加人眼不可见的微小扰动,生成“对抗样本”。
案例:路牌上涂几个小标记,“禁止通行”被识别成“限速45”,自动驾驶可能直接误判。
特点:跨模型通用,黑盒也能攻,防不胜防。
2)药饵攻击(给 AI“喂毒”)
往训练数据里掺精心设计的恶意样本,污染数据分布。
案例:仅 8% 的恶意数据,就能让 50% 的患者用药建议偏差超 75%。
场景:医疗用药、金融放贷/房价评估、风控等。
3)后门攻击(模型里埋“地雷”)
在模型训练/传输阶段植入隐蔽触发条件。
正常输入完全正常,一旦输入含“特定图案/关键词”,模型就“叛变”。
极度隐蔽,没有源代码也难解读,几乎查不出来。
4)模型窃取攻击(偷走你的 AI)
反复调用 AI 接口(AIaaS),根据输入输出反推模型结构和参数。
不仅偷走知识产权,还能用偷来的模型制造更精准的对抗样本,辅助黑盒攻击。
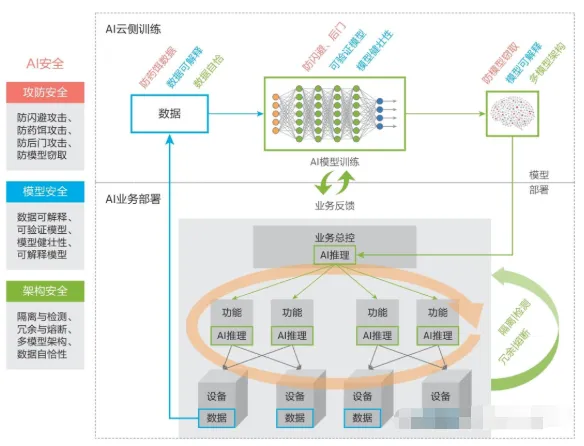
四、华为三层防御体系:从“被动挨打”到“纵深防守”
白皮书最核心的落地价值,就是这套 “攻防安全 + 模型安全 + 架构安全” 三层防御框架:
第一层:攻防安全(针对已知攻击的针对性防御)
在数据收集、模型训练、模型使用三个阶段,分别部署防御:
防闪避攻击:对抗样本生成(提前模拟)→ 对抗训练/网络蒸馏 → 对抗样本检测、输入重构
防药饵攻击:回归分析(异常值检测)→ 训练数据过滤 → 集成分析
防后门攻击:→ 模型剪枝(去除后门神经元)→ 输入预处理(过滤触发输入)
防模型窃取:差分隐私/模型水印 → 隐私聚合教师模型(PATE)
第二层:模型安全(让 AI 自身更“稳、透明、可信”)
核心思路是做到三件事:可检测、可验证、可解释。
可检测:输入前加“前馈检测模块”,输出后加“后馈检测模块”,过滤恶意样本。
可验证:用求解器约束“输入空间-输出空间”的对应关系(例如:验证在某扰动范围内不会产生对抗样本),但效率仍需优化(DNN 验证属 NP 完全问题)。
可解释(非常关键):
建模前:分析训练数据特征,筛选有意义特征;
构建:用可解释性更强的传统机器学习(统计类),平衡效果与可解释性;
解释分析:用 LIME 等通用方法,或针对模型结构的专用方法,理清输入-输出-中间信息的依赖关系。
实际意义:满足 GDPR“反算法歧视”要求,排除种族、性别等敏感因素影响,消除数据偏见(比如 HR 招聘数据偏见导致的性别失衡)。
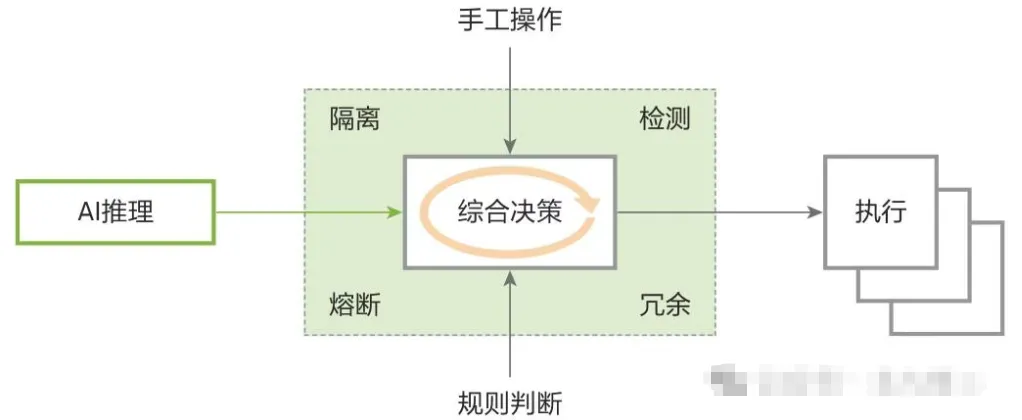
第三层:架构安全(结合业务场景做“安全设计”)
针对 AI 部署的业务特性,通过四类机制设计安全架构,关键案例包括自动驾驶和医疗 AI:
隔离:AI 推理模块、综合决策模块功能隔离,设置访问控制,减少攻击面。
检测:持续监控与攻击检测模型,实时分析威胁;高风险时交回人工控制。
熔断:关键操作(如自动驾驶刹车、医疗用药建议)设置“确定性阈值”,低于阈值时回退到规则判断或人工处理。
冗余:搭建“多模型架构”,单个模型错误不影响最终决策,降低单一攻击的全面危害。
五、一句话总结
AI 的爆发不可逆,但“聪明”并不等于“安全”。
华为这份白皮书的核心结论可以概括为:
AI 安全不是单点防攻击,而是“攻防针对性防御 + 模型可解释可验证 + 业务级隔离熔断冗余”的纵深体系;唯有让 AI 从黑盒走向可解释、从裸奔走向架构级防护,才能真正在关键领域用得放心。