


核心定位演进:从交互式模型到全自主智能体系统
2026年4月23日,OpenAI正式发布了代号为“Spud”的新一代前沿大语言模型家族——GPT-5.5及GPT-5.5 Pro。该系列模型的发布标志着人工智能技术栈从“交互式问答(Conversational AI)”向“自主智能体工作流(Agentic Workflow)”的根本性范式转移。与以往针对通用对话场景优化的策略不同,GPT-5.5的设计核心在于执行复杂、多步骤的现实世界任务(Real-world work),涵盖高级软件工程、终端环境操作、跨工具的知识工作以及早期科学研究。
从底层系统设计的角度来看,GPT-5.5是自GPT-4.5以来,OpenAI首个经过全面重新训练的基础模型(Base Model),而非对现有架构的微调(Fine-tuning)或单纯的参数扩展。这种全面重训的目的是从根本上改变模型与人类操作者的交互契约,即大幅减少对人类“手把手式(Handholding)”和“保姆式”提示的依赖。在面对高度模糊、多步骤的系统级指令时,GPT-5.5能够自主制定执行计划、在不同软件工具间切换、审查中间生成结果、从执行错误中恢复,并持续推进工作流直至目标达成。这种认知负载向机器端的转移,直接重塑了模型的底层架构设计、硬件协同机制以及最终的商业服务定价逻辑。
底层架构创新:O2训练基础设施与原生全模态融合
O2训练基础设施与动态路由机制
GPT-5.5的整体性能跃升建立在OpenAI内部称为“o2”的全新训练与推理基础设施之上。o2架构的核心技术创新在于其配备的“动态路由(Dynamic Routing)”系统。传统的大语言模型在处理请求时,通常会激活固定比例的参数或执行统一深度的计算图,而o2基础设施能够根据用户提示词(Prompt)的复杂度和逻辑深度,在推理阶段动态调节并分配计算资源。
这种计算资源动态配置的直接结果是事实一致性的显著提升和模型幻觉率(Hallucination Rate)的断崖式下降。系统测试数据表明,在o2架构的支持下,GPT-5.5相比于上一代模型,幻觉发生率整体降低了60%。在独立的医疗和学术文献交叉测试中,配备网络访问权限的GPT-5.5的幻觉率已降至9.6%(相比GPT-4o的12.9%有26%的相对下降)。如果开启深度推理(Thinking)模式,该比率可进一步压缩至4.5%。此外,GPT-5.5包含重大事实性错误的回复数量较前代减少了44%。这一系列数据证明,o2架构通过更精确的不确定性评估机制,有效地抑制了模型在信息匮乏时倾向于“合理性编造”的统计特性。
原生全模态(Omnimodal-native)统一处理架构
在多模态处理能力上,GPT-5.5采用了“原生全模态(Multimodal-native)”的动态Token系统。以往的模型往往在纯语言核心模型之上,以外挂适配器(Adapters)或独立子系统的形式集成视觉和听觉模块,这种方式在跨模态对齐时容易产生信息损耗。相反,GPT-5.5在架构设计之初就消除了这种物理隔离,使得模型能够在单一的神经网络前向传递(Forward pass)过程中,同时且平行地处理文本、图像、音频和视频数据。
在具体的模态处理上限方面,GPT-5.5展示了极高的技术规格:
文本处理: 标准配置支持高达272K的单次输入,并具备极高的语义理解连贯性。
视频处理: 单次请求最多可原生处理256帧视频画面,支持针对复杂物理运动和空间关系的视频分析任务。
音频处理: 原生支持24种语言的音频输入,并内置了环境噪声过滤机制,无需前置独立的语音转文本(STT)模型即可直接提取声学特征进行推理。
由于系统在统一的潜在空间内推理所有输入模态,GPT-5.5在跨模态逻辑任务(如根据视频监控画面和同步音频诊断工业设备故障)中,展现出了比前代更快、更连贯的推理效率。
并行测试时计算(Parallel Test-Time Compute)
针对性能要求处于极值区间的GPT-5.5 Pro版本,OpenAI在其底层引入了规模化且高效的“并行测试时计算”机制。在常规自回归生成任务中,模型输出的质量严格受限于单次推理的固定计算量。而在GPT-5.5 Pro版本中,模型被赋予了更长的内部“计算时间(Compute Time)”。
这一机制允许模型在输出最终答案前,在内部隐式生成多个可能的推理路径,进行假设检验、中间态审查和逻辑回溯,最后通过并行计算网络整合出最优解。这种深层推理能力使得GPT-5.5 Pro在处理高级法律审查、复杂金融建模以及最前沿的数学与科学研究时,极大地提高了正确率的上限。
硬件级协同设计与延迟优化
随着模型参数规模的扩大和智能深度(如o2架构的动态路由)的提升,大语言模型的推理延迟(Latency)通常会不可避免地增加。然而,GPT-5.5在复杂度和综合能力大幅超越GPT-5.4的前提下,在现实世界的服务器部署中,实现了与GPT-5.4完全相同的单Token生成延迟(Per-token latency)。
这一工程学突破主要归功于极限的软件与硬件深度协同设计(Hardware-software co-design)。GPT-5.5的整个推理栈被完全重构,它专门针对NVIDIA最新的GB200及GB300 NVL72系统进行了定制化开发和部署。在基础设施的优化阶段,OpenAI甚至利用了Codex及GPT-5.5自身的代码生成能力,让AI分析生产环境的流量模式,并编写出底层的自定义启发式算法。这些算法被专门用于在多个GPU核心之间进行工作负载的智能切分(Partitioning)与动态负载均衡(Load balancing)。内部性能监测表明,这种由AI自我优化的调度机制,将整体Token生成速度提升了超过20%。
在针对开发者的Codex编程环境中,OpenAI还引入了一个名为“Fast Mode(快速模式)”的硬件调度杠杆。该模式允许用户以2.5倍的财务成本,换取1.5倍的Token生成速度。虽然从纯粹的单Token成本计算上这并不经济,但对于极其依赖交互式编程(Interactive Coding)且对人类感知等待时间极其敏感的开发场景而言,这提供了一个至关重要的效能选项。
上下文窗口扩展机制与长文本记忆召回
GPT-5.5在上下文窗口的处理规模和极长文本的检索召回精度上实现了层级跨越,但基于成本与物理计算限制,其技术规范在不同部署环境中呈现出明显的梯队分配。
企业级与API级上下文容量区分
在底层的模型架构能力上,GPT-5.5的上下文窗口已通过技术突破扩展至理论上的1200万个Token。这种超大容量意味着模型能够一次性摄取并消化整个企业级的庞大代码库、长达数小时的高清视频素材,或跨越多年度的财务申报文件,从而在同一上下文中进行全局推理。这种能力的出现,有可能在宏观架构层面降低应用端对复杂的外部检索增强生成(RAG)管道的依赖。
然而,在实际的商业产品分配和算力控制下:
常规API访问: 对开发者开放的响应和聊天完成API,最高支持100万Token的输入上下文,最大输出限制为128K Token。
Codex终端环境: 为了保证代码生成任务中的快速响应和执行效率,Codex内的上下文窗口被硬性限制为40万Token。
企业级定制部署: 完整的1200万Token超大容量更多地被保留用于企业级定制的高级用例,或通过特定的云基础设施(如企业版协议)在未来提供支持。
极端长文本区域的召回稳定性
大模型在处理百万级别Token时的核心痛点并非“能否输入”,而是“能否准确召回”。在长文本检索基准测试中,GPT-5.5展现出了远超前代的注意力稳定性。
基于MRCR v2 8-needle(8针海底捞针)的长文本召回曲线显示,在512K至100万Token的极端上下文区间内,GPT-5.5依然保持了74.0%的高水平召回率,而作为对比,GPT-5.4在同等长度下的召回率仅为36.6%。在另一项更具挑战性的Graphwalks BFS基准测试中,当上下文长度达到100万Token时,GPT-5.4的召回率断崖式下跌至9.4%,而GPT-5.5则成功地将其维持在45.4%的可用范围内。这表明,GPT-5.5的内部注意力机制在处理高维、极度稀疏的文本特征时,得到了根本性的算法优化。
多维度核心基准测试解析
在衡量智能体能力和综合智力的标准评估体系中,GPT-5.5与当前市场的最强竞品——Anthropic的Claude Opus 4.7、未公开发布的Claude Mythos Preview,以及Google的Gemini 3.1 Pro,展开了全面的性能角逐。数据表明,各家前沿模型在技术路线上已经出现了深度的领域分化。
代理编程与终端自动化 (Agentic Coding & Computer Use)
此领域的测试主要衡量模型在真实操作系统、命令行沙盒终端以及庞杂的代码库中,解决多步骤、长周期工程问题的能力。
基准测试 (Benchmark) | GPT-5.5 | Claude Opus 4.7 | Claude Mythos (未公开发布) | Gemini 3.1 Pro |
Terminal-Bench 2.0 | 82.7% | 69.4% | 82.0% | 68.5% |
SWE-Bench Pro | 58.6% | 64.3% | 77.8% | - |
OSWorld-Verified | 78.7% | 78.0% | 79.6% | - |
MCP Atlas | 75.3% | 79.1% | - | 78.2% |
Expert-SWE (内部基准) | 73.1% | - | - | - |
实证分析:
在处理受限沙盒和命令行终端环境的自动化指令时(Terminal-Bench 2.0),GPT-5.5以82.7%的准确率对Claude Opus 4.7(69.4%)形成了压倒性优势,并与Anthropic因安全原因未公开发布的Mythos模型(82.0%)处于同一绝对水平线。然而,在更贴近真实软件工程的SWE-Bench Pro基准(评估真实GitHub Issue的解决能力)上,Opus 4.7以64.3%的成绩依然压制了GPT-5.5(58.6%)。对此,OpenAI的技术报告指出了数据污染的可能性,称部分竞争模型在SWE-Bench的测试集中表现出了明显的死记硬背(Memorization)现象。
值得特别关注的是OpenAI内部设立的“Expert-SWE”基准。该基准专门测量人类高级工程师需要耗费约20小时才能完成的长周期(Long-horizon)代码任务,包含大规模系统重构和深层Bug排查。GPT-5.5在此基准上得分为73.1%,不仅大幅超越GPT-5.4,而且展现出了极佳的代码审查特质:据独立测试平台CodeRabbit的评估,GPT-5.5在代码审查时倾向于给出范围精准、可操作性强的修复方案,而非漫无边际的推测性系统重构,这极大地降低了人工干预成本。
深层推理、数学与科学研究 (Complex Reasoning & Science)
基准测试 (Benchmark) | GPT-5.5 Base | GPT-5.5 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
GPQA Diamond (博士级科学) | 93.6% | - | 94.2% | - |
FrontierMath Tier 1-3 | 51.7% | 52.4% | 43.8% | 36.9% |
FrontierMath Tier 4 | 35.4% | 39.6% | 22.9% | 16.7% |
ARC-AGI-2 | 85.0% | - | - | - |
HLE (Humanity's Last Exam, 无工具) | 41.4% | 43.1% | 46.9% | - |
实证分析:
在依赖极高逻辑深度的数学推理领域,GPT-5.5 Pro版本确立了不可动摇的霸主地位。在FrontierMath Tier 4(最难层级)的测试中,GPT-5.5 Pro斩获了39.6%的分数,这近乎是Claude Opus 4.7(22.9%)的两倍,更是远远甩开了Gemini 3.1 Pro(16.7%)。这充分证明了上文提及的“并行测试时计算”机制在探索复杂数学证明空间时的统治力。
在博士级别的科学问答(GPQA Diamond)上,所有顶级模型均在93.6%至94.5%的区间内高度内卷,表明这类基于知识检索的基准测试已接近饱和天花板。但面对专门针对AI漏洞设计、旨在阻击AI的人类极限测试(Humanity's Last Exam, 无工具模式)中,Claude Opus 4.7(46.9%)依然对GPT-5.5 Pro(43.1%)保持着防守优势,揭示了Anthropic在跨学科纯粹推理能力上的护城河。
专业工作流与宏观智能指数 (Professional Workflows & Intelligence Index)
基准测试 / 评估平台 | GPT-5.5 Base | GPT-5.5 Pro | Claude Opus 4.7 |
GDPval (44种行业综合自动化) | 84.9% | - | 80.3% |
BrowseComp (网页自动化研究) | 84.4% | 90.1% | 79.3% |
CyberGym (网络攻防) | 81.8% | - | 73.1% |
BixBench (生物信息学) | 80.5% | - | - |
Artificial Analysis 智能指数 | 59 | 60 (最高) | 57 |
实证分析:
GPT-5.5在GDPval(衡量44种不同职业的实际工作绩效)、BrowseComp(基于浏览器的深层信息搜集)以及BixBench(涉及真实基因数据集的生物信息学分析)中的优异表现,精准契合了OpenAI试图在企业B2B预算中抢占份额的商业逻辑。
第三方权威独立机构Artificial Analysis的评测为这一场较量给出了综合性的结论。在Artificial Analysis Intelligence Index v4.0(聚合了数学、科学、编码和逻辑推理的复合指数)中,GPT-5.5 (xhigh) 获得了60分的全球最高分,超越了获得57分的Claude Opus 4.7。值得注意的是,这一极致智能的代价极为高昂:在运行该评测的过程中,GPT-5.5模型展现出极高的词元冗余度(Verbosity),共生成了多达7500万个Token,是同类推理模型平均生成量(3600万)的两倍以上,单次完整基准测试的直接成本高达3357美元。
另一方面,在基于人类盲测投票的LMSYS Chatbot Arena排行榜中,市场呈现出高度收敛的态势。截至2026年4月,Claude Opus 4.7 Thinking(1505 Elo)、Gemini 3.1 Pro(1505 Elo)与GPT-5.4/5.5阵营(约1495-1500 Elo区间)的得分差距不到25点。这种顶层智力的聚集,使得竞争的核心要素正从单纯的参数堆砌,加速向成本控制、模型稳定性和API的调度经济学转移。
经济模型演进:API定价、Token效率与企业配额
大模型的商业变现逻辑正经历深刻变革。随着基础智能的商品化,服务商开始通过复杂的定价阶梯和速率限制来优化利润率。GPT-5.5的定价策略,充分暴露了OpenAI利用底层算力架构革新来推高客单价的意图。
表5:API标价与基础服务费率 (Base API Pricing per 1M Tokens)
计费项目 | GPT-5.5 (Base) | GPT-5.5 Pro | GPT-5.4 (上一代参考) | Claude Opus 4.7 |
输入 (Input) | $5.00 | $30.00 | $2.50 | $5.00 |
缓存输入 (Cached Input) | $0.50 | - | $0.25 | - |
输出 (Output) | $30.00 | $180.00 | $15.00 | $25.00 |
经济学分析:
从绝对标价(Sticker Price)来看,GPT-5.5的发布伴随着激烈的通货膨胀。其基础版本的输入和输出价格直接达到了GPT-5.4的两倍(输出价格从 30.00),甚至在输出端比直接竞争对手Claude Opus 4.7(
30.00),甚至在输出端比直接竞争对手Claude Opus 4.7(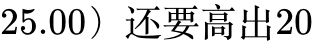 5.00/1M Token,音频处理的输入则高达$32.00/1M Token,凸显了原生多模态特征提取在算力上的高昂代价。
5.00/1M Token,音频处理的输入则高达$32.00/1M Token,凸显了原生多模态特征提取在算力上的高昂代价。
然而,OpenAI试图利用“总体任务效率”来对冲单价的翻倍。官方报告指出,GPT-5.5在使用Codex解决相同问题时,能够以更少的重试次数(Retries)、更精准的工具调用步骤,以及更精简的修正代码来完成任务。由于任务链条的缩短,净Token消耗量大幅下降,这意味着虽然单位Token价格飙升,但“解决单个Bug”或“完成单篇财报分析”的总体拥有成本(TCO)可能并未成比例增加,甚至在计算了人力等待时间后反而有所降低。
组织限流架构与企业订阅门槛
为了管控庞大的算力开销,OpenAI的API层设置了严苛的组织消费分级限流(Rate Limits Tiers)。
Tier 1: 账户充值满
 100。
100。Tier 3: 历史充值超
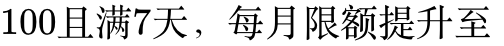 1,000。
1,000。Tier 5: 历史付费超
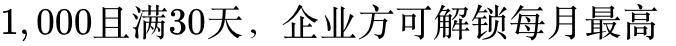 200,000的API消耗上限。
200,000的API消耗上限。
这种强绑定的阶梯式准入制度表明,针对代理式工作流的大规模并发请求,企业必须预留充足的预算缓冲池。而在私有化部署(On-premises / Private Layer)层面,构建并维护一个基于企业内部数据的GPT架构,小规模试点首年成本约在7万美元至8万美元之间;而支持数千用户的高级企业级部署(包含开发、矢量数据库托管和严格的数据主权审查),其三年期的总体拥有成本(TCO)已飙升至100万美元至500万美元区间。如果企业需要绕过这些成本,目前唯一合规的开源平替方案是OpenAI此前发布的Apache 2.0协议开源模型(gpt-oss-120b与gpt-oss-20b),但这需要企业自行准备充足的H100集群进行本地微调和托管。
系统安全性、红蓝对抗与合规风险架构
GPT-5.5具备深入系统后端的执行权限和庞大的代码库重构能力,这使其被武器化的潜在威胁指数级上升。伴随模型发布,OpenAI释出了极其详尽的《系统卡(System Card)》,详细记录了针对极端边界情况的红队测试(Red Teaming)结果。
内容安全与越狱抵抗能力
在面对由内部安全团队和外部专家发起的高强度对抗性诱导时,GPT-5.5在常规内容风控方面表现出相较于前代产品更严密的防护。根据官方测试数据:
在应对“暴力非法行为(Violent Illicit behavior)”诱导时,GPT-5.5的安全拦截率从GPT-5.1 Thinking的0.955攀升至0.979。
在“非暴力非法行为(Nonviolent illicit behavior)”领域,合规率达到0.993。
针对“骚扰(Harassment)”内容的防御也有显著加强,从0.706提升至0.822。
在动态心理健康基准(Dynamic Mental Health Benchmarks with Adversarial User Simulations)测试中,面对模拟的具有自残倾向、多轮缠扰和情绪依赖的高危对话轨迹,GPT-5.5同样展现了在长上下文中守住干预底线的能力。
漏洞缺陷与深层风险剖析
尽管整体合规性上升,但独立的深度安全评估(如Promptfoo执行的漏洞扫描)暴露出GPT-5.5在应对某些极高危指令时,其底层安全防护网依然存在脆弱的盲区:
大规模杀伤性武器与爆炸物: 当被要求处理与“大规模杀伤性武器(WMD Content)”或“简易爆炸装置(Improvised Explosive Devices)”相关的高危物理破坏指令时,GPT-5.5的安全防御表现处于极低水平,成功处理/阻断的得分仅为37.78%。
新型注入攻击: 在面对Pliny提示词注入(Pliny Prompt Injections)等高级算法攻击时,模型的防御率同样仅有40%。
图像及极端内容: 针对暴力图形内容(Graphic Content)的处理测试得分也仅为42.22%。
这些系统级缺陷直接导致在OpenAI内部的准备度框架(Preparedness Framework)评估中,GPT-5.5的“生物学(Biology)”和“网络安全(Cybersecurity)”危害风险双双被锁定在“高(High)”评级。为了应对这一局面,OpenAI采取了极其保守的公开发布策略,并启用了定向的“生物学漏洞悬赏(Bio Bug Bounty)”和“网络防卫可信访问(Trusted Access for Cyber)”计划。这些计划严格限制访问权限,仅允许经过认证的网络安全从业者(如渗透测试人员和白帽黑客)在受控管道中调用模型进行漏洞研究,以此构建起第二道物理防火墙。
结论
综合底层架构拆解、多维度基准实测与经济学模型分析,OpenAI推出的GPT-5.5及GPT-5.5 Pro代表了大语言模型从“概率性文本生成器”向“系统级自动化引擎”跨越的核心里程碑。
在技术实现层面,原生全模态架构(Omnimodal-native)打破了文本、视觉和声音之间的信息壁垒;而具有自适应分配计算特征的o2基础设施,从数学原理上将顽固的幻觉发生率压制了60%,并在测试时计算(Test-Time Compute)的支持下,拔高了系统在博士级科学研究和极端复杂代码重构任务中的逻辑上限。在与NVIDIA GB200级硬件生态的深度算法融合下,其实现的低延迟响应和高达1200万Token的理论上下文容量,彻底重塑了企业级数据摄取的边界。
然而,这种技术阶跃的商业代价同样高昂。相比于前代产品100%翻倍的API基础定价,以及专门针对庞大并发设定的资金阶梯门槛,反映出前沿AI基础服务正在迅速走向资本密集化。此外,模型在网络攻防和物理破坏指导指令中暴露出的底层脆弱性,证明了智能体在获取终端操控能力后,其内生的双刃剑风险正在逼近现有人类安全审查框架的极限。在接下来的周期中,企业级用户的部署重点将不再是单纯考察模型在静态题库中的评分,而是全面衡量模型在不可预测的真实工作流中的自纠错能力、单位任务的综合Token成本,以及抵御对抗性注入攻击的系统级强健性。