⏰ 全文约6200字 · 阅读需13分钟
2026年4月,大模型行业迎来史上最密集发布潮。这次不是简单的军备竞赛,而是三个梯队的路线分化。看完你就知道:大模型往哪走,谁最强,该用谁。 |
00 先说结论:三个梯队,三种未来
每次大厂发布新品,很多小伙伴都说“看不懂”。参数多少、上下文多长、MoE架构……这些技术术语把人绕晕了。
今天换个思路——先搞清楚大模型在往哪走,再看谁做了什么。
2026 年4月的这波发布潮,本质上是在三个梯队上同时发力:
? 三个梯队一览表
梯队 | 定位 | 核心方向 | 为什么重要 |
必争赛道 | 核心支柱,所有厂商必争 | ①推理效率与成本优化 ②Agent智能体推理 ③上下文长度 | “地基”,决定模型能不能用、好不好用 |
差异化赛道 | 体验升级,差异化竞争 | ④原生统一多模态 ⑤安全与对齐 ⑥领域专用大模型 | “装修”,决定模型用起来爽不爽 |
未来赛道 | 快速崛起,新增长点 | ⑦端侧大模型 ⑧世界模型 | “新赛道”,决定未来能走多远 |
01 必争赛道:核心支柱,所有厂商必争
这一赛道的三个方向,是大模型的基本功。基本功不扎实,其他都是空谈。
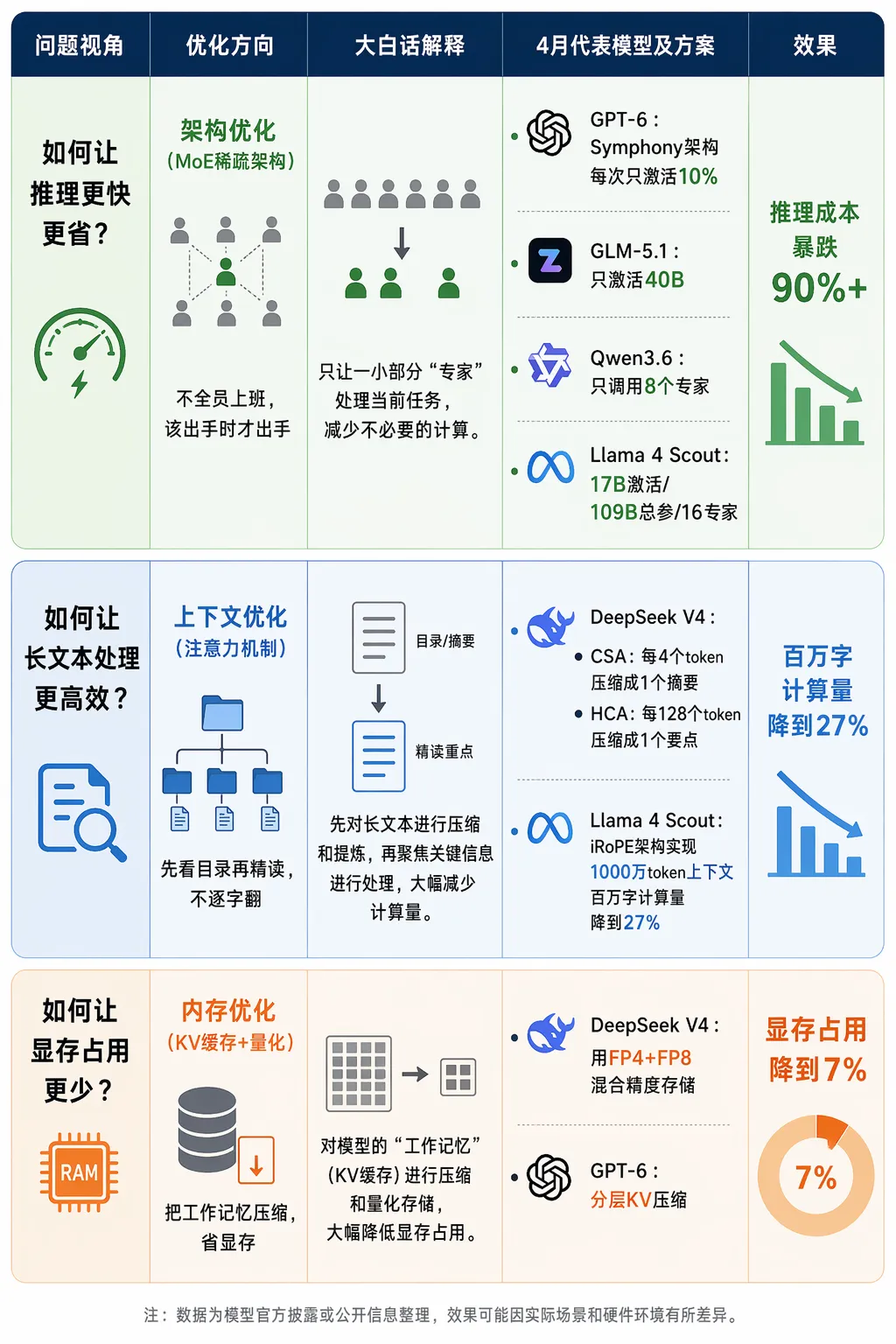
? 方向①:推理效率与成本优化——“又快又便宜”才是王道
大模型很强,但烧钱也是真的烧。4月的这波发布潮,核心主题就是:让AI“又快又便宜”。
? 方向②:Agent智能体推理——从“给建议”到“帮你干”
? 为什么重要?
大模型最初是“问答机器”——你问它答。Agent让AI从“顾问”升级为“员工”——你告诉它目标,它自己规划、自己执行、自己检查。
小白话解释:普通AI是“军师”,给你出主意;Agent是“经理”,帮你把事情干完。 |
? Agent核心能力
能力 | 说明 | 类比 |
任务规划 | 把复杂目标拆成一步步 | 像项目经理写工作分解 |
工具使用 | 调用API、搜索、代码执行 | 像助理使用各种软件 |
长链条推理 | 多步推理,不被干扰 | 像老手做复杂决策 |
自我反思 | 做完了自己检查对不对 | 像认真负责的员工 |
? 场景推荐:谁最适合Agent任务?
场景 | 首选 | 原因 |
企业级复杂Agent | GPT-6 | 91%完成率,自主工作8小时+ |
Agent自动编程 | GPT-5.5 | 自主编程能力最强,自动 debug |
开源Agent开发 | DeepSeek V4 | 性价比高,可本地部署 |
日常任务自动化 | Claude Opus 4.7 | 长上下文与编程能力双优,多轮对话与工具调用稳定性突出 |
? Agent的未来
GPT-6 能自主工作8小时,意味着什么?
意味着你可以:早上给AI布置任务“帮我把这份财报分析完”,AI自动搜索、分析、撰写,晚上回来看结果。从“AI帮我想”升级为“AI帮我做”。
预判:2026 年下半年,Agent将成为各厂商的主战场。 |
? 方向③:上下文长度——谁能读完整本书?
? 为什么重要?
大模型的“上下文”,相当于它的“记忆容量”。
上下文短,就像鱼一样只有7秒记忆——你给它一篇文章,它读一半就忘了前面写的啥。
上下文长,就能一次读完一整本书、分析几十份财报、审核几百页合同——不用分段喂,AI直接搞定。
小白话解释:上下文就是AI的“工作台大小”。工作台小,只能放一 张A4 纸;工作台大,能摊开多张 A4 纸。 |
? 核心数据对比表
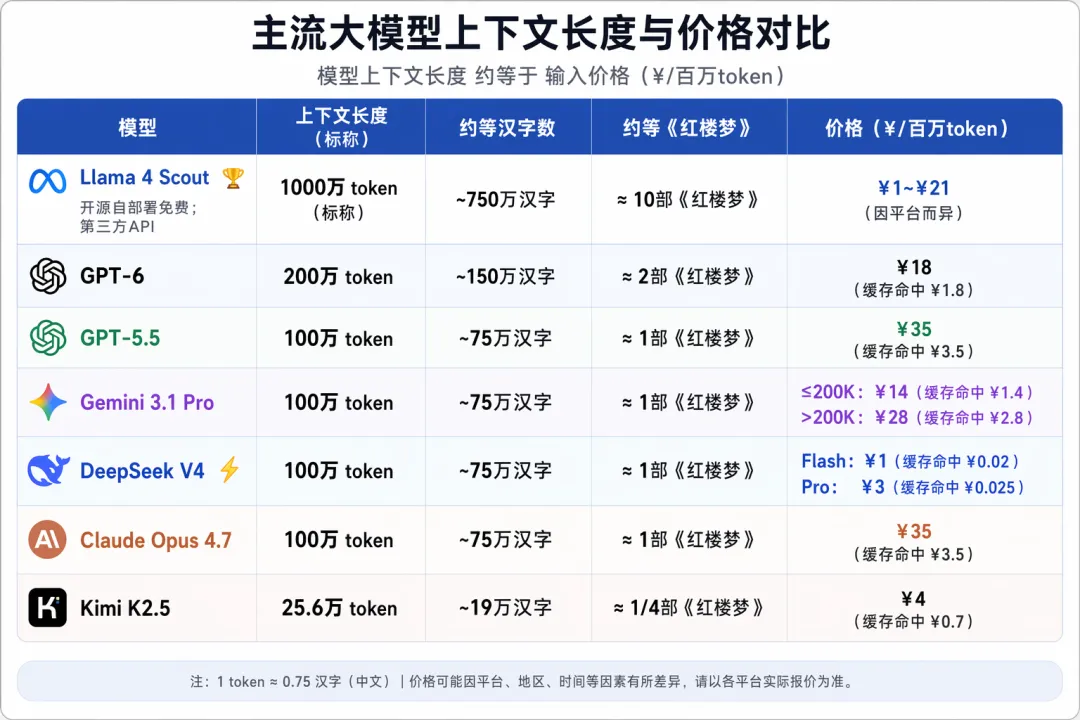
⚠️ 重要提示:不是越长越好
模型 | 标称上下文 | 实际表现 | 注意 |
Llama 4 Scout | 1000万token | 超过256K后性能衰减 | 120K文档问答准确率仅15.6% |
GPT-6 | 200万token | 召回准确率98.7% | 真能用,不是噱头 |
DeepSeek V4 | 100万token | 实测稳定 | 国产性价比之选 |
小白话有话说: 1、超长上下文选GPT-6(最稳)或DeepSeek V4(最便宜国产); 2、Llama 4 Scout的1000万token“虚标”,别被数字骗了。 |
02 差异化赛道:拉开差距的关键
必争赛道是“基本功”,差异化赛道是“拉开差距的关键”。基本功差不多的情况下,谁的体验更好,谁就赢。
? 方向④:原生统一多模态——能看图说话生成视频
? 为什么重要?
多模态 = AI不只是聊天,还能看图、听声音、生成视频。
传统多模态:文本、图像、语音是三个“部门”,各干各的,需要协调。
原生统一多模态:一个“全能选手”,文本、图像、语音、视频在同一个“大脑”里处理。
小白话解释:就像人有眼睛(视觉)、耳朵(听觉)、嘴巴(说话)——原生多模态就是让AI也有完整的感知能力,而且这些能力是“长在一起的”,不是拼凑的。 |
? 核心技术:统一向量空间
GPT-6的Symphony架构,把文本、图像、音频、视频映射到同一个“向量空间”——就像把不同语言翻译成同一种“世界语”,模型能理解它们之间的关联。
? 多模态能力对比表
模型/产品 | 看图理解 | 语音对话 | 视频生成 | 统一架构 |
GPT-6 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ✅ 原生统一 |
Claude Opus 4.7 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ❌ | ❌ |
可灵3.0(快手) | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ |
Seeduplex(字节) | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ | ❌ |
豆包(字节) | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | ❌ |
DeepSeek V4 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ❌ | ❌ |
? 重点产品解析
可灵3.0(快手):AI生成视频直接从4K高清起步,不用后期放大;行业首创“角色锁定”功能,主角不会中途“变脸”。适合:短视频创作者、电商卖家。
Seeduplex(字节跳动):AI语音从“对讲机模式”升级为“打电话模式”,可以边听边说、随时打断,像跟真人聊天。对话流畅度提升12%,已全量上线豆包App。
GPT-6:Symphony架构——文本、图像、音频、视频在同一向量空间处理。不再需要切换插件,一个模型搞定所有。
? 应用场景推荐
场景 | 推荐产品 | 原因 |
生成短视频 | 可灵3.0(快手) | 4K高清,角色锁定不“变脸” |
对话式语音助手 | Seeduplex(豆包) | 全双工语音,边听边说随时打断 |
看图理解、分析截图 | Claude Opus 4.7 | 看图能力最强,3倍提升 |
生成配图、海报 | 豆包 | 免费、中文理解好、生成快 |
综合多模态体验 | GPT-6 | 原生统一,文本/图像/音频/视频一个模型搞定 |
?️ 方向⑤:安全与对齐——让AI“听话”
? 为什么重要?
AI很强大,但如果不听指挥,反而会带来风险。
安全与对齐就是让AI:知道什么该做、什么不该做;不会好心办坏事;符合人类价值观。
小白话解释:就像教育孩子,光聪明不够,还要“听话”、有礼貌、守规矩。安全与对齐就是给AI“立规矩”。 |
⚡ 为什么在2026年特别重要?
2026 年,AI开始进入Agent时代——AI不再只是给建议,而是自己动手干。

自己能干活,就意味着:如果AI理解错了你的意图,可能做出错误的行动;
如果AI被“诱导”,可能绕过安全限制;
如果AI的价值观和人类不一致,后果可能很严重。
? 安全能力对比表
模型 | 安全评测 | 对齐技术 | 特点 |
Claude Opus 4.7 | 极高 | Constitutional AI | 最安全,强调“无害” |
GPT-6 | 高 | RLHF+红队测试 | 能力强,安全也不差 |
DeepSeek V4 | 中高 | 改进RLHF | 性价比优先 |
Llama 4 | 中 | RLHF | 开源模型安全有挑战 |
Gemini 3.1 | 高 | 内置安全层 | Google安全积累 |
⚙️ 核心安全技术解释
技术 | 说明 | 类比 |
RLHF(人类反馈强化学习) | 让人来教AI什么好、什么不好 | 像教练训练运动员 |
Constitutional AI | 用一套“宪法”来约束AI行为 | 像法律约束人的行为 |
红队测试 | 专门有人试图“攻击”AI找漏洞 | 像安全公司测试系统 |
⚠️ 安全不是绝对的:再安全的AI也有被“越狱”的可能;开源模型的安全完全依赖部署者;Agent时代的“安全”比聊天时代更复杂。 |
小白话建议:涉及高风险决策(医疗、法律、金融)的场景,一定要有人工监督,不要完全交给AI。 |
? 方向⑥:领域专用大模型——垂直赛道的“专科医生”
? 为什么重要?
通用大模型像“全科医生”——什么都会,但不一定什么都精。
领域专用大模型像“专科医生”——专门研究一个领域,在这个领域比全科医生强很多。
领域 | 专用模型优势 | 代表产品 |
医疗 | 医学术语、病历理解、诊断辅助 | 医疗大模型 |
金融 | 财报分析、风险评估、量化交易 | 金融大模型 |
法律 | 法条检索、合同审核、案例分析 | 法律大模型 |
代码 | 代码生成、bug修复、代码解释 | 编程大模型 |
? 商业化最成功:代码领域
Claude Code年收入已达25亿美元,直接推动Anthropic年收入突破300亿美元、超越OpenAI。
这说明一件事:垂直领域专用模型,是真正能赚钱的方向。 |
? 核心数据对比表
模型 | 领域 | SWE-bench | 特点 |
Claude Opus 4.7 | 编程 | Pro: 64.3% ? Verified: 87.6% | 最难代码任务最强 |
GPT-5.5 | 编程 | Pro: 58.6% Verified: 84.2% | Agent编程最强 |
DeepSeek V4 | 编程 | Verified: 83.7% | 开源最高分 |
GLM-5.1 | 编程 | Pro: 58.4% Verified: 77.8% | 国产编程top选手 |
?场景推荐
场景 | 首选 | 原因 |
企业级复杂编程 | Claude Opus 4.7 | 编程领域的“专科医生” |
开源编程,免费使用 | DeepSeek V4 | Codeforces3206分,开源最高 |
Agent自动编程 | GPT-5.5 | 能自主 debug |
国产 Top | GLM-5.1 | 编程超越GPT-5.4,首发适配华为芯片 |
03 未来赛道:快速崛起,新增长点
必争赛道是“基本功”,差异化赛道是“差异化”,未来赛道是“新赛道”。现在入场,可能决定未来5-10年的格局。
? 方向⑦:端侧大模型——手机电脑汽车都能跑
? 为什么重要?
大模型虽强,但以前必须在“云端”运行——你问问题,数据传到服务器,服务器回答,再传回来。
端侧大模型让AI直接跑在你的手机、电脑、汽车里:不用联网,隐私更安全;响应更快,不用等服务器;离线也能用。
小白话解释:就像以前要听歌必须去KTV,现在手机里就能存几万首歌。端侧AI就是“把AI装进口袋”。 |
? 端侧大模型对比表
模型 | 参数量 | 运行设备 | 能力 | 代表产品 |
Apple Intelligence | 30亿(3B) | iPhone/Mac | 日常任务 | 苹果设备 |
Gemini Nano | 手机 | 基础AI功能 | 安卓旗舰 | |
Phi-4-mini(微软) | 38亿(3.8B) | 手机/电脑 | 轻量高效 | Windows |
Qwen2.5-0.5B | 5亿 | 嵌入式设备 | 超轻量 | 物联网 |
DeepSeek-Coder-V2-Lite | 电脑(需GPU或≥16GB内存) | 编程辅助 | 开发者 |
? 为什么2026年是端侧元年?
因素 | 说明 |
芯片进化 | 手机芯片(苹果A系列、骁龙8 Gen)已能流畅跑百亿参数模型 |
模型压缩 | INT4量化让大模型缩小4-8倍,效果损失小 |
隐私需求 | 用户越来越在意敏感数据不上传云端 |
离线需求 | 汽车(隧道/地库断网等)、医疗、野外作业场景需要离线AI,响应延迟低 |
? 应用场景
场景 | 端侧优势 | 代表产品 |
手机助手 | 隐私保护、离线可用 | Apple Intelligence |
车载AI | 离线导航、语音控制 | 汽车智能座舱 |
工业设备 | 边缘计算、实时响应 | 工厂质检 |
智能穿戴 | 低功耗、常驻运行 | 智能手表 |
⚠️ 端侧的局限性:端侧模型能力比云端弱约 15-30%;手机散热、续航限制持续运行;部分复杂任务仍需云端。 |
? 方向⑧:世界模型——理解物理世界的动态
? 为什么重要?
当前的大模型主要是“语言模型”——它懂文字,但不懂物理世界。
世界模型(World Model)让AI理解:物体怎么移动;力、因果关系是什么;“常识物理”是什么。
比如:把杯子放在桌边,AI能预测它会不会掉下来。
比如:推一下球,AI知道它会滚到哪里停。
小白话解释:现在的AI像“纸上谈兵的军师”——懂很多知识,但不理解真实世界。世界模型让AI变成“有实地经验的将军”。 |
⚖️ 世界模型 vs 传统大模型
对比 | 传统大模型 | 世界模型 |
理解方式 | 文字、符号 | 物理、动态 |
知识来源 | 互联网文本 | 视频、物理交互 |
预测能力 | 文字接龙 | 物理预测 |
擅长能力 | 聊天、写文案、查资料、写简单代码 | 机器人、自动驾驶、游戏AI、数字孪生 |
?4 月代表进展
| 项目名称 | 所属机构 | 核心进展 |
| FSD v14 | Tesla | 端到端自研世界模型, 精准预测场景演变; |
| Omniverse ACE 2.0 | NVIDIA | 实时数字人+可交互世界模型深度融合 |
| HY-World 2.0 | 腾讯 | 多模态输入一键生成可编辑3D世界 |
| Happy Oyster | 阿里巴巴 | 实时构建可交互、可演绎的AI数字世界 |
| Kairos 3.0-4B | 商汤/大晓机器人 | 全流程适配华为昇腾等国产芯片 |
| GE-Sim 2.0 | 智元机器人 | 专注机器人操控数据合成 |
? 未来应用场景
场景 | 世界模型的作用 |
机器人 | 让机器人理解物理世界,执行复杂任务 |
自动驾驶 | 预测行人、车辆行为,提高安全性 |
游戏NPC | NPC有“常识”,行为更真实 |
科学仿真 | 模拟物理、化学实验 |
⚠️ 距离实用还有距离:世界模型目前主要停留在“视频生成”阶段;真正的“物理世界理解”还在早期;算力需求巨大,训练成本极高。 |
04 国内外PK:两种路线,一个舞台
看完三个梯队,很多读者会问:中国AI和美国AI,到底谁更强?
说实话,这个问题本身就是“伪命题”。因为两边的玩法,根本不是一回事儿。
⚖️ 两种路线对比
维度 | 美国玩家 | 中国玩家 |
追求目标 | AGI,让AI像人一样思考 | 产业AI化,让AI渗透到每个场景 |
商业模式 | API订阅+SaaS工具,靠“帮你赚钱”收费 | 云服务+生态变现,靠“帮你省钱/省事”收费 |
竞争焦点 | 模型能力有多强,技术有多前沿 | 场景渗透有多深,成本有多低 |
典型代表 | OpenAI、Anthropic——做“工具” | 字节、阿里、腾讯——做“入口” |
?? 美国在“卷智商”
硅谷的逻辑:我比你聪明10%-30%,所以你必须为我付费。
Claude Opus 4.7编程能力全球最强。
GPT-6追求“通往AGI的最后一公里”。
Google Gemini做“最灵活的大模型”。
他们靠的是:做生产力工具,用户为“AI帮我赚钱”付费。
?? 中国在“卷路子”
中国的逻辑:不追求AI“最聪明”,而是“最有用”、“最便宜”、“最普及”。
豆包4月上线“帮你选”购物功能,打通抖音电商——这是电商超级入口。
元宝依托微信社交关系链——这是社交生态插件。
千问嵌入阿里云服务——这是云服务粘合剂。
他们靠的是:AI渗透场景,生态锁住用户。
? 谁更强?
维度 | 美国 | 中国 |
技术巅峰 | ✅ 仍领先(Claude编程、GPT推理) | 正在追赶 |
落地规模 | ❌ 增长放缓 | ✅ 2026年4月中国调用量是美国的4倍 |
价格 | 较贵($2.5-35/百万token) | ✅ 碾压(0.2-4元/百万token) |
生态渗透 | 较弱 | ✅ 强(电商、社交、云服务) |
结论:技术巅峰看美国,落地普及看中国。两种路线没有对错,只有适合不适合。 |
05 普通人选择指南:谁最强?用谁最值?
扒完这波发布潮,很多朋友问我:“这么多大模型,我到底该用哪个?”
今天不聊技术,给你一个直接能用的选择指南。
✅ 一句话总结版
需求 | 首选 | 备选 | 价格 | 说明 |
日常聊天、问问题 | 豆包 | Kimi | 免费 | 响应快、中文好 |
写文章、做文案 | 千问/豆包 | — | 免费 | 中文写作流畅 |
写代码、调试bug | Claude或DeepSeek | — | DeepSeek更便宜 | 各有所长 |
看长文档、总结PDF | DeepSeek或Kimi | — | DeepSeek更便宜 | 都有长上下文 |
英文写作、翻译 | Claude | GPT | 两者都较贵 | Claude英文更地道 |
做PPT、写报告 | 豆包/千问 | — | 免费 | 有模板可用 |
学术研究、论文润色 | Claude | GPT | 较贵 | 推理能力强 |
生成视频 | 可灵3.0 | — | 付费 | 4K高清不“变脸” |
语音对话助手 | 豆包 | Seeduplex | 免费 | 边听边说随时打断 |
注意:以上只是粗略推荐,实际选择要看具体需求和预算,没有标准答案。
? 小白话的建议
不要纠结谁最强——没有绝对的最强,只有最适合。
日常使用免费的完全够——豆包、千问、Kimi三选一即可。 编程追求性价比选DeepSeek——便宜,开源,够用。 英文任务需要专业模型——Claude/GPT在这方面确实更强。 复杂任务可以组合使用——没有万能模型,混合使用效果更好。
最好的模型不是最强的那个,而是最适合你需求+预算的那个。 |
07 下半年预判:行业会怎么走?
基于4月发布潮的分析,来判断一下下半年的趋势:
? 预判1:Agent将成为主战场
GPT-6 Agent任务完成率91%、GPT-5.5能自主工作8小时……各家都在布局Agent。
下半年会看到更多Agent产品落地,从“AI聊天”升级为“AI干活”——你告诉AI你要做什么,它帮你完成,而不是只给你建议。
⚔️ 预判2:开源与闭源的博弈进入深水区
Llama 4、GLM-5.1、DeepSeek V4、混元Hy3已经证明了开源模型可以与闭源模型正面竞争。
下半年,闭源厂商将面临更大的价格压力,必须在“差异化能力”和“服务质量”上构建护城河。
? 预判3:垂直场景加速分化
Anthropic靠“聚焦编程场景”实现收入反超,已经证明了这条路的可行性。
“有没有用”比“强不强”更重要。下半年,能够在垂直场景(编程、法律、医疗、金融)真正解决企业问题的厂商,将获得商业回报。
? 预判4:国产算力崛起加速
DeepSeek V4适配华为昇腾,寒武纪、昇腾等8大国产AI芯片完成首发适配……国产算力的可用性已经得到验证。
下半年,更多企业将选择国产算力,“卡脖子”的困境正在被逐步破解。
? 预判5:行业整合加速
麦肯锡数据显示,仅6%的企业AI项目真正成功。
80%以上的中小厂商可能无法独立存活。下半年,行业整合将加速,市场将进一步向头部集中。
08 写在最后
扒完2026年4月这波发布潮,我有一个非常清晰的感受:
大模型行业正在从“技术竞赛”转向“生态博弈”。
过去三年,大家比的是“谁家的模型更强”;未来三年,大家要比的是“谁家的生态更稳”。
Meta守着Llama的开源生态,Anthropic在编程垂直场景称王,Google在混合推理上差异化突围,xAI用万亿参数叫板。
腾讯借姚顺雨的首秀重新杀入战局,阿里用开源生态撬动开发者,字节用场景驱动和语音革命占据流量入口,DeepSeek用技术理想主义证明“中国也能做顶级模型”,智谱和MiniMax在国产开源和性价比上各自精彩……
每个玩家都有自己的路,没有标准答案。
唯一确定的是:这场竞赛才刚刚开始,远没有到终局。
继续期待蹲下一个惊喜吧~
如果觉得有收获,欢迎关注「AI小白话」,把复杂的AI聊成你能听懂的话。