


点击蓝字
关注我们
昨天下午 DeepSeek-V4 预览版的正式上线与开源,笔者也是第一时间进行了体验。上线过程中,同步公布了长达58页的DeepSeek-V4 技术报告,笔者在仔细阅读过后,和大家深入谈谈本次的几点变化。技术报告原文链接供大家阅读:
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
一、 先来说说体验
笔者日常对大模型的使用除了网页端外,还通过阿里的百炼平台进行API调用,昨天上线后笔者也是第一时间从两个渠道都进行了测试,首先要明确的是,V4仍然是一个纯文本模型,暂不支持原生的多模态能力。体验下来,笔者总结出下面几点大家在使用上会感觉到的变化。
经济性突出: 如上图所示,deepseek的V4的两个版本都已经上线阿里百炼,在原程序中通过修改 model_name 为 deepseek-v4-pro 或 deepseek-v4-flash 即可调用。目前价格非常有优势,特别是flash版本,非常适合我这种每天用AI进行非复杂问题处理的用户。可惜的是目前百炼平台没有提供免费额度,让笔者白嫖失败。
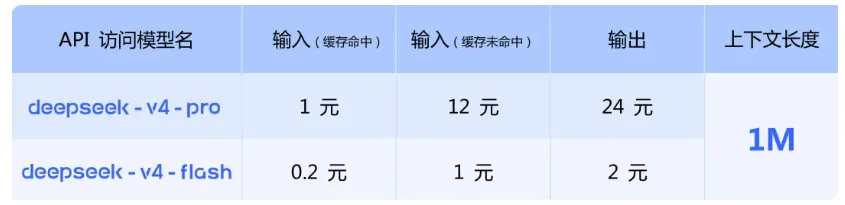
1M 上下文成为“无感标配”: 无论是成册的学术文献、超长财报,还是整个项目的代码库,系统处理将不再受制于长度报错与重度卡顿,超大规模信息处理走向日常化。这也代表Deepseek加入了Gemini、Claude Opus和Kimi,进入超长上下文处理大模型中的第一阵营。 首字响应时间(TTFT)大幅缩短: 借助“快速指令”机制,模型在处理意图识别、搜索判断等前置任务时实现瞬时并行并发,交互响应速度显著加快。 多轮长程对话“连贯如一”: “交错思考”能力赋予了模型跨轮对话的逻辑连贯性。在复杂的编程迭代或长期 Agent 任务中,模型不再“失忆”,能够始终保持一致的推理上下文。 总的来说,笔者认为它在开源阵营中确立了无可争议的新标杆,但在绝对性能的峰值上,并未对行业最顶尖的闭源巨头形成全方位的绝对领先,主要优势还是体现在长上下文处理的性价比上。
二、Pro 与 Flash 有什么不一样
根据技术报告,为满足多层次的计算需求,V4 系列采用了“同架构、异构型”的双线策略,两者均基于 Multi-Token Prediction(MTP)和 DeepSeekMoE 架构构建:
DeepSeek-V4-Pro(性能优先): 拥有 1.6T(万亿) 总参数,单 Token 激活参数为 49B,共 61 层网络。作为性能的集大成者,其在 Agent 能力、世界知识和复杂推理上均达到当前开源模型的巅峰,并在多项核心评测中比肩甚至超越 GPT-5.4、Gemini-3.1-Pro 及 Claude Opus 4.6 等顶尖闭源模型。 DeepSeek-V4-Flash(效能先锋): 拥有 284B 总参数,单 Token 激活参数仅为 13B,共 43 层网络。该版本以极高的能效比为核心,在提供与 Pro 版本接近的推理能力的同时,其 1M 上下文场景下的单 Token 推理计算量(FLOPs)仅为 V3.2 的 10%,是构建低成本、高并发应用的首选。
三、 上下文长度到底怎么提高的
针对 1M Token 上下文带来的算力与显存二次方爆炸问题,V4 引入了三项关键性的架构创新,从而确立了其极高的长序列处理效率:
混合注意力机制(CSA + HCA): V4 摒弃了全局密集注意力机制,创新性地将压缩稀疏注意力(CSA)与重度压缩注意力(HCA)交替部署。CSA 通过时间维度压缩与闪电索引器(Lightning Indexer)实现稀疏注意力计算;HCA 则进行更激进的序列压缩。为弥补压缩带来的局部信息折损,模型额外引入了滑动窗口注意力(SWA)分支以保留局部强依赖。 流形约束超连接(mHC): 针对超深层网络的数值不稳定性,V4 采用 mHC(Manifold-Constrained Hyper-Connections)增强了残差连接。借助 Sinkhorn-Knopp 算法,mHC 将残差映射矩阵严格约束在双随机矩阵流形上,确保了层间信号变换的非膨胀性(Non-expansive),从根本上解决了梯度爆炸与信号失真难题。 FP4 量化感知训练(QAT): V4 在 MoE 专家权重及 CSA 索引器的计算路径中全面引入 FP4 精度。在训练阶段,利用 FP8 与 FP4 指数位的差异实现了无损反量化,使得模型能够复用现有 FP8 混合精度框架,同时在推理端实现显存占用与访存带宽的大幅削减。
四、 万亿参数训练有何创新?
在模型的预训练与后训练阶段,DeepSeek 团队实际上攻克了很多难题,笔者这里列举几个比较有特点的:
全词表同轨蒸馏(Full-Vocabulary OPD): 在后训练阶段,V4 以同轨蒸馏(On-Policy Distillation)取代了传统的强化学习(RL)混合训练。通过预先训练数十个领域专家模型,统一的学生模型在生成轨迹时实时拟合专家的输出概率分布。为解决显存瓶颈,团队首创了“隐状态缓存”机制,实现了极其高效的全词表 Logits 蒸馏,确保了知识的无损继承。 生成式奖励模型(GRM): 面对难以验证的复杂任务,V4 摒弃了传统的标量奖励模型网络,使生成模型(Actor)原生兼任奖励模型(GRM)。这种将评估与生成能力统一的范式,极大地降低了对人类标注数据的依赖,提升了对齐效率。 训练稳定性控制: 针对万亿 MoE 模型频发的 Loss 尖峰,V4 采取了预测路由(Anticipatory Routing)与 SwiGLU 截断(Clamping)两大机制。前者通过解耦主干网络与路由网络更新,打破了错误路由的恶性循环;后者则在物理算子层面强行压制了异常值(Outliers)。
五、 Agent方面怎么优化的
DeepSeek-V4 针对 Claude Code 、OpenClaw、OpenCode、CodeBuddy 等主流的 Agent 产品进行了适配和优化,在代码任务、文档生成任务等方面表现均有提升,主要的优化措施有下面几个:
强鲁棒性的 XML 工具调用: 采用 <|DSML|tool_calls>等特定标签及 XML 格式进行工具交互,大幅降低了传统 JSON 格式易出现的格式逃逸和解析错误,提升了模型-工具交互的稳定性。交错思考(Interleaved Thinking): 在多轮 Agent 工作流中,V4 依托强大的长上下文能力,能够跨越用户对话边界完整保留历史思维轨迹。这解决了以往模型在多步任务中频繁“失忆”、需反复重构推理状态的痛点。 无预填充快速指令(Quick Instruction): 针对 Chatbot 常见的前置辅助任务(如判断是否联网、生成搜索词),V4 引入特定 Token,使其能直接复用主模型的 KV 缓存并行输出决策结果,彻底消灭了冗余的小模型预填充开销,大幅优化了首字响应时间(TTFT)。
六、 V4如何设计成本管理
为平衡计算成本与任务复杂度,V4(Pro 与 Flash)在系统层面均开放了三种梯度的推理模式:
Non-think(非思考模式): 适用于日常问答、紧急响应等低风险任务,基于模型直觉快速输出,响应极速。 Think High(高强度思考): 适用于代码编写与复杂规划。模型通过内置的 <think>标签进行逻辑拆解与分析,兼顾准确率与耗时。Think Max(极限思考): 旨在探索大模型推理能力的极限边界。系统会强制注入高标准指令,促使模型执行极致的步骤拆解、假设试错与自我验证。正是基于该模式,V4-Pro-Max 展现出了世界顶级的数理逻辑水平。
七、 异构 KV 缓存管理如何落实
百万上下文对推理框架的内存管理提出了严峻挑战。V4 打破了传统 PagedAttention 的局限,针对不同的 Attention 机制设计了异构缓存架构:
对于高压缩比的 CSA(压缩 4 倍)与 HCA(压缩 128 倍),缓存占用较小,执行常规管理。 对于未压缩且体量庞大的滑动窗口注意力(SWA)缓存,V4 创新性地引入了基于磁盘(On-Disk)的存储机制,并支持全缓存落盘(Full SWA Caching)、周期性快照(Periodic Checkpointing)与零缓存重计算(Zero SWA Caching)三种策略,使得部署端可以根据 I/O 与算力现状进行最优权衡。
结语
DeepSeek-V4 的问世,是一次充满探索精神的技术突围。它在保持与世界顶尖模型同一梯队实力的同时,把“性价比”和“普惠化”做到了极致。虽然在架构的精简度、部分极限能力的补齐上仍有提升空间,但随着 V4 系列的开源与 API 的平移,它无疑为全球开发者提供了一个极其强悍且经济的开源替代方案。