研究报告:利用 AI 智能体变革数据标注——架构、推理、应用及影响
摘要
数据标注是人工智能(AI)和机器学习(ML)的核心基础,传统人工标注与经典机器学习方法存在成本高、效率低、质量不稳定等局限性。随着大型语言模型(LLM)驱动的 AI 智能体的出现,标注流程正在经历范式性变革。本文基于 Karim 等(2025)在《Future Internet》发表的综述,系统分析了 AI 智能体在数据标注中的架构、推理方法、应用实践及其社会技术影响,展示了智能体在提升标注效率、保证质量、支持多模态数据和降低成本方面的潜力,并提出未来研究方向。
1. 引言
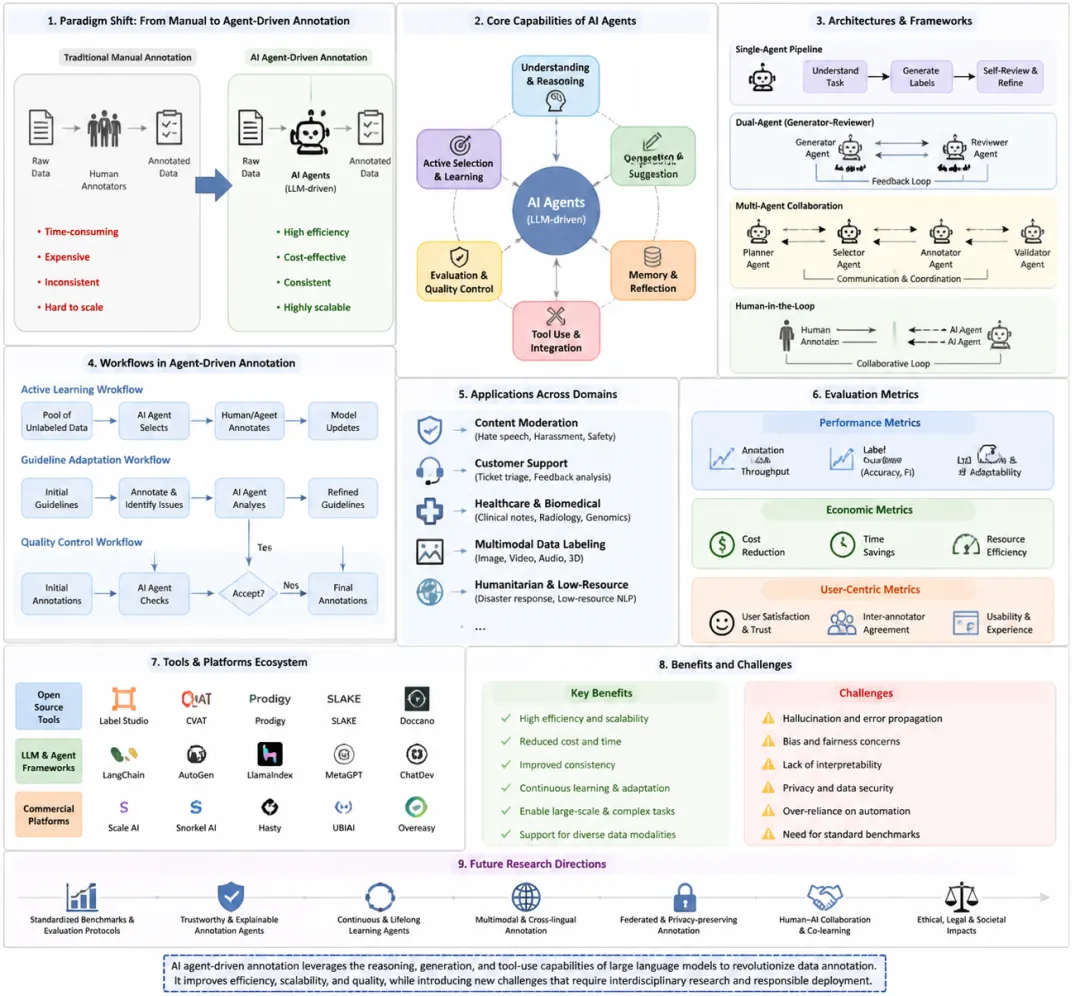
随着 AI 模型规模和复杂性的指数级增长,数据标注需求快速膨胀。高质量标注数据是监督学习的前提,直接影响算法在自动驾驶、医疗诊断和自然语言理解等领域的性能。然而,人工标注存在以下局限:成本高、耗时长:复杂数据集可能需要数月乃至数年完成。质量不一致:主观任务如情感分析或内容审核的标注一致性低于 70%。专业知识缺乏:领域任务如医学影像或法律文本需要专业训练,限制了标注人员供应。智能体驱动的数据标注通过自主性、协作和反馈机制,显著缓解了这些瓶颈,成为提升标注系统效率和可靠性的关键途径。
2. 数据标注方法演进
2.1 传统人工标注
工具如 LabelImg、LabelMe、Prodigy 等辅助专家标注图像或文本。问题:成本高、规模有限、主观任务一致性低、隐私风险。2.2 经典 ML 辅助方法
主动学习(Active Learning):优先标注信息量大的样本,减少人工负担。弱监督与迁移学习:通过规则或预训练模型生成标签,但仍需人工干预,易产生噪声。2.3 LLM 驱动方法
GPT-3/4、Llama-2 等可生成、审核和扩充标注数据。
3. AI 智能体及分类
3.1 概念
AI 智能体是自主实体,通过感知–推理–执行–学习循环实现智能化标注。LLM 集成增强了自然语言理解、推理、任务分解和少样本学习能力。3.2 分类
3.3 功能
4. 架构与系统设计
单智能体流水线:线性处理标注、评估、自我优化(如 Self-Refine)。双智能体复核模型:生成–审查模式,形成迭代反馈循环。多智能体协作:分工协作、角色分配(如 MetaGPT、TESSA),提升质量与可扩展性。人机协作(HITL):保留关键人工监督,如 CoAnnotating 框架。
5. 标注评估与验证
技术指标:标注吞吐量、准确率、F1、Cohen’s κ、一致性、适应性。
6. 应用案例
内容审核:快速标注用户生成内容,实现人工准确率,减轻心理负担。客服与反馈分析:主题标签、情感分析,显著提升分析效率。医疗与科研:医学影像、EHR、基因功能标注,智能体可接近专业水平。多模态数据标注:文本、图像、音频整合,速度提升 100x。低资源与人道主义:灾害信息分类、跨语种标注,提升响应速度和覆盖率。
7. 挑战与未来方向
跨域迁移与低资源支持:扩展到低资源语言和专业领域。智能体协作优化:多智能体通信、冲突解决、持续学习机制。
8. 总结
LLM 驱动的 AI 智能体正在从根本上改变数据标注范式。通过自主决策、协作机制和自适应质量控制,智能体显著提升了标注效率、质量和可扩展性。论文提供了系统分类、架构分析、评估方法和应用案例,为未来构建高效、可靠且可解释的数据标注生态奠定了基础。