


报告来源:资料版权归原发布机构所有,若有侵权,联系删除。
本文件深度剖析了大语言模型(LLM)的技术演进与推理能力突破,为出海企业提供从底层AI技术理解到高阶智能化应用的全景视图。文件指出,随着大模型从“感知智能”迈向“认知智能”,跨境企业必须在内容生成、客户服务、数据分析等场景中引入具备自主推理能力的大模型工具,以实现运营提效与用户体验升级。
• DeepSeek-R1实现推理能力质变:仅通过强化学习(RL)即可习得复杂推理能力,AIME 2024 pass@1分数从39.2%跃升至71.0%,逼近OpenAI o1水平,标志着中国开源模型在数学与编程推理赛道跻身全球第一梯队。
• 极致模型架构优化降低成本:采用MoE(混合专家)、MLA(多头隐含注意力)、MTP(多词元预测)等技术,实现671B参数下激活仅37B,训练成本约Llama-3.1的1/10,大幅降低企业部署门槛,助力中小企业实现高性价比AI落地。
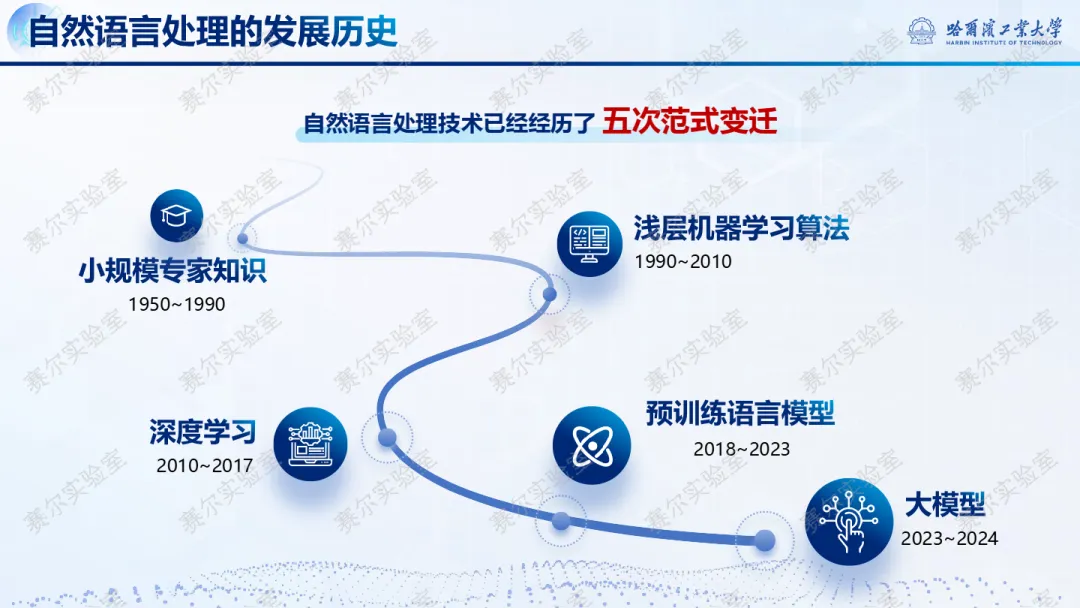
• 第六次NLP范式变迁开启:从“预训练+微调”转向“纯强化学习驱动推理”,DeepSeek-R1-Zero证明无需监督微调也能涌现思维链(CoT)与自我反思机制,预示未来模型将更擅长处理零样本复杂任务,如自动诊断、合同审查、多跳问答。
• 开源战略推动技术民主化:DeepSeek坚持开源R1系列模型及蒸馏版本,提供完整训练代码与数据思路,极大促进开发者社区创新,有利于构建基于中文语境的DTC品牌客服机器人、智能投顾系统等垂直应用。
• 人机协同决策已落地医疗场景:哈工大HIT-SCIR团队研发的“本草”医学大模型在30多家医院试用,通过多智能体辩论式会诊,人机融合组诊断准确率超过全人类医生组,为跨境数字健康产品出海提供可信AI背书。
适用人群:正在布局AI内容生成的DTC品牌营销团队、寻求智能客服升级的跨境电商平台运营者、探索AI+垂直行业解决方案的SaaS出海创业者、关注前沿AI技术动向的投资机构与产品经理。
应用场景:适用于在选择大模型供应商时评估其推理能力与成本效益;在设计智能导购、售后应答、多语言文案生成等自动化流程时借鉴思维链提示工程;或作为AI战略规划参考资料,提前布局基于开源大模型的私有化部署与定制化训练。



点击可获取完整版,开启出海新篇章!
如需获取本报告
关注订阅号并后台
回复关键词"报告"免费领取
扫描下方二维码可获得完整内容
名额有限快来领取吧!
【扫码添加,获取完整报告内容】

微信改版啦,
再不星标我们,你就看不到我们了……
星标我们,出海不迷路
