


执行摘要
本报告给出的核心结论是:十亿级企业数据不应被机械地“全量搬进图数据库”。更可落地的路线是,把企业大数据平台拆成“事实层、语义层、推理层、行动层”四层:数据中台/湖仓继续承载全量明细事实,图谱层只物化高价值实体、关键关系、规则上下文、行动状态与证据索引;本体与约束优先采用 万维网联盟[1] 的 JSON-LD、OWL 2 Profiles、SHACL 来表达;历史数据通过批量装载进入图谱,实时变化通过 Kafka/CDC/流处理做幂等增量更新;最终由 Agent 通过标准 API、消息与事件接口触发业务动作。这样既保留了 Parquet/湖仓在容量与成本上的优势,也让图谱与 Agent 获得稳定、可解释、可审计的业务语义上下文。JSON-LD 是兼容 JSON 的 Linked Data 表达方式;OWL 2 Profiles 明确用“降低表达力换取推理效率”的方法适配不同场景;SHACL 则是官方定义的 RDF 图校验语言。[2]
对于十亿级数据,推荐的主路线不是“一个图库承载全部事实”,而是“湖仓保真源,图谱保高价值语义与行动”。这不仅是工程经验,也是官方能力边界所暗示的最佳实践:Neo4j 的 neo4j-admin database import 强调 full / incremental 的离线大批量导入;NebulaGraph 官方明确建议 Importer 更适合低于十亿记录,而 Exchange 更适合十亿级以上分布式导入;Amazon Neptune 的 Bulk Loader 适合历史装载,但 AWS DMS 以 Neptune 为 target 时官方限制仍是 仅支持 full load,不支持 CDC;Stardog 则提供 Virtual Graph,把 RDBMS/CSV/JSON 等外部数据映射成 RDF,减少不必要的数据复制。[3]
推理与执行必须分层。语义层负责定义实体、关系、约束与规则;推理层负责给出“可解释的候选动作”;真正变更业务状态的执行必须经过权限、策略、人审与审计。这一点在事件接口和 API 设计上要从第一天就固化下来:HTTP 接口建议以 OpenAPI 描述,消息驱动接口建议以 AsyncAPI 描述,跨系统事件建议采用 CloudEvents 统一封装。OpenAPI 用于标准化 HTTP API 描述,AsyncAPI 是协议无关的消息驱动 API 规范,CloudEvents 用统一事件模型降低跨平台事件交换成本。[4]
工程落地建议采用三阶段推进。POC 聚焦两个到三个高价值场景,验证本体、导入链路、规则与一个 Agent 闭环;Pilot 打通历史批量、Kafka/CDC、规则服务、权限与审计;Production 再做跨域扩展、高可用、治理与合规。大多数企业失败并不是因为“图数据库不够强”,而是因为过早把“本体建模、规则治理、主键统一、权限边界、回放机制”这些更难但更关键的事情推迟了。流处理层面,Spark Structured Streaming、Kafka 与 Flink 的官方能力分别覆盖了可扩展微批、幂等/事务消息与有状态流式处理,因此可作为标准化的批流底座。[5]
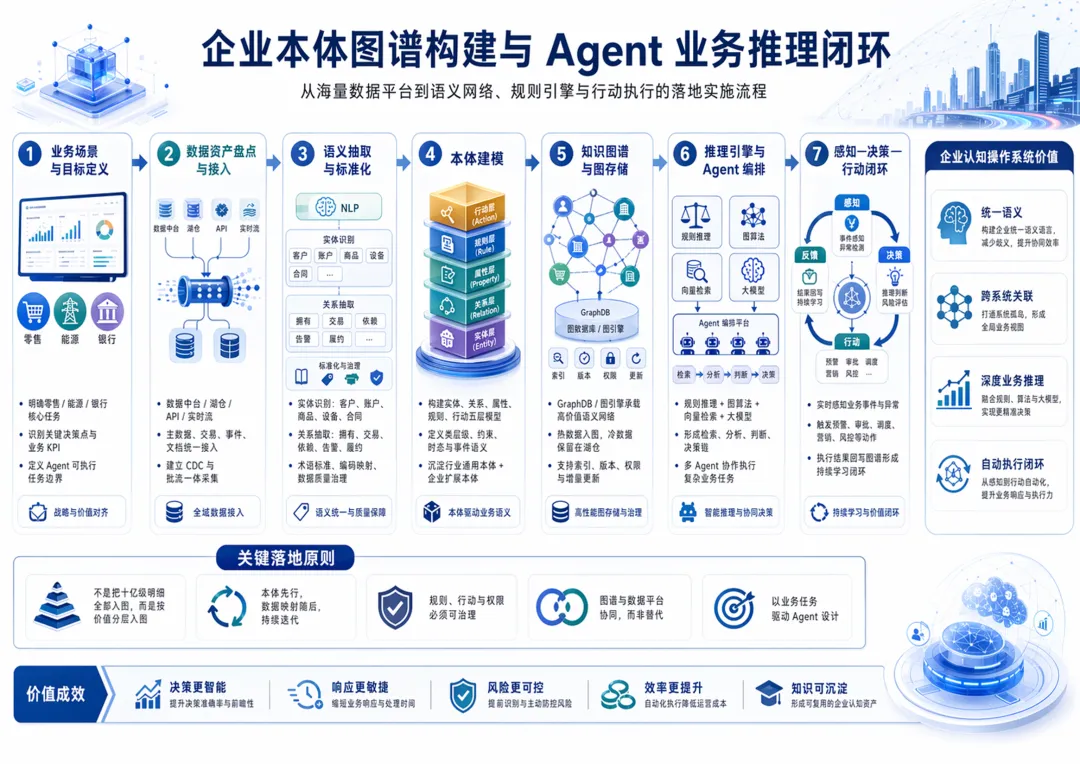
战略结论与目标蓝图
一个真正可执行的企业认知操作系统,建议围绕五个判断来设计。
第一,本体不是词典,而是“企业可计算认知边界”。它必须同时定义类、属性、关系、约束、规则、行动与证据,而不是只做一份术语表。JSON-LD 适合以 JSON 友好的方式表达语义对象;OWL 2 Profiles 适合在计算效率可控的前提下表达继承、等价与限制;SHACL 适合把“合法业务对象长什么样”明确写成机器可校验规则。[6]
第二,数据中台是事实系统,图谱是高价值语义与行动系统。历史明细、交易流水、设备遥测、长文本与文档证据仍应优先保存在列式事实层;图谱层只保留能显著提升推理与执行价值的实体、关系、状态与证据索引。Parquet 的列式设计适合大规模事实存储与检索;Stardog Virtual Graph、Neo4j bulk import、NebulaGraph Exchange 与 Neptune Bulk Loader 则分别提供了“映射、装载、分布式导入与托管装载”的不同路径。[7]
第三,批量与流式必须并存。历史数据入图要走批量装载,在线变化要走 CDC/Kafka/流处理;任何写入都必须具备事件主键幂等、回放、去重与断点恢复能力。Kafka 生产端的事务与 idempotence、Spark foreachBatch 的 batchId 去重能力、Flink 的 stateful processing 与 exactly-once 一起,构成了主流企业可接受的增量更新底座。[8]
第四,Agent 不能直接面对原始全表,只能面对“受控的语义上下文”。也就是说,Agent 的读入口应该是子图检索、政策判断、证据检索和工具目录,而不是任意 SQL 或任意表扫描;写入口则必须经过 OpenAPI / AsyncAPI / CloudEvents 统一契约、权限门与审计门。[9]
第五,图谱项目最怕“全量复制”“规则失控”“Agent 越权”。因此,从 Day 1 就要确立五个“不做”:不把所有明细事实都塞进图库;不让规则直接变更业务状态;不让 Agent 直接连核心系统;不把本体等同于数据字典;不把数据质量留给上线后修复。这个判断是本报告所有设计的总原则。
该蓝图将企业系统分为三条主线:左侧是“数据与实体化”,中部是“图谱、推理与语义服务”,下方是“Agent 执行、监控与反馈闭环”。它与官方能力边界一致:Parquet 适合事实层;JSON-LD、OWL、SHACL 适合语义层;Neo4j、NebulaGraph、Neptune 分别适合不同类型的图存储;GraphDB、Stardog、Jena 则更适合本体、规则与语义控制平面。[10]
分阶段实施蓝图
建议把实施拆成“发现、建模、抽取、导入、推理、Agent 集成、运维”七个阶段。这样做的目的是让每一阶段都有明确的业务边界、技术任务、交付件与退出条件,而不是在一个长周期里同时做完所有事情。
阶段 | 阶段目标 | 关键任务清单 | 主要交付物 | 建议工具与技术栈 | 退出条件 |
发现 | 识别最有价值的业务场景与数据源 | 盘点源系统、确定 Top 场景、梳理主数据主键、识别监管数据、定义 KPI/SLO、评估现有治理成熟度 | 用例地图、数据地图、主键词典、范围边界文档 | 数据目录、字段字典、业务访谈、数据画像 | 场景优先级明确;至少一条业务链路有完整数据来源与 owner |
建模 | 建立企业本体与命名规范 | 定义实体、关系、时态事实、规则、行动、证据;统一 ID、时间语义、来源字段、置信度;制定版本策略 | 本体 v1、JSON-LD / OWL 模板、SHACL 规则、命名规范 | Protégé、JSON-LD、OWL 2 Profiles、SHACL | 主实体与关系覆盖目标场景 80% 以上;关键对象具备唯一 canonical ID |
抽取 | 把结构化与非结构化数据转成语义对象 | 结构化映射、主键对齐、实体解析、关系抽取、文档证据切片、置信度计算、语义质量预检 | 节点/边中间层、抽取脚本、实体对齐规则、证据索引 | Spark、Python、NLP/LLM、规则模板、去重策略 | 抽样核对通过;实体重复率和丢失率可量化 |
导入 | 稳定地把历史与增量数据写入图层 | 历史全量批量导入、分区与并发调度、CDC/Outbox 增量、幂等 UPSERT、失败重放、索引预建/后建 | 图库 schema、批量导入任务、流式管道、回放机制 | Neo4j Admin Import / Nebula Exchange / Neptune Bulk Loader;Kafka;Spark/Flink;Debezium | 全量导入成功率高;增量链路可断点恢复;无高风险重复写入 |
推理 | 形成可解释业务判断能力 | RDFS/OWL 推理、SHACL 校验、业务规则、风险评分、推荐动作、Explain 与证据归因 | 规则库、推理服务、解释接口、规则监控 | GraphDB、Stardog、Apache Jena、规则服务 | 至少 1–2 个场景可以稳定输出“结论 + 证据 + 推荐动作” |
Agent 集成 | 把结论转成可控业务动作 | 设计 OpenAPI / AsyncAPI / CloudEvents 契约、子图检索 API、权限门、审批门、工具白名单、回执与补偿 | Tool schema、事件模型、执行编排、审计日志 | API Gateway、事件总线、工作流引擎、策略引擎 | Agent 能完成单场景闭环;关键动作有审批和审计 |
运维 | 建立长期演进能力 | 指标、日志、容量规划、规则灰度、备份恢复、版本回滚、血缘治理、权限轮换、值班手册 | SLO/SLA、Runbook、发布流程、优化基线 | Prometheus/Grafana、OpenLineage、Atlas、OPA、CI/CD | 运维有值守、有告警、有回滚;审计可追溯 |
这个分阶段蓝图与现有主流官方能力是匹配的:Spark Structured Streaming 负责可扩展微批与外部 sink 写入,Flink 负责长期运行的有状态流计算,Kafka 提供幂等/事务消息能力,Debezium Outbox Event Router 适合把业务数据库变化安全地转成事件流,OpenLineage 与 Atlas 则分别覆盖作业级血缘和元数据治理。[11]
如果要设置阶段门禁,建议采用以下口径。发现阶段以“场景与数据 owner 清晰”为门槛;建模阶段以“主实体 ID 与 SHACL 约束成型”为门槛;抽取阶段以“样本准确率与实体重复率可量化”为门槛;导入阶段以“全量成功率、增量幂等与回放可用”为门槛;推理阶段以“Explain 可展示”为门槛;Agent 集成阶段以“关键动作可审批、可补偿、可审计”为门槛。这样能显著降低大项目在中后期才暴露基础问题的风险。
数据、导入与性能设计
数据格式建议遵循一条非常实用的原则:Parquet 保存事实,CSV 服务装载,JSON-LD/RDF 表达语义。Parquet 是列式格式,适合海量事实数据的压缩、扫描与批处理;JSON-LD 天然兼容 JSON,适合把企业语义对象发布给服务层与 Agent;CSV 则仍是多数图数据库批量导入的现实首选。[12]
格式 | 适用位置 | 适用原因 | 示例 |
Parquet | 数据中台、湖仓、离线事实层 | 列式、压缩与扫描效率高,适合大规模历史与宽表事实 | 订单流水、交易事实、设备遥测 |
CSV | 图数据库批量装载中间层 | 工具链成熟,便于拆分节点表与边表 | Customer.csv、Order.csv、CustomerOrder.csv |
JSON / JSON-LD | 服务层、语义对象交换、Agent 输入 | 兼容应用系统与 API,易于表达嵌套语义对象 | 风险告警、推荐动作、证据摘要 |
RDF/Turtle | 本体、规则、知识发布 | 适用于语义网标准与 SPARQL 生态 | 本体 schema、规则与 shape 文件 |
下面给出一组最小可用的 CSV 设计。重点不在字段多少,而在每一条边和事实都带上主键、事件时间与证据引用。
# customers.csvcustomer_id,name,tier,master_id,source_system,event_timeC001,张三,GOLD,M-C001,crm,2026-04-23T09:30:00ZC002,李四,SILVER,M-C002,crm,2026-04-23T09:30:00Z
# orders.csvorder_id,customer_id,store_id,amount,currency,source_system,event_timeO9001,C001,S010,5888.00,CNY,oms,2026-04-23T09:31:00ZO9002,C002,S011,199.00,CNY,oms,2026-04-23T09:32:00Z
# customer_order_rel.csvsrc_customer_id,dst_order_id,relation,event_time,evidence_refC001,O9001,PLACED,2026-04-23T09:31:00Z,oms://order/O9001C002,O9002,PLACED,2026-04-23T09:32:00Z,oms://order/O9002
历史全量导入建议优先使用各图库的原生 bulk loader。Neo4j 官方的neo4j-admin database import支持full与incremental;NebulaGraph 官方建议十亿级以上使用 Exchange,低于十亿可用 Importer;Neptune 则建议通过 S3 + Bulk Loader 执行批量装载。需要特别注意的是,Neo4j 的 incremental import 对主键索引有要求,而 Neptune 作为 DMS target 时官方不支持 CDC,因此实时更新不宜直接依赖 DMS → Neptune。[13]
# Neo4j CSV -> 图批量导入示例neo4j-admin database import full neo4j \--nodes=import/customers_header.csv,import/customers_part_*.csv \--nodes=import/orders_header.csv,import/orders_part_*.csv \--relationships=import/customer_order_header.csv,import/customer_order_rel_part_*.csv
# customers_header.csvcustomer_id:ID(Customer),name:string,tier:string,master_id:string,source_system:string,event_time:datetime,:LABEL
# customer_order_header.csv:START_ID(Customer),:END_ID(Order),event_time:datetime,evidence_ref:string,:TYPE
对于增量链路,推荐主模式是“业务库/应用服务→ Debezium Outbox / CDC → Kafka → Spark/Flink →图谱幂等写入”。Debezium Outbox 适合避免业务数据库状态与外部事件状态不一致;Kafka 的事务与 idempotence 提供更稳的消息语义;Spark 的foreachBatch可以用batchId写外部系统并做去重;Flink 则更适合做复杂有状态流、长期运行任务和精细窗口处理。[14]
# Kafka -> Spark Structured Streaming -> 图数据库幂等增量伪代码from pyspark.sql import functions as Fevents = (spark.readStream.format("kafka").option("subscribe", "enterprise.semantic.events").option("startingOffsets", "latest").load())parsed = (events.selectExpr("CAST(value AS STRING) AS raw").select(parse_event_json("raw").alias("e")).select("e.*").withColumn("entity_partition", F.xxhash64("entity_key")))def upsert_to_graph(batch_df, batch_id: int):clean = (batch_df.dropDuplicates(["event_id"]).repartition("entity_partition"))vertices = build_vertices(clean)# 实体映射edges = build_edges(clean)# 关系映射facts = build_fact_nodes(clean)# 事实/证据节点graph.begin_tx()graph.upsert_vertices(vertices, key="canonical_id")graph.upsert_edges(edges, key="event_id")graph.upsert_vertices(facts, key="event_id")graph.record_checkpoint(batch_id=batch_id)graph.commit()(parsed.writeStream.foreachBatch(upsert_to_graph).option("checkpointLocation", "s3://kg-checkpoints/semantic-events").start())
分区与并发策略应围绕“稳定键、热路径、批次管理”展开。历史文件建议按租户、业务域、时间窗口切分;增量链路建议按 entity_key 或 canonical_id 分区,保证同一核心实体的事件尽量串行;批量装载时先节点后边,先低基数维度后高基数事实,尽量避免边与节点交错写入造成大量随机寻址;失败任务必须支持批次级重跑,不允许只能“整条链路从头来过”。
性能优化建议从四个维度着手。索引方面,业务主键、外部键、状态字段与时间窗字段是必建索引;全文检索与向量检索应与关系导航分工,不要用图遍历代替全文搜索。Neo4j 官方已把 full-text index 与 vector index 作为独立能力提供,适合 GraphRAG 类子图召回;Neptune 依赖 replica 扩展读吞吐;NebulaGraph 强调 shared-nothing 架构与横向伸缩。[15]
// Neo4j 索引示例CREATE RANGE INDEX customer_id_idx IF NOT EXISTSFOR (c:Customer) ON (c.customer_id);CREATE FULLTEXT INDEX customer_text_idx IF NOT EXISTSFOR (c:Customer|Merchant) ON EACH [c.name, c.alias, c.description];CREATE VECTOR INDEX customer_embedding_idx IF NOT EXISTSFOR (c:Customer) ON c.embeddingOPTIONS {indexConfig: {`vector.dimensions`: 1536,`vector.similarity_function`: 'cosine'}};
数据质量不能停留在 ETL 规则,而应形成“两层门禁”。第一层是工程质量门,用 GX 或等价框架验证完整性、唯一性、值域、分布、重复率与引用关系;第二层是语义质量门,用 SHACL 明确每类业务对象必须拥有哪些属性、哪些关系组合被禁止、哪些枚举值合法。血缘与模型关系则由 OpenLineage 与 Atlas 负责沉淀。GX 把“可接受的数据状态”表达为可执行验证;OpenLineage 记录 datasets/jobs/runs;Atlas 提供开放元数据管理与治理能力。[16]
规则、本体与 Agent 执行设计
本体设计推荐从“企业共性骨架 + 领域扩展”入手,而不是从行业术语堆出来。最小骨架应至少包括 Party、Asset、Event、Policy、Rule、Action、Evidence 七大类。零售、能源、银行的差异,应该体现在继承层和属性层,而不是把整个本体做成完全分裂的三套模型。OWL 2 Profiles 的设计目标本来就是在表达力与推理效率之间取得平衡,这正适合企业级场景。[17]
下面给出一个简化 JSON-LD 本体片段,可作为起步模板。
{"@context": {"ex": "https://example.com/ontology/","rdf": "http://www.w3.org/1999/02/22-rdf-syntax-ns#","rdfs": "http://www.w3.org/2000/01/rdf-schema#","owl": "http://www.w3.org/2002/07/owl#"},"@graph": [{ "@id": "ex:Party", "@type": "rdfs:Class" },{ "@id": "ex:Customer", "@type": "rdfs:Class", "rdfs:subClassOf": { "@id": "ex:Party" } },{ "@id": "ex:Asset", "@type": "rdfs:Class" },{ "@id": "ex:Order", "@type": "rdfs:Class", "rdfs:subClassOf": { "@id": "ex:Asset" } },{ "@id": "ex:RiskAlert", "@type": "rdfs:Class" },{ "@id": "ex:Action", "@type": "rdfs:Class" },{ "@id": "ex:placedOrder", "@type": "rdf:Property", "rdfs:domain": { "@id": "ex:Customer" }, "rdfs:range": { "@id": "ex:Order" } },{ "@id": "ex:triggersAlert", "@type": "rdf:Property", "rdfs:domain": { "@id": "ex:Order" }, "rdfs:range": { "@id": "ex:RiskAlert" } },{ "@id": "ex:recommendedAction", "@type": "rdf:Property", "rdfs:domain": { "@id": "ex:RiskAlert" }, "rdfs:range": { "@id": "ex:Action" } }]}
SHACL 适合用来表达“对象必须合法”。下面是一个最小示例,表示 Customer 必须有且只有一个masterId,并且tier只能是指定枚举值。SHACL 的官方定义就是针对 RDF 图的结构与约束校验。[18]
@prefix sh: <http://www.w3.org/ns/shacl#> .@prefix ex: <https://example.com/ontology/> .ex:CustomerShapea sh:NodeShape ;sh:targetClass ex:Customer ;sh:property [sh:path ex:masterId ;sh:minCount 1 ;sh:maxCount 1] ;sh:property [sh:path ex:tier ;sh:in ("BRONZE" "SILVER" "GOLD")] .
规则设计建议拆成三层。结构规则负责校验与纠错,例如主键唯一、关系合法、实体类型完整;业务规则负责推理,例如欺诈、补货、维修、关联预警;动作规则负责把推理结果翻译成可执行动作,例如派工、复核、通知、冻结、推荐。推理引擎层面,Apache Jena 提供 RDFS/OWL 与规则引擎支持;GraphDB 提供 RDFS、OWL-Horst、OWL2-RL、OWL2-QL 等规则集与一致性检查;Stardog 则以 query-time reasoning、late binding 和 Virtual Graph 为特点。[19]
# 银行:高风险交易复核IFTransaction(t) ANDamount(t) > 5000 ANDdeviceAgeHours(t) < 24 ANDgeoRisk(t) = "HIGH"THENcreate RiskAlert(type="MANUAL_REVIEW", subject=t, confidence=0.92)recommend Action(type="SUBMIT_CASE")
# 零售:补货建议IFStore(s) ANDProduct(p) ANDsales7d(s,p) / stockOnHand(s,p) > threshold(p)THENcreate RiskAlert(type="REPLENISHMENT_OPPORTUNITY", subject=s)recommend Action(type="CREATE_REPLENISHMENT_TASK")
# 能源:设备告警 -> 工单IFSensorEvent(e) ANDmetric(e,"temperature") > upperLimit(assetOf(e)) ANDmaintenanceDue(assetOf(e)) = trueTHENcreate RiskAlert(type="MAINTENANCE_REQUIRED", subject=assetOf(e))recommend Action(type="CREATE_WORK_ORDER")
# 实体解析:主数据主键一致 -> sameAsIFCustomer(c1) AND Customer(c2) ANDmasterId(c1) = masterId(c2) ANDsourceSystem(c1) != sourceSystem(c2)THENinfer sameAs(c1, c2)
Agent 接口层推荐使用“三件套”。同步调用用 OpenAPI 描述;异步接口用 AsyncAPI 描述;跨系统事件封装用 CloudEvents。这样可以把“子图查询、策略判断、任务创建”与“事件流、回执、审计”同时标准化。OpenAPI、AsyncAPI、CloudEvents 各自的官方定位都非常清晰,适合企业级的规范治理与代码生成。[4]
# OpenAPI 3.1.1 示例:子图检索接口openapi: 3.1.1info:title: Semantic Subgraph APIversion: 1.0.0paths:/subgraphs/{subjectId}:get:summary: 获取指定业务对象的执行子图parameters:- in: pathname: subjectIdrequired: trueschema: { type: string }responses:'200':description: 子图返回content:application/json:schema:type: objectproperties:subjectId: { type: string }nodes: { type: array, items: { type: object } }edges: { type: array, items: { type: object } }evidenceRefs: { type: array, items: { type: string } }
# AsyncAPI 3.1.0 示例:风险告警事件asyncapi: 3.1.0info:title: Risk Alert Event APIversion: 1.0.0channels:risk.alert.created:address: risk.alert.createdmessages:riskAlertMessage:payload:type: objectproperties:eventId: { type: string }tenantId: { type: string }subjectId: { type: string }severity: { type: string }recommendedAction: { type: string }evidenceRefs:type: arrayitems: { type: string }operations:onRiskAlertCreated:action: receivechannel:$ref: '#/channels/risk.alert.created'
{"specversion": "1.0","type": "risk.alert.created","source": "kg://reasoner/rules/RISK_001","id": "evt-20260423-000981","subject": "transaction/TX-9981","time": "2026-04-23T09:40:00Z","datacontenttype": "application/json","data": {"tenantId": "bank-cn-01","severity": "HIGH","confidence": 0.92,"recommendedAction": "SUBMIT_CASE","graphRef": "subgraph://risk/TX-9981","evidenceRefs": ["corebank://tx/TX-9981","device://D-10091","geo://session/abc-1"]}}
一个稳健的 Agent 执行流,建议严格遵循下表所示的顺序。
步骤 | Agent 行为 | 关键控制点 |
任务接收 | 接收业务目标、上下文与租户信息 | 必须带租户、权限、traceId |
语义检索 | 调用子图 API、证据 API、策略 API | 不直接让 Agent 扫原始大表 |
上下文压缩 | 输出执行子图、事实摘要、证据链 | 必须包含来源与置信度 |
规则推理 | 触发结构规则、业务规则、动作建议 | Explain 与命中记录必须保留 |
策略门禁 | 权限判断、审批判断、风控门 | 高风险动作默认需人审 |
工具调用 | 调用业务系统 API/消息接口 | 工具白名单、参数校验、幂等 |
回执验证 | 接收调用结果与状态变更 | 失败要有补偿或工单 |
图谱回写 | 写回 Action、Evidence、Outcome | 图上必须保留“做了什么” |
学习反馈 | 记录误报/漏报/人工修正 | 进入灰度验证,不直接改生产规则 |
闭环学习要采集四类反馈:结果反馈、质量反馈、行为反馈与知识反馈。结果反馈关注成功率、时延、人工接管率;质量反馈关注误报、漏报、实体误合并与规则冲突;行为反馈关注 Agent 是否出现循环、工具失败和重试异常;知识反馈关注术语变化、字段变化与政策变化。建议使用“候选变更 → 离线回放 → 灰度发布 → 全量发布”的发布链,避免 Agent 或规则在生产系统中自发漂移。
安全与合规设计必须遵循 least privilege 原则。NIST 对 least privilege 的定义是:仅授予完成任务所必需的最小权限。策略执行层则建议引入 OPA,将审批、操作白名单、字段遮蔽等逻辑写成 Rego;如果已有 Atlas 体系,也可以让资产分类与授权策略联动。[20]
选型比较与建议工具链
图数据库的选型不应只问“谁最快”,而应问“谁最适合你的主职责”。如果主职责是在线关系遍历、热路径执行与 GraphRAG,属性图通常更实用;如果主职责是本体治理、规则推理、语义映射与知识发布,RDF/OWL 语义库更自然。大多数企业的最佳实践不是单选,而是“双层组合”:在线执行图层 + 语义控制平面。
图数据库 | 适合场景 | 可扩展性 | 导入工具 | 查询语言 | 公开成本估算 | 主要优点 | 主要限制 |
Neo4j[21] Aura / Self-Hosted | 在线知识图谱、子图检索、GraphRAG、Agent 热路径 | 支持 full / incremental bulk import;Aura Professional 单实例可到 128GB,Business Critical 可到 512GB | neo4j-admin database import、LOAD CSV | Cypher | AuraDB Professional 约 $65/GB/月;Business Critical 约 $146/GB/月 | 生态成熟、Cypher 易用、向量与全文索引成熟 | 大规模分片与跨域治理需额外架构设计 |
Amazon Neptune(由 Amazon Web Services[22]提供) | AWS 托管优先、需要 openCypher/Gremlin/SPARQL 共存 | 支持 up to 15 个 reader;按需与 Serverless 扩缩容 | S3 Bulk Loader;DMS target 仅 full load | openCypher、Gremlin、SPARQL | 按实例/NCU/存储/I/O 计费,官方按需与 Serverless 无最低费用 | 托管化程度高,适合 AWS 一体化 | CDC 方案需自建事件链路;索引与调优方式与属性图库不同 |
NebulaGraph[23] | 十亿级以上分布式属性图、成本敏感、自建能力强 | shared-nothing,支持横向伸缩;官方文档定位在大规模图场景 | Importer、Exchange | nGQL | 社区版软件成本低,基础设施与 SRE 成本主导 | 分布式大图性价比高,适合超大规模 | 团队需要更强的自运维能力 |
表中关于导入方式、可扩展性与公开成本口径,主要基于官方导入、架构与定价文档整理。Neo4j 的 full/incremental import、AuraDB 价格与索引能力来自官方文档;Neptune 的 Bulk Loader、reader 数量、按需/Serverless 计费来自 AWS 官方文档;NebulaGraph 的 Importer/Exchange 分工与 shared-nothing 架构来自官方手册。[24]
推理引擎建议按“推理模式、规则能力、是否支持虚拟图、是否适合作为控制平面”来选,而不是只看是否支持 OWL。
推理引擎 | 推理模式 | 标准能力 | 成本估算 | 优点 | 限制 | 最佳角色 |
Apache Jena(来自 Apache 软件基金会[25]) | 嵌入式规则与推理框架 | 支持 RDFS/OWL reasoner 与规则引擎 | 软件成本低,主要是工程投入 | 轻量、灵活、适合做规则微服务 | 不适合作为超大规模在线主库 | 语义控制平面、规则 sidecar |
GraphDB(由 Ontotext[26]提供) | 库内推理、规则集与一致性检查 | 支持 RDFS、OWL-Horst、OWL2-RL、OWL2-QL、自定义规则集 | Free 适合小负载;生产版需询价 | 规则体系强,RDF 语义能力强,可做企业语义主库 | Free 限两并发查询;企业版商业化 | 本体主库、规则与语义治理 |
Stardog[27] | 查询时推理、late binding | 支持 RDFS、OWL2 QL/RL/EL/SL;支持 Virtual Graph | Cloud Free 可到 1M edges;生产版需询价 | 查询时推理、虚拟图强、减少数据复制 | 大规模生产通常需商业版 | 跨源语义层、语义联邦与虚拟图 |
这一张表的核心依据是:Jena 官方文档明确提供 RDFS/OWL 与规则引擎;GraphDB 官方说明支持 RDFS、OWL-Horst、OWL2-RL、OWL2-QL、自定义规则集,以及 Free 版两并发查询限制和企业集群对 tens of billions RDF statements 的支持;Stardog 官方强调 query-time reasoning、late binding、Virtual Graph 以及 Cloud Free 的 1M edges 限额。[28]
在没有特殊约束的前提下,本报告给出的默认推荐拓扑如下:
架构层 | 推荐默认组合 | 选择理由 |
事实层 | 湖仓 / 数据中台 + Parquet | 容量、扫描效率、成本与生态最稳 |
在线图层 | Neo4j 或 NebulaGraph 或 Neptune | 分别对应“开发效率优先 / 超大规模自建 / AWS 托管优先” |
语义控制平面 | GraphDB 或 Stardog 或 Jena 规则服务 | 分别对应“本体主库 / 跨源虚拟图 / 轻量嵌入式规则” |
事件层 | Kafka + Debezium Outbox | 保证 CDC 与事件一致性更稳 |
批流引擎 | Spark + Flink | 微批与有状态流长期共存 |
治理层 | GX + OpenLineage + Atlas | 分别负责数据质量、血缘、元数据治理 |
策略层 | OPA | 权限门、审批门、操作门可代码化 |
监控层 | Prometheus + Grafana + Trace | 监控导入、查询、规则、Agent 执行 |
这个工具链清单对应的官方能力分别来自:Parquet 的列式格式定位,Spark/Flink/Kafka/Debezium 的批流与事件能力,OpenLineage 的 lineage 模型,Atlas 的 metadata & governance,OPA 的 Rego 策略语言。[29]
里程碑、组织投入、风险与未定项
下面给出一套可用于立项、预算和项目排期讨论的粗略里程碑。这里的工作量是“高可信粗估”,而不是供应商合同级承诺。
路线 | 目标范围 | 粗略工期 | 粗略人月 | 关键产出 |
POC | 单业务域;2–3 个高价值场景;单图层 + 单规则服务 + 单闭环 Agent | 8–12 周 | 8–12 人月 | 本体v1、批量导入、最小增量链路、规则样板、1 个 Agent 工具闭环 |
Pilot | 一个主域 + 一个关联域;亿级历史 + 核心增量;权限与审计上线 | 16–20 周 | 18–28 人月 | 历史批量、CDC、规则 Explain、审批门、审计、监控 |
Production | 多业务域;十亿级关系;7×24 运维;灰度与回滚健全 | 24–36 周 | 30–45 人月 | 高可用、治理、容灾、模型与规则发布链、跨域复用 |
典型团队配置建议为:架构师 1 人,数据工程师 2–3 人,图数据库/知识工程师 2 人,后端/Agent 工程师 2 人,DevOps/SRE 1 人,治理与安全 0.5–1 人,业务专家 1–2 人兼职评审。项目成败通常不取决于数据库人数,而取决于业务 owner + 主数据 owner + 规则 owner 是否同时到位。
主要风险与缓解措施如下。
风险 | 典型表现 | 缓解措施 |
全量复制进图导致成本与性能失控 | 图库膨胀、索引沉重、热查询退化 | 湖仓保全量事实;图谱只放高价值关系与行动状态;必要时引入虚拟图 |
主键体系不稳 | 同一客户/账户/设备被拆成多个实体 | 先做 canonical ID;主数据映射优先于图入库 |
CDC 重复、乱序与事件丢失 | 状态回跳、边重复、规则误触发 | 事件主键幂等、按实体键分区、检查点与重放机制 |
规则体系失控 | 规则冲突、不可解释、无法灰度 | 结构规则/业务规则/动作规则分层;所有规则版本化、可回放 |
Agent 越权执行 | 绕过审批、直接写核心系统 | 工具白名单、least privilege、OPA 审批门、审计全留痕 |
选型与场景错配 | 用 RDF 主库承担高并发热遍历,或用属性图硬做复杂本体推理 | 采用“双层”架构:在线图层与语义控制平面分离 |
供应商能力边界被忽视 | 例如以为 DMS 可以直接 CDC 到 Neptune | 在 POC 阶段把导入、索引、Explain、失败恢复全部验证一遍 |
从合规与安全视角看,以下要求应视为“上线前必选项”:统一身份源、最小权限、关键动作审批、敏感字段分类与遮蔽、审计日志不可篡改、规则与模型版本可回滚、批次与事件可追溯。这些要求与 NIST least privilege、Atlas 授权模型、OPA policy-as-code 的思路是一致的。[20]
当前仍有四类未定项,会显著影响最终方案细节。延迟目标决定选择 Spark 微批还是更偏 Flink 的长期流;组织边界决定选择单租户还是多租户隔离模型;合规地域决定日志、备份与数据跨域策略;现有治理成熟度则决定发现与建模阶段要投入多大比例的人力。这些未定项不会改变本报告的总路线,但会改变工程实现深度与成本结构。
适合作为立项、详细方案设计、POC 与交付验收的参考。
语义标准与数据格式方面,优先参考 JSON-LD 1.1、OWL 2 Profiles、SHACL 与 Apache Parquet 官方资料。[30]
图数据库导入、扩缩容与索引方面,优先参考 Neo4j 的 import 与 indexes 文档、Amazon Neptune 的 pricing / intro / bulk load / scaling 文档,以及 NebulaGraph 的 Exchange / Importer / architecture 文档。[31]
推理引擎与语义控制平面方面,优先参考 Apache Jena inference 文档、GraphDB inference / reasoning / cluster / licensing 文档,以及 Stardog inference engine / virtual graphs / cloud 文档。[32]
事件与接口标准方面,优先参考 OpenAPI Specification 3.1.1、AsyncAPI Specification、CloudEvents 官方规范。CloudEvents 还提供中文站,可作为团队培训材料。[33]
批流、CDC 与质量治理方面,优先参考 Spark Structured Streaming / foreachBatch、Apache Flink、Apache Kafka producer configs、Debezium Outbox Event Router、Great Expectations、OpenLineage 与 Apache Atlas。[34]
权限、策略与安全基线方面,优先参考 NIST least privilege 与 OPA policy language / REST API 文档。[35]
本报告的最终建议可以概括为一句话:用数据中台承载全部事实,用本体统一企业语义,用图谱承载高价值关系与行动状态,用规则提供可解释推理,用 Agent 在权限与审计之内完成业务动作。这样做,才是十亿级企业知识网络真正可落地、可扩展、可治理的路径。欢迎大家报名参加OAG 5天训练营,成为企业的FDE.
________________________________________
[1] [16] https://docs.greatexpectations.io/docs/core/introduction/gx_overview/
https://docs.greatexpectations.io/docs/core/introduction/gx_overview/
[2] [7] [10] [12] [29] https://parquet.apache.org/
https://parquet.apache.org/
[3] [13] [24] [25] [31] Import - Operations Manual
https://neo4j.com/docs/operations-manual/current/import/?utm_source=chatgpt.com
[4] [9] [21] [27] [33] https://spec.openapis.org/oas/v3.1.1.html
https://spec.openapis.org/oas/v3.1.1.html
[5] [11] [34] https://spark.apache.org/docs/latest/streaming/index.html
https://spark.apache.org/docs/latest/streaming/index.html
[6] [22] [26] [30] JSON-LD 1.1
https://www.w3.org/TR/json-ld11/?utm_source=chatgpt.com
[8] Producer Configs | Apache Kafka
https://kafka.apache.org/41/configuration/producer-configs/?utm_source=chatgpt.com
[14] https://debezium.io/documentation/reference/3.4/transformations/outbox-event-router.html
https://debezium.io/documentation/reference/3.4/transformations/outbox-event-router.html
[15] https://neo4j.com/docs/cypher-manual/current/indexes/semantic-indexes/full-text-indexes/
https://neo4j.com/docs/cypher-manual/current/indexes/semantic-indexes/full-text-indexes/
[17] OWL 2 Web Ontology Language Profiles (Second Edition)
https://www.w3.org/TR/owl2-profiles/?utm_source=chatgpt.com
[18] Shapes Constraint Language (SHACL)
https://www.w3.org/TR/shacl/?utm_source=chatgpt.com
[19] [23] [28] [32] https://jena.apache.org/documentation/inference/
https://jena.apache.org/documentation/inference/
[20] [35] https://csrc.nist.gov/glossary/term/least_privilege
https://csrc.nist.gov/glossary/term/least_privilege