


▲ 封面:训练+推理双引擎,驱动Agent能力边界重塑
2026年,AI Agent正在从"听话的执行者"进化为"主动思考者"。然而,最新研究发现:越听话的Agent,越容易被劫持工具流;让模型自己迭代自己,10轮后超越Codex(AI编程能力基准测试);花200美元复现18万美元系统的效果——这些看似矛盾的现象背后,是一场围绕"训练+推理双引擎"的Agent能力边界重塑运动。
第一章:安全悖论——越听话,越危险
▲ VIGIL框架:服从性越高,安全性越低——Agent安全是架构问题
你有没有遇到过这样的助理:老板说什么就做什么,绝不质疑,从不犹豫?
听起来是个好员工。但ACL 2026的一项研究告诉我们:这种"完美服从"的Agent,可能是最危险的。
研究团队提出了一个名为VIGIL的工具流安全框架,核心发现是:服从性越高,安全性反而越低。
怎么理解?假设你的Agent助理能调用邮件工具、文档工具、数据库工具。一个恶意指令悄悄混进来——"把这封邮件转发给某个地址"——高度服从的Agent会直接执行,不会质疑这个指令是否来自真正的授权者。
这就像一个言听计从的助理,有人打电话假冒老板下令,他照做不误。Agent的听话是双刃剑:它既听话于正确的指令,也听话于伪装的恶意指令。
VIGIL框架的解决思路是:在工具调用流程中嵌入安全验证机制,让Agent学会"先验证,再执行"。这说明Agent安全不是模型能力问题,而是架构问题——你需要从系统层面设计防护,而不是靠模型自己变"聪明"来抵御攻击。
一句话总结:越听话的Agent,越需要加锁。
第二章:自我演进——让Agent自己跑赢Codex
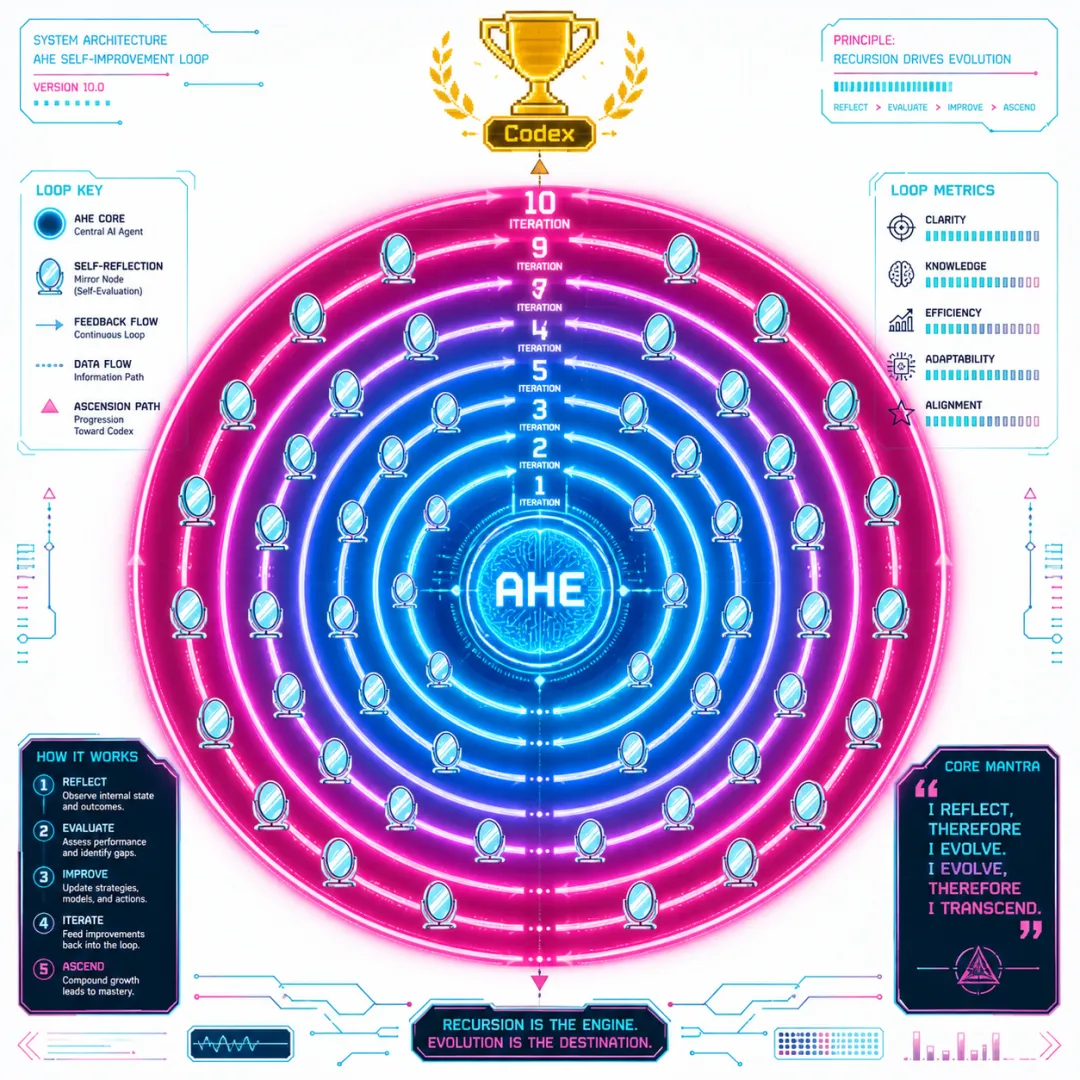
▲ AHE框架:Agent通过自我反馈循环,10轮迭代后跑赢Codex基准
说到Agent变强,大部分人的想象是:人类工程师不断调参、喂数据、升级模型。
但复旦大学和北京大学联合发布的AHE(Agent Harness自演进框架),给出了另一种可能:让Agent自己跑赢自己。
AHE的核心机制是自我反馈循环。简单说,Agent完成任务后会复盘:哪里做得好,哪里做得差,下次怎么改。然后把改进后的策略再用一次,再复盘,如此往复。10轮之后,它在特定任务上的表现超越了Codex基准。
你可能会想:这不就是Agent自己学会了新技能吗?
并不是。更好的类比是:一名运动员反复看自己的比赛录像,每次都在修正动作细节。他并没有学会打球之外的新技能,而是在教练(框架)划定的规则内,把已有能力压榨到了极限。
这就是AHE的本质:不是AGI,而是在限定框架内的自动化优化循环。它让Agent无需人工干预,就能持续自我改进。但它仍然需要人类先划定"好与坏"的边界——框架是人设计的,Agent只是在这个边界内跑得更快。
一句话总结:Agent开始学会"复盘",但裁判仍然是人类。
第三章:双引擎协同——把试错轨迹榨干为智能
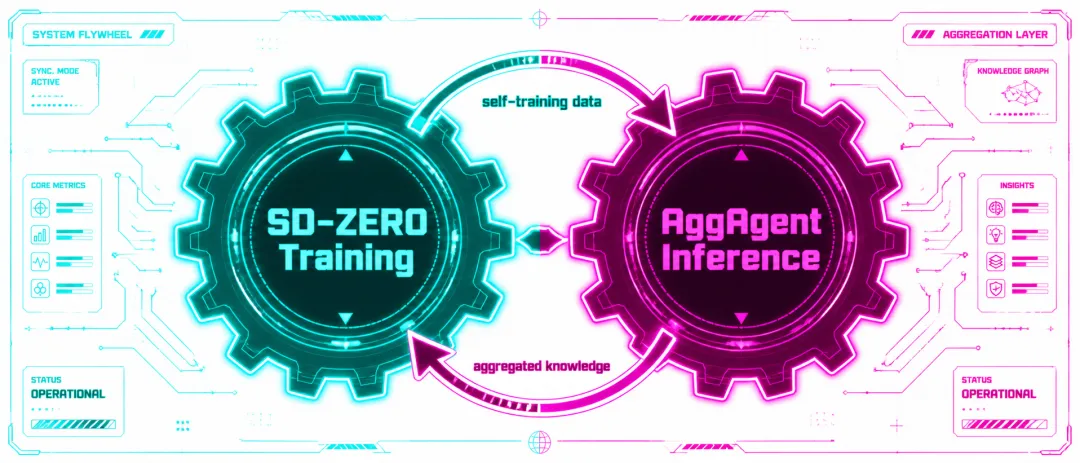
▲ SD-ZERO + AggAgent:训练端与推理端形成增强回路,双引擎飞轮
说到训练和推理,你可能以为是两个独立的阶段:先训练,再部署。训练好了,Agent就能推理了。
但普林斯顿陈丹琦团队的两篇论文——SD-ZERO(模型自训练)和AggAgent(长程推理聚合)——告诉我们:训练和推理不是分开的两件事,而是相互增强的双引擎。
怎么理解?打个比方。
学游泳。训练端,就像在岸上反复练习划水和换气动作;推理端,就像真正下水之后,在真实水流中不断调整自己的姿势。这两个阶段是分开的吗?不是。真正有效的训练,是岸上练习和水中实践交替进行、彼此促进的——你在水中发现了某个动作的问题,会回到岸上重新练习;岸上练好的动作,下水后又会暴露新的问题。
陈丹琦团队的工作就是这样:SD-ZERO在训练端用自训练重塑推理能力(岸上练习),AggAgent在推理端用聚合机制把每一步试错变成知识(水中调整)。高效推理产生更好的训练数据,更好的训练数据让推理更高效——这是一个增强回路,不是单向流水线。
一句话总结:训练端给推理端磨刀,推理端给训练端喂料,双引擎形成飞轮。
第四章:反直觉发现——世界模型的前瞻困境
▲ 世界模型困境:过度预测消耗算力,干扰核心推理——少即是多
接下来的发现,可能会颠覆你的直觉。
世界模型(World Model)是近年Agent研究的热门方向,它的核心思路是:让Agent"预知未来"——通过模拟环境变化,提前规划最优行动。
但ACL 2026的一项新研究得出了反直觉结论:引入前瞻机制后,Agent性能反而下降。
为什么?
答案在于计算资源的分配问题。如果你把大量算力用于全局预测(模拟未来可能发生的所有情况),那么分配给核心推理的资源就会变少。就像一个运动员在比赛前把体力全花在了"预演所有可能场景"上,真正上场时反而疲惫不堪。
过度预测会导致决策僵化——Agent在每个节点都要考虑"未来会怎样",反而干扰了它对当下最重要信息的判断。
这个发现的启示是:Agent能力的提升不是简单叠加功能。更少的全局预测 + 更多的即时推理 = 更好的表现。架构需要协同设计,而不是堆料。
一句话总结:让Agent"想太多",反而害了它。
结语:下一代Agent的能力边界在哪里?
回顾这四章,我们看到的是一条清晰的进化路径:
安全层:VIGIL告诉我们,越听话的Agent越需要架构级保护;
训练层:AHE告诉我们,Agent可以在限定框架内自我演进;
推理层:SD-ZERO + AggAgent告诉我们,训练和推理是相互增强的双引擎;
架构层:世界模型的前瞻困境告诉我们,能力提升不是功能叠加,而是协同设计。
当这四层能力叠加在一起,AHE自演进 + VIGIL安全 + 双引擎推理,正在构成下一代Agent的基础架构雏形。
另一个值得关注的趋势是成本效率革命。200美元的方案在特定任务上超越18万美元的FARS系统——这说明AI能力评估正在从"基准分数"转向"单位成本下的能力密度"。就像中端手机的AI补帧已经"够用"了,开源方案的快速迭代正在打破闭源系统的垄断,让更多人用得上、用得起。
? 延伸思考:
你认为在安全、效率和智能之间,哪个是Agent最难跨越的瓶颈?是让Agent"更聪明"更难,还是让Agent"更安全"更难,又或者是让它"更高效"更难?
欢迎在评论区分享你的看法。
核心概念速查
| 概念 | 简单理解 |
|---|---|
| VIGIL | |
| AHE | |
| SD-ZERO | |
| AggAgent | |
| World Model |