



近日,全球知名科技市场研究机构 Omdia 正式发布了一份重磅行业报告——《Rethinking Critical AI Infrastructure》。这份报告由苹果公司委托制作,基于对全球1500 余位企业技术决策者(CIO、CTO、AI 负责人等)的深度调研,是近一年来 覆盖样本最广 的一份企业级 AI 基础设施研究。
过去两年,关于 AI ,主流的叙事几乎全是“云端”和“千亿参数大模型”。但 Omdia 这份报告,用一组组硬数据,把企业内部那些没被讲出来的“真实故事”摆到了台面上——安全焦虑、成本失控、工作负载错配,正在让越来越多企业悄悄把目光投向“端侧”。正是这三个维度,构成了端侧 AI 的核心优势——通过架构层面的设计,它能够解决企业在安全、经济和工作负载上的挑战。
以下是报告重点内容的解读。

端侧成为企业 AI 布局新考量
AI 基础设施在过去几年发生的最大变化,不是算力,而是企业开始重新思考“算力应该放在哪里”。Omdia 的调研揭露了一个事实:纯云端方案,正在大量企业里遇到瓶颈。
01混合部署已成主流
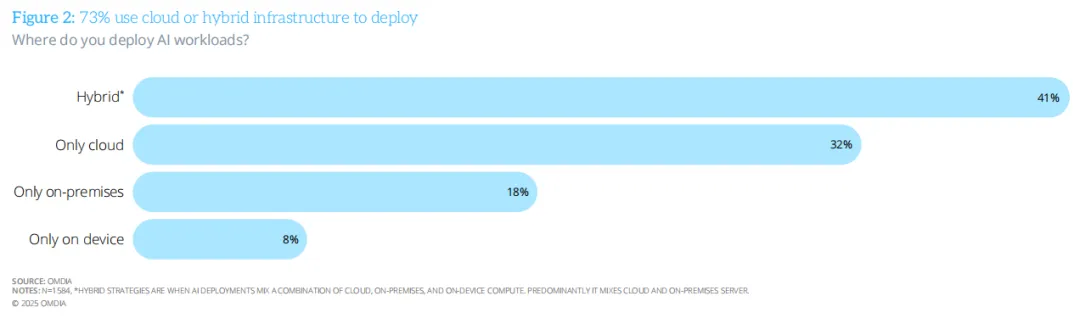

报告显示,41% 的企业已经采用“云 + 本地 + 端侧”的混合部署策略,32% 仅使用云端,18% 仅使用本地,8% 仅使用端侧。
而且AI 成熟度越高的企业,混合部署的比例越高——已规模化部署 AI 的企业中,约一半采用混合策略;而仍处于试点阶段的企业,这一比例约为三分之一。
02 企业对现有云服务商的满意度并不高

Omdia 给出了一个让不少云厂商有点难堪的数字:只有 9% 的企业认为他们当前的战略 AI 合作伙伴“没有明显短板”。最主要的三个不满项分别是:
数据隐私与安全控制不足(32%)
不可预测或持续高昂的成本(32%)
与现有系统集成不佳(28%)
这三件事加在一起,几乎构成了企业 AI 落地的“三座大山”。
03 向端侧迁移的明确意图

超过三分之一的企业明确表示,将在未来 12 个月内把更多 AI 工作负载迁移到端侧设备。按当前主要部署方式划分:
已使用端侧的企业中,有 65% 计划进一步加大端侧投入
使用本地部署的企业中,有 51% 计划新增端侧能力
使用混合策略的企业中,有 33% 计划继续向端侧倾斜,
仅使用云端的企业中,有 26% 计划向端侧迁移。

值得注意的是,Omdia 在这一章节强调了一个常被忽略的“成本可见性偏差”——72% 的企业紧盯每月的云账单,但不到 50% 的企业系统追踪过安全合规、人力审计、流程延迟等隐性成本。也就是说,企业在做 TCO 评估时,往往低估了端侧的价值。

安全性——从流程合规到架构级隐私
报告中有两个数字值得玩味:
99% 的企业 在 AI 工作流中处理专有或敏感数据;
76% 的企业 对通过云服务造成的数据泄露表达了明确担忧。


不是企业不信任云厂商。云厂商的安全工程能力,大概率比 99% 的企业自建机房都要强。真正的问题是:AI 让“数据传输”从一次性动作,变成了持续动作。
过去把数据搬上云,是一次性的合规决策。但 AI 应用意味着用户的每一次提问、每一份上传、每一次工具调用,都在持续地把企业内部数据往外送。
Omdia 用了一个非常精准的概念来形容端侧的优势——架构级隐私(architectural privacy)。它的逻辑朴素但是有力:没有传输,就没有需要管理的传输风险。
开发团队可以直接在本地数据集上⼯作,⽆需访问第三⽅基础设施。模型在数据所在位置进⾏训练,从⽽⽆需承担数据传输成本,⽆需验证传输加密,⽆需审计云服务提供商的控制措施,也⽆需处理跨境数据传输的相关⽂件。
同时,借助端侧 AI,开发团队可以在本地使⽤⼈⼯智能⼯具来加快清理和准备过程,利⽤模型识别敏感字段、⾃动进⾏数据遮蔽、验证数据质量以及转换数据集,所有这些操作都在数据离开安全环境之前完成。
这不是“更好的安全”,而是“不再需要这部分安全管理”。两者是完全不同的范畴。

经济性——「实验税」与失控的推理账单
报告在这一章节里使用了一个概念,叫做“Experimentation Tax(实验税)”。
01 被默默缴纳的“实验税”

在云端做 AI 开发,每一次失败的实验和成功的实验一样,都会从计算时间、数据传输和存储⽅⾯累积费⽤。久而久之,研发团队会下意识地“少做实验”。
报告一针见血地指出:这本质上是对创新的打压。AI 研发与传统软件开发最大的不同,恰恰在于它对“试错密度”的要求高得离谱。试错被压制,迭代速度被压制,产品天花板就被压制。
而端侧开发把这个变量重新放开了——硬件是沉没成本,硬件部署完成后,每次迭代、测试运⾏和验证周期都不再产⽣额外成本,跑一百次实验还是跑一次实验的钱。
02 推理成本的“线性诅咒”
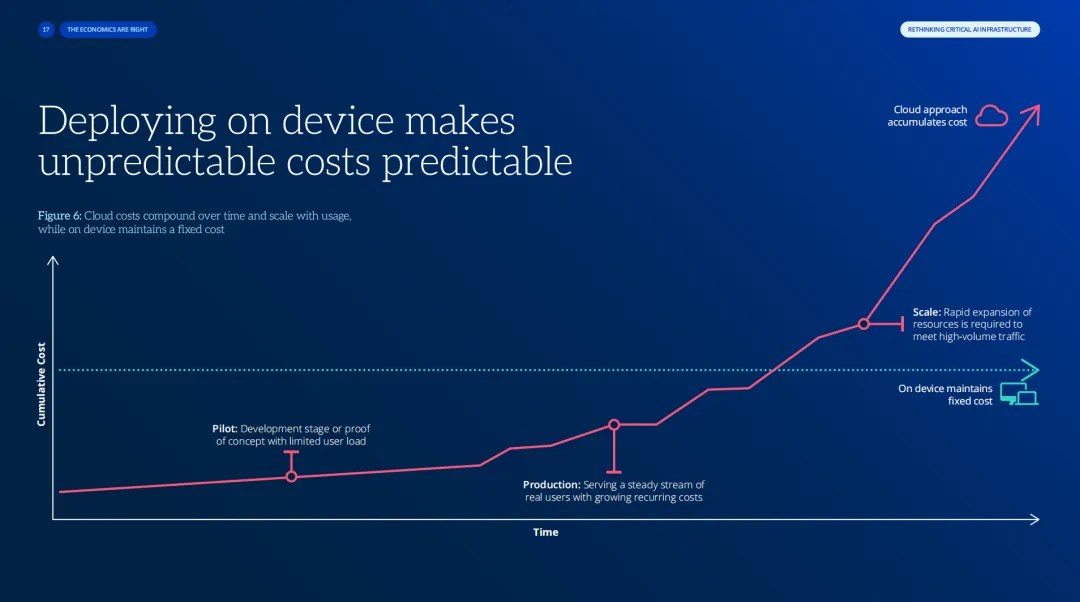
云端 API 调用成本随用户量线性增长——一个 AI 应用越成功,钱花的越多。
而端侧推理的成本是 确定的:调用一万次还是一百万次,硬件成本不变。端侧使不可预测的成本变得可预测。
03 利用模式的差别

基于云的⼈⼯智能主要遵循两种定价模式:按每次 API 调⽤收费,这种收费会随着每次请求⽽累积;或者按席位订阅收费,这种收费⽆论使⽤强度如何都保持固定。这两种模式都会带来经济上的挑战,随着时间的推移会增加成本。
更让人肉痛的是订阅模式中的浪费:如果 1000 个云 AI 许可证以每个⽤户每⽉ 30 美元的价格出售,哪怕仅有 10%未被使⽤,那么每⽉就是 3000 美元被浪费了。
报告显示,62% 的企业对终端用户的 AI 工具采纳情况并不满意,大量被采购的云端席位长期处于闲置状态。
而对端侧 AI 来说,即便 AI 负载不高,设备本身仍然是生产力工具,永远不会被迫成为“闲置资产”。

工作负载有效性——被神化的「巨型模型」
整份报告里,最值得一看的数据是这个:
57% 的企业,实际部署的 AI 模型参数量低于 100 亿。

过去几年,整个舆论场都在追“更大”——千亿、万亿、十万亿,仿佛参数量与“AI 能力”之间存在简单的线性关系。但企业用脚投票的结果是:一多半的真实部署,连百亿都不到。
这中间的落差,藏着一个被很多人忽略的事实——前沿研究和产业落地,正在走两条不同的曲线。前沿曲线追求“能力上限”,产业曲线追求“价值闭环”。两条曲线在 AI 早期是重合的,但当能力扩散到一定程度,它们开始分叉。企业不再需要“地表最强”,而是需要“够用、可控、便宜、安全”。
而百亿参数,恰好是现代高端端侧设备能够轻松承载的区间。报告指出,一个 100 亿参数模型经 8-bit 量化后约需 10-12GB 内存,对于配备 16GB 或 24GB 甚至更高内存的现代 PC 与工作站,绰绰有余。
统一内存架构:被低估的硬件变量

报告中还有一段干货,是关于Unified Memory Architecture(统一内存架构)的论述。这一架构(典型代表为 Apple Silicon)让 CPU 和 GPU 共享同一个大内存池,用空间换了拓扑复杂度。一台配备 128GB 统一内存的笔记本电脑,理论上可以本地运行经过量化的 700 亿甚至千亿参数大模型。
这件事的意义,远超“端侧能跑大模型”这一个结论。它实际上提示了一个更大的可能性——未来的推理硬件,未必都长成“GPU + HBM”的样子。当模型权重越来越大、推理越来越成为主要负载,“大内存 + 中等算力”的架构,可能会从另类选项变成主流选项之一。
报告中还有一个反直觉的发现,特别值得注意:

已经在使用端侧 AI 的企业,部署 1000 亿参数以上模型的概率,接近其他企业的两倍。
换句话说——端侧不是装不下大模型,而是有了端侧能力的企业,反而更敢用大模型。

混合智能——未来的标准答案
强调端侧的价值,不是要与云端二元对立。Omdia 在结论部分明确指出:未来的企业 AI 架构,必然是混合式的。
云端——承载超大规模训练、公共 API 服务、需要海量弹性算力的任务;
企业内部集群——处理批量数据加工、私有模型训练等中重量级负载;
端侧设备——承担高频、低延迟、高隐私要求的个性化推理与开发调试。

一个典型的未来工作流可能是这样的:在端侧工作站上用本地数据快速原型设计与微调;调用云端或内部集群完成最终的大规模训练;将优化后的模型部署回成千上万员工的端侧设备,进行安全、低成本的日常推理。
报告也在结论部分给出了四条明确建议:
一、让基础设施与工作负载相匹配
强制基于“模型大小、数据敏感度、使用模式、用户需求”做工作负载-基础设施对齐。研究前沿模型的研究员与部署 10B 以下模型的多数企业的最优基础设施完全不同;开发阶段与生产阶段的需求也不同。要警惕“一刀切”的默认基础设施选择。
二、在可能的地方,用架构解决安全问题
对于涉及专有或敏感信息的项目,应优先评估那些通过架构(而非流程)来消除传输风险的方案。端侧不是唯一答案,但对于开发流程和小模型推理而言,它能消除一整类合规审查与流程延迟。
三、让不可预测的成本变得可预测
将 TCO 的衡量范围扩展到容易被忽略的区域——安全审查延迟、合规开销、资源约束对生产力的影响、按使用量计费下的实验边际成本。企业总会优化它能测量的东西,不完整的成本可见性,必然导致次优的基础设施决策。
四、赋能技术团队构建混合方案
让自研团队拥有引入多种基础设施类型的自由。做最复杂 AI 工作的团队,本来就在构建混合组合。采购框架与技术政策应该支持而非限制这种战略多元化。

写在最后
可以看出,Omdia 的这份报告不是要否定云端,而是要强调一个被舆论简化的真相——
AI 基础设施的最优解,不是“全云”或“全端”,而是让每一种工作负载跑在最合适的地方。
调研中那些已经在端侧建立能力的企业,并没有放弃云端,他们只是发现——当端侧能力足够强大时,云端能被用得更聪明、本地集群能被用得更专注、开发节奏能被释放得更彻底。
随着 AI 能力持续演进、工作负载模式不断变化,那些今天就建立起基础设施灵活性的企业,将在未来收获复利。
谁能更早地意识到这一点,谁就能更早地省心提效。
参考文献:
Omdia, 《Rethinking Critical AI Infrastructure: How on-device infrastructure is emerging as a platform for enterprise AI development and deployment》
➤ 欢迎加入 OpenBMB 社区:


