




这是我的第415篇专栏文章。
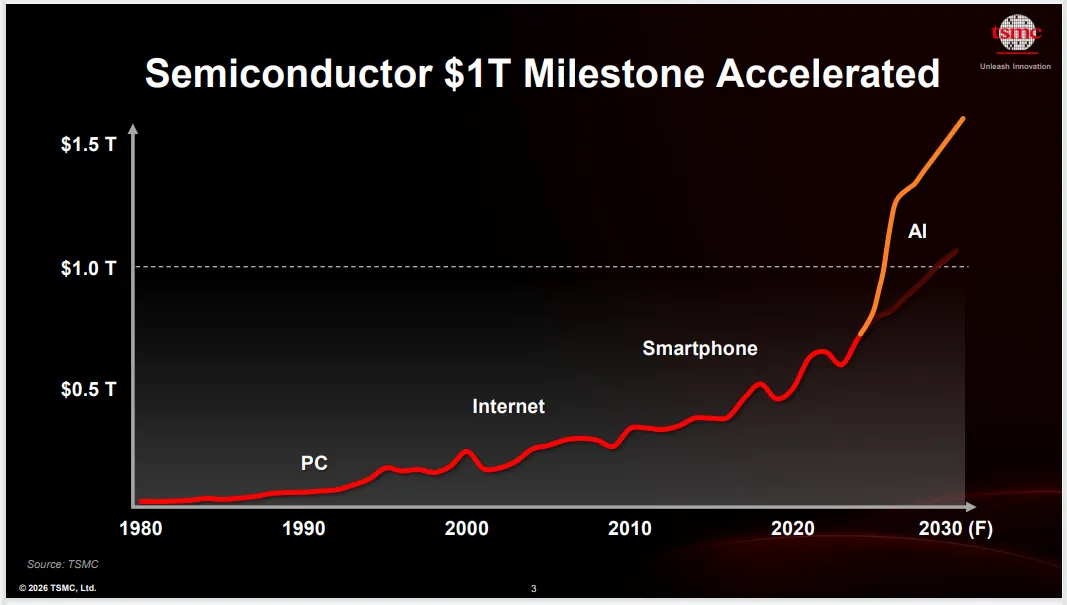
4月底,在台积电2026北美技术研讨会上,这家半导体行业的霸主用了很大的篇幅,描绘了一个迄今还没有完全定型的产业:人形机器人。
台积电给出了一个极其精准的产业定义:
人形机器人 = Agentic AI(智能体AI) + Physical AI(物理AI)
这从侧面印证了一个宏大的趋势:AI正在完成一次历史性的跃迁,从“理解世界”,走向“参与世界”。
此前,台积电曾系统性地把人形机器人拆解为四个技术象限:大脑(Brain)、感知(Sensing)、运动(Movement)、电力(Power)。每一个象限都对应着一组具体的芯片体系:AP、连接芯片、传感器、MCU、PMIC…它们共同拼凑出了一张完整的硅基路线图。
台积电计划在未来三年内,将与人形机器人芯片相关的产能扩大两倍。这意味着,具身智能将第一次在芯片巨头的财报上,变现为真金白银。
至此,硬件侧的故事已经清清楚楚。路线图已经画好,财报已经开出,三年翻倍已经是写在董事会决议里的铁律。
但有一个致命的问题,至今没有人正面回答:谁来“喂饱”这些芯片?
当全球每年250万颗机器人级芯片正在被排进台积电的产线,当每一颗AP、MCU、PMIC都在等待被赋予“灵魂”时,产业界突然意识到一个残酷的现实:硬件这条腿正在以指数级速度迈出,而数据这条腿,还停留在两年前。
这就是2026年具身智能产业最大的“剪刀差”。
硬件侧的明牌已基本落定。但真正决定2026到2030年产业终局的,是一张迄今鲜有公司敢说自己已经看透的暗牌:数据。
文本大模型的训练语料以百亿小时计,而目前具身智能高质量数据的全行业存量,仅有约50万小时。从50万小时到100亿小时,是2万倍的扩张。这不是一个普通的市场机会,这是一条国运级的赛道。
而在这张暗牌的背面,最有意思的故事正在发生。一场由国家数据局、地方政府、产业巨头和VC共同卷入的、规模空前的数据基础设施暗战,已经悄然打响。
硬件已“明牌”:四象限框架反推出的数据缺口图谱
过去,关于人形机器人的讨论几乎都被一个个关于场景的执念所占据:能不能后空翻?能不能走楼梯?能不能练武术?似乎只有动起来,才有人买单。
但如果把视野从产业焦点拉回到台积电的那张芯片图谱,我们会发现一个反直觉的事实:四个象限里被讨论得最热的那一个,恰恰是技术壁垒相对最低的那一个。

大脑:对应AP和AI加速器,需要意图理解与长程规划数据,目前几乎空白。
感知:对应CIS、MEMS、6D力矩、触觉传感器,需要视觉、听觉、力觉、触觉、本体感知五维以上的融合数据,但产业90%的精力却只停留在RGB视觉。
运动:对应MCU和伺服,需要轨迹和力反馈数据,这是当下讨论的绝对中心。
电力:对应PMIC和BMS,需要能耗-动作耦合数据,同样几乎空白。
四个象限里,有三个都尚未真正建立起系统性的采集体系。
其中,尤其值得追问的是感知象限。台积电的传感器清单暗示,机器人的数据感官至少是六维以上的。但今天产业采集的数据是几维的?两维到三维。绝大多数企业仍停留在“RGB视频+动作标签”的初级阶段,少数前沿玩家引入了VLA(视觉-语言-动作)模型,但距离真正的高维多模态,中间还隔着至少两个量级的鸿沟。
这个差距不是工程问题,而是认知问题。
互联网巨头带着做大模型的“肌肉记忆”杀进具身智能,他们最擅长采集视频、处理图像。但人类在做精细动作时,比如拧螺丝、剥鸡蛋、穿针引线…绝大部分关键信息根本不来自眼睛,而是来自指尖的压力、手腕的力矩、整条手臂的本体感受。这些信息一旦缺失,再聪明的VLA模型也只是在“表演”,而非“干活”。
所以,互联网巨头采集的“机器人数据”,在“感知”象限里只解决了10%的问题。
剩下90%的力觉、触觉、本体感知、能耗-动作耦合,根本没有规模化采集的现成路径。
这不是数据“多不多”的问题,而是数据“对不对”的问题。
而在中国,已经有一小批玩家开始悄悄打这三张暗牌。他们的故事,要从当下笼罩产业的五个认知误区说起。
数据迷雾:五大认知误区正在误导整个产业
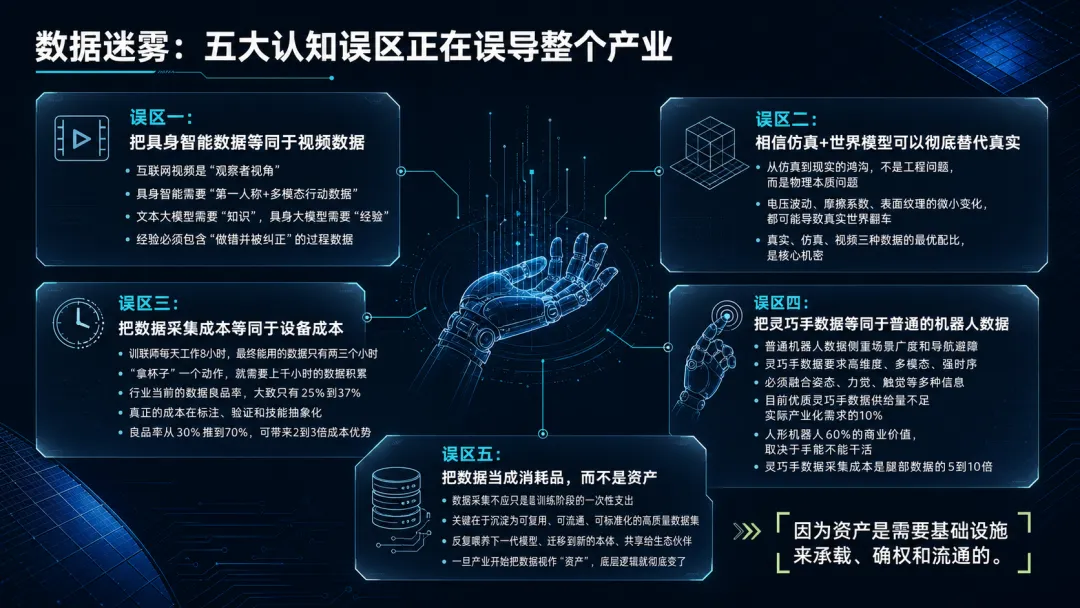
误区一:把具身智能数据等同于视频数据。
这是最流行的偷懒答案:既然大模型是靠语料堆出来的,那机器人靠视频继续堆就行了。但互联网视频是“观察者视角”,具身智能需要的是“第一人称+多模态行动数据”。文本大模型只需要“知识”,具身大模型需要的是“经验”,而经验里必须包含“做错并被纠正”的过程数据。看一万小时的烹饪视频,AI也学不会切菜时握刀的最佳力度。
误区二:相信仿真+世界模型可以彻底替代真实。
从仿真到现实的鸿沟,不是工程问题,而是物理本质问题,一度电的电压波动、地面摩擦系数的微小变化、皮革表面的细微纹理,都可能让仿真环境里完美运行的算法,在真实世界里立刻翻车。真实、仿真、视频三种数据的最优配比,将成为接下来几年各家模型公司最不愿公开的核心机密。
误区三:把数据采集成本等同于设备成本。
有研究机构曾经给出一个统计数字:一个训练师每天工作8小时,最终能用的数据只有两三个小时;机器人学会“拿杯子”这一个动作,就需要上千小时的数据积累。这意味着行业当前的数据良品率,大致只有25%到37%。真正的成本不在采集设备,而在标注、验证和技能抽象化。一个能把良品率从30%推到70%的玩家,将直接拥有2到3倍的成本优势,这是被严重低估的机会。
误区四:把灵巧手数据等同于普通的机器人数据。
普通机器人数据侧重场景广度和导航避障,而灵巧手数据要求高维度、多模态、强时序,必须融合姿态、力觉、触觉等多种信息。目前,优质灵巧手数据的供给量不足实际产业化需求的10%。这不是产能问题,而是结构性稀缺。人形机器人60%的商业价值,恰恰取决于手能不能干活。灵巧手数据的采集成本是腿部数据的5到10倍,但产业当下大量企业都在采集移动数据“占山头”,真正卡脖子的环节反而缺乏系统性投入。
误区五(最隐蔽的误区):把数据当成消耗品,而不是资产。
在绝大多数企业的财务模型里,数据采集是训练阶段的一次性支出,训练完模型,数据就被归档遗忘。但真正决定长期竞争力的,是这些数据能否沉淀为可复用、可流通、可标准化的高质量数据集,反复喂养下一代模型、迁移到新的本体、共享给生态伙伴。一旦产业开始把数据视作“资产”,底层逻辑就彻底变了。因为资产是需要基础设施来承载、确权和流通的。
而这,正是“国家队”入场的根本理由。
国家入场:从“市场失灵”到“基础设施化”的演进
数据一旦跃升为“资产”,就必然呼唤一套极其厚重的底层基建来承载:确权、定价、流通、安全、标准,缺一不可。这套宏大的系统工程,注定超出了任何单体企业的承载极限,必须由国家力量来铺设“高速公路”。
就在4月28日,工信部与国家数据局联合印发了《关于联合实施2026年“模数共振”行动的通知》。但若追本溯源,这场“模数共振”的发令枪,早在2024年12月便已悄然扣动。
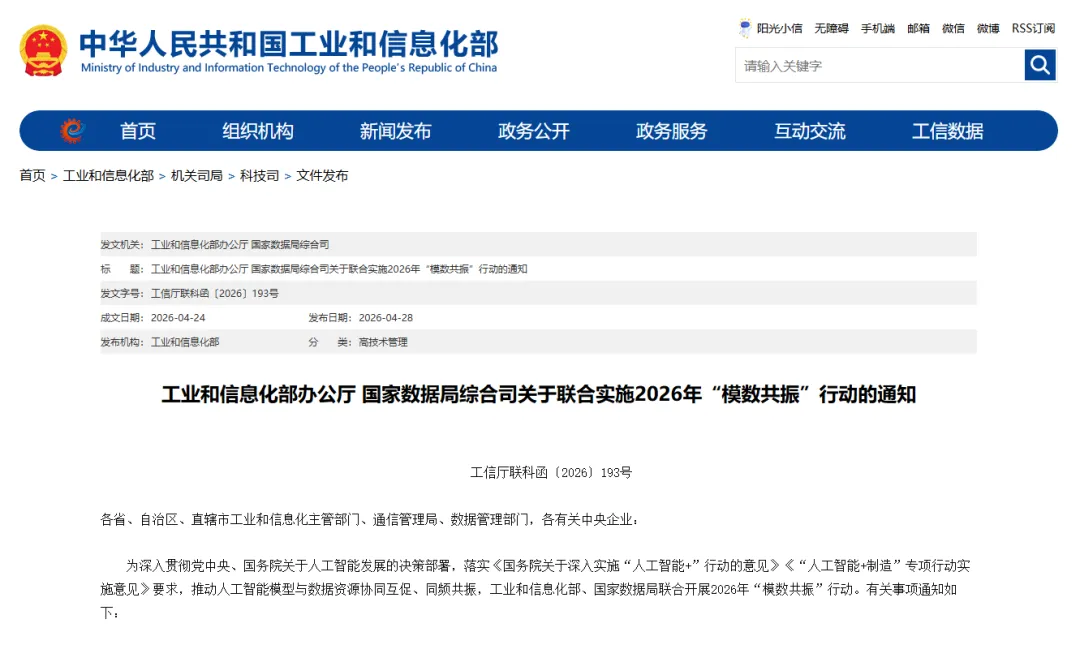
彼时,国家发改委与国家数据局等部门联合发文,首次将“高质量数据集”的战略地位推上台面。历经一年多的沉淀,如今政策端释放出了极强的“实操”信号:2026年不仅将密集出台30余项数据领域国家标准,更要在智能体、具身智能等前沿无人区完成深度布局。
紧随其后的是工信部与国家数据局的联合行动方案:到2026年底,基本形成“数据-模型-场景应用”良性互促的循环,鼓励“模数共振”空间与国家数据基础设施互联互通。
“模数共振”四个字很值得品味,它意味着国家正式把“模型”与“数据”并列为新基建的两块基石。
最高规格的背书则来自“十五五”规划纲要:建设高质量数据集,培育发展具身智能、脑机接口、6G等未来产业。在这里,具身智能不再是配角,而是与6G并列的国家级未来产业。
如果说政策是上层建筑,物理基础设施已经在20多个城市拔地而起。
北京亦庄落地了国家地方共建具身智能机器人创新中心,整个区域已集聚机器人和智能制造生态企业300余家;上海2025年8月发布的《具身智能产业发展实施方案》明确提出,到2027年核心产业规模突破500亿元;张江搭建了全国首个异构人形机器人训练场,目标年内沉淀1000万条高质量具身数据集;天津帕西尼超级数据工厂占地12000平方米,年产近2亿条高维训练数据。
一支由国资与地方政府联合搭建的数据采集军团,正在用标准化、规模化的方式,开采具身智能时代的“原油”。
具身数据的特殊性在于,它不像政务数据是存量资产,它需要实时增量采集的动态交互。这意味着,商业层和国家层最有可能形成的不是替代关系,而是分工关系:国家做通识数据集的底座,企业做专识数据集的差异化。地基由国家铺,上盖由企业建。
这是中国具身数据产业最有可能的演化路径。
世界坐标系:中美路径选择背后的发展哲学分歧
如果把视野拉到太平洋的另一端,我们会发现,中美在具身数据上选了两条截然不同的路。这不是简单的技术路线之争,而是底层发展哲学的分裂。
美国走的是“仿真优先”路线。
这套方法的核心逻辑是:用算力把数据“造”出来。NVIDIA GR00T Blueprint可以在11个小时内生成78万条合成轨迹,相当于6500小时的人类演示数据。当真实采集成本太高时,就用算力压垮采集,反正算力是英伟达自己的。
中国走的是“真实优先”路线。
从北京亦庄到上海张江,从天津帕西尼到武汉创新中心,一座座物理意义上的数据采集工厂正在拔地而起。帕西尼超级数据工厂构建了全球第一个VTLA(视觉-触觉-语言-动作)具身智能模型。当顶级算力受限时,就用场景换数据,用工厂换数据。
两套方法的底层假设完全相反。
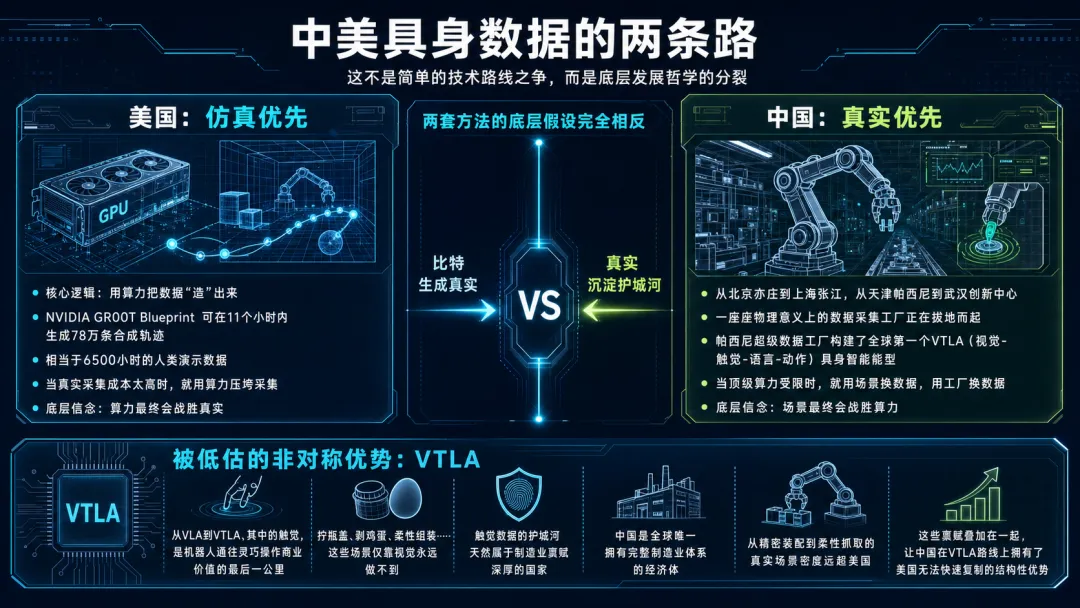
美国相信“算力最终会战胜真实”,只要GPU足够多、世界模型足够好,比特就能生成原子级别的真实。
中国则相信“场景最终会战胜算力”,只要工厂足够多、模态足够全,触觉、力觉、本体感知这些无法被完美仿真的数据,将成为终极护城河。
这种分歧并非偶然,而是被外部约束逼出来的产业适应。GPU出口管制让中国无法以同等规模做仿真合成,但这种被迫的转向,反而催生了一个被严重低估的非对称优势:VTLA。
从VLA到VTLA,其中的触觉,恰恰是机器人通往灵巧操作商业价值的最后一公里,拧瓶盖、剥鸡蛋、柔性组装…这些场景仅靠视觉永远做不到。
更关键的是,触觉数据的护城河天然属于制造业禀赋深厚的国家。中国是全球唯一拥有完整制造业体系的经济体,从精密装配到柔性抓取的真实场景密度远超美国。这些禀赋叠加在一起,让中国在VTLA路线上拥有了美国无法快速复制的结构性优势。
写在最后
台积电用30年在芯片端筑起了护城河,OpenAI和DeepSeek用3年在模型端筑起了护城河。下一块护城河,很有可能建在数据端。
回到产业层面,目前有五条具身数据采集路径正在同台竞争:真机遥操作、UMI外骨骼、第一人称视频学习、仿真合成、世界模型生成。
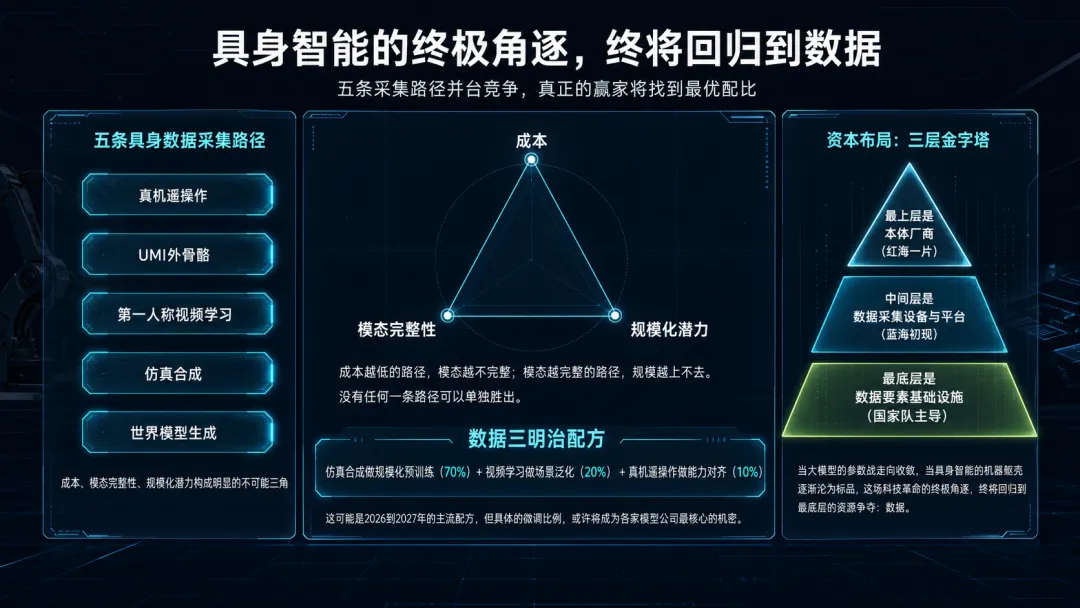
它们各自的成本、模态完整性和规模化潜力构成了一个明显的“不可能三角”:成本越低的路径,模态越不完整;模态越完整的路径,规模越上不去。没有任何一条路径可以单独胜出。
所以真正的赢家,不会押注单一路径,而是会找到最优配比。
我们暂且把它叫做“数据三明治配方”:仿真合成做规模化预训练(70%) + 视频学习做场景泛化(20%) + 真机遥操作做能力对齐(10%)。
这可能是2026到2027年的主流配方,但具体的微调比例,或许将成为各家模型公司最核心的机密。
而围绕这盘棋的资本布局,正在形成一个清晰的三层金字塔:
最上层是本体厂商(红海一片)
中间层是数据采集设备与平台(蓝海初现)
最底层是数据要素基础设施(国家队主导)
当大模型的参数战走向收敛,当具身智能的机器躯壳逐渐沦为标品,这场科技革命的终极角逐,终将回归到最底层的资源争夺:数据。
在这个金字塔中,越往下走,根系越深;越往上走,厮杀越烈。


