


1.概述与背景
1.1从确定论到概率论的范式转变
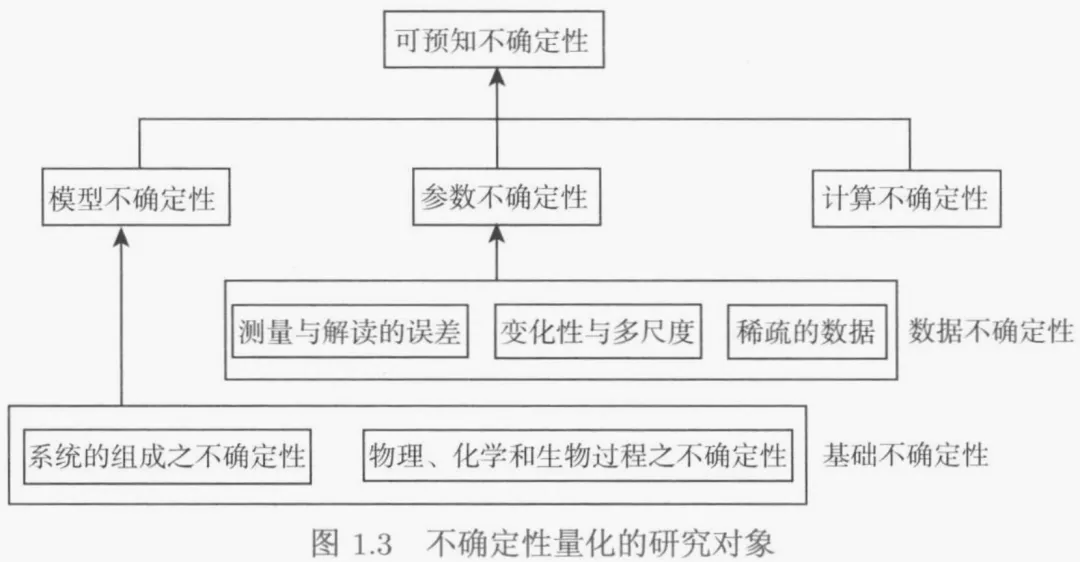
1.2. 不确定性量化(UQ)的定义与重要性
提供决策依据:为监管机构和核电站营运者提供定量的风险信息,支持安全许可、设备改造、延寿等重大决策。 优化设计与运行:在确保安全的前提下,通过更精确地了解安全裕度,优化反应堆设计,提高运行效率和经济性。 指导研发方向:通过敏感性分析(UQ的一个重要组成部分),识别出对最终结果影响最大的不确定性来源,从而指导未来的实验研究和模型开发,以最有效的方式减少认知不确定性。
1.3. UQ分析的通用流程与关键技术
1.4. 五大UQ辅助工具概览
DAKOTA:由美国桑迪亚国家实验室开发,是目前功能最全面、应用最广泛的UQ工具之一。它是一个集成了大量算法的开源工具包,涵盖了从抽样、优化、敏感性分析到模型校准的几乎所有方面。 URANIE:由法国原子能和替代能源委员会(CEA)主导开发,是一个基于ROOT框架的开源UQ平台。它在欧洲核能界,特别是与多物理场仿真平台的集成方面,扮演着重要角色。 CIRCE:同样源于法国CEA,它是一种独特且有影响力的逆向不确定性量化方法,专注于从实验数据中推断热工水力模型中经验关系式的不确定性,其方法论根植于频率主义统计学,引发了长期的学术讨论。 QUESO:由美国德克萨斯大学奥斯汀分校 Oden 计算科学与工程研究所下属的预测工程和计算科学中心(PECOS)主导开发,是一个专注于贝叶斯推断和统计反问题的C++库。它为更大型的UQ框架(如DAKOTA)提供了强大的底层贝叶斯计算能力。 PAPIRUS:这是一个为解决大规模计算问题而设计的并行计算平台,集成了不确定性和敏感性分析功能,旨在高效地连接复杂的工程模拟代码和统计分析算法。
对比维度 | QUESO | DAKOTA | PAPIRUS | CIRCE | URANIE |
开发机构 | 得克萨斯大学等 | 桑迪亚国家实验室 | 韩国原子能研究院 | 法国原子能委员会 | 法国原子能委员会 |
开放程度 | 开源 | 开源 | 机构内部 | 方法公开 | 开源 |
方法广度 | 窄(贝叶斯专用) | 极宽(全栈) | 中等 | 窄(IUQ专用) | 宽(平台化) |
方法深度 | 深(MCMC专家) | 中等 | 中等 | 深(IUQ专家) | 中等 |
正向传播 | 有限 | 极丰富 | 良好 | 不适用 | 丰富 |
逆UQ | 强(贝叶斯) | 良好 | 良好 | 极强(专用) | 良好 |
并行计算 | 强(MPI) | 良好 | 极强(专用框架) | 依赖平台 | 良好 |
代理模型 | 高斯过程 | 多方法 | 有限 | 不适用 | 极强(NN/Kriging) |
核电专用性 | 通用 | 高(广泛验证) | 极高(快堆专用) | 极高(TH IUQ) | 高(CEA全栈) |
学习曲线 | 陡峭 | 中等 | 中等 | 中等 | 平缓(GUI支持) |
社区规模 | 小 | 大 | 小 | 中 | 中 |
监管认可度 | 有限 | 高(NRC项目) | 中(韩国境内) | 高(欧洲IUQ标准) | 高(法国/欧洲) |