


1. 引言
在通用容错量子计算(Fault-Tolerant Quantum Computing, FTQC)的发展进程中,物理平台的选择直接决定了系统扩展的工程可行性。过去十余年间,超导量子电路与捕获离子技术在含噪声中等规模量子(NISQ)时代占据主导地位。然而,随着量子比特数量向成百上千规模迈进,传统固态量子芯片面临串扰、布线复杂性及制造公差等根本性物理限制,而离子阱技术则受制于同性电荷排斥导致的单阱扩展瓶颈。
在此背景下,基于光镊阵列(Optical Tweezer Arrays)的中性原子(Neutral Atom)量子计算平台呈现出显著的后发优势。该技术利用激光冷却与捕获不带电荷的原子,结合里德堡态(Rydberg state)的强相互作用实现量子逻辑门。中性原子架构凭借其原子的绝对同质性、室温运行环境、动态可重构的拓扑连通性,以及与新型量子纠错码的底层适配性,已迅速从基础物理实验验证阶段跨入工业级系统构建与商业部署阶段。本报告将系统性地研究中性原子量子计算机的底层物理基础、技术演进脉络、横向架构对比、工程实现瓶颈,以及当前的全球商业化落地与未来发展路线图。
2. 物理基础与控制机制
中性原子量子计算机的底层运作依赖于原子物理学、量子光学以及精密激光控制技术的深度融合。其核心机制包括原子的捕获、状态编码以及通过里德堡阻塞效应实现的纠缠操作。
2.1 光学偶极阱与系统初始化
中性原子的捕获不依赖于电磁场对带电粒子的束缚,而是利用光学偶极阱原理。当失谐激光聚焦于空间极小区域时,光子动量的传递会产生空间变化的交流斯塔克频移(AC Stark shift),极化中性原子并将其限制在激光强度的最高点。研究人员利用空间光调制器(SLM)或声光偏转器(AOD)在真空中生成数百至数千个焦点的二维或三维光镊阵列。
在初始化阶段,系统通常从磁光阱(MOT)中捕获数百万个原子,随后将单个原子概率性地加载到静态光镊阵列中。由于加载具有概率性(通常约为50%),系统需要通过相机成像识别原子位置,并利用动态光镊实时重排原子,以生成无缺陷的计算阵列。这一过程完全在室温条件下的真空室中进行,仅被捕获的原子本身被激光冷却至微开尔文(K)级别,从而免除了超导平台所需的大型稀释制冷机(Dilution refrigerator),极大降低了系统的尺寸、重量和功耗(SWaP)。
2.2 量子态编码与退相干抑制
量子信息被编码在原子的内部能级中。根据所用原子种类的不同,编码方式主要分为两类:
第一类是碱金属原子(如铷-87、铯-133),这类原子通常利用其超精细基态(Hyperfine ground states)来定义逻辑 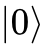 和 。由于这些基态具有极高的稳定性,铷和铯原子能够展现出长达数秒的相干时间。
和 。由于这些基态具有极高的稳定性,铷和铯原子能够展现出长达数秒的相干时间。
第二类是碱土金属或类碱土金属原子(如锶-88、镱-171),其外层具有两个价电子。这类原子允许将量子信息编码在极其稳定的核自旋态(Nuclear spin states)中。由于核自旋对外部电磁噪声具有极强的免疫力,且不存在自发辐射衰减,这类量子比特在理论上能够实现极长的记忆时间(数十秒量级),为执行复杂的纠错协议提供了充足的时间裕度。
2.3 里德堡阻塞与双量子比特逻辑门
单量子比特操作通过全局或局部寻址的微波或拉曼激光束实现,而双量子比特纠缠门则依赖于里德堡阻塞(Rydberg Blockade)机制。当原子被激发至主量子数  的高激发态(里德堡态)时,原子的电子轨道半径急剧扩大,诱发极强的范德华力或偶极-偶极相互作用。这种相互作用强度 与原子间距 呈反比(例如范德华力
的高激发态(里德堡态)时,原子的电子轨道半径急剧扩大,诱发极强的范德华力或偶极-偶极相互作用。这种相互作用强度 与原子间距 呈反比(例如范德华力 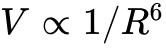 ),其强度比基态高出约十二个数量级。
),其强度比基态高出约十二个数量级。
在设定的里德堡阻塞半径(通常为几微米)内,如果控制量子比特已被激发至里德堡态,巨大的能级偏移会导致目标量子比特无法被相同频率的激光共振激发。利用这一排他性物理现象,系统可以施加条件逻辑脉冲(如在控制原子、目标原子和控制原子上依次施加激光脉冲),从而高保真度地执行控制非门(CZ Gate)或受控非门(CNOT Gate),这是构建通用量子电路的基础。
3. 技术演进与关键里程碑
中性原子量子计算的发展是从理论物理的初步探索向具有高度复杂度的系统工程迈进的历程。
二十世纪八十年代,理查德·费曼首次提出量子计算的理论构想。直到2000年,Jaksch 等人及 Saffman 等人在《物理评论快报》上发表了利用里德堡阻塞效应实现量子逻辑门的理论框架,为中性原子量子计算奠定了基础。2009年,Antoine Browaeys 团队在实验中首次观测并证实了两个单原子之间的里德堡阻塞效应。随后,基础研究加速转化为系统构建,Thierry Lahaye 和 Browaeys 团队在2016年利用中性原子实现了包含30个量子比特的模拟系统,并于2018年将该架构扩展至三维,成功模拟了包含72个原子位点、49个量子比特的复杂系统。
技术的商业化拐点发生在2022至2024年间。2022年,QuEra 公司基于哈佛大学与麻省理工学院的技术,在亚马逊 Braket 云平台上推出了拥有256个量子比特的“Aquila”模拟处理器,首次向公众开放了中性原子算力。2023年12月,由 Mikhail Lukin 领导的哈佛大学团队,联合 QuEra、MIT 及 NIST,在《自然》杂志上发表了一项具有历史意义的研究。该团队利用包含280个物理量子比特的区域化可重构中性原子阵列,成功编码了48个逻辑量子比特,并运行了包含数百个逻辑门操作的复杂算法,首次证明了逻辑量子比特在执行复杂算法时的性能超越了物理量子比特。
进入2024与2025年,阵列规模不断刷新记录。Atom Computing 宣布了其第二代系统,该系统构建了具有1225个位点的计算阵列,容纳了超过1180个量子比特,并展示了64个逻辑量子比特架构。与此同时,加州理工学院(Caltech)的 Manuel Endres 团队成功组装了包含6100个中性原子的超大物理阵列,这是迄今为止公开记录中最大的原子阵列。在中国,中国科学技术大学(USTC)的潘建伟与陆朝阳团队,通过结合人工智能模型优化光镊控制,实现了包含2024个无缺陷原子的二维与三维阵列的高速重排,将时间常数开销压缩至60毫秒,该成果入选美国物理学会(APS)年度重要进展。
4. 架构特性及跨技术路线基准测试
在当前的量子硬件生态中,超导电路、捕获离子和中性原子构成了主流技术路径。通过严谨的基准测试与架构对比,可以客观界定中性原子的技术站位与发展潜力。
4.1 主流技术路线基准测试对比
下表汇总了截至2024-2025年期间,三种主要量子计算模式在物理特性与关键性能指标上的核心数据。
架构维度 | 超导量子电路 (Superconducting) | 捕获离子 (Trapped Ion) | 中性原子 (Neutral Atom) |
代表企业及系统 | IBM (Heron 133/156), Google (Willow 105) | Quantinuum (H2), IonQ | QuEra (Aquila 256), Atom Computing (1180), Pasqal |
量子比特同质性 | 存在制造公差,频率参数各异 | 自然界中完全一致 | 自然界中完全一致,无物理制造缺陷 |
工作环境要求 | ~15 mK极低温,高度依赖稀释制冷机 | 室温或中等低温真空 | 室温外部环境,内部微开尔文级激光冷却 |
拓扑连通性 | 固定的局部二维近邻连接结构 | 全连接或局部全连接 (基于CCD架构) | 灵活可重构,基于物理穿梭实现动态全连接 |
单/双比特门保真度 | 单: 99.965%, 双: 99.67% (以Willow为例) | 单: 99.99%, 双: 99.94% (业界最高) | 单: 99.993%, 双: 99.73% (处于快速提升期) |
门操作周期/速度 | 极快 (数十纳秒至微秒量级) | 较慢 (微秒至毫秒量级) | 慢 (毫秒量级),但支持高维度的并行门操作 |
4.2 中性原子架构的系统级优势与妥协
相较于超导和离子阱路线,中性原子架构在系统工程上展现出显著优势,同时也存在固有的技术妥协。
首先是规模化路径的平滑性。超导量子比特面临严重的布线危机,随比特数增加,微波同轴电缆、控制电子设备的热载荷以及极低温制冷功率构成了极高的工程壁垒。而捕获离子受限于同一离子链中带电粒子间复杂的静电库仑力相互作用,难以在单阱中大幅扩展,通常需要依赖光子互连或复杂的量子电荷耦合器件(QCCD)架构拼接。中性原子不仅由于缺乏电荷而不会相互排斥,其通过自由空间光学系统(激光聚焦)进行控制的方式,也彻底避免了微波走线的物理拥挤问题。
其次是动态连通性与穿梭机制(Qubit Shuttling)。在固定架构(如超导)中,相距较远的量子比特若要产生纠缠,必须插入一系列交换操作(SWAP gates),这会导致极大的错误累积和电路深度增加。中性原子通过动态移动光镊焦点,可以使整个原子在空间中相向移动,执行纠缠门后再返回原位,从而实现全连接(All-to-all connectivity)。这种能力在硬件底层赋予了量子编译算法极大的优化空间。
然而,中性原子的主要妥协在于时间维度上的速度限制。超导逻辑门的执行周期在纳秒级别,而中性原子因激光脉冲整形、原子穿梭延迟等因素,门操作周期普遍在微秒乃至毫秒量级。因此,学术界常将其总结为:超导处理器易于在时间维度(电路深度)上扩展,而中性原子更易于在空间维度(比特数量)上扩展。
5. 迈向容错量子计算(FTQC)的核心技术解析
量子纠错(Quantum Error Correction, QEC)是衡量硬件平台是否具备向实用化迈进潜力的决定性指标。中性原子的物理特性,尤其是在转置门、低密度奇偶校验码的适配以及擦除转换方面,展现出了加速实现 FTQC 的理论与实践基础。
5.1 转置门与表面码架构的优化
传统超导架构在实现诸如表面码(Surface Code)等纠错协议时,底层物理量子比特的交互必须遵循严格的二维晶格拓扑。执行逻辑层面的双比特运算通常需要复杂的晶格手术(Lattice surgery)技术,消耗大量的物理空间与时间。
中性原子的穿梭能力允许采用区域化架构(Zoned Architecture)。该架构将计算阵列划分为存储区、相互作用区和读出区。在此架构下,系统能够通过移动整个逻辑比特的数据块(由多个物理原子组成)并使其重叠,通过单一的全局激光脉冲并行执行操作,实现“转置门(Transversal gates)”。转置门能够保证物理层面的错误不会在数据块内部发生级联扩散,从而极大地降低了错误纠正的时间与空间开销。
5.2 高效量子低密度奇偶校验码(qLDPC)的天然适配
近期理论计算机科学表明,量子低密度奇偶校验码(qLDPC)能够突破表面码编码效率低下的限制,实现远超 0.5 的高编码率(即物理比特数与逻辑比特数的比率)。然而,诸如 Bivariate Bicycle 码或 La-cross 码等 qLDPC 方案,在几何结构上要求中等距离的非局域相互作用。这在二维平面超导阵列上几乎无法实现。
中性原子的动态重构性完美满足了这一硬件映射需求。2024年,QuEra 与学术机构合作的模拟研究表明,基于中性原子系统设计的结构化 qLDPC 码能够实现高编码率的参数配置。这意味着仅需约 2300 个物理原子,即可编码超过 1100 个逻辑比特,并纠正最高 6 个错误,从而以极低的物理资源开销,将逻辑操作的每回合错误率推向 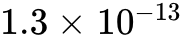 的 Teraquop(万亿次运算无错)实用化区间。
的 Teraquop(万亿次运算无错)实用化区间。
5.3 擦除转换(Erasure Conversion)重塑纠错阈值
量子计算中,未知的退极化错误(Depolarizing error)是破坏系统相干性的元凶。近期,普林斯顿大学的 Jeff Thompson 团队与加州理工学院等机构提出了一种重塑错误处理逻辑的方案——擦除转换。
该方案不采用碱金属铷原子,而是采用复杂的镱-171(Yb-171)原子。由于镱原子复杂的电子能级结构,研究人员不再利用最低的基态编码,而是将其逻辑状态编码在两个亚稳态中。物理原理在于,当双比特门操作发生激光相位噪声或散射等失误时,原子绝大概率会从亚稳态衰减至与计算子空间不相交的基态,而不是在 和 之间发生未知的随机翻转。
此时,系统利用状态选择性荧光成像技术(State-selective readout)对其进行持续监测。未衰减的原子保持相干状态,而衰减的原子则会被标记为“擦除错误(Erasure errors)”。在经典解码理论中,已知位置的错误(擦除)比未知位置的错误要容易处理得多。基于最小权完美匹配(MWPM)解码器的电路级模拟结果显示,应用擦除转换后,表面码的容错物理错误阈值从标准的 0.937% 飞跃性地提升至 4.15%。结合原位连续重载技术(K-shift erasure recovery),中性原子系统能够在不干扰邻近正在计算的比特的前提下,动态替换损失的原子,从而在硬件层面对抗长期运行中的原子损耗。
6. 面临的工程挑战与光学控制突破
中性原子硬件在向实用化扩展的过程中,正面临着从物理极限向工程系统转化的一系列技术挑战。
6.1 光学控制硬件的刷新率与串扰瓶颈
由于光镊阵列完全由外部激光雕刻而成,系统的规模受限于空间光调制技术。传统的空间光调制器(SLM)采用液晶材料调节相位以生成静态大阵列,但其刷新率存在严重瓶颈,最高只能达到几百赫兹(Hz),无法适应量子算法执行期间所需的高频次原子重排和动态路由。
声光偏转器(AOD)虽然通过射频频率控制可以实现微秒级的高速扫描与动态光镊生成,但在控制大规模原子阵列时,产生多频率信号引发的光学相干串扰(Crosstalk)以及衍射效率下降,会导致原子被加热并引起退相干。这造成了SLM规模大但速度慢、AOD速度快但易产生噪声的结构性困境。
6.2 前沿MEMS与PIC光子集成解决方案
为了突破上述光学限制,产业界正积极引入半导体制造级技术。例如,Infleqtion 公司与微机电系统(MEMS)供应商 Silicon Light Machines 达成战略合作,研发了位移相位调制器(DPM)技术。该技术利用硅锗(SiGe)材料,将高速活塞相位调制器直接集成到 CMOS 驱动电路上,实现了 250 kHz 的调制速率以及 4 微秒的全帧刷新周期。此外,光子集成电路(PICs)被大量部署以取代庞大的传统自由空间光学平台,将系统的体积、重量和功耗大幅降低,为实现桌面级乃至机架式可部署的中性原子量子计算机铺平了道路。
6.3 穿梭延迟与相干时间损耗的权衡
原子在阵列中的穿梭虽然赋予了全连接能力,但运动过程不可避免地占用毫秒级的传输时间,增加了退相干风险。针对这一瓶颈,研究人员提出将原子的宏观速度引入控制方程。通过利用受控的多普勒频移(Doppler shifts),激光系统可以仅与处于特定速度区间内移动的原子发生共振,从而允许在原子连续飞行时直接执行状态制备、测量及局部旋转操作,极大压缩了纠错周期的空闲时间。
7. 软件架构设计与混合计算系统集成
在中性原子平台上执行算法,对软件控制栈提出了超越传统微波门逻辑序列的需求。软件架构必须深度融合其独特的并发性及模拟操作特性。
7.1 双模编程范式:模拟域与数字域
中性原子架构支持在模拟模式(Analog mode)和数字模式(Digital mode)下进行操作。在模拟模式下,量子处理器不执行分立的逻辑门,而是通过连续改变系统的全局哈密顿量(如控制全局里德堡激光的幅度与相位),利用原子的多体物理相互作用求解组合优化、流体动力学等问题。
Pasqal 公司开发的开源 Python 库 Pulser 为这一控制提供了底层接口。Pulser 允许开发者从脉冲级别(Pulse-level)精细控制激光序列的几何参数和持续时间,且兼顾数字和模拟处理的编译。为降低应用开发门槛,其推出的无代码环境 Pulser Studio 实现了直观的阵列布局建模与光镊脉冲配置。
7.2 面向并行化与动态连通性的高级中间表示
针对数字容错时代的门操作模式,原有的模拟 SDK 无法有效控制原子穿梭与区域划分。QuEra 在其基于亚马逊云 Braket 平台的模拟库之上,演进出了 Bloqade Circuit 和 Bloqade Shuttle 软件栈。
其核心在于引入了新的中间表示层(Intermediate Representation)SQuIN。不同于传统量子汇编语言(如 QASM),SQuIN 允许将量子指令与经典的结构化控制流(如 For 循环、If 语句和闭包)深度混合。这一设计深刻契合了中性原子特有的并行化特性,使得系统可以通过一次全局激光照射,向阵列中数百个不同区域的原子并行广播逻辑门操作,从而优化了执行开销。
8. 全球产业应用与商业化部署案例
中性原子技术的长相干时间与强并行能力,使其在工业应用与超算中心集成方面具备了先发优势,相关企业已产生具有实际商业价值的概念验证(PoC)与系统交付。
在金融领域,法国农业信贷银行(Crédit Agricole)联合 Pasqal,利用中性原子的优化和模拟算法,针对复杂金融衍生产品的估值定价模型及信贷风险评估进行了实机验证,论证了量子启发式算法在多变量金融计算中的计算潜力。
在制造业领域,宝马集团(BMW Group)将中性原子计算引入其生产与研发流程。针对汽车制造中的板材冲压工艺(金属成型过程),宝马使用 Pasqal 开发的模拟量子算法预测材料的力学行为并寻求最优生产参数。随后,双方还将应用范围扩展至碰撞结构的结构力学微分方程求解。
在算力基础设施部署方面,中性原子计算机开始被集成至经典高性能计算(HPC)中心,形成量子-经典混合工作流架构。Pasqal 已经向法国 GENCI 高算中心、德国于利希(Jülich)研究中心交付了早期 QPU 单元。2025年,其 140 量子比特的 Orion Beta 级机器部署至意大利的 CINECA 高超算中心,直接对接欧洲最高性能的预百亿亿次(pre-exascale)超算 Leonardo,在数据处理分配上实现经典处理器、Nvidia GPU 与量子 QPU 的协同。
9. 未来技术路线图与演进展望
全球中性原子量子计算的主流企业已经发布了高度量化的技术演进路线图,预示着未来五年将是量子从“探索阶段”走向“系统容错阶段”的关键时间窗口。
根据 QuEra 的技术演进规划:2025年,其硬件系统不仅将支撑超过 3000 个物理原子量子比特,而且将通过魔术态蒸馏(Magic state distillation)实现约 30 个逻辑错误纠正量子比特,从而执行通用容错量子算法所需的高保真非克利福德门(non-Clifford gates);到2026年,将推出第三代容错量子计算硬件体系。
Pasqal 的路线图同样目标宏大且层级分明:2025年底完成 1000 个物理量子比特的处理能力储备并制备少量逻辑比特;2026年,计划通过 250 量子比特规模的专用系统在调度优化、物理模拟等领域实现具有现实工业价值的“量子优势(Quantum Advantage)”;2027年,随 Vela 系统的推出,实现 20 个高保真逻辑比特;到2028-2029年,其 Centaurus 和 Lyra 系列产品将把物理比特数量推升至 10,000 个级别,并达成生成 100 至 200 个可靠逻辑量子比特的宏伟目标,这被视作足以解决实际工业大规模复杂问题、实现全面实用化容错量子计算(FTQC)的门槛。
此外,Infleqtion 等企业也着眼于通过先进芯片级光子学(PIC)进一步将万级别比特的控制设备微型化,最终目标是实现桌面级架构。
综上所述,中性原子量子计算由于在物理性质上无需规避制造缺陷的统计涨落、天然具备运行室温设备的潜能,以及其全连接和穿梭能力与前沿纠错编码架构(qLDPC、表面码转置门)的无缝契合,已确立其在容错量子计算竞争中的第一梯队地位。随着激光控制工程、微机电调制器、自动重载机制的进一步优化以及商业应用的持续深化,中性原子技术必将在重塑未来算力生态格局与加速前沿科学计算中发挥决定性作用。