


AI 工程师的三大断层:2026 白皮书
这是《三大断层》系列的最后一篇。
过去两周,我们一起走完了 5 篇——开篇宣言 → 定义断层 → 信号断层 → 产品发布 → 撮合断层与流动图谱。
今天这篇干三件事:
- 1. 把 5 篇的结论压成一页纸,方便你整体回看
- 2. 给出 2028 年的 3 条判断,供你做职业决策参考
- 3. 提供完整白皮书 PDF 下载——所有数据、图表、方法论的合集,关注公众号后台回复
AI2026
一、一页纸回顾
过去 5 篇建立了这样一套语言——
三大断层(核心框架)
AI 招聘市场的问题不是"岗位不够"或"人不够"。是供需两端在用不同的词汇表——具体拆成三层:
- • 定义断层 Taxonomy:AI Engineer 到底是什么,没有共识
- • 信号断层 Signal:怎么证明一个人会 AI,没有权威中枢
- • 撮合断层 Matching:JD 和简历怎么对上,没有机制
AI 工程师光谱 L1 到 L5(取代 7 种标签)
- • L1 · API 调用者(能把模型接进业务)
- • L2 · Prompt 工程师(能让输出稳定)
- • L3 · RAG 架构师(能搭完整检索系统)
- • L4 · Agent 设计师(能做多步骤多工具协作)
- • L5 · AI 全栈(从 Prompt 到 fine-tune 端到端)
能力信号 vs 能力标签(Signal vs Label)
- • 标签(Label)是自述——简历、LinkedIn、JD 里写的词。易通胀、难验证。
- • 信号(Signal)是他述——GitHub 画像、作品集、Benchmark 成绩、社区贡献。可验证、难造假。
- • 在 AI 时代,Signal 的权重会越来越大。
GitHub 画像四维(Signal 层的具体标准)
- • 影响力(reachability):关注者触达
- • 贡献力(impact):Stars / Fork 带来的声量
- • 活跃度(activity):近期 commit / issue 参与
- • 生态参与(ecosystem):跨仓库 PR / issue 互动
二、6 组关键数据
系列里引用过的核心数据,全部列在这里。这些数字也写进了完整白皮书的附录。
数据 1:中国 GitHub 开发者总量
110,659 人(china_confirmed,2026-04-23 快照)
按综合能力分布:
- • T1 极客精英:9,198(8.31%)
- • T2 技术专家:18,502(16.72%)
- • T3 活跃开发者:40,110(36.25%)
- • T4 新兴开发者:42,848(38.72%)
数据 2:领域分布("AI 方向"的真实边界)
在这 11 万人里,被归为各领域的比例:
- • 跨栈 / 综合:38,000(34.6%)
- • 前端:21,830(19.7%)
- • AI 与机器学习:12,993(11.7%)
- • 移动端:9,900(9.0%)
- • 后端:9,100(8.2%)
- • (其他:运维、数据工程、数据库、嵌入式、游戏、区块链、安全、全栈……)
反直觉观察:前端开发者比 AI 方向开发者多 1.67 倍;"AI Engineer" 在 JD 里最热门,在画像里是 11% 的小众。
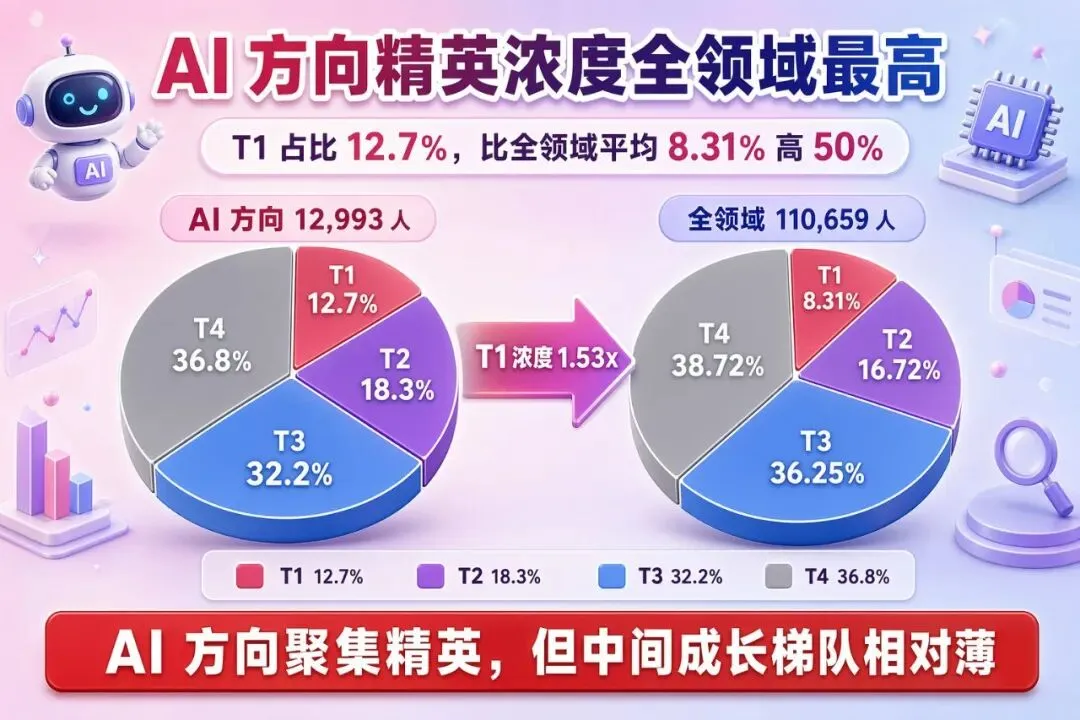
数据 3:AI 方向的 Tier 分布
AI 方向 12,993 人内部——
- • T1(极客精英):1,645(12.7%)
- • T2(技术专家):2,384(18.3%)
- • T3(活跃开发者):4,191(32.2%)
- • T4(新兴开发者):4,782(36.8%)
观察:AI 方向的 T1 占比(12.7%)是全领域最高,比平均(8.31%)高 50%——AI 方向相对聚集精英。但 T4 也占 36.8%,"顶尖 + 新兴"双偏高,中间的成长梯队相对薄。
数据 4:AI 方向的城市地图
Top 10 城市:
| 排名 | 城市 | 人数 | 平均画像综合分 |
|---|---|---|---|
| 1 | 北京 | 2,699 | 22.17 |
| 2 | 上海 | 2,012 | 21.24 |
| 3 | 杭州 | 950 | 21.25 |
| 4 | 深圳 | 841 | 21.59 |
| 5 | 广州 | 480 | 19.17 |
| 6 | 香港 | 450 | 25.56(全体最高) |
| 7-10 | 成都 / 武汉 / 南京 / 台北 | 214-379 | 18-23 |
观察:北京 AI 方向人才是上海的 1.34 倍;香港 AI 画像综合分全体最高(虽数量小);成都、武汉、南京等二线城市各有 200-400 个 AI 开发者,不应被招聘市场忽视。
数据 5:AI 方向的公司集中度(反直觉)
Top 15 机构:
- • 1-5 名全是高校:清华(233)/ 浙大(179)/ 上交(140)/ 北大(134)/ 复旦(114)
- • 6-7 名是头部大厂:腾讯(111)/ 阿里(86)
- • 8-11 名又是高校:武大、南大、华科、中科大
- • 12-14 名:电科大、百度(56)、字节(55)
观察:前 6 名有 5 所是高校。清北浙交复的 AI 开发者加起来是四大厂(腾讯 + 阿里 + 百度 + 字节)总和的 2.6 倍。
原因:高校 AI 方向学生 / 博士生有时间也有动力开源,大厂 AI 代码多在内网。但对招聘意味着——不要只盯大厂背景。
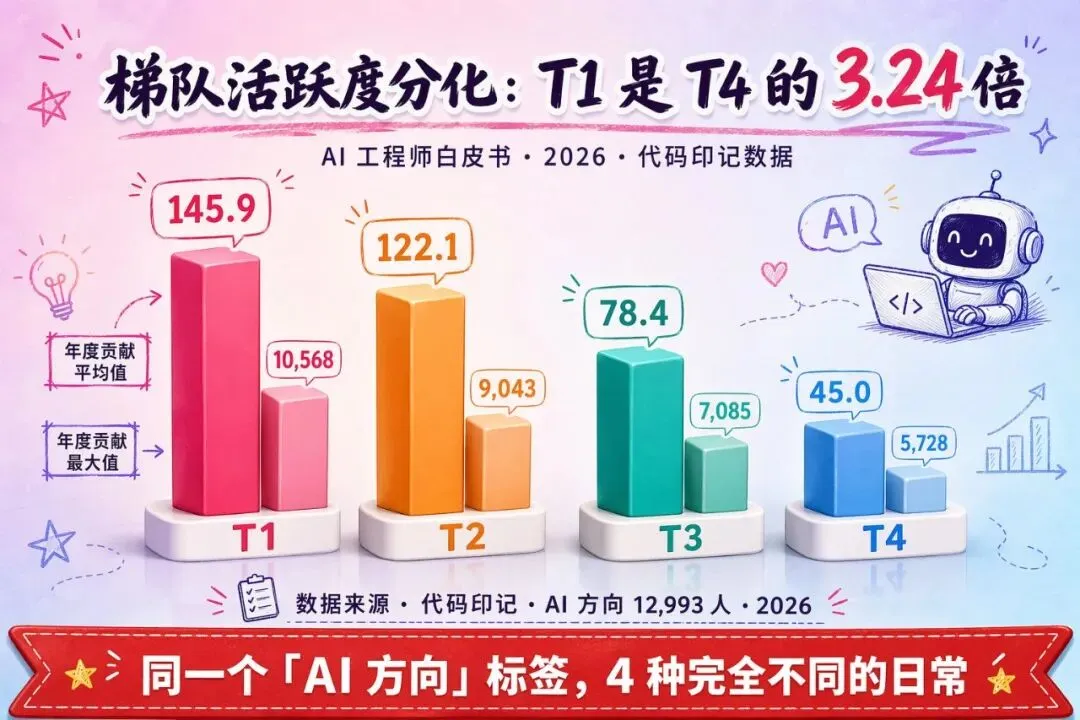
数据 6:AI 方向的 Tier × 活跃度对比
同样都叫 "AI 方向开发者",不同 Tier 的实际活跃度:
| Tier | 年贡献平均 | 年贡献最大 |
|---|---|---|
| T1 | 145.9 | 10,568 |
| T2 | 122.1 | 9,043 |
| T3 | 78.4 | 7,085 |
| T4 | 45.0 | 5,728 |
观察:T1 的年均活跃度是 T4 的 3.24 倍。这个差距会自我加速——写得多 → 获得反馈 → 更有动力写 → 画像更强 → 更多机会 → 写得更多。
三、2028 年的三条判断
写这个系列的过程中,我越来越相信接下来 2-3 年会发生这 3 件事。如果你要做职业决策,可以参考。
判断 1:"AI Engineer" 这个标签会消失或重新定义
2028 年之前,大概率发生两件事之一:
- • 标签被细分术语取代:招聘市场开始明确说"L2 Prompt Engineer""L3 RAG Architect""L4 Agent Designer"——不再笼统说 "AI Engineer"
- • 标签回归 Software Engineer:因为到时候"会 AI"就像今天"会写 SQL"一样是基础门槛,不再独立成岗
决策建议:别把自己的 career identity 完全绑在 "AI Engineer" 这个词上。多想"我在光谱的哪一层""我的核心能力是什么"。
判断 2:GitHub 画像会成为事实简历
今天只有 10-15% 的工程师会认真展示 GitHub 画像。2028 年这个比例会到 50%+。
两个推动力:
- • AI 内容造假越来越容易——LinkedIn 简历可以用 LLM 生成几十版,HR 的"人眼筛选"在降维
- • HR 工具会自动读 GitHub 画像——不会再问"几年 AI 经验",会直接给出"这位候选人的活跃度是行业 P42"
决策建议:从今天起,保持 GitHub 活跃。不需要每天 commit,但至少每月有可见的产出。6-12 个月的活跃度信号比 3 页简历值钱。
判断 3:任务化面试会普及
一线公司招 AI 工程师不会再用 "LeetCode 2 轮 + 系统设计 1 轮"。会是:
- • take-home 任务(24 小时做一个真实业务场景的 Demo)
- • Benchmark 对比(你的 agent 能不能超过 AgentBench 中位数)
- • 代码 review(看你写的真实代码,讨论设计哲学)
决策建议:刷 LeetCode 和做真项目二选一,毫不犹豫选后者。
四、对工程师的 5 条建议
如果你是现在 30 岁上下、在考虑 AI 方向的工程师,这 5 条写给你:
1. 明确你在 L1-L5 的哪一层
看 W2 的自测题。诚实回答"我能交付什么"。不要焦虑级别低——L1 到 L3 的市场需求最大,不是"越往上越值钱"。
2. 用 GitHub 画像做你的他述简历
从今天起,每月至少 1 个可公开的产出(代码 / 项目 / 技术博客 / issue 参与)。6 个月后你的活跃度信号会是面试时最强的筹码。
3. 选子领域——NLP 红海,Agent / MLOps / Embodied 还有蓝海
看 W4+W5 数据:AI 方向 5822 人做 NLP(44.8%),Agent 只有 688 人(5.3%)。不是说 NLP 不做,而是竞争密度不一样。如果你想快速积累 Signal,选新兴热点 + 竞争者少的交叉点。
4. 不用非进大厂,学院派和独立开发者都有红利
图 3 的反共识结论:高校 + GitHub 强的组合正在跑赢大厂背景。如果你是博士 / 硕士 + 有 AI 项目,你在 2026-2027 市场上的议价能力很强。
5. 学会用"信号语言"写简历 / 自我介绍
不要再写"5 年 AI 经验"。改成写具体信号:
- • "过去 12 个月 GitHub 贡献 XXX 次"
- • "主要 AI 项目
github.com/me/xxx获得 Y stars" - • "在 HuggingFace 上开源过 Z 个模型"
这样的信号句式比 Label 有说服力 10 倍。
五、白皮书领取
以上是 2 周连载的精华。完整白皮书 PDF(50+ 页,包含全部数据表、所有图表高清版、一手 Python 分析脚本、补充方法论)可以关注我们公众号后台回复:
AI2026
回复关键词后,系统会自动发你 PDF 下载链接。
白皮书里额外的内容:
- • 16 张完整数据图表(文章里只展示了 3 张)
- • 从北京 / 上海 / 杭州 / 深圳 / 香港的 5 个真实 T1 AI 开发者的匿名对话访谈(半小时一档)
- • 代码印记的完整数据方法论(我们怎么判定"中国开发者""AI 方向""Tier 分级"的算法细节)
- • 10 家中国 AI 创业公司的"招聘 JD 案例诊断报告"(哪些是典型错位、怎么改)
六、最后一句
2 年前我们还没有"全栈工程师"的精确概念。但这个词铸造出来之后,整个市场围绕这个词重构了招聘。
今天我们试图对"AI 工程师"做类似的事——在这个还没有人说清楚的窗口期,把语言先铸造出来。
如果接下来 2 年,你在招聘、谈判、选择方向的时候,能想起"这是三大断层里的哪一层""我是 L 几""我的 Signal 说了什么"——这套语言就发挥了它的价值。
感谢你走完这 6 篇。
我们下个系列再见。
本系列所有数据由「代码印记」开发者画像平台(ct.xiaotaozi.cc)采集自 GitHub 公开数据。完整白皮书 PDF 通过公众号关键词「AI2026」发送。若你对某个数据或方法论存疑,可以在评论区留言,我们一起讨论。